
Inter + Net
大多数互联网公司的看法是,如果你是免费用户,那么我们就可以把你当作产品的一部分,来使用你。
– HN 读者
互联网诞生之前,程序员没有 StackOverflow、Slack、Reddit、Youtube、网络教程。编程遇到问题的时候,手边必须有语法手册和系统手册,如果你没有这两本书,就只能去图书馆或书店找书。
– 推特用户
What
互联网就像一个坑坑洼洼的道路系统,路上到处都有修路工人。
上路时,你的车辆可能被劫持,也可能有黑手伸入车窗偷走你的东西,甚至你不知不觉时,车辆就被卖掉了,供他人使用。你都没有注意到那些犯罪的人,压根不会指责和追究他们的责任。
– GNU:net
互联网不再稀缺
疫情期间,很多东西都是稀缺的:缺口罩、缺消毒液、缺呼吸机……但是,有一样东西是不缺的,那就是互联网。

互联网相关的东西,好像没有出现过紧缺,随时都可以轻松使用。宽带不缺、流量不缺、App 不缺,云服务也不缺。一些视频会议软件,出现过资源紧张,但是服务器扩容以后,很快就解决了。
仔细观察,你会发现,稀缺的都是实体商品,虚拟的互联网服务不仅不缺,实际上还很宽裕。
这说明了什么?
经过几十年的高速发展和庞大投资,互联网不再是稀缺商品,即使发生危机的情况下也不缺,实际上还处于过剩状态。
我问大家一个问题,4G 通信已经很快了,为什么电信服务商还拼命发展 5G?我认为,原因是常规的电信数据服务(即互联网需求)已经接近饱和了, 4G 拉动不了需求了,服务商不得不用更快的网速去刺激消费,尤其希望高清电视能通过 5G 得到普及。

(图片说明:每个人头上的云,现在不是太少了,而是太多了。)
根据经济学原理,稀缺的东西才能卖出高价。如果互联网不再稀缺,这意味着什么?
我认为,今后互联网服务的竞争将非常激烈,因为市场的增长速度已经大大放缓,没有任何一种网络服务是供不应求的。 线上的虚拟产业,到了最后将都是规模竞争,卖不出高价,真正可以卖出高价的是一些实体的东西。
什么是互联网圈的降维攻击?
最近互联网圈有个词儿挺火,叫降维攻击,维是三维空间的维。什么是降维攻击呢,打个比方,战斗机是立体式作战,原始部落只能地平面作战,所以战斗机可以打地面的原始人,原始人却打不到天上去,这种高维打低维,就叫降维攻击。
比如说,咱都知道百度是搜索领域的绝对老大,但搜狗和360,硬是从百度嘴里抢走了一块市场,为什么?因为百度再牛也只是个网页,用户打开百度页面,得先开浏览器吧,搜狗和360都做了浏览器,处在更高维,所以通过浏览器推荐自家的搜索服务,就能分走百度一块市场。
再比如,为什么淘宝要屏蔽百度呢?因为淘宝害怕被降维攻击啊,你想,如果用户上淘宝都要先经过百度,那百度就占据了更高维,淘宝只有挨打的份儿了。后来淘宝还屏蔽了蘑菇街之类的导购网站,也是怕别人从高维抢用户。
现在,在移动互联网的时代,为什么大家都争着做手机、做WiFi?因为这都是未来的更高维,各种APP要通过手机和用户见面,家里上网也都要通过WiFi,谁占据更高维度,谁就拥有降维攻击的优势地位。
你看,互联网巨头之间的过招,看起来眼花缭乱,本质上是一场抢占高维、避开低维的较量。
本文源自:从降维攻击详解互联网格局体系
什么是互联网新物种?
最近罗辑思维的罗振宇在真格论坛做了场演讲,其中一个观点挺有意思,他提出,过去互联网就像是线的时代,连接最有价值,就像没有铁路的时候铁路公司最赚钱,但互联网连接红利结束以后,点的时代就会到来,就像铁路铺完了,利用铁路的钢铁业、石油业最赚钱。那怎么才能做成一个未来有价值的“点”呢?他从两个角度进行了说明。
第一,做点要具备打通产业链的能力。什么意思?简单来看,产业链可以分成品牌、流量、用户、造货、服务这五个环节,过去咱们的商业都是在这五个环节上进行横向切割,然后像铁路警察一样各守一段儿,比如淘宝、百度专门生产流量,媒体专门打造品牌,生产企业专门去造货……但现在,出现了能打通全环节 的企业,你比如苹果吧,它自己就有媒体属性——每次发布新产品都万众瞩目啊,它根本不需要别人给它流量,它的造货和服务能力是全世界一流的。雷军的小米、罗永浩的锤子手机也都是这样,自己就把媒体、流量、用户、造货和服务全打通了。具备了打通产业链的能力,就能把自己做成一个很有价值的点,别人才会来主动连接你。
第二,拒绝创新,用重复去累积价值。美国的超级碗,那是全美国人的盛事,一年一度,形式上从来没有创新。奥斯卡颁奖礼,几十年了,形式也没有创新。越是没有创新,每一个从业者都会本能的在里边进行各种细节上的创新,这是遏制不住的。于是,依靠时间的力量,它就可以堆积出很大的价值,这是做点的企业的心态。罗振宇自己就打算从今年12月31号开始,请一群思想者实践者搞跨年演讲,一直讲到新年钟声敲响。重要的是,他会把这个事重复搞20年,他相信,时间会把这场年度演讲堆积成一个巨大的价值高地。
所以你看,创业公司如果能具备全产业链能力,用重复去不断累积价值,就能成为一个很有价值的点。
本文源自:【真格基金】罗振宇专题演讲
观点:互联网下半场是物理世界的数字化
陶闯是PPTV前CEO,离开PPTV之后做过投资,现在他创立了服务于自动驾驶的地图公司Wayz.ai(提供完整的位置智能服务解决方案)。在接受创业创新服务平台i黑马采访时,陶闯谈到了自己创业的原因,“互联网上半场的时候,大家都在考虑虚拟的东西,是网络信息的数字化,包括游戏、搜索、视频,以内容为主。下半场不同了,是物理世界的数字化,最直接的就是地图”。
陶闯认为,线下最核心的就是解决距离问题。比如,共享单车是人和自行车的匹配,滴滴是人和汽车的匹配,外卖是人和商户的匹配。而地图相当于真实世界的线上版本,解决的就是线下的连接问题。“因为距离决定了服务,任何一个线下商业的核心都要基于位置。” 所以,业界首先要做的就是“物理世界的数字化”,地图又是一件“趋势确定、模式不确定”的东西,陶闯认为很适合创业公司。
陶闯做地图的决定来自于他2014年的判断。当时他离开PPTV,到国外看到了自动驾驶的发展,他认为这是未来的一个趋势。陶闯说:“目前缓解交通问题只有两个方法:第一,修高速公路,直到每个人出门都有高速公路,但成本太大、性价比太低。我们把修路叫‘横向解决’;第二,‘纵向解决’,把每个开车的行为有效规范化,让车间距从20米压缩到两米,这样的车只有机器才能开,人开不了,会出问题。”而计算表明,如果自动驾驶完全普及,车间距减少到2米或者3米,全球在开车这方面的交通效率会提升20到30倍,安全系数会提高1万倍、甚至10万倍以上。
至于这样的未来是否会实现,陶闯认为,人的适应性是很强的,当趋势确定,并且某件事以超乎想象的速度发生之后,很快人们就会习以为常。陶闯举例说,在做PPTV的时候,他们专门讨论了用户是在电脑上看视频,还是在手机上看视频,当时大家都觉得,手机屏幕这么小,人们会在上面看吗?而随着移动互联网出现之后,人人都习惯在手机上看视频了。
线下企业该向互联网公司学什么
现在,越来越多的企业在向互联网转型,但它们不是开个公众号,就是做一个App。最近营销达人李叫兽写了篇文章,说其实线下企业要想互联网化,关键不在于做不做App,而是有没有做App的思维。那线下企业到底要跟App学什么呢?我们来听听李叫兽怎么说。
第一,文章说,你要多添加内容。举个例子,健身软件Keep, 本来就是一个工具型产品,但是它的内容就不只是健身功能而已。Keep做了大量视频演示,指导用户健身,还搭建社区让用户看到其他人的健身成果,更直观地感受健身的意义,用户评价就很高。线下的场景其实也应该多考虑加内容进去。就像多肉植物,如果你只把它当成一款普通又便宜的植物的话,那就没什么上升空间。但是,当多肉被赋予了治愈的含义的时候,就不一样了。在你觉得受到挫折的时候,这种治愈系植物就有了被欣赏的场景,这样的内容一下子就让多肉从一种植物变成一种有陪伴属性的事物。还有,智能体重秤,本来也是平淡无奇,但它对外宣传出一种对抗脂肪,拥抱健康生活的态度,同样能感化到有这种价值观的用户。再比如可口可乐,通过在平面包装上添加了电影台词,就把一罐饮料变成了一个可以用来回忆的场景。其实消费场景的同时,就是在消费内容。多一点内容,也就多一点消费场景。
第二,要重视小游戏。如果你留意一下会发现,许多App都设置了一些互动的小游戏,比如微信上的步数排名,打飞机等等。同样线下场景也可以设计游戏,让用户玩起来。比如,罗辑思维曾经卖过一款真爱月饼,就是设置了一种众人支付的玩法,让用户把支付链接分享给朋友,让大家众筹来把订单凑齐。再比如优衣库,曾经在自己的门店里策划了一个搭衣服的游戏,在门店里摆放一个巨大的镜像屏幕,用户站在屏幕前,屏幕就会自动给用户加载一个巴黎啊,东京街头的背景,让用户瞬间体验一把穿越,用户发朋友圈发的不亦乐乎。
第三,要注重跨界合作。现在的App经常引入各种跨界合作,比如说有一个专注为女性提供服务的App叫大姨妈,后来就和姜茶啊,红糖啊等这类的相关厂家进行电商合作。线下场景其实也可以这么干。比如说有一款智能手环,可以用来检测用户每天的运动量,同时,又和一些线上的跑酷手游合作,换取一些游戏币。还有,易到专车还曾经和书籍机构合作,在专车里推出读书活动,鼓励用户在车上读书,还可以扫描书中的二维码获取乘车优惠券,这些都是跨界合作带来的丰富的线下场景。
第四,要有社交属性。社交是App特别重要的一环,线下也是一样。比如曾经美国航空业竞争非常的激烈,维珍航空就推出了约空姐的活动,鼓励乘客在飞机到达目的地后主动跟空姐约会。再比如,有些餐厅提供约会服务,让单身顾客邀请美女或者帅哥服务员共进午餐。还有最近特别火的小猪短租,也是提倡让旅客直接入住当地人家,感受本地的文化,这些都是在植入社交元素。
第五,要鼓励分享。酒香也怕巷子深,一个好的App都是在鼓励用户分享,线下的场景最好也能鼓励用户分享,这样,用户不仅有参与感,还更容易传播品牌。比如,如果你经营的是一家餐厅的话,就可以在餐厅的桌子上贴一个二维码,客人用微信扫描就可以看到之前在这个桌子上吃饭的人,还可以主动晒照片,给他们留言。你还可以在餐厅的排队等候区放置一个大屏幕,让大家用手机就可以在屏幕上弹幕,让餐厅变成一个又好吃,又好玩的场景,客人等餐的时候也不会不耐烦。
第六,也是最后一点,就是要像App一样,重视反馈。说到这,通过用户反馈做的最成功的产品恐怕就是小米了,小米的系统就是根据用户的不断反馈研发出来的,上市之后大获成功。其实线下的场景也非常需要用户的反馈,比如说现在很多小鲜肉明星就经常向粉丝发起各种投票,甚至会按照粉丝的建议修改发型。还有服装店,也可以让用户做主,决定店里的 员工穿什么样的工作服等等。
总的来说,线下企业想和互联网公司学几手,做一个App还只是皮毛功夫,领悟到了内容、游戏、跨界合作、社交、分享和反馈这六个要素,才算是学到了家。
本文源自:微信公众号“李叫兽”(场景营销:互联网不是搞个App就可以了)
52|互联网诞生:互联网的本质是什么?
吴军·科技史纲60讲
03-07
进入课程 >
52|互联网诞生:互联网的本质是什么?
11:43 16.09 MB
转述:宝木
Apollo18,你好!
欢迎来到我的《科技史纲60讲》。
自二战以来,人类历史上再也没有出现像牛顿和爱因斯坦这样全能型、创造奇迹的科学家,但是科学和技术进步的速度都远远超越前代。我在构思这门课的大纲时就发现,课程一开始的内容是以十万年为颗粒度展开的,然后就是以千年纪的最高成就为中心展开的,接下来是世纪也就是百年,等到进入了20世纪之后,就是以10年为单位了。科技进步的速度是越来越快,这就是我在课程开篇告诉你的,科技的正循环一旦开启,就是一个不断放大的过程,人类获得的收益也是不断叠加的。
二战后的科技成就非常多,即使是挑那些最重要讲,也很可能讲不完。因此接下来的内容,我们重点讲解看懂科技进步的线索,这样大家能够更好地理解当下技术革命的主线,把握住以后的趋势。
对21世纪以及未来产生最大影响的发明,恐怕就是互联网了。互联网你再熟悉不过了,但如果问你,互联网的本质是什么?恐怕一千个人会给出一千个答案,有人可能会想到网络连接,愿意往更基础的层次思考的人,会想到通信。这里我给出一个最为根本的理解,那就是:以信息换能量。
这一讲,我就从互联网的诞生和对当下影响最大的电商产业,一头一尾来分析一下信息换能量的本质,希望可以帮你提纲挈领地把握住当今的科技趋势。
互联网的诞生其实就是人们通过信息节省能量的结果。为什么这么说?这就要回到上个世纪60年代,看看最初人们倡导建设它的目的了。
1962年,美国国防部高级研究计划署(简称ARPA)的一位负责人利克里德(J.C.R.Licklider)决定在学术界内搞一项便民措施,他没有想到这个便民措施后来变成了改变世界的互联网。
当时计算机非常贵,美国70%的大型计算机都是由高级研究计划署这个具有军方背景的机构出资支持购置的,集中分布在几个靠近某些大学的超级计算中心里面。那时全美国其他的科学家要使用这些计算机就要出差到当地工作一段时间,这样不仅费时费力,而且费用自然低不了。
1996年我到美国时,和我同宿舍的一位土木工程系的博士生,因为要利用匹兹堡的超级计算机,就由导师出钱,暑假在那里培训了两个多月,然后回来通过互联网远程登录使用。那时美国的互联网已经非常发达了,但是使用超级计算机依然不容易,而更早的30年前,就更加麻烦了,科学家们在计算中心附近常常一住就是半年。
为了方便美国的科学家使用数量不多的超级计算机,美国国防部高级研究计划署决定建立一个网络,让大家远程使用计算资源。1967年,罗伯茨接替利克里德成为高级研究计划署的项目经理,开始将这个想法付诸实施。
这个网络被称为“阿帕网”(ARPANET),就是高级研究计划署的缩写和网络这个词放在一起的合成词,这就是互联网的前身。因此,从互联网的诞生来看,它的目的很明确,就是用信息手段节省能量。
转眼到了上个世纪 80 年代,美国国家科学基金会(National Science Foundation,简称 NSF)在阿帕网原有基础上进行大规模的扩充,形成了NSFNET,这就形成了大规模广泛连接的互联网。
美国国家科学基金会的性质和我国的同名称组织差不多,是完全没有军方背景,支持基础研究的政府基金部门。它建设这个网络的直接目的是为了方便研究人员(主要在大学里)开展学术交流活动和跨部门合作。
在此之前,大家进行学术交流和远程合作,依然要靠出差。由于是为了科研,美国国家科学基金会提供了网络运营的费用,让大学教授和学生们免费使用,这个免费的决定定下了今天互联网免费的传统。
至于为什么自然科学基金会愿意掏钱让学校里的人免费使用,其实如果算一笔经济账,它并不亏,因为大学的科研经费很大一部分来自于它,与其让教授和学生们把经费中很大一部分用于差旅,还不如一劳永逸地建设网络,因此自然科学基金会其实也是在做信息换能量的事情。
到了20世纪80年代末,一些公司看到了互联网带来的便利,也希望接入互联网,当然自然科学基金会没有义务为它们买单,于是出现了商业的互联网服务提供商。不过,由于互联网最初的规定不允许在上面从事商业活动,比如做广告卖东西,因此这又导致互联网的发展并不快。
互联网从上个世纪90年代开始快速发展,得益于美国政府退出对互联网的管理。1990年,美国国防部高级研究计划署首先退出了对互联网的管理,五年后自然科学基金会也退出了。从这时起,整个互联网迅速开始商业化,大量资金的涌入,使得互联网开始爆炸式地增长。
互联网的发展说明,政府需要在技术发展的初级阶段,出资扶植那些一时难以产生的新技术,而当技术成熟,可以靠市场机制发展时,政府就不应该继续扶持了。
世界其它国家互联网的发展历程和美国非常类似,欧洲在上个世纪60、70年代,开始了早期互联网的研究。
中国今天虽然是互联网大国,但是当时的起步却较晚,而最初的发展,也和科研有关。20世纪90年代初,诺贝尔奖获得者丁肇中教授和中国科学院高能物理研究所开展了科研合作。
开始的时候,双方只能通过信件、电话和传真进行合作,有些实验结果可以在电话里讲(当时国际长途大约是一分钟100多元人民币),但是大量的数据只能通过邮政快递来传送,既浪费时间,成本还高。
为了方便双方每天及时汇报交流实验结果,经科学家们建议,有关部门特别批准,高能物理研究所正式开通了一条64KB/s 的专线,直连美国斯坦福大学直线加速器中心(SLAC),这样中国就和互联网开始联系起来。
1994年初,高能物理研究所允许该研究所之外的少数知识分子在审批合格之后使用该网络,于是中国社会就第一次接触了互联网。
当时我的同事、清华校园网的负责人李星教授得知这个消息,就在第一时间告诉了我。我当然资质不够,就用我父亲的资质申请了一个互联网账号,成为了中国第一批网民。
当时给我的注册邮箱依然是斯坦福直线加速器中心的,因此很多人奇怪为什么我的邮件都是从斯坦福发出的。而当时的网速是每秒钟1.2KB(150字节),因此查看一封邮件需要先花大约十分钟下载到本地再慢慢看。但是,即便这样,也比和国外同行通过写信进行学术交流方便了很多。
1998年,我在约翰·霍普金斯大学获得硕士学位,毕业典礼的主讲嘉宾是联邦快递的总裁,他回顾了1968年史密斯(Frederick W.Smith)想要创建该公司(公司直到1971年才成立)的初衷--24小时内将任何文件送抵世界每一个角落。
当时波音707已经能完成横跨太平洋的飞行,因此当时他们觉得利用飞机传递信息是最有效的。而30年后,互联网做到同样的事情,不到一秒钟,这就是信息换能量带来的便利。
互联网的后续发展大家都很熟悉,我就不多讲了,我们只讨论一下,在互联网技术的帮助下,产生了很多对我们今天生活影响巨大的新产业,比如发展最为迅速的电商,电商为什么发展迅速?这从本质上来讲,也是信息换能量的结果。
大家买东西有两个办法:第一个是到商店里去买,这要消耗能量,当然也要花费时间精力,第二个是网购,这样从自身来讲消耗的能量和精力要少很多。从商家来讲,信息推广的成本要低很多,因此即使给你送货上门,在经济上也是合算的。最后综合算下来,由于统一配送还是省了很多能量。
有了互联网后,世界上就诞生了一大批宅男宅女。虽然这类人过去也有,但是数量远远无法和今天相比,为什么会产生这样的结果呢?我问了很多有这样生活习惯的人,他们给我的答案中的一致之处是,因为足不出户可以全知天下事,而且可以和网上的朋友沟通,并不孤独,因此“懒得”出门。
这从本质上,是通过信息节省了能量。坦率地讲,人多少都有点懒筋,懒得费力或许植根于我们的基因。
要点总结:
- 我们通过用信息换能量,讲述了互联网的本质,分析了为什么电商受到广泛的欢迎。
- 互联网的诞生,最初始于计算资源的缺乏,使得大家不得不集中使用少量的超级计算中心的资源。因此,互联网其实是源于遇到困难解决困难的做事方法。
- 从今天的内容我们作一个延伸,为什么在互联网发达后云计算兴起了?因为它提供了一个让个人得以利用大公司巨大计算能力和存储空间的可能性。这和当年远在美国各个大学和研究机构的科学家们得以利用超级计算中心的资源是如出一辙的。
- 商业化对技术推广的作用。很多技术,在它还完全无法盈利时,要靠政府扶持,但是一旦可以盈利之后,政府就应该退出,让市场机制发挥作用。美国政府对科研经费的发放有一个明确的原则,就是不和企业界竞争,只支持那些短期无法见效的科研。
思考题:
如果10000年后我们发现在距离地球1000光年的地方有另一个和地球一样宜居的星球,人类移居到那个星球最便捷的方式是什么?
预告:
下一讲我们介绍互联网的第二个阶段,移动互联网。
53|移动互联网:前赴后继的移动通信之路
吴军·科技史纲60讲
03-08
进入课程 >
53|移动互联网:前赴后继的移动通信之路
12:25 17.06 MB
转述:宝木
Apollo18,你好!
欢迎来到我的《科技史纲60讲》。
上一讲我从互联网的诞生为你分析了互联网的本质,那是互联网发展的第一阶段。这一讲,我会通过发明的预先要求和自然结果,讲讲互联网发展的第二个阶段——移动互联网。也就是基于移动通信的互联网,从设备上来说就是手机互联网,你可能会说,不就是在“互联网”前面加上了“移动”两个字么?
但是要实现“移动互联网”,是需要满足四个预先要求的:
移动通信技术
低功耗半导体技术
互联网技术
操作系统
我们不妨对它们一一分析一下。
先看移动通信技术是如何被解决的。
在二战之前,世界上单点对单点的通信大多是有线的,因为有线通信很容易实现,莫尔斯最早的电报也是有线传输的。这时你可能意识到了,要想实现“移动通信”,就必须摆脱有线,实现“无线”。
其实无线电技术早已发明出来,但是由于没有技术实现长距离的无线电通信,因此无线电通信只能在固定的基站之间进行,或者从基站向四周进行广播,比如收音机就是这样工作的。这种通信方式虽然是无线的,但却还是单向传播,而且传输距离也非常有限。
所以,如果要进行点对点的双向远距离通信,关键在于提高单位功率的信息传输率。我们今天说的移动通信,第一代、第二代即2G,第三、四代,即3G、4G,一直到未来的5G,从本质上讲,就是提高了单位能量的信息传输率,这和摩尔定律提高单位能量的信息处理能力非常类似。
那么如何提高单位能量的信息传输率呢?第一个历史性的突破可以追溯到二战期间,那主要是出于战争的需要。
当时美国军方已经认识到无线电通信的重要性,因此在战争尚未开始,就研制起便携式无线通信工具来了。要提高无线通信的传输功率,人们很自然地就会把设备做得又大又重,再加上长长的天线,最初的无线电设备都是如此。
美军研制出一款报话机(Walkie-Talkie)SCR-194 ,1938年开始装备,在二战期间广为使用。当时做汽车收音机起家的摩托罗拉公司有一些工程师参与了这项研究。
他们继续开展研究,1940年,摩托罗拉接到军方合同,开始研制报话机SCR-300,它既是一个无线电接收机,也是发射机,可以进行双向通信,这让战场上的指挥和通讯变得实时有效了。
1942年春,SCR-300最终通过了用户验收。从下面的图片可以看出,它又大又重,根本无法民用。
摩托罗拉公司再接再厉,还研制出了“手提式”的对讲机(Handy-Talkie)SCR-536,这比报话机SCR-300已经小了很多,至少能“手提”了,但是通信范围还是不够广,在开阔地带通信范围是一公里半,在树林中只有三百米。即使如此,这也让当时的美军在通信上高出其它军队一大截。
你可以看出它和早期的“大哥大”样子非常像。
到了上个世纪60年代,摩托罗拉深度参与了阿波罗登月计划,并且提供了登月所需的通信设备,这时它的移动通信技术遥遥领先于世界。
1967年在纽约的全球消费电子展(也就是今天拉斯维加斯的CES展)上,它展出了民用的移动通信设备,但是当时的价格和性能其实还达不到实用的水平。
到了20世纪80年代,移动电话才真正开始民用。当然,要联入已有的电话网络,并且能够拨打任何号码,就不可能像对讲机那样只考虑点对点的通信,而需要建立很多基站,让无线信号能够覆盖人们活动的区域,实现多点对多点的无线通信。
工程师们从数学上很容易推算出来,把无线通信的网络修建得像蜂窝那样呈六角形分布,相互重叠,是最为经济有效的。因此,民用的移动通信又被称为蜂窝式移动通信,今天我们说的“手机cellphone”,就是“蜂窝cellular”和“电话telephone”两个词的组合。
移动电话刚出来时,在这个领域,民用通信之争集中在AT&T公司和摩托罗拉之间,AT&T公司的主营业务是固定电话,因此它认为家庭内的无绳电话是未来发展的方向,而以移动通信见长的摩托罗拉则看准了移动电话。
当时AT&T认为,即便发展20年,到2000年,全球使用移动电话的人数也不会超过一百万,结果它少估计了一百倍。这样,AT&T就将全球第一代移动电话的主导权拱手让给了摩托罗拉。
不过,摩托罗拉的辉煌没有持续太久,因为很快第二代移动电话(又称为2G)开始起步了。
第二代移动电话一方面采用了新的通信标准,另一方面将很多过去通用的芯片重新设计,做成一个专用集成电路,使得手机的体积和功耗都大大降低,这都得益于半导体技术的发展,也就实现了移动互联网的第二个预先要求。
好,我先说新的通信标准为什么让摩托罗拉失败,这也是美国在第二代移动通信标准上最终没有竞争得过欧洲的原因。
当时欧洲为了和美国竞争,运营商和设备制造商最终达成了一致,形成了一个统一的2G移动通信标准GSM,而美国一个国家却搞出了三个标准。因此,欧洲的诺基亚就成为了2G通信最大的赢家,它一度占据近一半的全球手机市场。
从这里也可以看出在通信领域标准的重要性。这也是今天美国和西方很多国家联合起来围剿华为的动机。
虽然通信标准基本是统一或者彼此兼容了,但是由于当时的半导体技术做不出功耗比PC机处理器小一个数量级,而功能相当的处理器,因此不可能在手机上完成过去由PC机才能完成的任务。
随着半导体工艺制程的提升,移动处理器性能越来越强大,越来越支持多媒体,因此也就逐步替代了很多PC的使用场景,这才为迈向移动互联网提供了硬件基础。
但是半导体技术的成熟,造成的结果却是摩托罗拉连在硬件上的先发优势也丢了。从能耗上讲,第二代移动通信电话比第一代降低了一个数量级,而通信的速率却提高了半个到一个数量级。你可以将它理解成单位能耗传输的信息量增加了50倍~100倍。
2G的普及给诺基亚和三星这样后进入行业的公司机会,得以后来居上,而固守原有技术和市场的摩托罗拉则开始落伍了。
然而,随着3G时代的到来,在2G时代辉煌一时的诺基亚,其发展也戛然而止了。因为2007年,苹果的iPhone诞生了,第二年,数量更多、更便宜的各种安卓手机出现了。
作为计算机公司的苹果和Google,进入移动通信市场后,与其说是做了一部功能更强的移动电话给用户,不如说是提供了一台微型计算机。
更关键的是,3G是以互联网和云计算为核心的新时代,接入互联网的高性能手机真正实践了“移动互联网”,所以互联网技术是第三个预先要求。
在此之前,手机作为通信工具在2G的时代已经开始普及,但是,那时的移动通信和互联网没什么关系,人们只是用手机打电话、发短信而已,要想实现用手机上网,完成多媒体数据的传输,就需要传统通信业和IT产业的结合,最终它们形成一个巨大的移动互联网产业,当然,这都是在3G之后的事情。
很多人觉得2G时代网速不够,无法形成移动互联网,事实并非如此。实际上在2000年之前高通公司基于CDMA的标准就足以让无线上网的速度达到除了看视频之外全部移动互联网的要求。
世界上绝大多数移动运营商并没有采用这种标准,是因为当时不可能有移动互联网的应用需求,超前提高无线网速完全是浪费。也就是说,是人们在实现了通信基本需求之后,才产生了对移动互联网更多元的需求。
移动互联网的第四个预先要求是通用的操作系统,这件事在2008年前后已经完成了。
虽然在一开始有五种操作系统,除了今天的安卓和iOS,还有诺基亚的塞班、微软的视窗,和黑莓自己的系统,彼此各不兼容,但是随着安卓一统天下,这个问题也就解决了。如果有五个操作系统,那么App的开发者开发的成本极高,移动互联网是发展不起来的。
在上面四个条件具备之后,移动互联网的便利性使得它以比传统互联网更快的速度发展,并且在用户规模上超过了传统的互联网。这时,手机的语音通话功能反而变得不重要,重要的是无线上网。
到了接下来的4G时代,通过移动设备上网的通信量(总的数据量)甚至超过了同时期通过PC上网的通信量。
2007年当苹果推出智能手机时,全世界互联网上信息传播的速率是每秒钟2TB,而到了2016年,增长到27TB(数据来源:思科公司年度网络指数报告),这里面大部分增量都是移动互联网贡献的。
而这个变化,也撑起了全球巨大的电信市场。2016年,全世界互联网的产值(包括Google、Facebook、亚马逊、中国的BAT等公司)是3800亿美元,而电信市场(包括移动设备、电信设备,以及运营商收入)的产值高达3.5万亿美元。
那么移动互联网的本质是什么?从某种角度上讲也是信息换能量,而且是以一种更有效的方式。
高效在哪里呢?移动互联网比互联网可以帮助我们少做很多无用功,比如你想在网上订一辆出租车,却无法定位,你只好走到一个双方都熟知的地点等待,这就要耗费能量。现在有了移动互联网,你就可以随时随地叫车了。
要点总结:
- 我们分析了移动互联网出现的预先要求,你能看到它是关键性技术突破后的必然结果。
- 我们再次看到战争包括冷战对技术的推动作用。
- 我们从信息带来的便利性的角度,简单分析了移动互联网比传统互联网在节省能量方面的优势。
- 我们展示出每一次技术革命通常都会更换一个领导者,关于这一点,大家可以参考拙作《浪潮之巅》,里面有详细的分析。
思考题:
今天留给大家的作业就是进一步找出一些移动互联网起步必需的基本技术,完善移动互联网发展的技术依赖图。除了上面我提到的技术,我再给大家几个提示,锂电池技术、射频技术、Wi-Fi技术、触屏技术等等。
预告:
互联网发展的第三个阶段就是万物互联。这是我下一讲要给你讲的内容。
54| IoT:万物互联到底是什么意思?
吴军·科技史纲60讲
03-09
进入课程 >
54| IoT:万物互联到底是什么意思?
10:30 14.42 MB
转述:宝木
Apollo18,你好!
欢迎来到我的《科技史纲60讲》。
我在前面谈到了使用PC机的互联网和移动互联网的发展,它们可以被看成第一代和第二代的互联网。那么如果要问接下来的互联网是什么,那就是万物互联,即IoT。一些媒体把它翻译成“物联网”,这个翻译其实不准确,因为它不只是物和物的联网,而是所有东西的联网。
万物互联和前两代互联网有什么差别呢?我们还是从联网对象的本质着手分析。
第一代互联网从本质上讲是计算机和计算机的联网。从一开始,它就是远程终端和超级计算中心大型机之间的联网,后来演化成个人的电脑通过服务器彼此相连。每一个使用互联网的人,身份只有通过账号加上IP地址来确认,或者说人是通过互联网间接相连的。
20年前,你上班登录邮箱查看邮件,或者登录QQ聊天。下班离开了计算机,开车回家或者坐地铁回家,就离开了互联网。直到你吃完晚饭,做完家务事,再坐回到计算机旁边,才算是回到互联网上。
第二代互联网的本质是人和人的相连。虽然从形式上讲,联网的设备由过去的PC变成了智能手机,但是,每个人要找的不是对方某个手机,而是要找对方那个人。当你见到一个新的朋友,提出要扫一下微信二维码时,不是为了让你的手机能够连接上对方那台手机,而是要随时找那个人。
这样除了带来便利性,还带来两个结果。其一是网络上的人和真实的人基本上是一致的,而不至于像在PC互联网时代,QQ后面的人很多都是虚拟的。这种一致性使得移动支付成为了可能,因此这种支付方式必须确认真实身份,而移动互联网绑定的都是真实的人。
其二是网上的行为和线下的生活融合。今天,打车,线上线下相结合的电子商务,人的定位,都和它有关。因此,以移动互联网为特征的第二代互联网在连接人的方面进了一大步。
第三代互联网是万物互联。虽然从连接的对象看,加入了各种东西,包括带有可跟踪设备的智能物件,也包括可被监控范围内的所有东西,但是从连接的本质上看,是由孤立的、不连续的连接,变成可以全程跟踪的、任何时刻的连接。而在这些连接中,人依然是一个中心,虽然不再是唯一的中心。
我在《智能时代》举了几个万物互联的例子,比如美国的一家经过智能改造的酒吧,它可以跟踪每一个服务员每一次倒酒的细节,几月几号,几点几分,哪种酒倒了多少。通过这种跟踪,可以杜绝“偷酒”的行为,而之前美国酒吧平均23%的酒是被酒保“偷”掉了。
今天任何一架商用客机的发动机,里面都有一千多个传感器,对发动机的各种工作情况,包括外部条件,比如空气的温度和湿度,都进行随时的监控,每次飞行产生的数据都有好几百G,比如波音787飞机每次起降产生500GB的数据(所有的数据总和)。这样一来,一旦发动机有了小的故障,都能及时发现并且定位问题所在。
类似地,特斯拉汽车里面有几百个传感器监控汽车运行的情况,并进行行车记录,包括司机有没有好好扶把,是不是在打手机等细节。特斯拉汽车一旦出现问题,厂家可以马上定位问题的原因,而不需要像其他汽车维修中心那样先花一两个小时找原因,甚至半天找不到原因。
从上面三个例子可以看出,万物互联远不是简单地用某个智能设备控制一下家里的智能家电,或者通过手环等可穿戴式设备把心跳、睡眠情况等信息输入到手机中那么简单,甚至要超出带有机器学习功能的智能空调、智能照明等IoT的应用。它具有全时段跟踪每一个细节的特点,因此会导致跟踪经济的产生。
关于跟踪经济,大家可以参考拙作《见识》一书。到目前为止,万物互联对人身体状况的监控、跟踪才刚刚开始。2012年,Google推出一款能够监控血糖的隐形眼镜,其实就是对人身体简单的监控。今天的心脏起搏器,也一直在监控人心脏的搏动以及导致搏动变化的身体变化。
但是,到目前为止,这些都是针对少数特定人群的,对于大部分人,我们身体中没有任何监控,以至于身体出现异常,比如疾病,我们有时很难诊断。
今天,我们一方面对汽车、飞机,甚至家电有深入到细节的监控和跟踪,以便及时发现问题和修理,但是对我们自身的新陈代谢却没有,以至于对生病的“先兆”并不敏感,许多人得了癌症,等发现的时候往往已经是晚期了。
万物互联在很大程度上要解决的就是这个问题。我在《硅谷来信》中介绍过从事早期癌症检测的Grail公司所做的事情,就是通过测量血液中的基因,监控身体内是否有癌症病变。这其实也是万物互联的一部分——通过某种技术方式,将我们的身体连到了监控系统中。
此外,使用RFID标签实现商品的跟踪,无人售货等等,也是万物互联的应用。
概括来讲,万物互联从两个维度扩展了互联网,一个是时间维度,从我们过去断断续续的连接,变成全时段的跟踪;另一个是空间维度,将我们能够想象到的各种物品连到网络中。这样一来互联网的规模就大了。IoT绝不是说,过去有个互联网,今天再来一个把东西(things,或者说是物)连在一起的网络。
IoT的规模会有多大呢?最保守地估计,会有500亿个设备(包括我们人自身连到网络中),比较大胆地估计,能有上万亿的设备连入网,当然这其中很多是带有RFID的商品,在网上只是短暂停留。
相比之下,前两代互联网的规模就小得多。第一代互联网大约有10亿台计算机联入了网络,第二代大约有50亿个设备(包括计算机、手机和一些可穿戴式设备)。也就是说,从第一代到第二代,大约大了一个数量级,从第二代到第三代,还将大一个数量级。
这么多的设备,形成的经济规模是极为可观的,最保守地估计,也应该有今天电信市场规模的两倍,即7万亿美元以上。
那么,万物互联什么时候能够像今天移动互联网一样普及呢?我们还是从预先要求开始入手分析。今天,移动通信的技术和网速对它来讲都不是问题,今天的5G完全可以解决万物互联的通信问题。但是接下来有三个瓶颈问题需要解决。
首先是能耗足够低的处理器。今天的手机比PC的单位能耗性能提升了一个数量级左右,如果按照这个要求设计IoT的芯片,需要把能耗降低十倍左右。
目前比较通行的方法有两个,一个是设法降低芯片的工作电压,比如如果能从现在手机的3V(伏)降低到1V,就能节省90%左右的电量。另一个方法是用更专用的芯片取代目前较为通用的芯片。在这两方面,现在都有不错的进展。但是这还只是必要条件之一。
其次是需要有一个合适的操作系统,将这么多设备管理好,这个目前还没有。
第三则是要有合适的商业模式,目前也没有找到。没有从商业上获得利润继续投入这个产业,它就很难快速发展。
由于现在的很多条件还不具备,因此万物互联的时代不会一天到来。
如果万物互联真的来了,谁将是下一个微软或者Google,英特尔或者ARM公司呢?目前还看不出苗头,不过从目前的技术准备来看,华为在通信标准和设备上有一定优势。而在处理器方面,反而是开发安卓系统的Google准备得最充分。
在控制了移动互联网的操作系统之后,Google就在布局IoT。它请来了RISC系统结构(今天手机使用的ARM芯片,用的就是RISC系统结构,关于它,大家可以阅读《Google方法论》)的发明人、著名的计算机科学家帕特森(David Patterson),负责了开源(芯片)设计项目(Open Source Design)。
它相当于是开源版的ARM,在此基础上,各个厂家可以设计自己的专业芯片。帕特森讲,现在谁加入到新一代芯片的设计上,谁就有可能获得图灵奖。目前已经有很多小的芯片设计公司在Google开源设计的基础上,在开发IoT的芯片。
要点总结:
- 互联网经历了两代,现在正在开启第三代,也就是万物互联。
- 每一代互联网比上一代,从设备的数量和市场的规模,都会有巨大的增长,这是未来的机会所在。
- 每一代互联网都有掌握产业链的龙头公司,从PC时代的英特尔和微软,到今天的ARM和Google,以及未来掌握核心芯片和操作系统的公司。
- 从能量的角度讲,每一代互联网都是以更少的能量传输和处理更多的信息,这一点是未来发展的方向。
对于这样的问题,我们可以拭目以待。
预告:
下一讲,我们会总结一下到目前为止科技进步的特点。
55|大复盘:用科学方法论指导我们的行动
吴军·科技史纲60讲
03-10
进入课程 >
55|大复盘:用科学方法论指导我们的行动
09:29 13.02 MB
转述:宝木
Apollo18,你好!
欢迎来到我的《科技史纲60讲》。
我们科技史的课程,关于历史的部分已经结束了。在讲述对未来科技发展的展望之前,我们先对前面几个单元的内容作一个复盘。
首先,我们在科学史中强调了科学是一种对世界的态度,是理解世界的观点,和日常做事的方法,而不代表正确,也不限于某些特定的知识和结论。
科学是一种求真的过程,但它不等于真。科学的常识、科学的结论,都会随着时间的推移和科技的进步成为过时的东西,因此没有什么放之四海而皆准的真理,真理都是有局限性的,它们是在一定范围内解决我们的困惑、我们的问题。科学的结论总会过时,成为过去,但是信念永存,方法永存。
那么什么是科学的方法呢?或者说在日常工作中如何主动采用科学的态度、科学的方法做事情呢?
我不妨给你举一个最简单的例子。比如你学习打篮球,有两个教练,第一个教练先教你对大部分人都适用的投篮要领,然后观察你的投篮,根据你姿势中一些不好的动作,告诉你一套可以遵从的方式。
比如提高出手的角度,端正投篮前手扶球的位置,增加腿弯的深度等等,改正你的动作,最后逐渐提高投篮的准确率。虽然你不能保证100%进球,但是知道按照动作要求来做,10个总能进7、8个,悟性差一点,也能进5、6个。
第二个教练教你一个所谓的投篮绝招,手这么一勾就进去了,你学习这个动作,总是学不到家,他会说,勾得太过头了,或者勾得不到位。最后你能否投中全凭运气,投进了他会说你手感不错,投不进去他会说你悟性差。当然,你还从他身上学到一些迷信的动作,比如投篮前用左手摸两下屁股。
这两个教练当然都没有在搞科学研究,但是无意中,第一个人做事是遵循了科学方法的,另一个还是在靠直觉和迷信。遵循科学方法,不等于每次都能投进球,但是你上一次用某个姿势,做某些动作,控制多大的力量和角度投进去了,这次这么做,也能再次成功。
不遵循科学方法,上次摸了两下屁股投进去了,这次就难说了。采用不同的态度做事情,就会得到不同的结果,每次在结果上微小的差别,久而久之的积累,就会产生本质的差别。
我们在课程中介绍了,逻辑对科学发展的重要性,从事实出发,讲究逻辑,得到合理的结论,这就是我们应该遵从的做事方法。
有一次吃饭,一个巨无霸上市公司的女老板挑战我说,我做事就不讲逻辑,只讲原则,讲奉献,讲忠诚,二十多年前接手企业至今,销售增加了近百倍。
我说,你的成功不可复制,不信你问问周围的人谁可以接你的班。人成功一次并不难,就如同投篮进去一样,闭着眼睛一勾手,或许也能进。但是难的是获得可重复性的成功。
世界发展到近代以前也有伟大的科学成就和了不起的发明出现。但那些具有很大的偶然性,一次成功之后,下一次不知道什么时候才能再来。
但是到了近代之后,情况就不同了,各种科学成就不断涌现,各种发明接踵而至,这是因为有了一整套的科学研究方法,而科学家们自觉地使用这种方法论。到了工业革命之后,发明家们也自觉地用理论指导发明。
关于这一点,大家可以回顾课程的《第27讲:为什么是瓦特?》、《第31讲:能量守恒定律:为什么是焦耳?》和《第32讲:发现电的本质》。
这是我在课程结束之前要强调的第一点。
其次,我想告诉你的第二点,是关于当下和未来的一个重要趋势:世界进入近代以来,能量增加的速率在放缓,信息增加的速率在放大。
能量增加放缓的原因,并非人类没有能力产生更多的能量,而是不需要,在人类还不能控制核聚变、不能低成本地获取可再生能源之前,那些便于使用,但是污染和温室效应严重的能量要省着用。
与此同时,信息在科技和经济中权重的增加则是不争的事实,这里面根本的原因在于在进入到信息社会之后,人类有能力通过计算机处理更多信息,用磁媒介和半导体存储更多信息,用光纤更快地传递信息。
在过去的半个多世纪里,人类处理和存储信息的能力每18个月翻一番,这便是摩尔定律。在这半个多世纪里,经济增长的主要动力都来自于此,如果我们将摩尔定律对各行各业的改进所带来的GDP扣除,世界的GDP不是增长而是倒退。
在未来的十几年里,尽管半导体集成电路的集成度(密度)不会再像过去那样迅速增加,但是,芯片处理信息的能力还会快速增加。
同时,今天全世界每三年数据量就将翻一番,也就是说,最近三年里产生的数据总量,超过了三年前到有文字记载以来数据量的总和,因此信息在科技和经济中的地位还将进一步增加。而我们无论从事什么行业,想获得进步都需要利用好信息。
我们在课程中还从信息和能量结合的角度,分析了摩尔定律的本质,即单位能耗处理信息能力的增加,这其实是在过去的几十年里,IT行业硬件进步最核心的主线。没有这个方向的进步,今天即使把全世界的能源都用上,也不能支持AlphaGo和李世石下棋的用电量。这条主线,给行业的从业者指明了一生应该努力的方向。
但是一个现实问题是:为什么同样是从事IT行业的人,有的人十多年甚至更长的时间,都能做得顺风顺水,有的人天天忙活,却如同无头苍蝇乱撞,或者像是在森林里走路转一圈又回到原点,他们之间的区别在哪里呢?
IT行业中从事软件工作的,要把握好最关键的一条主线,就是安迪-比尔定理,搞软件开发的,一定要通过提供给用户更多的功能,将硬件提升的性能抵消掉,否则大家就不会买新的硬件了,也就不会再装新的软件了,大家就都没饭吃了。我在《见识》一书中讲,商业的本质是让大家多花钱,而不是省钱,也是同样的道理。
同样,在其它行业的发展中也有这样的主线,把握主线的能力是最根本的生存之道。
第三,我希望通过这门课,能够让我们更加全面客观地看待一些事情。
我们在课程中多次讲了战争对科技进步的帮助。我们都知道战争不是什么好东西,但是因为战争涉及到生死存亡,参战的一方或者双方才能把能量集中到一点,实现很多技术临门一脚的突破。我们在课程中举了很多例子,从原子能到计算机,从青霉素到航天,都是如此。
通过这些事情,我们能得到什么启发呢?当然不是去发动战争,而是在做事情的时候,要把能量集中到一点上,形成局部很高的能量密度,实现突破。我经常讲做减法,少做事,就是这个道理。
最后,我们在课程中讲了进入20世纪后,人类对于不确定性这件事情的认识。
我们从物理学危机开始讲起,讲述了爱因斯坦和玻尔等人对超出我们生活经验的世界的认识过程,特别讲述了不确定性是世界固有的本质,以及对于不确定性这件事,人类接受的过程。
在二战后,出现了所谓的“三论”,即控制论、信息论和系统论,它们是新时代的科学基础和方法论。我们今天所说的大数据思维、互联网思维,不仅仅是炒作概念,而是有科学基础的。在新的时代,需要掌握新的方法论。
虽然在历史上人类曾经不断追求可预测性和确定性,虽然我们都喜欢确定性而不喜欢不确定性,但是面对真实的、充满不确定性的世界,我们需要积极地应对。新时代的方法论,就给了我们行动指南。
ProtoSchool

该网站有各种原创的分布式互联网协议教程。
互联网协议入门
作者: 阮一峰
日期: 2012年5月31日
我们每天使用互联网,你是否想过,它是如何实现的?
全世界几十亿台电脑,连接在一起,两两通信。上海的某一块网卡送出信号,洛杉矶的另一块网卡居然就收到了,两者实际上根本不知道对方的物理位置,你不觉得这是很神奇的事情吗?
互联网的核心是一系列协议,总称为”互联网协议”(Internet Protocol Suite)。它们对电脑如何连接和组网,做出了详尽的规定。理解了这些协议,就理解了互联网的原理。
下面就是我的学习笔记。因为这些协议实在太复杂、太庞大,我想整理一个简洁的框架,帮助自己从总体上把握它们。为了保证简单易懂,我做了大量的简化,有些地方并不全面和精确,但是应该能够说清楚互联网的原理。
一、概述
1.1 五层模型
互联网的实现,分成好几层。每一层都有自己的功能,就像建筑物一样,每一层都靠下一层支持。
用户接触到的,只是最上面的一层,根本没有感觉到下面的层。要理解互联网,必须从最下层开始,自下而上理解每一层的功能。
如何分层有不同的模型,有的模型分七层,有的分四层。我觉得,把互联网分成五层,比较容易解释。
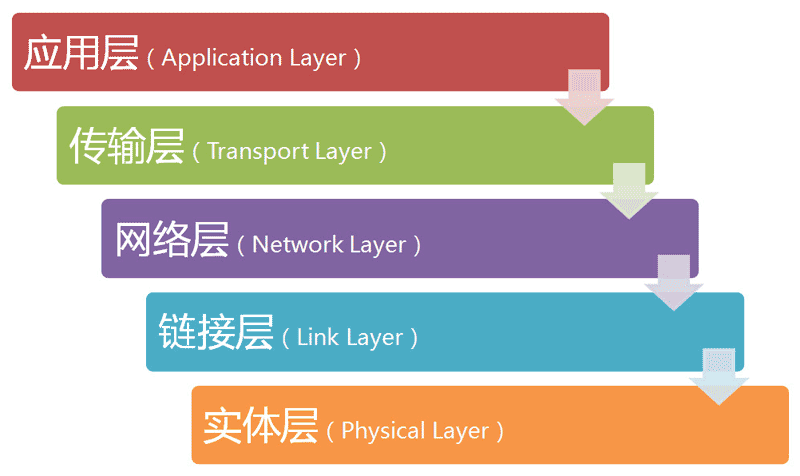
如上图所示,最底下的一层叫做”实体层”(Physical Layer),最上面的一层叫做”应用层”(Application Layer),中间的三层(自下而上)分别是”链接层”(Link Layer)、”网络层”(Network Layer)和”传输层”(Transport Layer)。越下面的层,越靠近硬件;越上面的层,越靠近用户。
它们叫什么名字,其实并不重要。只需要知道,互联网分成若干层就可以了。
1.2 层与协议
每一层都是为了完成一种功能。为了实现这些功能,就需要大家都遵守共同的规则。
大家都遵守的规则,就叫做"协议"(protocol)。
互联网的每一层,都定义了很多协议。这些协议的总称,就叫做”互联网协议”(Internet Protocol Suite)。它们是互联网的核心,下面介绍每一层的功能,主要就是介绍每一层的主要协议。
二、实体层
我们从最底下的一层开始。
电脑要组网,第一件事要干什么?当然是先把电脑连起来,可以用光缆、电缆、双绞线、无线电波等方式。

这就叫做”实体层”,它就是把电脑连接起来的物理手段。它主要规定了网络的一些电气特性,作用是负责传送0和1的电信号。
三、链接层
3.1 定义
单纯的0和1没有任何意义,必须规定解读方式:多少个电信号算一组?每个信号位有何意义?
这就是”链接层”的功能,它在”实体层”的上方,确定了0和1的分组方式。
3.2 以太网协议
早期的时候,每家公司都有自己的电信号分组方式。逐渐地,一种叫做”以太网"(Ethernet)的协议,占据了主导地位。
以太网规定,一组电信号构成一个数据包,叫做”帧”(Frame)。每一帧分成两个部分:标头(Head)和数据(Data)。

“标头”包含数据包的一些说明项,比如发送者、接受者、数据类型等等;”数据”则是数据包的具体内容。
“标头”的长度,固定为18字节。”数据”的长度,最短为46字节,最长为1500字节。因此,整个”帧”最短为64字节,最长为1518字节。如果数据很长,就必须分割成多个帧进行发送。
3.3 MAC地址
上面提到,以太网数据包的”标头”,包含了发送者和接受者的信息。那么,发送者和接受者是如何标识呢?
以太网规定,连入网络的所有设备,都必须具有”网卡”接口。数据包必须是从一块网卡,传送到另一块网卡。网卡的地址,就是数据包的发送地址和接收地址,这叫做MAC地址。

每块网卡出厂的时候,都有一个全世界独一无二的MAC地址,长度是48个二进制位,通常用12个十六进制数表示。

前6个十六进制数是厂商编号,后6个是该厂商的网卡流水号。有了MAC地址,就可以定位网卡和数据包的路径了。
3.4 广播
定义地址只是第一步,后面还有更多的步骤。
首先,一块网卡怎么会知道另一块网卡的MAC地址?
回答是有一种ARP协议,可以解决这个问题。这个留到后面介绍,这里只需要知道,以太网数据包必须知道接收方的MAC地址,然后才能发送。
其次,就算有了MAC地址,系统怎样才能把数据包准确送到接收方?
回答是以太网采用了一种很”原始”的方式,它不是把数据包准确送到接收方,而是向本网络内所有计算机发送,让每台计算机自己判断,是否为接收方。
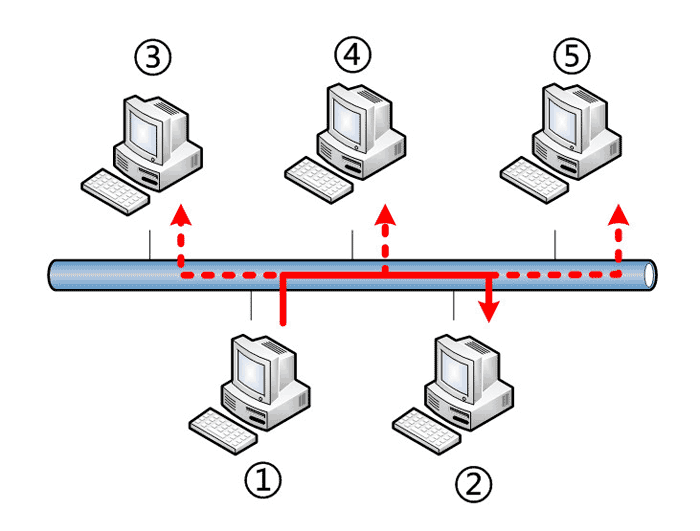
上图中,1号计算机向2号计算机发送一个数据包,同一个子网络的3号、4号、5号计算机都会收到这个包。它们读取这个包的”标头”,找到接收方的MAC地址,然后与自身的MAC地址相比较,如果两者相同,就接受这个包,做进一步处理,否则就丢弃这个包。这种发送方式就叫做”广播”(broadcasting)。
有了数据包的定义、网卡的MAC地址、广播的发送方式,”链接层”就可以在多台计算机之间传送数据了。
四、网络层
4.1 网络层的由来
以太网协议,依靠MAC地址发送数据。理论上,单单依靠MAC地址,上海的网卡就可以找到洛杉矶的网卡了,技术上是可以实现的。
但是,这样做有一个重大的缺点。以太网采用广播方式发送数据包,所有成员人手一”包”,不仅效率低,而且局限在发送者所在的子网络。也就是说,如果两台计算机不在同一个子网络,广播是传不过去的。这种设计是合理的,否则互联网上每一台计算机都会收到所有包,那会引起灾难。
互联网是无数子网络共同组成的一个巨型网络,很像想象上海和洛杉矶的电脑会在同一个子网络,这几乎是不可能的。
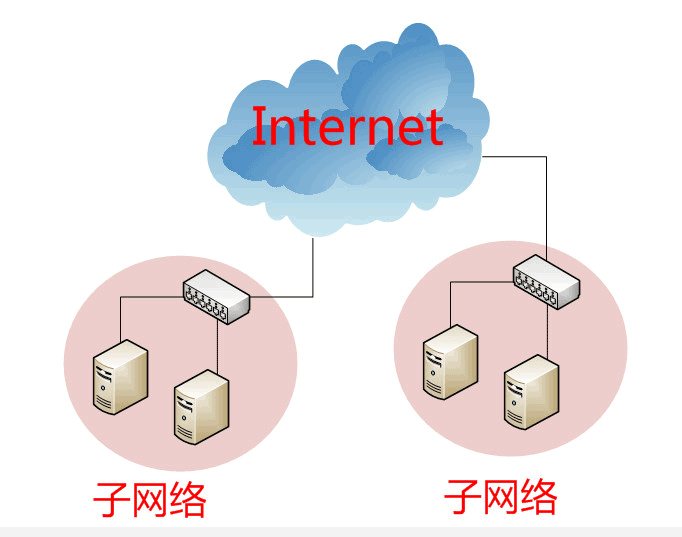
因此,必须找到一种方法,能够区分哪些MAC地址属于同一个子网络,哪些不是。如果是同一个子网络,就采用广播方式发送,否则就采用"路由"方式发送。(”路由”的意思,就是指如何向不同的子网络分发数据包,这是一个很大的主题,本文不涉及。)遗憾的是,MAC地址本身无法做到这一点。它只与厂商有关,与所处网络无关。
这就导致了”网络层”的诞生。它的作用是引进一套新的地址,使得我们能够区分不同的计算机是否属于同一个子网络。这套地址就叫做"网络地址",简称"网址"。
于是,”网络层”出现以后,每台计算机有了两种地址,一种是MAC地址,另一种是网络地址。两种地址之间没有任何联系,MAC地址是绑定在网卡上的,网络地址则是管理员分配的,它们只是随机组合在一起。
网络地址帮助我们确定计算机所在的子网络,MAC地址则将数据包送到该子网络中的目标网卡。因此,从逻辑上可以推断,必定是先处理网络地址,然后再处理MAC地址。
4.2 IP协议
规定网络地址的协议,叫做IP协议。它所定义的地址,就被称为IP地址。
目前,广泛采用的是IP协议第四版,简称IPv4。这个版本规定,网络地址由32个二进制位组成。

习惯上,我们用分成四段的十进制数表示IP地址,从0.0.0.0一直到255.255.255.255。
互联网上的每一台计算机,都会分配到一个IP地址。这个地址分成两个部分,前一部分代表网络,后一部分代表主机。比如,IP地址172.16.254.1,这是一个32位的地址,假定它的网络部分是前24位(172.16.254),那么主机部分就是后8位(最后的那个1)。处于同一个子网络的电脑,它们IP地址的网络部分必定是相同的,也就是说172.16.254.2应该与172.16.254.1处在同一个子网络。
但是,问题在于单单从IP地址,我们无法判断网络部分。还是以172.16.254.1为例,它的网络部分,到底是前24位,还是前16位,甚至前28位,从IP地址上是看不出来的。
那么,怎样才能从IP地址,判断两台计算机是否属于同一个子网络呢?这就要用到另一个参数"子网掩码"(subnet mask)。
所谓”子网掩码”,就是表示子网络特征的一个参数。它在形式上等同于IP地址,也是一个32位二进制数字,它的网络部分全部为1,主机部分全部为0。比如,IP地址172.16.254.1,如果已知网络部分是前24位,主机部分是后8位,那么子网络掩码就是11111111.11111111.11111111.00000000,写成十进制就是255.255.255.0。
知道”子网掩码”,我们就能判断,任意两个IP地址是否处在同一个子网络。方法是将两个IP地址与子网掩码分别进行AND运算(两个数位都为1,运算结果为1,否则为0),然后比较结果是否相同,如果是的话,就表明它们在同一个子网络中,否则就不是。
比如,已知IP地址172.16.254.1和172.16.254.233的子网掩码都是255.255.255.0,请问它们是否在同一个子网络?两者与子网掩码分别进行AND运算,结果都是172.16.254.0,因此它们在同一个子网络。
总结一下,IP协议的作用主要有两个,一个是为每一台计算机分配IP地址,另一个是确定哪些地址在同一个子网络。
4.3 IP数据包
根据IP协议发送的数据,就叫做IP数据包。不难想象,其中必定包括IP地址信息。
但是前面说过,以太网数据包只包含MAC地址,并没有IP地址的栏位。那么是否需要修改数据定义,再添加一个栏位呢?
回答是不需要,我们可以把IP数据包直接放进以太网数据包的”数据”部分,因此完全不用修改以太网的规格。这就是互联网分层结构的好处:上层的变动完全不涉及下层的结构。
具体来说,IP数据包也分为”标头”和”数据”两个部分。

“标头”部分主要包括版本、长度、IP地址等信息,”数据”部分则是IP数据包的具体内容。它放进以太网数据包后,以太网数据包就变成了下面这样。

IP数据包的”标头”部分的长度为20到60字节,整个数据包的总长度最大为65,535字节。因此,理论上,一个IP数据包的”数据”部分,最长为65,515字节。前面说过,以太网数据包的”数据”部分,最长只有1500字节。因此,如果IP数据包超过了1500字节,它就需要分割成几个以太网数据包,分开发送了。
4.4 ARP协议
关于”网络层”,还有最后一点需要说明。
因为IP数据包是放在以太网数据包里发送的,所以我们必须同时知道两个地址,一个是对方的MAC地址,另一个是对方的IP地址。通常情况下,对方的IP地址是已知的(后文会解释),但是我们不知道它的MAC地址。
所以,我们需要一种机制,能够从IP地址得到MAC地址。
这里又可以分成两种情况。第一种情况,如果两台主机不在同一个子网络,那么事实上没有办法得到对方的MAC地址,只能把数据包传送到两个子网络连接处的”网关“(gateway),让网关去处理。
第二种情况,如果两台主机在同一个子网络,那么我们可以用ARP协议,得到对方的MAC地址。ARP协议也是发出一个数据包(包含在以太网数据包中),其中包含它所要查询主机的IP地址,在对方的MAC地址这一栏,填的是FF:FF:FF:FF:FF:FF,表示这是一个”广播”地址。它所在子网络的每一台主机,都会收到这个数据包,从中取出IP地址,与自身的IP地址进行比较。如果两者相同,都做出回复,向对方报告自己的MAC地址,否则就丢弃这个包。
总之,有了ARP协议之后,我们就可以得到同一个子网络内的主机MAC地址,可以把数据包发送到任意一台主机之上了。
五、传输层
5.1 传输层的由来
有了MAC地址和IP地址,我们已经可以在互联网上任意两台主机上建立通信。
接下来的问题是,同一台主机上有许多程序都需要用到网络,比如,你一边浏览网页,一边与朋友在线聊天。当一个数据包从互联网上发来的时候,你怎么知道,它是表示网页的内容,还是表示在线聊天的内容?
也就是说,我们还需要一个参数,表示这个数据包到底供哪个程序(进程)使用。这个参数就叫做”端口“(port),它其实是每一个使用网卡的程序的编号。每个数据包都发到主机的特定端口,所以不同的程序就能取到自己所需要的数据。
“端口”是0到65535之间的一个整数,正好16个二进制位。0到1023的端口被系统占用,用户只能选用大于1023的端口。不管是浏览网页还是在线聊天,应用程序会随机选用一个端口,然后与服务器的相应端口联系。
"传输层"的功能,就是建立"端口到端口"的通信。相比之下,"网络层"的功能是建立"主机到主机"的通信。只要确定主机和端口,我们就能实现程序之间的交流。因此,Unix系统就把主机+端口,叫做"套接字"(socket)。有了它,就可以进行网络应用程序开发了。
5.2 UDP协议
现在,我们必须在数据包中加入端口信息,这就需要新的协议。最简单的实现叫做UDP协议,它的格式几乎就是在数据前面,加上端口号。
UDP数据包,也是由”标头”和”数据”两部分组成。

“标头”部分主要定义了发出端口和接收端口,”数据”部分就是具体的内容。然后,把整个UDP数据包放入IP数据包的”数据”部分,而前面说过,IP数据包又是放在以太网数据包之中的,所以整个以太网数据包现在变成了下面这样:

UDP数据包非常简单,”标头”部分一共只有8个字节,总长度不超过65,535字节,正好放进一个IP数据包。
5.3 TCP协议
UDP协议的优点是比较简单,容易实现,但是缺点是可靠性较差,一旦数据包发出,无法知道对方是否收到。
为了解决这个问题,提高网络可靠性,TCP协议就诞生了。这个协议非常复杂,但可以近似认为,它就是有确认机制的UDP协议,每发出一个数据包都要求确认。如果有一个数据包遗失,就收不到确认,发出方就知道有必要重发这个数据包了。
因此,TCP协议能够确保数据不会遗失。它的缺点是过程复杂、实现困难、消耗较多的资源。
TCP数据包和UDP数据包一样,都是内嵌在IP数据包的”数据”部分。TCP数据包没有长度限制,理论上可以无限长,但是为了保证网络的效率,通常TCP数据包的长度不会超过IP数据包的长度,以确保单个TCP数据包不必再分割。
六、应用层
应用程序收到”传输层”的数据,接下来就要进行解读。由于互联网是开放架构,数据来源五花八门,必须事先规定好格式,否则根本无法解读。
“应用层”的作用,就是规定应用程序的数据格式。
举例来说,TCP协议可以为各种各样的程序传递数据,比如Email、WWW、FTP等等。那么,必须有不同协议规定电子邮件、网页、FTP数据的格式,这些应用程序协议就构成了"应用层"。
这是最高的一层,直接面对用户。它的数据就放在TCP数据包的”数据”部分。因此,现在的以太网的数据包就变成下面这样。
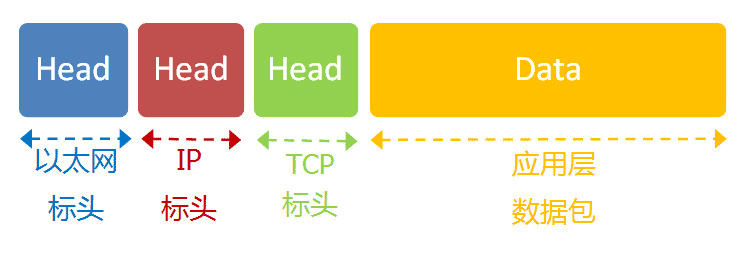
至此,整个互联网的五层结构,自下而上全部讲完了。这是从系统的角度,解释互联网是如何构成的。下一篇,我反过来,从用户的角度,自上而下看看这个结构是如何发挥作用,完成一次网络数据交换的。
上一篇文章分析了互联网的总体构思,从下至上,每一层协议的设计思想。
这是从设计者的角度看问题,今天我想切换到用户的角度,看看用户是如何从上至下,与这些协议互动的。
七、一个小结
先对前面的内容,做一个小结。
我们已经知道,网络通信就是交换数据包。电脑A向电脑B发送一个数据包,后者收到了,回复一个数据包,从而实现两台电脑之间的通信。数据包的结构,基本上是下面这样:
发送这个包,需要知道两个地址:
对方的MAC地址 对方的IP地址
有了这两个地址,数据包才能准确送到接收者手中。但是,前面说过,MAC地址有局限性,如果两台电脑不在同一个子网络,就无法知道对方的MAC地址,必须通过网关(gateway)转发。
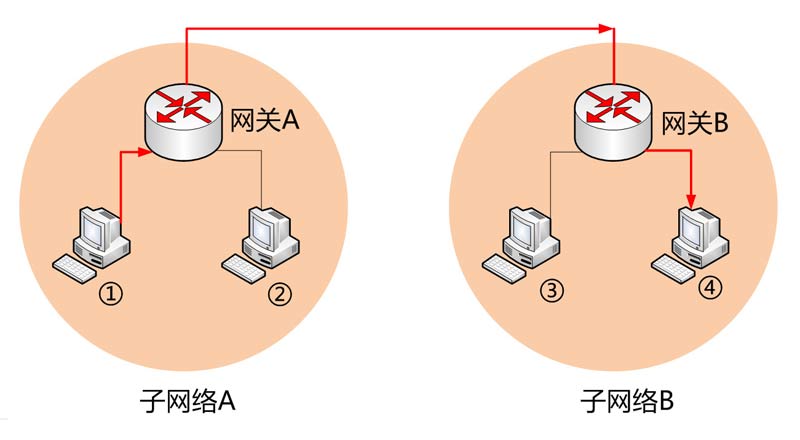
上图中,1号电脑要向4号电脑发送一个数据包。它先判断4号电脑是否在同一个子网络,结果发现不是(后文介绍判断方法),于是就把这个数据包发到网关A。网关A通过路由协议,发现4号电脑位于子网络B,又把数据包发给网关B,网关B再转发到4号电脑。
1号电脑把数据包发到网关A,必须知道网关A的MAC地址。所以,数据包的目标地址,实际上分成两种情况:
场景 数据包地址
同一个子网络 对方的MAC地址,对方的IP地址
非同一个子网络 网关的MAC地址,对方的IP地址
发送数据包之前,电脑必须判断对方是否在同一个子网络,然后选择相应的MAC地址。接下来,我们就来看,实际使用中,这个过程是怎么完成的。
八、用户的上网设置
8.1 静态IP地址
你买了一台新电脑,插上网线,开机,这时电脑能够上网吗?

通常你必须做一些设置。有时,管理员(或者ISP)会告诉你下面四个参数,你把它们填入操作系统,计算机就能连上网了:
本机的IP地址
子网掩码
网关的IP地址
DNS的IP地址
下图是Windows系统的设置窗口。

这四个参数缺一不可,后文会解释为什么需要知道它们才能上网。由于它们是给定的,计算机每次开机,都会分到同样的IP地址,所以这种情况被称作”静态IP地址上网“。
但是,这样的设置很专业,普通用户望而生畏,而且如果一台电脑的IP地址保持不变,其他电脑就不能使用这个地址,不够灵活。出于这两个原因,大多数用户使用”动态IP地址上网”。
8.2 动态IP地址
所谓”动态IP地址”,指计算机开机后,会自动分配到一个IP地址,不用人为设定。它使用的协议叫做DHCP协议。
这个协议规定,每一个子网络中,有一台计算机负责管理本网络的所有IP地址,它叫做”DHCP服务器“。新的计算机加入网络,必须向”DHCP服务器”发送一个”DHCP请求”数据包,申请IP地址和相关的网络参数。
前面说过,如果两台计算机在同一个子网络,必须知道对方的MAC地址和IP地址,才能发送数据包。但是,新加入的计算机不知道这两个地址,怎么发送数据包呢?
DHCP协议做了一些巧妙的规定。
8.3 DHCP协议
首先,它是一种应用层协议,建立在UDP协议之上,所以整个数据包是这样的:
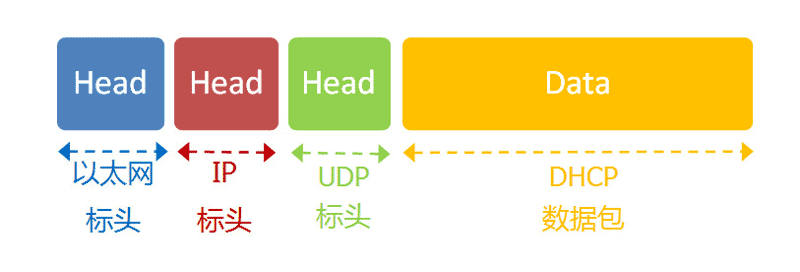
(1)最前面的”以太网标头”,设置发出方(本机)的MAC地址和接收方(DHCP服务器)的MAC地址。前者就是本机网卡的MAC地址,后者这时不知道,就填入一个广播地址:FF-FF-FF-FF-FF-FF。
(2)后面的”IP标头”,设置发出方的IP地址和接收方的IP地址。这时,对于这两者,本机都不知道。于是,发出方的IP地址就设为0.0.0.0,接收方的IP地址设为255.255.255.255。
(3)最后的”UDP标头”,设置发出方的端口和接收方的端口。这一部分是DHCP协议规定好的,发出方是68端口,接收方是67端口。
这个数据包构造完成后,就可以发出了。以太网是广播发送,同一个子网络的每台计算机都收到了这个包。因为接收方的MAC地址是FF-FF-FF-FF-FF-FF,看不出是发给谁的,所以每台收到这个包的计算机,还必须分析这个包的IP地址,才能确定是不是发给自己的。当看到发出方IP地址是0.0.0.0,接收方是255.255.255.255,于是DHCP服务器知道"这个包是发给我的",而其他计算机就可以丢弃这个包。
接下来,DHCP服务器读出这个包的数据内容,分配好IP地址,发送回去一个”DHCP响应”数据包。这个响应包的结构也是类似的,以太网标头的MAC地址是双方的网卡地址,IP标头的IP地址是DHCP服务器的IP地址(发出方)和255.255.255.255(接收方),UDP标头的端口是67(发出方)和68(接收方),分配给请求端的IP地址和本网络的具体参数则包含在Data部分。
新加入的计算机收到这个响应包,于是就知道了自己的IP地址、子网掩码、网关地址、DNS服务器等等参数。
8.4 上网设置:小结
这个部分,需要记住的就是一点:不管是”静态IP地址”还是”动态IP地址”,电脑上网的首要步骤,是确定四个参数。这四个值很重要,值得重复一遍:
本机的IP地址
子网掩码
网关的IP地址
DNS的IP地址
有了这几个数值,电脑就可以上网”冲浪”了。接下来,我们来看一个实例,当用户访问网页的时候,互联网协议是怎么运作的。
九、一个实例:访问网页
9.1 本机参数
我们假定,经过上一节的步骤,用户设置好了自己的网络参数:
本机的IP地址:192.168.1.100
子网掩码:255.255.255.0
网关的IP地址:192.168.1.1
DNS的IP地址:8.8.8.8
然后他打开浏览器,想要访问Google,在地址栏输入了网址:www.google.com。
这意味着,浏览器要向Google发送一个网页请求的数据包。
9.2 DNS协议
我们知道,发送数据包,必须要知道对方的IP地址。但是,现在,我们只知道网址www.google.com,不知道它的IP地址。
DNS协议可以帮助我们,将这个网址转换成IP地址。已知DNS服务器为8.8.8.8,于是我们向这个地址发送一个DNS数据包(53端口)。
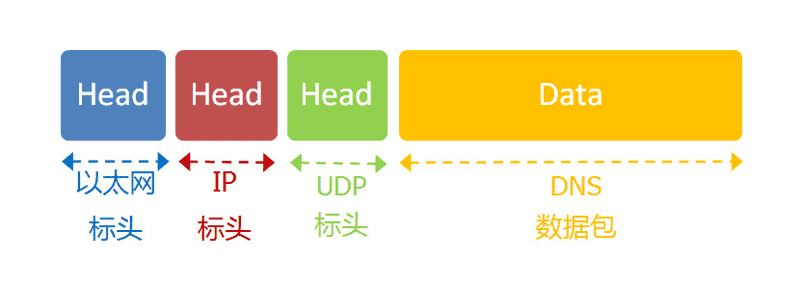
然后,DNS服务器做出响应,告诉我们Google的IP地址是172.194.72.105。于是,我们知道了对方的IP地址。
9.3 子网掩码
接下来,我们要判断,这个IP地址是不是在同一个子网络,这就要用到子网掩码。
已知子网掩码是255.255.255.0,本机用它对自己的IP地址192.168.1.100,做一个二进制的AND运算(两个数位都为1,结果为1,否则为0),计算结果为192.168.1.0;然后对Google的IP地址172.194.72.105也做一个AND运算,计算结果为172.194.72.0。这两个结果不相等,所以结论是,Google与本机不在同一个子网络。
因此,我们要向Google发送数据包,必须通过网关192.168.1.1转发,也就是说,接收方的MAC地址将是网关的MAC地址。
9.4 应用层协议
浏览网页用的是HTTP协议,它的整个数据包构造是这样的:
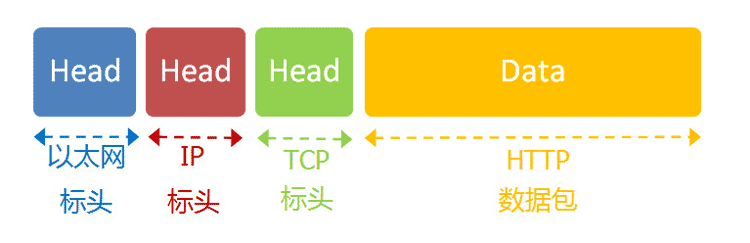
HTTP部分的内容,类似于下面这样:
GET / HTTP/1.1
Host: www.google.com
Connection: keep-alive
User-Agent: Mozilla/5.0 (Windows NT 6.1) ……
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,/;q=0.8
Accept-Encoding: gzip,deflate,sdch
Accept-Language: zh-CN,zh;q=0.8
Accept-Charset: GBK,utf-8;q=0.7,*;q=0.3
Cookie: … …
我们假定这个部分的长度为4960字节,它会被嵌在TCP数据包之中。
9.5 TCP协议
TCP数据包需要设置端口,接收方(Google)的HTTP端口默认是80,发送方(本机)的端口是一个随机生成的1024-65535之间的整数,假定为51775。
TCP数据包的标头长度为20字节,加上嵌入HTTP的数据包,总长度变为4980字节。
9.6 IP协议
然后,TCP数据包再嵌入IP数据包。IP数据包需要设置双方的IP地址,这是已知的,发送方是192.168.1.100(本机),接收方是172.194.72.105(Google)。
IP数据包的标头长度为20字节,加上嵌入的TCP数据包,总长度变为5000字节。
9.7 以太网协议
最后,IP数据包嵌入以太网数据包。以太网数据包需要设置双方的MAC地址,发送方为本机的网卡MAC地址,接收方为网关192.168.1.1的MAC地址(通过ARP协议得到)。
以太网数据包的数据部分,最大长度为1500字节,而现在的IP数据包长度为5000字节。因此,IP数据包必须分割成四个包。因为每个包都有自己的IP标头(20字节),所以四个包的IP数据包的长度分别为1500、1500、1500、560。
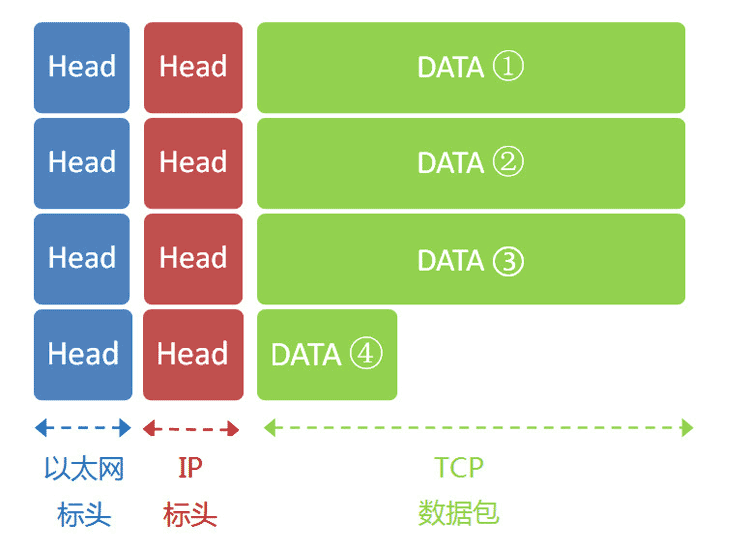
9.8 服务器端响应
经过多个网关的转发,Google的服务器172.194.72.105,收到了这四个以太网数据包。
根据IP标头的序号,Google将四个包拼起来,取出完整的TCP数据包,然后读出里面的”HTTP请求”,接着做出”HTTP响应”,再用TCP协议发回来。
本机收到HTTP响应以后,就可以将网页显示出来,完成一次网络通信。
这个例子就到此为止,虽然经过了简化,但它大致上反映了互联网协议的整个通信过程。
网络通信原理
一.操作系统基础
操作系统:(Operating System,简称OS)是管理和控制计算机硬件与软件资源的计算机程序,是直接运行在“裸机”上的最基本的系统软件,任何其他软件都必须在操作系统的支持下才能运行。
注:计算机(硬件)->os->应用软件
二.网络通信原理
2.1 互联网的本质就是一系列的网络协议
一台硬设有了操作系统,然后装上软件你就可以正常使用了,然而你也只能自己使用
像这样,每个人都拥有一台自己的机器,然而彼此孤立

如何能大家一起玩耍

然而internet为何物?
其实两台计算机之间通信与两个人打电话之间通信的原理是一样的(中国有很多地区,不同的地区有不同的方言,为了全中国人都可以听懂,大家统一讲普通话)

普通话属于中国国内人与人之间通信的标准,那如果是两个国家的人交流呢?

问题是,你不可能要求一个人/计算机掌握全世界的语言/标准,于是有了世界统一的通信标准:英语

结论:英语成为世界上所有人通信的统一标准,如果把计算机看成分布于世界各地的人,那么连接两台计算机之间的internet实际上就是
一系列统一的标准,这些标准称之为互联网协议,互联网的本质就是一系列的协议,总称为‘互联网协议’(Internet Protocol Suite).
互联网协议的功能:定义计算机如何接入internet,以及接入internet的计算机通信的标准。
2.2 osi七层协议
互联网协议按照功能不同分为osi七层或tcp/ip五层或tcp/ip四层

每层运行常见物理设备

2.3 tcp/ip五层模型讲解
我们将应用层,表示层,会话层并作应用层,从tcp/ip五层协议的角度来阐述每层的由来与功能,搞清楚了每层的主要协议
就理解了整个互联网通信的原理。
首先,用户感知到的只是最上面一层应用层,自上而下每层都依赖于下一层,所以我们从最下一层开始切入,比较好理解
每层都运行特定的协议,越往上越靠近用户,越往下越靠近硬件
2.3.1 物理层
物理层由来:上面提到,孤立的计算机之间要想一起玩,就必须接入internet,言外之意就是计算机之间必须完成组网

物理层功能:主要是基于电器特性发送高低电压(电信号),高电压对应数字1,低电压对应数字0
2.3.2 数据链路层
数据链路层由来:单纯的电信号0和1没有任何意义,必须规定电信号多少位一组,每组什么意思
数据链路层的功能:定义了电信号的分组方式
以太网协议:
早期的时候各个公司都有自己的分组方式,后来形成了统一的标准,即以太网协议ethernet
ethernet规定
一组电信号构成一个数据包,叫做‘帧’
每一数据帧分成:报头head和数据data两部分
head data
head包含:(固定18个字节)
发送者/源地址,6个字节
接收者/目标地址,6个字节
数据类型,6个字节
data包含:(最短46字节,最长1500字节)
数据包的具体内容
head长度+data长度=最短64字节,最长1518字节,超过最大限制就分片发送
mac地址:
head中包含的源和目标地址由来:ethernet规定接入internet的设备都必须具备网卡,发送端和接收端的地址便是指网卡的地址,即mac地址
mac地址:每块网卡出厂时都被烧制上一个世界唯一的mac地址,长度为48位2进制,通常由12位16进制数表示(前六位是厂商编号,后六位是流水线号)

广播:
有了mac地址,同一网络内的两台主机就可以通信了(一台主机通过arp协议获取另外一台主机的mac地址)
ethernet采用最原始的方式,广播的方式进行通信,即计算机通信基本靠吼

2.3.3 网络层
网络层由来:有了ethernet、mac地址、广播的发送方式,世界上的计算机就可以彼此通信了,问题是世界范围的互联网是由
一个个彼此隔离的小的局域网组成的,那么如果所有的通信都采用以太网的广播方式,那么一台机器发送的包全世界都会收到,
这就不仅仅是效率低的问题了,这会是一种灾难

上图结论:必须找出一种方法来区分哪些计算机属于同一广播域,哪些不是,如果是就采用广播的方式发送,如果不是,
就采用路由的方式(向不同广播域/子网分发数据包),mac地址是无法区分的,它只跟厂商有关
网络层功能:引入一套新的地址用来区分不同的广播域/子网,这套地址即网络地址
IP协议:
规定网络地址的协议叫ip协议,它定义的地址称之为ip地址,广泛采用的v4版本即ipv4,它规定网络地址由32位2进制表示
范围0.0.0.0-255.255.255.255
一个ip地址通常写成四段十进制数,例:172.16.10.1
ip地址分成两部分
网络部分:标识子网
主机部分:标识主机
注意:单纯的ip地址段只是标识了ip地址的种类,从网络部分或主机部分都无法辨识一个ip所处的子网
例:172.16.10.1与172.16.10.2并不能确定二者处于同一子网
子网掩码
所谓”子网掩码”,就是表示子网络特征的一个参数。它在形式上等同于IP地址,也是一个32位二进制数字,它的网络部分全部为1,主机部分全部为0。比如,IP地址172.16.10.1,如果已知网络部分是前24位,主机部分是后8位,那么子网络掩码就是11111111.11111111.11111111.00000000,写成十进制就是255.255.255.0。
知道”子网掩码”,我们就能判断,任意两个IP地址是否处在同一个子网络。方法是将两个IP地址与子网掩码分别进行AND运算(两个数位都为1,运算结果为1,否则为0),然后比较结果是否相同,如果是的话,就表明它们在同一个子网络中,否则就不是。
比如,已知IP地址172.16.10.1和172.16.10.2的子网掩码都是255.255.255.0,请问它们是否在同一个子网络?两者与子网掩码分别进行AND运算,
172.16.10.1:10101100.00010000.00001010.000000001
255255.255.255.0:11111111.11111111.11111111.00000000
AND运算得网络地址结果:10101100.00010000.00001010.000000001->172.16.10.0
172.16.10.2:10101100.00010000.00001010.000000010
255255.255.255.0:11111111.11111111.11111111.00000000
AND运算得网络地址结果:10101100.00010000.00001010.000000001->172.16.10.0
结果都是172.16.10.0,因此它们在同一个子网络。
总结一下,IP协议的作用主要有两个,一个是为每一台计算机分配IP地址,另一个是确定哪些地址在同一个子网络。
ip数据包
ip数据包也分为head和data部分,无须为ip包定义单独的栏位,直接放入以太网包的data部分
head:长度为20到60字节
data:最长为65,515字节。
而以太网数据包的”数据”部分,最长只有1500字节。因此,如果IP数据包超过了1500字节,它就需要分割成几个以太网数据包,分开发送了。
以太网头 ip 头 ip数据
ARP协议
arp协议由来:计算机通信基本靠吼,即广播的方式,所有上层的包到最后都要封装上以太网头,然后通过以太网协议发送,在谈及以太网协议时候,我门了解到
通信是基于mac的广播方式实现,计算机在发包时,获取自身的mac是容易的,如何获取目标主机的mac,就需要通过arp协议
arp协议功能:广播的方式发送数据包,获取目标主机的mac地址
协议工作方式:每台主机ip都是已知的
例如:主机172.16.10.10/24访问172.16.10.11/24
一:首先通过ip地址和子网掩码区分出自己所处的子网
场景 数据包地址
同一子网 目标主机mac,目标主机ip
不同子网 网关mac,目标主机ip
二:分析172.16.10.10/24与172.16.10.11/24处于同一网络(如果不是同一网络,那么下表中目标ip为172.16.10.1,通过arp获取的是网关的mac)
源mac 目标mac 源ip 目标ip 数据部分
发送端主机 发送端mac FF:FF:FF:FF:FF:FF 172.16.10.10/24 172.16.10.11/24 数据
三:这个包会以广播的方式在发送端所处的自网内传输,所有主机接收后拆开包,发现目标ip为自己的,就响应,返回自己的mac
2.3.4 传输层
传输层的由来:网络层的ip帮我们区分子网,以太网层的mac帮我们找到主机,然后大家使用的都是应用程序,你的电脑上可能同时开启qq,暴风影音,等多个应用程序,
那么我们通过ip和mac找到了一台特定的主机,如何标识这台主机上的应用程序,答案就是端口,端口即应用程序与网卡关联的编号。
传输层功能:建立端口到端口的通信
补充:端口范围0-65535,0-1023为系统占用端口
tcp协议:
可靠传输,TCP数据包没有长度限制,理论上可以无限长,但是为了保证网络的效率,通常TCP数据包的长度不会超过IP数据包的长度,以确保单个TCP数据包不必再分割。
以太网头 ip 头 tcp头 数据
udp协议:
不可靠传输,”报头”部分一共只有8个字节,总长度不超过65,535字节,正好放进一个IP数据包。
以太网头 ip头 udp头 数据
tcp报文

tcp三次握手和四次挥手

2.3.5 应用层
应用层由来:用户使用的都是应用程序,均工作于应用层,互联网是开发的,大家都可以开发自己的应用程序,数据多种多样,必须规定好数据的组织形式
应用层功能:规定应用程序的数据格式。
例:TCP协议可以为各种各样的程序传递数据,比如Email、WWW、FTP等等。那么,必须有不同协议规定电子邮件、网页、FTP数据的格式,这些应用程序协议就构成了”应用层”。

2.3.6 socket
我们知道两个进程如果需要进行通讯最基本的一个前提能能够唯一的标示一个进程,在本地进程通讯中我们可以使用PID来唯一标示一个进程,但PID只在本地唯一,网络中的两个进程PID冲突几率很大,这时候我们需要另辟它径了,我们知道IP层的ip地址可以唯一标示主机,而TCP层协议和端口号可以唯一标示主机的一个进程,这样我们可以利用ip地址+协议+端口号唯一标示网络中的一个进程。
能够唯一标示网络中的进程后,它们就可以利用socket进行通信了,什么是socket呢?我们经常把socket翻译为套接字,socket是在应用层和传输层之间的一个抽象层,它把TCP/IP层复杂的操作抽象为几个简单的接口供应用层调用已实现进程在网络中通信。

socket起源于UNIX,在Unix一切皆文件哲学的思想下,socket是一种'打开—读/写—关闭'模式的实现,服务器和客户端各自维护一个'文件',在建立连接打开后,可以向自己文件写入内容供对方读取或者读取对方内容,通讯结束时关闭文件。
三.网络通信实现
想实现网络通信,每台主机需具备四要素
本机的IP地址
子网掩码
网关的IP地址
DNS的IP地址
获取这四要素分两种方式
1.静态获取
即手动配置
2.动态获取
通过dhcp获取
以太网头 ip头 udp头 dhcp数据包
(1)最前面的”以太网标头”,设置发出方(本机)的MAC地址和接收方(DHCP服务器)的MAC地址。前者就是本机网卡的MAC地址,后者这时不知道,就填入一个广播地址:FF-FF-FF-FF-FF-FF。
(2)后面的”IP标头”,设置发出方的IP地址和接收方的IP地址。这时,对于这两者,本机都不知道。于是,发出方的IP地址就设为0.0.0.0,接收方的IP地址设为255.255.255.255。
(3)最后的”UDP标头”,设置发出方的端口和接收方的端口。这一部分是DHCP协议规定好的,发出方是68端口,接收方是67端口。
这个数据包构造完成后,就可以发出了。以太网是广播发送,同一个子网络的每台计算机都收到了这个包。因为接收方的MAC地址是FF-FF-FF-FF-FF-FF,看不出是发给谁的,所以每台收到这个包的计算机,还必须分析这个包的IP地址,才能确定是不是发给自己的。当看到发出方IP地址是0.0.0.0,接收方是255.255.255.255,于是DHCP服务器知道”这个包是发给我的”,而其他计算机就可以丢弃这个包。
接下来,DHCP服务器读出这个包的数据内容,分配好IP地址,发送回去一个”DHCP响应”数据包。这个响应包的结构也是类似的,以太网标头的MAC地址是双方的网卡地址,IP标头的IP地址是DHCP服务器的IP地址(发出方)和255.255.255.255(接收方),UDP标头的端口是67(发出方)和68(接收方),分配给请求端的IP地址和本网络的具体参数则包含在Data部分。
新加入的计算机收到这个响应包,于是就知道了自己的IP地址、子网掩码、网关地址、DNS服务器等等参数
四.网络通信流程
1.本机获取
本机的IP地址:192.168.1.100
子网掩码:255.255.255.0
网关的IP地址:192.168.1.1
DNS的IP地址:8.8.8.8
2.打开浏览器,想要访问Google,在地址栏输入了网址:www.google.com。
3.dns协议(基于udp协议)

13台根dns:
A.root-servers.net198.41.0.4美国
B.root-servers.net192.228.79.201美国(另支持IPv6)
C.root-servers.net192.33.4.12法国
D.root-servers.net128.8.10.90美国
E.root-servers.net192.203.230.10美国
F.root-servers.net192.5.5.241美国(另支持IPv6)
G.root-servers.net192.112.36.4美国
H.root-servers.net128.63.2.53美国(另支持IPv6)
I.root-servers.net192.36.148.17瑞典
J.root-servers.net192.58.128.30美国
K.root-servers.net193.0.14.129英国(另支持IPv6)
L.root-servers.net198.32.64.12美国
M.root-servers.net202.12.27.33日本(另支持IPv6)
域名定义:http://jingyan.baidu.com/article/1974b289a649daf4b1f774cb.html
顶级域名:以.com,.net,.org,.cn等等属于国际顶级域名,根据目前的国际互联网域名体系,国际顶级域名分为两类:类别顶级域名(gTLD)和地理顶级域名(ccTLD)两种。类别顶级域名是 以’COM’、’NET’、’ORG’、’BIZ’、’INFO’等结尾的域名,均由国外公司负责管理。地理顶级域名是以国家或地区代码为结尾的域名,如’CN’代表中国,’UK’代表英国。地理顶级域名一般由各个国家或地区负责管理。
二级域名:二级域名是以顶级域名为基础的地理域名,比喻中国的二级域有,.com.cn,.net.cn,.org.cn,.gd.cn等.子域名是其父域名的子域名,比喻父域名是abc.com,子域名就是www.abc.com或者*.abc.com.
一般来说,二级域名是域名的一条记录,比如alidiedie.com是一个域名,www.alidiedie.com是其中比较常用的记录,一般默认是用这个,但是类似*.alidiedie.com的域名全部称作是alidiedie.com的二级
4.HTTP部分的内容,类似于下面这样:
GET / HTTP/1.1
Host: www.google.com
Connection: keep-alive
User-Agent: Mozilla/5.0 (Windows NT 6.1) ……
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,/;q=0.8
Accept-Encoding: gzip,deflate,sdch
Accept-Language: zh-CN,zh;q=0.8
Accept-Charset: GBK,utf-8;q=0.7,*;q=0.3
Cookie: … …
我们假定这个部分的长度为4960字节,它会被嵌在TCP数据包之中。
5 TCP协议
TCP数据包需要设置端口,接收方(Google)的HTTP端口默认是80,发送方(本机)的端口是一个随机生成的1024-65535之间的整数,假定为51775。
TCP数据包的标头长度为20字节,加上嵌入HTTP的数据包,总长度变为4980字节。
6 IP协议
然后,TCP数据包再嵌入IP数据包。IP数据包需要设置双方的IP地址,这是已知的,发送方是192.168.1.100(本机),接收方是172.194.72.105(Google)。
IP数据包的标头长度为20字节,加上嵌入的TCP数据包,总长度变为5000字节。
7 以太网协议
最后,IP数据包嵌入以太网数据包。以太网数据包需要设置双方的MAC地址,发送方为本机的网卡MAC地址,接收方为网关192.168.1.1的MAC地址(通过ARP协议得到)。
以太网数据包的数据部分,最大长度为1500字节,而现在的IP数据包长度为5000字节。因此,IP数据包必须分割成四个包。因为每个包都有自己的IP标头(20字节),所以四个包的IP数据包的长度分别为1500、1500、1500、560。

8 服务器端响应
经过多个网关的转发,Google的服务器172.194.72.105,收到了这四个以太网数据包。
根据IP标头的序号,Google将四个包拼起来,取出完整的TCP数据包,然后读出里面的”HTTP请求”,接着做出”HTTP响应”,再用TCP协议发回来。
本机收到HTTP响应以后,就可以将网页显示出来,完成一次网络通信。
深入理解HTTPS通讯原理
一、HTTPS简介
HTTPS(Hyper Text Transfer Protocol over Secure Socket Layer),简单来讲就是加了安全的HTTP,即HTTP+SSL;我们知道HTTP通讯时,如果客户端C请求服务器S,那么可以通过网络抓包的形式来获取信息,甚至可以模拟服务器S端,来骗取与C端的通讯信息;这对互联网应用在安全领域的推广非常不利;HTTPS解决了这个问题。
二、HTTPS与HTTP的区别
1)HTTPS的服务器需要到CA申请证书,以证明自己服务器的用途;
2)HTTP信息是明文传输,HTTPS信息是密文传输;
3)HTTP与HTTPS的端口不同,一个是80端口,一个是443端口;
可以说HTTP与HTTPS是完全不同的连接方式,HTTPS集合了加密传输,身份认证,更加的安全。
三、HTTPS通讯的步骤

1)客户端请求服务器,发送握手消息
2)服务器返回客户端自己的加密算法、数字证书和公钥;
3)客户端验证服务器端发送来的数字证书是否与本地受信任的证书相关信息一致;如果不一致则客户端浏览器提示证书不安全如下图所示
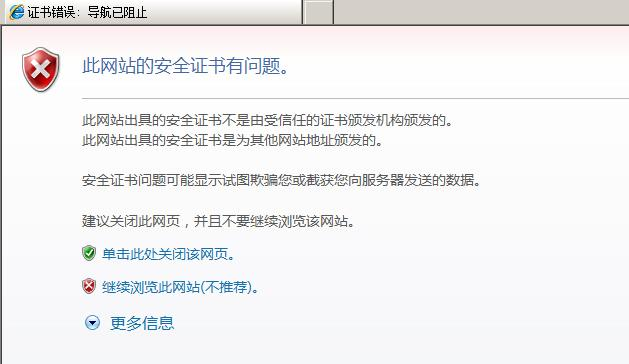
如果验证通过,则浏览器会采用自身的随机数算法产生一个随机数,并用服务器发送来的公钥加密;发送给服务器;这里如果有人通过攻击获取了这个消息,那也没用,因为他没有解密此段消息所需要私钥;验证通过的网站在浏览器地址栏的右边会有一安全锁的标识;
3)服务器解密得到此随机数,并用此随机数作为密钥采用对称加密算法加密一段握手消息发送给浏览器;
4)浏览器收到消息后解密成功,则握手结束,后续的信息都通过此随机密钥加密传输。
以上是服务端认证的情况,如果服务端对访问的客户端也有认证需求,则客户端也需要将自己的证书发送给服务器,服务器认证不通过,通讯结束;原理同上;
另外,一般在传输过程中为了防止消息窜改,还会采用消息摘要后再加密的方式,以此保证消息传递的正确性。
Why
罗胖60秒:为什么很多互联网服务是免费的?
- 我在「得到」App里面有一个节目,也叫《罗辑思维》。
昨天我在里面引用了一句话:“如果你买了产品,但是不需要付钱,那么,你就是产品本身。”
- 这句话精彩,它重新定义了现在互联网公司产品的本质。你想,谷歌、Facebook、腾讯、百度这些公司,它们的产品是啥?是它们的App吗?当然不是,是用户本身。
它们生产的是用户的注意力,卖给广告商;生产用户的数据,卖给需要的人。所以,用户才是它们的产品。
- 这么一说,你才能理解,为什么它们提供给用户的服务是免费的了。
那这个模式有普遍意义吗?恐怕没有。因为用户注意力和用户数据,只有到了一定的规模才有价值。所以,免费模式天然是巨头的市场。
- 初创企业,还是只能创造价值,然后靠用户掏钱来支持你的发展。
这种最古老的商业模式,才是最可靠的商业模式。
How
QuickJS
ffmpeg 的作者写的 JavaScript 引擎。他等于自己从头实现了一个简化的 V8,这也太猛了……这个引擎体积很小,但是功能完整而且高效。
Experience
Firefox 宣布试点,只要使用它家的浏览器,美国境内所有流量默认都走 HTTPS 代理,防止暴露用户信息。
Firefox 推出了浏览器全局的默认代理,本文介绍如何安装试用。
为什么蓝汛从2014年开始,走向了衰落?
互联网的早期,中国遍地都是网络公司。只要承包几个机柜,就能开网络公司。为什么后来都开不下去了?为什么蓝汛从2014年开始,走向了衰落?
原因很简单,因为阿里云出现了,大型互联网公司纷纷跟进,开设自己的云服务公司。它们像磁铁一样,将客户都吸走,小型网络公司从此一蹶不振。
这在互联网行业是普遍趋势,大厂商”赢家通吃”,小厂商很难存活。传统行业往往可以容纳多家公司,比如百货行业就有许多厂商。但是,互联网不是这样,一个行业通常只有头部前两位的公司,可以活得比较好,其他都不行。
如果你看到,有的领域竞争还很激烈,就说明这个领域还没有形成统一市场,互联网化还不彻底,比如现在的教育培训市场就是这样。以后的趋势,很可能是只要阿里和腾讯进入的市场,都是它们两家通吃,其他人分不到羹。如果它们通吃不了,就会把对手买下来。
高能预警:弹幕语言密码
这条音频要跟你说的是,二次元世界里的弹幕文化以及弹幕文化的特征。
有些话你可能听过,但是不知道是从哪儿来的,比如 “厉害了,我的哥”、“前方高能预警”,其实,这些话都是原本活跃在视频的弹幕里,最后从“二次元”世界流行到大众生活里来的词。
咱们在这儿先解释一下弹幕和二次元。弹幕的弹,就是子弹的弹,如果你在看视频时,发现画面上飘过很多评论,这个就是弹幕;二次元呢,就可以简单理解成动漫世界,而且弹幕最早就是出现在动漫视频里,也就是说,弹幕最早是二次元世界的产物。可以说,过去两年,二次元和弹幕大放异彩,不仅制造流行语,还制造了很多焦点事件。那隐藏在弹幕背后的“二次元世界”究竟是什么样的?到底是哪些人在使用弹幕呢?近日,人民网舆情室的技术人员先通过抓取十几万条弹幕,然后在请多位语言专家进行分析,出炉了《弹幕与网络语言》报告,对什么人爱用弹幕、弹幕语言有什么特征做了分析,下面咱们来详细说说。
首先来看看使用弹幕的消费者,是男性多还是女性多?问题的答案恐怕让你出乎意料,从数据来看,使用弹幕的男性用户占多数,占了总数的六成。从人群构成上来看,用户大多集中在二三线城市,整体上以高中生和大学生为主,而且24岁以下的年轻人占了七成。
其次,咱们再来看看,弹幕语言有什么特征。
从语义特征来看,弹幕语言有夸张化、重口味化和极端化的发展趋势,比如表达争吵,弹幕会用“拍砖”,表达有趣,会用“碉堡”,分析认为,这与受众的刺激点不断提升有关,受众的刺激点不断提升,调侃的方式就越来越极端化。
除此之外,弹幕语言还有符号化、场景化的特点以及低俗化的倾向,像是颜文字,也就是用标点和英文搭建的表情符号,还有川普和“雷电法王”杨永信等等都是符号化的表现。其中的“雷电法王” 杨永信,就是十几年前,号称要用“电击”来治愈青少年网瘾的那个人。给这个称号,其实就是表达对杨永信的讽刺,他也是弹幕文化将人物符号化的经典案例。
另外,弹幕语言的语义“兼容性”强,这就使它可以从“小圈子”逐层向外扩散开去,与流行文化相互影响。比如一些原本属于小众文化圈的专有名词,被成功地推广到大众领域,神曲、毁三观、下限等等都是这方面的例子。
从表意特征来看,弹幕有时会成为视频内容的重要补充,比如有些弹幕会给没有字幕的视频配上字幕,有些会对视频中出现的科学知识进行解释;有时弹幕还会成为视频内容的组成部分,甚至比原作还好看。并且,弹幕用户还形成了约定俗成的弹幕礼仪,像是当影片即将出现恐怖或出人意料的镜头时,“高能预警””就会集中刷屏,而这大大增强了用户的仪式感和参与感。
从形式特征来看,弹幕具有时间、空间和色彩三个维度的属性。时间属性相信你不难理解,弹幕评论本身就是按视频的时间轴呈线性排列,当众多弹幕像流水一样从眼前滑过时,可以很大程度上消解人们在看视频时的孤独感;空间属性也不难理解,弹幕可以出现在屏幕上的任何位置,这就让观众在看视频的时候,需要捕捉的信息量成倍增加,需要“眼观六路、耳听八方”,大大提升了“感官调动率”;色彩属性说的是用户可以自己选择弹幕文字的颜色,比如粉红色代表少女心,绿色代表“绿帽子”,红色代表激动、预警等等。这种文字色彩在文化意义上的隐喻,极大地丰富了弹幕语言,会对受众形成强烈的视觉冲击,也容易激发他们参与互动的热情。
以上就是语言学界专家们对弹幕语言的分析,不过报告最后也提出,弹幕语言主力军还是年轻群体,它的文化创造力、传播辐射力和日常消费能力,都极具潜力。但是由于脱离二次元群体,弹幕还没能形成独有的文化景观,而眼下呢,线下弹幕也尚未出现影响力较大的应用模式,所以弹幕文化要真正融入大众视野仍需时日。看待弹幕语言,需要直面它自身的特点和属性,这样要求管理者和相关平台,在开放和管理上予以更多的尝试。
以上内容,供你参考。
来源:人民网舆情监测室(弹幕与网络语言)
印度的上网人口仅次于中国,2018年为5.66亿,今年将增长11%达到6.27亿(中国为超过8亿)。印度和中国是世界仅有的两个超过5亿上网人口的国家。
但是,由于印度人均收入太低(仅为中国的四分之一),印度互联网企业的收入少得可怜,2018年印度数字广告支出仅为15.3亿美元,中国为850亿美元,世界第一的美国为1080亿美元。
– 《印度微薄的数字广告收入》
RMS(理查德.斯托曼)是一个伟大的人,但遗憾的是,他与更广阔的世界沟通有困难。历史上许多伟大的思想家都是如此。很可悲,这种事情发生在他这样的英雄人物身上,但我相信,只要人们继续为自由软件作斗争,历史会还给他公正。
– HN 读者评论 RMS 辞去自由软件基金会 FSF 主席
justDelete.me
每一种互联网服务,都需要注册,如果你以后想删除账户,可能会非常困难。该网站评价各网站删除用户账户的难易程度。
互联网诞生的地方
1969年10月29日,互联网诞生于加州大学洛杉矶分校 Boelter Hall 大楼三楼的3420室。
那天晚上10点半,一位名叫 Charley Kline 的研究生坐在 ITT 电传打字机前,有史以来第一次,将数据发给560公里以外斯坦福研究所的比尔·杜瓦尔(Bill Duvall)的电传打字机。这是美国 ARPANET 网络的起源,ARPANET 则是后来互联网的雏形。

上图:3402室已经恢复成1969年的样子,供人参观。

上图:那时采用的电传打字机终端,现在 Unix 系统里面的缩写 tty 指的就是这个东西。
值得一提的是,那天晚上 Charley Kline 想把命令 LOGIN 传给 Bill Duvall,但是只传了前两个字母L和O,等到第三个字母G时,系统就崩溃了。两个人电话沟通以后,修复了 BUG,20分钟后,总算把这个单词传过去了。
BBS 往事:人们在互联网尚未普及之前的「连接」
Suess 的离世让人们再一次想起,在 1978 年的那场暴风雪中,先驱们悄然发起的一场「互联网」连接革命。
「在人与人之间在线交流这件事上,一切都可以追溯到 Randy 和他的 BBS。」计算机史学家 Jason Scott 这样悼念刚去世的互联网先驱 Randy Suess。据《纽约时报》,Suess 12 月 10 日在芝加哥去世,享年 74 岁。世界上第一个对公众开放的拨号 BBS 诞生于 1978 年 2 月 16 日,Suess 就是它的发明者之一。
对于出生在互联网时代的人来说,BBS(Bulletin Board System,电子布告栏系统)是一段蒙满灰尘的「史前」故事。关于 BBS,人们更多谈起的往往是论坛(Forum),一种在 BBS 基础上经过多番改良的,不再限于纯文字交流的平台。Suess 的离世再一次唤起人们的记忆,他是「互联网」连接革命的发起者,而这场革命早在 1978 年就开始了。
生于暴风雪
1978 年年初,一场罕见的暴风雪袭击五大湖地区,芝加哥被超过 1 米的积雪覆盖。城市停止了运转,人们暂时不用去工作。终于闲暇下来的 IBM 工程师 Ward Christensen 打通了 Suess 的电话。随后,这对在家用电脑爱好者俱乐部上相识的好友,开始着手开发他们此前一直在讨论的新型信息交流系统。

CBBS 的两位发明者|BBS: The Documentary 预告片截图
他们的想法就是先建造一台中央电脑,然后俱乐部成员可以用各自的电脑拨号接进来,发布通告,交换关于会议、新想法和新项目的信息。打个比方,这套计算机系统就像是杂货店墙上供人们张贴传单的公告板。
据 Christensen 的回忆,仅靠二人合作——Christensen 负责编写软件,Suess 负责组装硬件,搭建系统只用了两周。系统工作的具体流程是,他们在一台名为 S-100 的个人电脑中嵌入一个可以通过电话线发送、接收数据的 modem(调制解调器)后,Suess 还将其他硬件和电脑焊接在一起。这些硬件的作用是自动重启机器,每当有人拨号接入 S-100 的时候,机器就会开始加载 Christensen 编写的软件。
就这样,CBBS(Computerized Bulletin Board System)上线,世界上第一个对公众开放的拨号 BBS 诞生,后来出现的同类系统都被称为 BBS。
「硬件看起来非常简陋,看起来像是用铁丝网和口香糖粘起来的。」Christensen 说。不仅是外观,它的功能现在看来也十分「简陋」。由于硬件和连接限制,CBBS 每次只能接待单个拨号者的访问,用户轮流接入系统,而系统每秒钟只能传输 5 个单词。
在一部描述 BBS 的缘起、发展和影响的纪录片 BBS: The Documentary 里,Christensen 的说法也得到佐证。「单从表面上看,早期的 BBS 似乎非常荒谬。」用户要进行对话耗时太长。在 BBS 上玩像国际象棋那样的电子游戏更是需要花上好几天,因为玩家在执行完指令后必须等一两天,再让对手接入,并轮流进行。
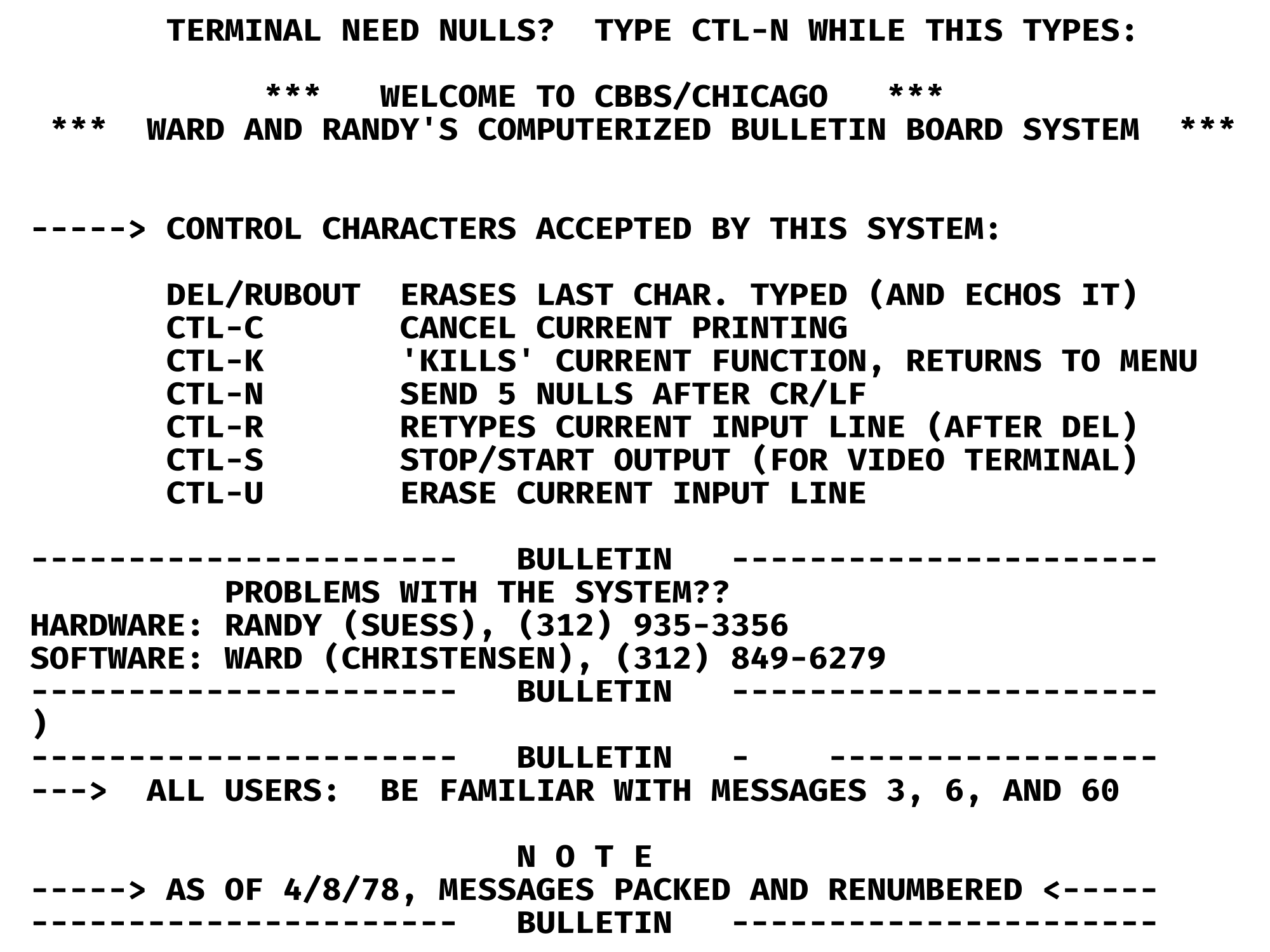
CBBS 登录界面|Wikipedia
即便如此,CBBS 还是很受欢迎。在系统上线几个月后,Suess 和 Christensen 在科技杂志 Byte 上撰写文章介绍 CBBS,并免费分发 BBS 软件的拷贝。即便那时还很少有人家里配备 modem。但在两年时间里,已经出现了 200-300 个比较活跃的 BBS,在顶峰时期,北美区留存着超过 15 万个 BBS。
直到 1980 年 CBBS 停用,据说它总计处理过超过 50 万次的拨号连线。
为互联沟通奠基
1984 年,Tom Jennings 开发了 Fido 协议(protocol)。Fido 的出现,让 BBS 可以实现跨站交流,也慢慢形成了一个由爱好者自行搭建的通讯网络 FidoNet。在 FidoNet 上,用户不再只能向单一布告栏发布信息,而是可以一次将消息分发到数百、数千个布告栏上。
据《连线》报道,1984 年,FidoNet 在世界范围内只有 132 个站点(node),到了 1995 年,数量已经增加到了 35000 个。FidoNet 在 CBBS 的基础上进行改造后,系统的互联属性也得以增强,它被认为是互联网普及之前使用人数最多的网络系统。
在 BBS: The Documentary 里,Jennings 描述了他的朋友们刚开始接触 Fido 概念时的反应,「有了这个程序,在电脑上拨号,输入账户和密码,进站浏览,然后留言,再过几个月,你或许能看到别人的回复。」但朋友们都认为这种沟通「太愚蠢了」。
FidoNet 上的 BBS 界面|FidoSysop Blog
这种「愚蠢」的交流方式,却仿佛拥有魔力,甚至可以让部分人沉迷。在当时,如果拨号接入了不在用户所在地区的 BBS,用户需要按越境电话标准支付每分钟 1 美元的费用。一些 BBS 用户成为了重度访问用户,在流连忘返一天下来后,他们就要付上 600 美元的电话费。这似乎很难理解,但在纪录片里,一些 BBS 站长(sysop)描述着他们对这种连接的浪漫想象:他们躺在床上,每当有人发帖,电脑上的灯光闪过的时候,他们觉得全世界将要涌进他们的卧室,即便是如此微渺的、慢吞吞的连接。
一位受访对象甚至笑笑说,「当你跟别人提起『BBS』,如果对方的眼睛里没有猛地闪过一道光,那他就不值得我继续花费时间。」在他看来,BBS 俨然已经成为识别同好的社交符号。
除此之外,BBS 更深远的意义是将更多的普通人连接到了一起。《连线》记者 Kim Zetter 写道,「不像互联网在刚出现的那样,只有研究者和军方能够使用它,BBS 的内核是民粹主义(反精英主义)的,只要是买得起 3000 到 10000 美元电脑的人,就能互联。」在这之前,ARPAnet 尽管迎来 100 台主机数量的突破,但仍局限在国防领域,普通的电脑爱好者很难介入网络世界。因此,CBBS 是在当时许多拥有调制解调器的人唯一能拨入的网络。

Randy Suess 地下室里的 CBBS|Suess 家人提供给《纽约时报》的照片
从 19 世纪 70 年代末到 80 年代,各地的爱好者以当年那个简陋的 CBBS 为蓝本,设计自己的 BBS,这些形式更丰富的论坛支持富文本信息,提供实效聊天室和在线游戏等功能。《纽约时报》的作者 Cade Metz 这样写道,「这些由普通人们创造的服务,是现在互联全球的 Twitter、Facebook 和 YouTube 等社交媒体服务的先驱。」谁能想到最初 50 万次的拨号连接衍变成 Facebook 和 YouTube 的 20 多亿月活,曾经被 Suess 安置在地下室的 CBBS 系统也早就成为今天人们日常生活中基础设施般的存在。
低龄化的互联网
现在,很多人拍视频为生。每天拍若干条,上传到门户网站,靠网站分红和商业合作赚钱。
对他们来说,视频的播放量就是一切,直接决定了收入的多少。他们最关心的一个问题:什么题材会有大量的观众?
我最近好像知道答案了。 我发现,亲子类的视频,也就是跟儿童相关的内容(包括玩具和儿歌),流量都非常好。 随便举几个例子,百度的视频搜索”亲子”。
Youtube 搜”儿童玩具”。
搜”儿歌”的话,播放量更惊人。
我看了好几个视频网站,觉得这是普遍现象,亲子类视频的播放量非常高。一个很普通的帐号,非常简单的内容,往往有几十万的播放量,极个别甚至高达千万。
当然我不是说,你拍亲子内容,就一定有很多人看。我的意思是,它获得高流量的机会大于其他视频。
如果确实存在这种现象,那么这是为什么?到底什么人在看这些儿童视频呢?
唯一的解释似乎是,互联网用户里面,儿童以及相关人群的比例非常高,高得超乎想象。
我猜想,很多小朋友、家长、婆婆妈妈其实都在网上,构成了互联网很大一部分(超过一半?)的用户,所以儿童视频的流量才会那么高。这些观众平时不太发声,大家听不到他们的声音,但他们是最大的流量来源。这大概也是《爸爸去哪儿》这一类亲子类电视节目,风靡一时的原因。
亲子类视频的流行,其实只是互联网低龄化的一个表现。我有一种感觉,18岁以下的用户,正在主导互联网。不止是视频网站,整个互联网都变得低龄化。青少年用户(甚至少儿用户)的喜好和观点,主导了互联网的生态和潮流。
不要再错误地认为,互联网是社会精英和知识分子主导的园地。恰恰相反,互联网其实是一个低龄化的地方,网上的主流永远反映的是青少年用户的口味。这反过来又决定了互联网产品的形态:你要开发一个面向大众的互联网产品,就别无选择,只能面向青少年用户群体来开发。
A List of Post-mortems
这个仓库收集各大互联网公司网络事故的事后分析报告。
Reference
- 图解服务器端网络架构
- 图解网络硬件
- 网络是怎样连接的
- 图解TCP/IP : 第5版
- 观点:互联网下半场是物理世界的数字化
- 用户的真正需求是什么?
- 黎万强:互联网新物种的四要素
- 数字独立宣言
- 涨知识了,网络原来是这样连接的
- 中国互联网报告2019
- 使用 Datasette 探索 SQLite 数据库
- 如何自己写一个静态站点生成器
- OKTools
- 计算机网络
- 硅谷竞相构建下一代互联网:Metaverse(元宇宙)
- 每个开发人员应了解的 TCP 知识(英文)
- 比特币挖矿简史
- 为什么你要扫描我的端口?(英文)
- 互联网之子 The Internet’s Own Boy: The Story of Aaron Swartz
- 我们窃取秘密:维基解密的故事 We Steal Secrets: The Story of WikiLeaks