
就像上图所描述的那样,机器学习实际上只包括了三个主要构成部分:
首先,你需要通过建模来确定一个公式,这个公式就是「机器」。
其次,确定「w」和「b」这两个变量「参数」。
通过系统或软件的设定不断重复测试并调整「参数」直到达到一个稳定的值。
在公式的确定中,整个学习的过程是渐进的,一旦这种重复的运算达到了一个稳定的取值,机器学习的错误概率就会大大减少。
简单来说,就是用一个公式来描述输入、输出和参数,从而提高机器对特定事物的认知。
Neural Networks API
Note: The Neural Networks API is available in Android 8.1 and higher system images. The header file is available in the latest version of the NDK. We encourage you to send us your feedback via the Android 8.1 Preview issue tracker.
The Android Neural Networks API (NNAPI) is an Android C API designed for running computationally intensive operations for machine learning on mobile devices. NNAPI is designed to provide a base layer of functionality for higher-level machine learning frameworks (such as TensorFlow Lite, Caffe2, or others) that build and train neural networks. The API is available on all devices running Android 8.1 (API level 27) or higher.
NNAPI supports inferencing by applying data from Android devices to previously trained, developer-defined models. Examples of inferencing include classifying images, predicting user behavior, and selecting appropriate responses to a search query.
On-device inferencing has many benefits:
Latency: You don’t need to send a request over a network connection and wait for a response. This can be critical for video applications that process successive frames coming from a camera.
Availability: The application runs even when outside of network coverage.
Speed: New hardware specific to neural networks processing provide significantly faster computation than with general-use CPU alone.
Privacy: The data does not leave the device.
Cost: No server farm is needed when all the computations are performed on the device.
There are also trade-offs that a developer should keep in mind:
System utilization: Evaluating neural networks involve a lot of computation, which could increase battery power usage. You should consider monitoring the battery health if this is a concern for your app, especially for long-running computations.
Application size: Pay attention to the size of your models. Models may take up multiple megabytes of space. If bundling large models in your APK would unduly impact your users, you may want to consider downloading the models after app installation, using smaller models, or running your computations in the cloud. NNAPI does not provide functionality for running models in the cloud.
Understanding the Neural Networks API runtime
NNAPI is meant to be called by machine learning libraries, frameworks, and tools that let developers train their models off-device and deploy them on Android devices. Apps typically would not use NNAPI directly, but would instead directly use higher-level machine learning frameworks. These frameworks in turn could use NNAPI to perform hardware-accelerated inference operations on supported devices.
Based on the app’s requirements and the hardware capabilities on a device, Android’s neural networks runtime can efficiently distribute the computation workload across available on-device processors, including dedicated neural network hardware, graphics processing units (GPUs), and digital signal processors (DSPs).
For devices that lack a specialized vendor driver, the NNAPI runtime relies on optimized code to execute requests on the CPU.
The diagram below shows a high-level system architecture for NNAPI.
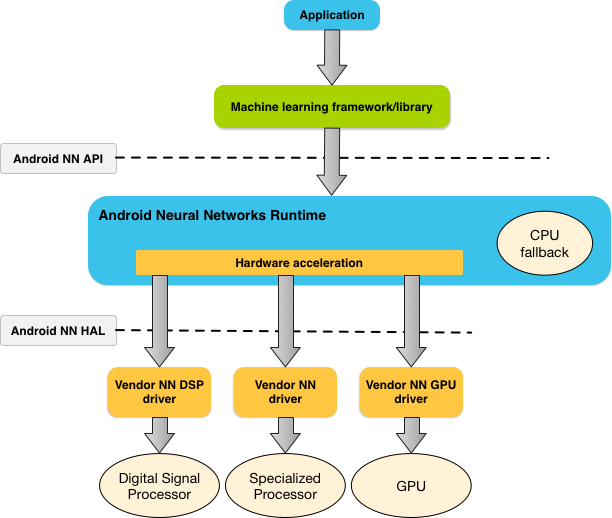
Figure 1. System architecture for Android Neural Networks API
Neural Networks API programming model
To perform computations using NNAPI, you first need to construct a directed graph that defines the computations to perform. This computation graph, combined with your input data (for example, the weights and biases passed down from a machine learning framework), forms the model for NNAPI runtime evaluation.
NNAPI uses four main abstractions:
Model: A computation graph of mathematical operations and the constant values learned through a training process. These operations are specific to neural networks. They include 2-dimensional (2D) convolution, logistic (sigmoid) activation, rectified linear (ReLU) activation, and more. Creating a model is a synchronous operation, but once successfully created, it can be reused across threads and compilations. In NNAPI, a model is represented as an ANeuralNetworksModel instance.
Compilation: Represents a configuration for compiling an NNAPI model into lower-level code. Creating a compilation is a synchronous operation, but once successfully created, it can be reused across threads and executions. In NNAPI, each compilation is represented as an ANeuralNetworksCompilation instance.
Memory: Represents shared memory, memory mapped files, and similar memory buffers. Using a memory buffer lets the NNAPI runtime transfer data to drivers more efficiently. An app typically creates one shared memory buffer that contains every tensor needed to define a model. You can also use memory buffers to store the inputs and outputs for an execution instance. In NNAPI, each memory buffer is represented as an ANeuralNetworksMemory instance.
Execution: Interface for applying an NNAPI model to a set of inputs and to gather the results. Execution is an asynchronous operation. Multiple threads can wait on the same execution. When the execution completes, all threads will be released. In NNAPI, each execution is represented as an ANeuralNetworksExecution instance.
The following diagram shows the basic programming flow.
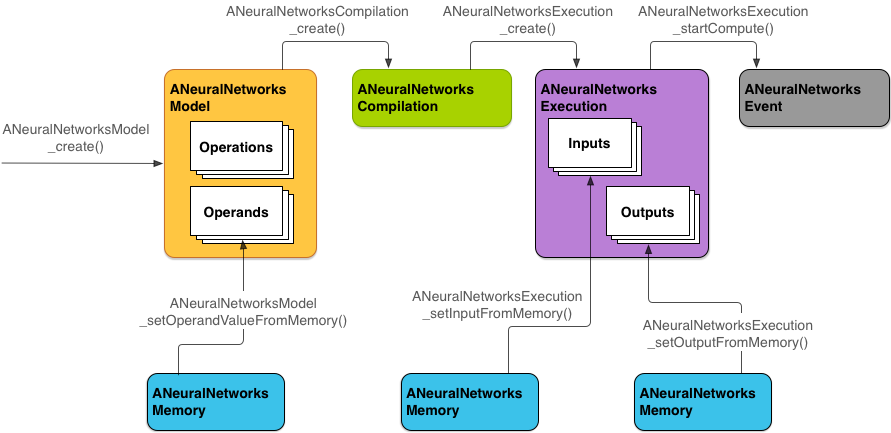
Figure 2. Programming flow for Android Neural Networks API
The rest of this section describes the steps to set up your NNAPI model to perform computation, compile the model, and execute the compiled model.
Tip: For brevity, we’ve omitted checking the result codes from each operation in the code snippets below. You should make sure to do so in your production code.
Providing access to training data
Your trained weights and biases data are likely stored in a file. To provide the NNAPI runtime with efficient access to this data, create a ANeuralNetworksMemory instance by calling the ANeuralNetworksMemory_createFromFd() function, and passing in the file descriptor of the opened data file.
You can also specify memory protection flags and an offset where the shared memory region starts in the file.
// Create a memory buffer from the file that contains the trained data.
ANeuralNetworksMemory* mem1 = NULL;
int fd = open(“training_data”, O_RDONLY);
ANeuralNetworksMemory_createFromFd(file_size, PROT_READ, fd, 0, &mem1);
Although in this example we use only one ANeuralNetworksMemory instance for all our weights, it’s possible to use more than one ANeuralNetworksMemory instance for multiple files.
Models
A model is the fundamental unit of computation in NNAPI. Each model is defined by one or more operands and operations.
Operands
Operands are data objects used in defining the graph. These include the inputs and outputs of the model, the intermediate nodes that contain the data that flows from one operation to the other, and the constants that are passed to these operations.
There are two types of operands that can be added to NNAPI models: scalars and tensors.
A scalar represents a single number. NNAPI supports scalar values in 32-bit floating point, 32-bit integer, and unsigned 32-bit integer format.
Most operations with NNAPI involve tensors. Tensors are n-dimensional arrays. NNAPI supports tensors with 32-bit integer, 32-bit floating point, and 8-bit quantized values.
For example, the diagram below represents a model with two operations: an addition followed by a multiplication. The model takes an input tensor and produces one output tensor.
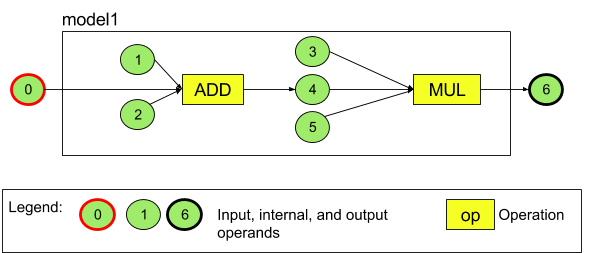
Figure 3. Example of operands for an NNAPI model
The model above has seven operands. These operands are identified implicitly by the index of the order in which they are added to the model. The first operand added has an index of 0, the second an index of 1, and so on.
The order in which you add the operands does not matter. For example, the model output operand could be the first one added. The important part is to use the right index value when referring to an operand.
Operands have types. These are specified when they are added to the model. An operand cannot be used as both input and output of a model.
For additional topics on using operands, see More about operands.
Operations
An operation specifies the computations to be performed. Each operation consists of these elements:
an operation type (for example, addition, multiplication, convolution),
a list of indexes of the operands that the operation uses for input, and
a list of indexes of the operands that the operation uses for output.
The order in these lists matters; see the NNAPI API reference for each operation for the expected inputs and outputs.
You must add the operands that an operation consumes or produces to the model before the adding the operation.
The order in which you add operations does not matter. NNAPI relies on the dependencies established by the computation graph of operands and operations to determine the order in which operations are executed.
The operations that NNAPI supports are summarized in the table below:
Category Operations
Element-wise mathematical operations
ANEURALNETWORKS_ADD
ANEURALNETWORKS_MUL
ANEURALNETWORKS_FLOOR
Array operations
ANEURALNETWORKS_CONCATENATION
ANEURALNETWORKS_DEPTH_TO_SPACE
ANEURALNETWORKS_DEQUANTIZE
ANEURALNETWOKRS_RESHAPE
ANEURALNETWORKS_SPACE_TO_DEPTH
Image operations
ANEURALNETWORKS_RESIZE_BILINEAR
Lookup operations
ANEURALNETWORKS_HASHTABLE_LOOKUP
ANEURALNETWORKS_EMBEDDING_LOOKUP
Normalization operations
ANEURALNETWORKS_L2_NORMALIZATION
ANEURALNETWORKS_LOCAL_RESPONSE_NORMALIZATION
Convolution operations
ANEURALNETWORKS_CONV_2D
ANEURALNETWORKS_DEPTHWISE_CONV_2D
Pooling operations
ANEURALNETWORKS_AVERAGE_POOL_2D
ANEURALNETWORKS_L2_POOL_2D
ANEURALNETWORKS_MAX_POOL_2D
Activation operations
ANEURALNETWORKS_LOGISTIC
ANEURALNETWORKS_RELU
ANEURALNETWORKS_RELU1
ANUERALNETWORKS_RELU6
ANEURALNETOWORKS_SOFTMAX
ANEURALNETWORKS_TANH
Other operations
ANEURALNETWORKS_FULLY_CONNECTED
ANEURALNETWORKS_LSH_PROJECTION
ANEURALNETWORKS_LSTM
ANEURALNETWORKS_RNN
ANEURALNETWORKS_SVDF
Building models
To build a model, follow these steps:
Call the ANeuralNetworksModel_create() function to define an empty model.
In the following example, we create the two-operation model found in the diagram above.
ANeuralNetworksModel* model = NULL;
ANeuralNetworksModel_create(&model);
Add the operands to your model by calling ANeuralNetworks_addOperand(). Their data types are defined using the ANeuralNetworksOperandType data structure.
// In our example, all our tensors are matrices of dimension [3, 4].
ANeuralNetworksOperandType tensor3x4Type;
tensor3x4Type.type = ANEURALNETWORKS_TENSOR_FLOAT32;
tensor3x4Type.scale = 0.f; // These fields are useful for quantized tensors.
tensor3x4Type.zeroPoint = 0; // These fields are useful for quantized tensors.
tensor3x4Type.dimensionCount = 2;
uint32_t dims[2] = {3, 4};
tensor3x4Type.dimensions = dims;
// We also specify operands that are activation function specifiers.
ANeuralNetworksOperandType activationType;
activationType.type = ANEURALNETWORKS_INT32;
activationType.scale = 0.f;
activationType.zeroPoint = 0;
activationType.dimensionCount = 0;
activationType.dimensions = NULL;
// Now we add the seven operands, in the same order defined in the diagram.
ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 0
ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 1
ANeuralNetworksModel_addOperand(model, &activationType); // operand 2
ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 3
ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 4
ANeuralNetworksModel_addOperand(model, &activationType); // operand 5
ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 6
For operands that have constant values, such as weights and biases that your app obtains from a training process, use the ANeuralNetworks_setOperandValue() and ANeuralNetworks_setOperandValuesFromMemory() functions.
In the following example, we set constant values from the training data file for which we created the memory buffer above.
// In our example, operands 1 and 3 are constant tensors whose value was
// established during the training process.
const int sizeOfTensor = 3 4 4; // The formula for size calculation is dim0 dim1 elementSize.
ANeuralNetworksModel_setOperandValueFromMemory(model, 1, mem1, 0, sizeOfTensor);
ANeuralNetworksModel_setOperandValueFromMemory(model, 3, mem1, sizeOfTensor, sizeOfTensor);
// We set the values of the activation operands, in our example operands 2 and 5.
int32_t noneValue = ANEURALNETWORKS_FUSED_NONE;
ANeuralNetworksModel_setOperandValue(model, 2, &noneValue, sizeof(noneValue));
ANeuralNetworksModel_setOperandValue(model, 5, &noneValue, sizeof(noneValue));
For each operation in the directed graph you want to compute, add the operation to your model by calling the ANeuralNetworks_addOperation() function.
As parameters to this call, your app must provide:
the operation type,
the count of input values,
the array of the indexes for input operands,
the count of output values, and
the array of the indexes for output operands.
Note that an operand cannot be used for both input and output of the same operation.
// We have two operations in our example.
// The first consumes operands 1, 0, 2, and produces operand 4.
uint32_t addInputIndexes[3] = {1, 0, 2};
uint32_t addOutputIndexes[1] = {4};
ANeuralNetworksModel_addOperation(model, ANEURALNETWORKS_ADD, 3, addInputIndexes, 1, addOutputIndexes);
// The second consumes operands 3, 4, 5, and produces operand 6.
uint32_t multInputIndexes[3] = {3, 4, 5};
uint32_t multOutputIndexes[1] = {6};
ANeuralNetworksModel_addOperation(model, ANEURALNETWORKS_MUL, 3, multInputIndexes, 1, multOutputIndexes);
Identify which operands the model should treat as its inputs and outputs, by calling the ANeuralNetworksModel_identifyInputsAndOutputs() function. This function lets you configure the model to use a subset of the input and output operands that you specified earlier in step 4.
// Our model has one input (0) and one output (6).
uint32_t modelInputIndexes[1] = {0};
uint32_t modelOutputIndexes[1] = {6};
ANeuralNetworksModel_identifyInputsAndOutputs(model, 1, modelInputIndexes, 1 modelOutputIndexes);
Call ANeuralNetworksModel_finish() to finalize the definition of your model. If there are no errors, this function returns a result code of ANEURALNETWORKS_NO_ERROR.
ANeuralNetworksModel_finish(model);
Once you create a model, you can compile it any number of times and execute each compilation any number of times.
Compilation
The compilation step determines on which processors your model will be executed and asks the corresponding drivers to prepare for its execution. This could include the generation of machine code specific to the processors on which your model will run.
To compile a model, follow these steps:
Call the ANeuralNetworksCompilation_create() function to create a new compilation instance.
// Compile the model.
ANeuralNetworksCompilation* compilation;
ANeuralNetworksCompilation_create(model, &compilation);
You can optionally influence how the runtime trades off between battery power usage and execution speed. You can do so by calling ANeuralNetworksCompilation_setPreference().
// Ask to optimize for low power consumption.
ANeuralNetworksCompilation_setPreference(compilation, ANEURALNETWORKS_PREFER_LOW_POWER);
The valid preferences you can specify include:
ANEURALNETWORKS_PREFER_LOW_POWER: Prefer executing in a way that minimizes battery drain. This is desirable for compilations that will be executed often.
ANEURALNETWORKS_PREFER_FAST_SINGLE_ANSWER: Prefer returning a single answer as fast as possible, even if this causes more power consumption.
ANEURALNETWORKS_PREFER_SUSTAINED_SPEED: Prefer maximizing the throughput of successive frames, for example when processing successive frames coming from the camera.
Finalize the compilation definition by calling ANeuralNetworksCompilation_finish(). If there are no errors, this function returns a result code of ANEURALNETWORKS_NO_ERROR.
ANeuralNetworksCompilation_finish(compilation);
Execution
The execution step applies the model to a set of inputs, and stores the computation outputs to one or more user buffers or memory spaces that your app allocated.
To execute a compiled model, follow these steps:
Call the ANeuralNetworksExecution_create() function to create a new execution instance.
// Run the compiled model against a set of inputs.
ANeuralNetworksExecution* run1 = NULL;
ANeuralNetworksExecution_create(compilation, &run1);
Specify where your app reads the input values for the computation. Your app can read input values from either a user buffer or an allocated memory space, by calling ANeuralNetworksExecution_setInput() or ANeuralNetworksExecution_setInputFromMemory() respectively.
Important: The indexes you specify when setting input and output buffers are indexes into the lists of inputs and outputs of the model as specified by ANeuralNetworksModel_identifyInputsAndOutputs(). Do not confuse them with the operand indexes used when creating the model. For example, for a model with three inputs, we should see three calls to ANeuralNetworksExecution_setInput(): one with an index of 0, another with 1, and one with 2.
// Set the single input to our sample model. Since it is small, we won’t use a memory buffer.
float32 myInput[3, 4] = { ..the data.. };
ANeuralNetworksExecution_setInput(run1, 0, NULL, myInput, sizeof(myInput));
Specify where your app writes the output values. Your app can write output values to either a user buffer or an allocated memory space, by calling ANeuralNetworksExecution_setOutput() or ANeuralNetworksExecution_setOutputFromMemory() respectively.
// Set the output.
float32 myOutput[3, 4];
ANeuralNetworksExecution_setOutput(run1, 0, NULL, myOutput, sizeof(myOutput));
Schedule the execution to start, by calling the ANeuralNetworksExecution_startCompute() function. If there are no errors, this function returns a result code of ANEURALNETWORKS_NO_ERROR.
// Starts the work. The work proceeds asynchronously.
ANeuralNetworksEvent* run1_end = NULL;
ANeuralNetworksExecution_startCompute(run1, &run1_end);
Call the ANeuralNetworksEvent_wait() function to wait for the execution to complete. If the execution was successful, this function returns a result code of ANEURALNETWORKS_NO_ERROR. Waiting can be done on a different thread than the one starting the execution.
// For our example, we have no other work to do and will just wait for the completion.
ANeuralNetworksEvent_wait(run1_end);
ANeuralNetworksEvent_free(run1_end);
ANeuralNetworksExecution_free(run1);
Optionally, you can apply a different set of inputs to the compiled model by using the same compilation instance to create a new ANeuralNetworksExecution instance.
// Apply the compiled model to a different set of inputs.
ANeuralNetworksExecution run2;
ANeuralNetworksExecution_create(compilation, &run2);
ANeuralNetworksExecution_setInput(run2, …);
ANeuralNetworksExecution_setOutput(run2, …);
ANeuralNetworksEvent run2_end = NULL;
ANeuralNetworksExecution_startCompute(run2, &run2_end);
ANeuralNetworksEvent_wait(run2_end);
ANeuralNetworksEvent_free(run2_end);
ANeuralNetworksExecution_free(run2);
Cleanup
The cleanup step handles the freeing of internal resources used for your computation.
// Cleanup
ANeuralNetworksCompilation_free(compilation);
ANeuralNetworksModel_free(model);
ANeuralNetworksMemory_free(mem1);
More about operands
The following section covers advanced topics about using operands.
Quantized tensors
A quantized tensor is a compact way to represent an n-dimensional array of floating point values.
NNAPI supports 8-bit asymmetric quantized tensors. For these tensors, the value of each cell is represented by an 8-bit integer. Associated with the tensor is a scale and a zero point value. These are used to convert the 8-bit integers into the floating point values that are being represented.
The formula is:
(cellValue - zeroPoint) * scale
where the zeroPoint value is a 32-bit integer and the scale a 32-bit floating point value.
Compared to tensors of 32-bit floating point values, 8-bit quantized tensors have two advantages:
Your application will be smaller, as the trained weights will take a quarter of the size of 32-bit tensors.
Computations can often be executed faster. This is due to the smaller amount of data that needs to be fetched from memory and the efficiency of processors such as DSPs in doing integer math.
While it is possible to convert a floating point model to a quantized one, our experience has shown that better results are achieved by training a quantized model directly. In effect, the neural network learns to compensate for the increased granularity of each value. For each quantized tensor, the scale and zeroPoint values are determined during the training process.
In NNAPI, you define quantized tensors types by setting the type field of the ANeuralNetworksOperandType data structure to ANEURALNETWORKS_TENSOR_QUANT8_ASYMM. You also specify the scale and zeroPoint value of the tensor in that data structure.
Optional operands
A few operations, like ANEURALNETWORKS_LSH_PROJECTION, take optional operands. To indicate in the model that the optional operand is omitted, call the ANeuralNetworksModel_setOperandValue() function, passing NULL for the buffer and 0 for the length.
If the decision on whether the operand is present or not varies for each execution, you indicate that the operand is omitted by using the ANeuralNetworksExecution_setInput() or ANeuralNetworksExecution_setOutput() functions, passing NULL for the buffer and 0 for the length.
Google开源TensorFlow背后:会成为人工智能领域的Android 吗?

在具体的实践中,Gmail 已经能够辨别 99.9% 的垃圾邮件,并能将语音识别为文字;Google Photo 的图片识别错误率也从 23% 降到了 13%,用户不需要再照片上标注「大海」的名字即可自动归类;而在 Google 的现金流业务广告系统中,机器学习的应用也将大大提高广告投放的投资回报率。
这一切看似复杂的过程都源自于一个简单公式的重复测试,正如 Greg Corrado 所言,「我们不会给机器一个规则,而是让它不断地去自己去学习和纠正。」
人类通过几个简单的例子就能进行学习,但机器却需要大量的测试。即便依靠一个简单的公式就能实现准确的预测,但整个参数和过程的确立却要经历无数的重复试验。
「机器学习并不是魔术,它只是个工具而已。」
未来,机器学习还面临着在移动设备上实现的瓶颈。由于大量的计算需要在云端完成,因此所有的结果的实现需要一个庞大网络的支撑,而目前的移动设备和网络还不足以达到这一要求。
「你的手机现在只是接受了数千台计算机为你计算处理的数据,未来我们会把网络做小,让机器学习的结果更具适用性。」Schimidt 毫不回避这一困境所在。
因此,TensorFlow 的开源变得理所当然,能否超越 Android 称为又一个全新的生态也变得没那么重要。比起建立一套固定的规则,「机器学习」和「人工智能」更需要的是一套技术标准。
利用 TensorFlow Serving 系统在生产环境中运行模型
机器学习技术支撑着许多 Google 产品的功能,比如:Google 应用中的语音识别,收件箱的智能回复,以及 Google 照片搜索,等等。尽管软件行业几十年中积累起的无数经验促成了很多用于构建并支持产品的最佳实践,但基于机器学习的服务却还是带来了一些新颖而有趣的挑战。如今,专为解决这些挑战的系统终于出现了,这就是 TensorFlow Serving。TensorFlow Serving 是一种用于机器学习模型的高性能开源服务系统,专为生产环境而设计,并针对 TensorFlow 进行了优化处理。
TensorFlow Serving 系统非常适用于大规模运行能够基于真实情况的数据并会发生动态改变的多重模型。它能够实现:
模型生命周期管理。
使用多重算法进行试验。
GPU 资源的有效使用。
TensorFlow Serving 能够简化并加速从模型到生产的过程。它能实现在服务器架构和 API 保持不变的情况下,安全地部署新模型并运行试验。除了原生集成 TensorFlow,还可以扩展服务其他类型的模型。下图显示了简化的监督学习过程,向 learner 输入训练数据,然后输出模型:

一旦经过验证后,新模型版本定型,就可以部署到服务系统,如下图所示:

TensorFlow Serving 使用(之前训练的)模型来实施推理——基于客户端呈现数据的预测。因为客户端通常会使用远程过程调用(RPC)接口来与服务系统通信,TensorFlow Serving 提供了一种基于 gRPC 的参考型前端实现,这是一种 Google 开发的高性能开源 RPC 架构。当新数据可用或改进模型时,加载并迭代模型是很常见的。事实上,在谷歌,许多管线经常运行,一旦当新数据可用时,就会产生新版本的模型。

TensorFlow Serving 由 C++ 编写而成,支持 Linux。TensorFlow Serving 引入的开销是非常小的。我们在一个有着 16个 vCPU 的英特尔至强 E5 2.6 GHz 的机器上进行了测试,执行每核每秒约 100,000 次查询,不包括 gRPC 和 TensorFlow 推理处理时间。我们非常激动地向大家分享这个遵守 Apache 2.0 开源协议的 TensorFlow 重要组件。非常希望大家能在 Stack Overflow 和 GitHub 上提问或请求开发一些功能。上手很简单,只需复制 github.com/tensorflow/serving 中的代码,然后签出教程即可。随着我们对 TensorFlow 的继续开发,你一定会了解到更多有关内容,因为这大概是世界上最好用的机器学习工具包了。如果希望及时了解最新进展,请关注 @googleresearch 或 +ResearchatGoogle,以及 2016 年 3 月,Jeff Dean 将在 GCP Next 2016 上的主题演讲。
人工智能:TensorFlow 带你进入深度学习的世界
自 TensorFlow 于 2015 年底正式开源,距今已有一年多,不久前,TensorFlow 正式版也发布了。这期间 TensorFlow 不断给人以惊喜,推出了分布式版本,服务框架 TensorFlow Serving,可视化工具 TensorFlow,上层封装 TF.Learn,其他语言(Go、Java、Rust、Haskell)的绑定、Windows 的支持、JIT 编译器 XLA、动态计算图框架 Fold,以及数不胜数的经典模型在 TensorFlow 上的实现(Inception Net、SyntaxNet 等)。在这一年多时间,TensorFlow 已从初入深度学习框架大战的新星,成为了几近垄断的行业事实标准。
目前看来,对于人工智能这个领域依然有不少怀疑的声音,但不可否认的是,人工智能仍然是未来的发展趋势。因此,在高手问答第 142 期里,我们策划了 “TensorFlow 实战” 的主题,并邀请了 @黄文坚 @唐源Terry 作为高手嘉宾。
本文整理了本期高手问答中一些与 TensorFlow 相关的精彩问答。
一、TensorFlow 之入门篇
1.没接触过,刚了解了一下,这个东西就是把某种东西用数据描述出来,然后用一些样本告诉机器它是什么,或者要对他进行什么操作,训练后,机器就能告诉我们输入的数据是什么,或者自动的进行操作吗?比如输入一堆图片告诉他哪个是猫,以后它就能自动识别猫了;给汽车装上各种传感器采集数据,人开着车操作,一段时间后,它就知道什么情况要怎么操作了,就会自动驾驶了?不知理解得对不对,希望指正。
对的,你说的是其中一类运用,属于机器学习的概念,但可以做到的还远远不止这些,可以多多关注这个领域。深度学习是机器学习的一个分支。TensorFlow 是主要用来进行深度学习应用的框架。
- 我是 TensorFlow 爱好者,现在正在学习, 国内的这方面的资料不多, 感谢你们提供的资料。我想问一下,学习 TensorFlow 有什么学习曲线,有没有什么实战的案例?另外在集群模式支持的是不是友好,和 Spark 集成是不是友好?或者有没有这方面的规划。
书中有特别多的实战例子,欢迎购买!至于对 Spark 集群的友好,你可以了解一下雅虎最近新开源的 TensorFlowOnSpark。
- 看了这个题目的一些提问,发现这个 TensorFlow 技术,学习曲线还是很陡峭,研究的人还是少数,有什么方法可以把学习曲线降低,更容易入门吗?还有学习这个技术,有什么必要的学科基础要求吗?
可以先通过 keras 上手,这是一个支持 TensorFlow 的上层封装。在学习 TensorFlow 之前,需要有基础的 Python 编程能力,以及对深度学习有一定了解。不过我现在在和 RStudio 合作把这个也能放在 R 里面跑,可以关注一下我的 GitHub:https://github.com/terrytangyuan。
- 好期待 TensorFlow 这本书,对于新手看着书入门会有难度吗?要先掌握什么基础知识呢?
可以先看看 TensorFlow 中文官方站点的文档。本书对新手难度不高。需要一些基础的 Python 运用能力,还有一些机器学习基础。书中对深度学习有较多的讲解,所以对深度学习的知识要求不高。
- 作为一名成长在 Spring 技术栈下的码农,转投 TensorFlow 的话,这本书适合我们入门么?也想请您在机器学习方向上提供一些指导意见,谢谢。
完全可以的,可以学习一下基础的 Python 语法,学习机器学习,深度学习,尝试做一做相关的小应用,也可以看看雅虎最近出的 TensorFlowOnSpark,或从 sklearn+numpy+pandas 开始。
- 请问如果要学习 TensorFlow,数学应该掌握到什么程度,高数,线代,积分都学过还需要再学哪些内容?
如果只是要掌握这门工具,不需要学习太多理论的东西,比如说你如果想利用这门工具来做一些机器学习的运用,我现在做的 tf.contrib.learn 模块,类似 scikit-learn,降低了很多学习的门槛,希望能够帮助到大家。如果想深入做研究的话,你说的这些都是必须要掌握的基础,可以在这基础上多关注一下相关的研究,建立好自己的感兴趣方向。
- 学习 TensorFlow 需要哪些技术栈,了解 TensorFlow 需要阅读源码吗?
如果只是想调用高阶的一些模块做一些应用,基本的 Python 就够了,如果想在某一块做提升的话,能自己学习读代码是再好不过的了,我一开始参与开源软件的时候也是只懂一些基础,可以积极参与开发和讨论,从这个过程中可以学到很多。如果想掌握底层的一些细节,就需要学好 C 语言之类的了。
最底层还有 cuda 的代码。这个要看自己的需求,是想了解到什么程度,如果只是用来做应用,想要很快出结果,直接看 api 就好。如果想对性能进行优化,可能需要阅读源码。
- 与 TensorFlow 类似的项目有哪些?TensorFlow 的优点和缺点是?
还有 Caffe、CNTK、MXNet 等,在《TensorFlow实战》书中第二章详尽地讲解了 TensorFlow 与其他学习框架的对比。
- TensorFlow 只能部署在 Linux 机器上?
Mac, Windows, Mobile, Rasberry Pi 都是可以的
二、TensorFlow 之性能篇
1.TensoFlow 的优点我知道,架构好、跨平台、接口丰富、易部署,而且是大公司的产品。问题就是 TensoFlow 的性能到底如何,我看过网上几个评测,是不是像以前别人测试中的那样慢的离谱,不管 CPU 还是 GPU 跟 Torch 比都慢不少,评比原文,更有测试评论说 TensoFlow 比 convnetjs 慢 100 倍,原文地址。
我简单了解深度学习的算法有很多,效率也不同,我希望知道的是,在同算法的情况下,TensoFlow 到底比其它框架慢多少?毕竟性能也是一个很关键的因素。
这些评测是很旧的了,新版的 TensorFlow 没有这个问题。TensorFlow 目前可能在全连接的 MLP 上稍微慢一点,但是后续 XLA 会解决这个问题。但是其他比如 CNN、RNN 等,因为大家主要都使用 cuDNN,差异不大,性能基本上非常接近的。性能你可以放心,Google 内部全部使用这个框架,如果真有性能慢的话,这么多人使用着早就解决了。
- 机器学习中一般分有监督学习和无监督学习,无监督学习下,用 TensorFlow 来对某个数据集进行学习,那么它识别出来的特征是什么?还有 TensorFlow1.0 中加入了 XLA,我理解为能把代码翻译成特定的 GPU 或 x86-64 的运行代码,是不是只有在做代数运算时才会用上 XLA?TensorFlow 不是已经在底层用cuda 的 cuDNN 库加速了吗,为什么还要用 XLA?
关于无监督学习,书中有讲解。无监督学习在深度学习中一般是自编码器等,提取到的是抽象的高阶特征,去除了噪声。XLA 会对几个层叠的操作进行 JIT 编译。cuda 是一门语言,cuDNN 是深度学习的库,使用 cuda 加速也要看是怎么使用它加速,是一层计算执行一次,还是把几层的计算合并在一起执行,XLA 做的就是这个,将一些简单的操作编译合并成一个操作。此前 TensorFlow 训 练 MLP 等网络较慢,使用 XLA 后有。
- 请问使用 TensorFlowOnSpark 之后,除了免去数据在 HDFS 和 TensorFlow 移动之外,是否能对性能有较好的提升呢?如果不用 TensorFlowOnSpark,TensorFlow 目前自己的分布式性能是否已经成熟了呢?
目前 TensorFlow 的分布式算是比较成熟的,但可能还不是最快的。TensorFlowonSpark 应该不能提升分布式的性能,毕竟还经过了一层 Spark 的通信机制处理。
- 应该选择 TensorFlow 还是 Theano?有使用两个库的用户比较一下这两者。比如从编译速度,运行速度,易用性等角度进行比较。
三、TensorFlow 之适用场景
- 请问 TensorFlow 在自然语言处理上有没有优势?
自然语言主要使用 RNN、LSTM、GRU 等,目前新推出的 TensorFLow Fold 支持 Dynamics Batching,计算效率大幅度提升,非常适合做自然语言处理。
- TensorFlow 在实际生产环境中,有什么特别适合的场景呢?
TensorFlow 部署非常方便,可用在 Android、iOS 等客户端,进行图像识别、人脸识别等任务。常见的 CTR 预估,推荐等任务,也可以轻松地部署到服务器 CPU 上。
- TensorFlow 有在生产企业中应用的案例吗?
在 Google 用的特别多,所有会用到深度学习的场景,都可以使用 TensorFlow,比如搜索、邮件、语音助手、机器翻译、图片标注等等。
- TensorFlow 在大数据行业的应用和运用怎么样?TensorFlow 的源码使用了哪些设计模式?
应用非常广的,谷歌已经在很多项目上用了 TensorFlow,比如说 Youtube watch next,还有很多研究型的项目,谷歌 DeepMind 以后所有的研究都会使用这个框架。如果对某段代码好奇,可以去参考参考源代码学习学习,很多的设计都是经过内部各种项目和用户的千锤百炼。
Google 内部非常多 team 在使用 TensorFlow,比如搜索、邮件、语音、机器翻译等等。数据越大,深度学习效果越好,而支持分布式的 TensorFlow 就能发挥越大的作用。
- 最近在学习 TensorFlow,发现其分布式有 in-graph 和 between-gragh 两种架构模式,请问这两种架构的区别是什么?或者是不是应用场景不同?
其实一个 in-graph 就是模型并行,将模型中不同节点分布式地运行;between-graph 就是数据并行,同时训练多个 batch 的数据。要针对神经网络结构来设计,模型并行实现难度较大,而且需要网络中天然存在很多可以并行的节点。因此一般用数据并行的比较多。
- TensorFlow实现估值网络 ,作用和意义在哪里? 有没有其他的方法实现估值网络?
估值网络是深度强化学习中的一个模型,可以用来解决常见的强化学习问题,比如下棋,自动玩游戏,机器控制等等。
- 想请问下 TF 有类似 Spark Streaming 的模块吗?TF 在后端存储上和 cassandra 或者 hdfs 的集成上有没有啥需要注意的地方?Spark 在集群上依赖 Master,然后分发到 Worker 上,这样的架构感觉不太稳定,不知道 TF 在分布式是什么架构有没有什么特点?
目前没有类似 Streaming 的东西,Spark 主要用来做数据处理。TensorFlow 则更多是对处理后的数据进行训练和学习。
- TensorFlow 对初学者是否太难了?TensorFlow 貌似都是研发要用的,对服务器运维会有哪些改变?
TensorFlow 针对实际生产也是非常好的。应该是所有框架中最适合实际生产环境的,因为有 Google 强大的工程团队的支持,所以 TensorFlow 拥有产品级的代码,稳健的质量,还有适合部署的 TensorFlow Serving。
- TensorFlow 从个体学习研究到实际生产环境应用,有哪些注意事项?
个人研究的时候没有太多限制,实际上线生成可以使用 TensorFlow Serving,部署效率比较高。
- TF 的耗能是否可以使其独立工作在离线环境的嵌入式小板上,真正达到可独立的智能机器人。
可以的,使用 TensorFlow 的嵌入式设备很多。但做机器人涉及到很多步骤,核心部分都设计了机器学习,图像处理之类的,TensorFlow 可以用来搭建那些。
- 互联网应用如何结合 TensorFlow,能简单介绍一下吗?
互联网应用很多都是推荐系统,比如说 Youtube watch next 的推荐系统就是用到了 TensorFlow,现在在 tf.contrib.learn 里面有专门的 Estimator 来做 Wide and Deep Learning(可以查看官网上的例子,我们的书中也有更深一些的讲解),大家也都可以用的。
- 不知道有没有针对传统零售行业的实际案例,比如销售预测的案例。
用深度学习可以做销售预测模型,只要它可以转为一个分类预测的问题。
- 使用 TensorFlow 的产品有哪些?有比较有代表性的吗?
可以看看我之前的评论,Youtube watch next 就是其中一个例子,还有很火的 AlphaGo。
四、TensorFlow 之实战篇
1.现在在用 TensorFlow 实现图像分类的例子,参考的是 CIFAR-10,输入图片会被随机裁剪为 24x24 的大小,而且训练效率较慢(用了近 20 小时,已使用了 GPU),是否有其他方法来提高效率?TensorFlow 有分布式的处理方法吗,若采用分布式,是否要手动将每一台机器上的训练结果进行合并?若提高裁剪的大小,是否能提高准确率?另外,网上有评论说 TensorFlow 的 C/C++ 接口没有 Caffe 友好,这个您怎么看?
提高裁剪的大小,会降低样本量,准确率不一定提高。训练 20 多小时是用了多少 epoch?可以通过 tensorboard 观看准确率变化,不一定要训练特别多 epoch。TensorFlow 有分布式的训练,不需要手动,有比较好用的接口,在《TensorFlow实战》中有详细的例子如何使用分布式版本。TF 的 C/C++ 接口很完善,有没有 caffe 友好这个见仁见智。
- 想问一下 TensorFlow 和 Spark 结合的框架,例如 TensorFlow on Spark,目前是否已经成熟可用?另外,TensorFlow 新版本增加了对 Java API 的支持,如果不使用 Python 语言,所有功能都直接使用 Java 语言进行相关开发是否已经可行?
Java API 目前还不太成熟,很多还有待实现,TensorFlowOnSpark 也挺有意思的,可以在现有的 Spark/Hadoop 分布式集群的基础上部署 TensorFlow 的程序,这样可以避免数据在已有 Spark/Hadoop 集群和深度学习集群间移动,HDFS 里面的数据能够更好的输入进 TensorFlow 的程序当中。至于成熟不成熟我就不清楚了,毕竟自己还没有试过,不过稍微看了看雅虎自己有使用。
- 对其他的一些机器学习的库接触过一些,要出一个好的效果,对算法选取和参数设置及调节这些方面,希望能给些建议。算法比较多,该如何从分析维度去选取合适的算法?
我觉得最好的方法就是参加数据科学竞赛,比如说 Kaggle,通过融入在大家的讨论当中,实际操作和锻炼,你可以很快的理解各种参数的意义和一些比较好的参数范围。
对于一般的数值、种类等特征的数据集,XGboost 和 Lightgbm 都有很好的效果。如果你的数据量很大,或者是图片、视频、语音、语言、时间序列,那么使用深度学习将能获得很好的效果。
- 打算做个文章分析类的东东,比如,分析一篇新闻的要素(时间、地点、人物),用 TensorFlow 应该怎么着手?
这个问题应该先看看 NLP(自然语言处理)相关的内容,TensorFlow 是实现你算法的工具。但是前提是你得知道应该使用什么算法。
TensorFlow 对于分布式 GPU 支持吗?如何选择 TensorFlow 和 XGboost?
TensorFlow 支持分布式 GPU,用于深度学习。XGBoost 主要是做 gradient boosting 这一块,最近也有人贡献了代码使它能够的 GPU 上跑,可以做一做实验比较一下。毕竟 XGboost 是经过 kaggle 用户的千锤百炼,很多都已经能够满足他们的需求了。现在学习 TensorFlow 有没有合适的数据可以使用的?
TensorFlow 中自带了 MNIST 和 CIFAR 数据的下载程序,其他常用的,比如 ImageNet, Gigaword 等数据集需要自己下载。
- BNN分类器训练出的曲线是高次多项式吗?
你说的 BNN 是指?如果神经网络中没有激活函数,那输出的结果只是输入的线性变换。但是加入了激活函数后,就不是高次多项式了。
五、其他相关的问题
1.TensorFlow 的发展趋势是怎么样的?
会集成越来越多的 contrib 模块,添加很多方便的上层接口,支持更多的语言绑定。同时新推出的 XLA(JIT编译器),Fold(Dynamics Batching)都是未来的大方向。
- 个人开发者做 TensorFlow 应用和开发有前途吗?还是说数据和资料都在大公司,没有合适的、相当数量的数据喂养是无法训练好模型的?
不仅仅限制在深度学习领域,现在 TensorFlow 也提供很多机器学习的 Estimators,我贡献的大部分都在这一块,可以了解一下 tf.contrib.learn 这个模块,书中有很多机器学习的例子。
另外就是具体要看你做什么任务,当然数据是需要的,但是 现在也有很多公开的数据。大公司的数据虽多,但是质量也并不是非常高。
有关 TensorFlow 的相关问答内容至此结束。欢迎大家在开源中国的技术问答区上面踊跃提问和回答。
最后,安利一下两位老师的著作 €€€€ 《TensorFlow实战》。 本书结合了大量代码实例,深入浅出地介绍了如何使用 TensorFlow、深度剖析如何用 TensorFlow 实现主流神经网络、详述 TensorBoard、多 GPU 并行、分布式并行等组件的使用方法。
谷歌人工智能背后的大脑
【伯乐在线导读】:1996 年 Jeff Dean 在华盛顿大学获得计算机科学博士学位,三年后便加入了谷歌。谷歌在 1998 年成立,他是公司早期员工之一。Jeff Dean 在谷歌公司的成长过程中扮演了重要角色,设计并实现了支撑谷歌大部分产品的分布式计算基础架构。2016 年 8 月 Forbes 的 Peter High 对 Jeff Dean 做了一次采访,伯乐在线编译如下。
谷歌 CEO Sundar Pichai 曾说谷歌将主要成为一家人工智能公司,作为系统和基础架构小组的资深前辈,Dean 和他的团队对于实现这个计划来说至关重要。这次的采访所涵盖的内容比较广泛,Dean 描述了他在谷歌扮演的多样角色,公司的 AI 愿景以及他对于谷歌即使已成为科技巨头但仍保持着创业精神的看法,同时还包括其他各种各样的话题。

Peter High:你好,Jeff Dean,你参与了谷歌大部分的历史,在 1999 年就加入了公司。请简单描述下这十几年来你在公司的角色是如何演变的。
Jeff Dean:我刚加入时公司真的很小,我们一起挤在帕罗奥图市大学路的一间小办公室里。我做的第一件最主要的事情就是创建我们第一个广告系统。之后,我花费了4到5年的时间在用于每一次查询的抓取、索引和搜索系统。之后,我主要与同事 Sanjay Ghemawat 等人创建用于存储和处理大规模数据设置的软件基础架构,还做一些像搜索指数或者处理卫星图像这样的事情。最近,我致力于机器学习系统。
High:你在公司的权限有多大,你要做的工作范围有多广?我猜想你没有“普通的一天”。你如何与公司内部或者外部的人员互动?在当前的工作上,你如何把时间分配在这些不同的事情呢?
Dean: 真不是典型的工作日 。在最初的 14 到15 年,我没有接受任何管理性的职位,这给了我更多自由时间去集中精力写代码。在最近几年,我接受了一些机器学习方面的管理职位,这对我来说很有趣,也是新的学习经历。因为在公司历史上我从事过多种工作,我会保持跟进这些不同的项目,我收到很多邮件。我花费相当一部分时间去处理邮件,通过浏览邮件来跟进项目的最新进展。在任何特定的时间,我手上都有几个技术性项目,我努力分配出时间在这些项目上面,同时还穿插着各种会议和设计审查各种事情。
High:尽管谷歌已经取得了巨大的发展,它仍然是保持创新的典范。它保持着壮志雄心和开拓创新,仿佛它只是一个很小的组织一般。但是它已有了资源——不管是人才上还是资金上——俨然已是科技界的庞然大物。这个组织是如何对抗停滞和官僚主义,从而保持不拘于自身规模的更强的灵活性呢?
Dean: 自从我加入公司以来,我们基本就经历了公司的不断成长。在早期,我们新招聘的员工每年都会增长一倍。按新员工占总员工的百分比算,我们后来降低了这个比例,但是在绝对数量上,我们基本仍保持一个大的增长,现在大约每年招聘 10% 到 20% 的新员工。公司规模每扩大一倍,我们就被迫使去重新思考公司已经完成的这些事情。哪些过去适用于 X 倍规模,但却不再适用于 2X 倍规模,我们必须去努力使我们的模式、工程、组织结构、团队动力等适应新的规模。
我认为有助于我们成长的一个举动是,把与谷歌其他业务在一定程度相分离的部分独立出来,成立不同的部门。创建为偏远地区覆盖网络的高海拔气球,与服务搜索查询有相对适度的互动。大体上把各种不同的活跃的项目独立开来,我们能获取更好的规模和效率,这些项目是我们的核心业务,但是彼此不需要太多的沟通交流。
High:我理解 Google/Alphabet 各部门的分离,是出于想要维持一定的灵活性,和划分开不同的活动的逻辑。这个评价是否公允?
Dean: 是的。我认为这使得 Alphabet 下面一些其他实体可以更独立地操作。关于规模的成倍增长,有一个有趣的转变是:以前我们每个人都是在同一个大楼,现在每个人都不在同一个大楼。
另一个转变,以前员工只在山景城,后来在瑞士苏黎世、纽约、日本东京和西雅图都设有办事处。我们一度有 5 个办事处,都相当大而完善。然后在短短几年内,我们的办事处从 5 个扩张到 35 个,因为我们觉得在世界各地设有许多办事处很好,在哪里可以找到有才华的人才,就在他们身边设立一个办事处。这促使我们不得不重新思考,如何去组织我们工程师的诸多成果。如果你有一个小的办公室,他们可能不应该做一百件事;他们应该做少数几件事,并专心把他们做好。一些小办公室采取的模式是看山景城的人在做什么,他们看到他们在做一百件事,所以他们认为他们也应该做一百件事。我们慢慢摸索到有一种更好的方式来充分发挥这些散布在各地的工程办事处的人的能力。
High:谷歌 CEO Sundar Pichai 曾说,从长远来看,设备装置将会消失,计算将从移动设备优先向人工智能优先进化。你如何看待谷歌对于人工智能优先的愿景?
Dean:我认为我们已经从桌面计算进入到了移动计算,这时候每个人都有一个计算设备随身随时携带。随着设备不断地缩小,语音识别和其他可用的 UI 变得实际可用,这将改变我们与计算设备交流的方式。他们将会退居到幕后或者只是周边,允许我们与他们对话就像我们与其他可信赖的伙伴对话一样。他们将会帮助我们获取我们需要的信息和完成各种任务。我认为这是推动机器学习的一个主要目标:在提供咨询方面让计算机提供其他人类伙伴能够提供的智慧,期待必要的时候有更多的信息和更多这类的事情。我认为在下个 5 到 10 年,将会是一个激动人心的时期。
High:随着各种进步和各种关于 AI 的目标的实现,看起来很多人不再谈论那些已经实现的真正的 AI。那就是,AI 在被谈论时似乎总是带有未来色彩。你怎么定义 AI 的边界?
Dean:我认为真正的通用人工智能将是一个系统,能够执行人类水平的推理,理解和完成复杂的任务。我们显然还没有达到这个水平,但你说得很对,确实有了很多进展。5 年前,给计算机一张图片,它还不能生成一个人类水平的句子来描述这个图片。现在,计算机生成的句子会说,“这张图片描述的是一个男人拿着网球拍在网球场上。”同时,一个人可能会说,“这是一张网球运动员发球的图片。”人的描述更为微妙,但事实上,现在计算机能够生成看起来几乎是人类写的标题,这是一个相当大的进步。这只是过去的 5~6 年间已实现的众多更具智慧的机器学习模型中的其中一个成就。随着他们应用更大的数据和计算,结果会更好。
High:你认为我们距离通用人工智能还有多远?
Dean:不同的问法有不同的回答,这个问题有点广泛。我只敢给出一个宽泛的猜测。大约就是 15 到 50 年,也有可能比 15 年更早。
High:正如你所提到的,语言是关键,许多谷歌的人工智能都围绕着语言、阅读和理解网页上的一切或从事智能对话和理解背景。你能谈谈能使得机器更好的解释事物的路径吗?你预见的事情,以及你从事的事情正朝什么方向进展,如果还没完全达到全面的通用人工智能的话?
Dean:我认为有趣的事之一是信息检索领域,这基本上就是谷歌早期做的工作。传统上,它并不试图真正理解用户在查询时需要什么。它更多的是关于查找包含或者接近这个单词的文档。有趣的是,在过去的四五年,我们已经开始发展出这样一种技术,可以更好地理解“car”这个单词的本质。知道 “car” 和 “cars”、 “automobile”、“passenger car”、“pickup truck” 在某种意义上都是相关联的,能够以更顺畅的方式匹配出文章,在许多语言理解任务上可以得出更好的结果。
我们能理解的不仅仅是单词,我们的理解还能达到这个水平,即理解在阐释上不同但意思相同的两个句子。这开始促使我们的语言理解达到这样一个层次:以更机器学习的方式理解更长得多的序列文本。
接下来几年我们有个目标,希望能够采集数以百计数以千计的文件,然后对这些文件内容展开一个对话。也许系统会自动总结这些文件,提问或者回答关于文件内容的问题。我认为这种水平的理解,是我们将真正去实现的高水平的语言理解。
High:似乎你和你们团队的成果已经开始应用在谷歌的各种产品当中:谷歌助手,谷歌新的对话虚拟助手;与 Amazon Echo 相竞争的 Google Home;以及为谷歌服务提供对话界面的信息 APP——Allo。你怎么看待谷歌最近的产品和服务?
Dean: 我目前领导的研究小组被称为谷歌大脑(Google Brain)。我们专注于建立大规模计算系统来实现机器学习,和做前沿的机器学习研究。只有机器学习技能或只有大规模计算技能的人才,往往不能完全发挥他们的才能,而同时拥有这两种不同技能的人才在一起工作,合作解决问题,通常会产生出意义重大的进步。我想这就是我们团队在这两个领域,在关于我们在这些难题上投入达到世界先进水平的计算力,以及我们怎样训练大有力的模型在我们关心的问题上都取得很大成功的原因之一。
通过理解我们的一些研究成果什么时候可以用于提升谷歌现有产品上,我们以往在长期研究上是相当机会主义的。我们与产品团队一起合作说,“嘿,我们认为这个机器学习研究将会非常有用。”有时这是需要放手去做的事情。其他时候我们小组和产品团队深度合作,让研究结果变成真实产品。
我们小组的研究人员曾发明了一种叫“从序列到序列学习(sequence-to-sequence learning)”的模型。这其中的理念是,你使用一个输入序列来预测某些输出结果序列。听起来有点抽象,但可以映射到许多你想要解决的真正问题。他们发表的研究论文最初是在语言翻译的背景下。输入序列可以是一个句子中的英文单词,一次一个。该模型被训练去输出对应的法国单词来创建一个法语句子,意思与输入的英语句子相同。这不同于其他机器翻译系统,别的机器翻译系统往往是问题的代码和子件——也许使用了机器学习或统计模型,然后将它拼接在一起。相比与那个方法,这个系统是一个完全的机器学习,端到端系统,在这个系统中你用语言不同但表达的意思相同的成对的句子作为数据来训练,然后系统就能学会将一种语言翻译另一种语言。
在其他语境中,这种通用模型非常有用。Gmail 团队采用了它,把它作为我们称之为“智能回复”特征的基础,其中输入序列是一封刚收到的邮件,而通过序列是根据刚收到邮件的语境而做出的对回复内容的预测。例如,你也许会收到一封这样的邮件,“嘿,我们想邀请你参加感恩节晚宴。如果能来请回复。”回复通常来说可能是这样。“是的,我们很想去。我们要带些什么?”或者“不好意思,我们去不了,”或者与此语境下相关的类似的回复。它是同一个基本模型,只是用了不同的数据集来训练。
High:潜在的研究应用以及 Google Brain 做出的突破,如何部署在谷歌传统的产品服务中?
Dean: 我们已经开始将这个流程变得规范一点。五年前,当我们最初创建机器学习研究团队去研究海量计算和深度神经网络如何解决问题时,公司里还没有太多人使用这些方法。我们找到了一些感觉领域,在这些领域我们感觉他们是有效地,包括语音识别系统,所以我们与语音识别团队密切协作,将深度神经网络配置为语音识别系统的一部分,并且在识别准确率上取得了实质性进展。然后我们和各种计算机视觉相关团队合作,比如图片搜索和街景服务团队,从而训练模型在给定的各种图片的原始像素下做有趣的事情,比如从图片中提取文本或者理解图片内容是什么(美洲豹、垃圾车等等)。
有趣的是,随着时间的推移,更多的团队开始采用这些方法,因为他们总会听说另一个团队正在尝试新的东西并取得了好成果。我们会帮助这样这些团队建立联系,或者提供一些关于在特定问题情境中如何使用这些方法的基本建议。我们后来把这个流程做得更规范了一些,所以现在我们有一个专门的团队做外展服务。这是为正在产品中尝试使用这些机器学习模型的团队建立联系的第一点。他们会描述他们的问题,然后外展服务团队会告诉他们:噢,听起来很像另外 XX 团队的问题,这个解决方案很有效果,试试并记得给我们反馈。使用这些方法的团队在数量上有非常大的增长,在 2011 年、2012 年只有几个团队,现在已经发展到 200 多个,并且可能已有几千人在使用我们团队创建的软件训练这种模型。
High:你同时也是 Google 开源机器学习库 TensorFlow 的主要创始人。 和其他几个大公司一样,谷歌专注于开发开源 AI 技术。您对使用开源人工智能技术的理论基础及优势有什么看法?
Dean: 现在有许多表达不同机器学习算法的不同框架,并且都还是开源项目 。有更多选择,我认为挺好的,但如果我们可以开发出能获得机器学习社区支持,大家一起来改进的东西,这样也很好。这些框架都在尝试着相似的工作,所以如果我们能将它们放在一起形成一个库供大家采用和使用,这样是很好的。这样做,可以更为简单地表达机器学习想法。传统方式是把探索出来的想法写成论文,做一些实验,而且他们通常不会公开代码,不允许其他人再做这些实验。作为一个研究者,你正在看某人的论文,并尝试将你自己的技术与其对比。通常,因为论文中没有代码,你只能猜测那些代码会是什么。作者并不是有意省去了大量细节。论文作者也许会使用「我们使用了低的学习率」一样的描述,然而你关心的是他们使用了 .0001 的学习率,在一万步后降低到 .0005。建立一个人们可以用代码表达机器学习理念,并把这些研究模型和想法以可执行的方式发布出来的软件架构,使得机器学习理念可以在社区中快速传播。
对于我们自己而言,它也方便了我们与谷歌外部人员的合作。通常我们暑期会招聘实习生,过去他们大部分已经完成了实习期的项目,但是他们仍在写这方面的论文。然后他们离开了谷歌,再也接触不到谷歌的电脑,所以他们很难继续完成论文最后的工作,运行更多的实验。现在他们使用开源或者 TensorFlow 就可以很快做到,甚至可以找到平台上的人来帮忙。我们正在教谷歌的工程师学习通用机器学习,并把 TensorFlow 作为基本的教学工具。
High:谷歌的优势之一是它拥有大量 AI 和机器学习领域的人才。谷歌研究主管Peter Norvig 估测,全球超过 5% 的机器学习顶尖专家都在谷歌工作。谷歌如何做到对这些天才有这么大的吸引力?鉴于这涉及到多个不同的学科的交叉——计算机科学、工程、神经科学、生物学、数学,你怎么把这些人才安排到最适合他们的位置?
Dean: 因为我们涉足的领域很多,所以我们需要拥有多种专业知识的人。我发现,当你把具有不同专业知识的人聚在一起去解决问题时,你会发现最终得到结果比那些只具备一种专业知识的一大群人一起做出来的要好。总的来说,你最终做的事情,没有人可以单独做出来。我们的机器学习团队是一个很好的例子。我们有像我一样在建设大规模计算系统方面有很多经验的人,然后我们也有世界级的机器学习研究人员。把这些类型的人结合起来是一个非常强大的团队。机器学习正在接触很多不同的领域。我们正在做的工作涉及医疗、机器人和计算机科学里的一大堆领域,这非常的好。我们团队有数位神经科学专家。
很快我们将开始一个有趣的实验,它被称为“谷歌大脑培训项目”。这些人在我们的团队工作一年基本上是学习怎么去做机器学习研究。我们有大量的申请者,但是最后这个项目只会留下 28 个人。他们来自不同的背景,处于职业生涯的不同阶段。有的刚刚完成本科学业,有些已经读完博士,有的刚读完博士后,有些已经在不同的领域有过工作经历。他们有不同的学科背景,包括计算机科学、统计学、数学、生物学、物理学,从解决问题的角度来说,我认为这是一个极好的结合。
High:我很好奇,有很多不以技术为中心的传统公司也会使用人工智能和机器学习,你会在多大程度这些传统公司交流与合作?你如何看待采用创新曲线(市场采用新型或创新产品的速度)?显然这涉及了不同公司甚至是不同行业,但也有一些领先的传统行业开始利用人工智能,包括医疗、金融服务公司、有大量非结构化数据需要处理的公司。你是否曾经有机会与传统行业的公司互动或者谈论他们在更加传统的环境中走向人工智能的过程?
Dean:其他行业的大部分公司在把机器学习应用到业务方面,可能不如谷歌或者其他高科技公司那样深远。我认为随着时间推移,最终大部分公司都会越来越多地应用机器学习,因为机器学习会给他们的业务带来很大的能量和转型。在与一些大的医疗组织建立合作关系上,我们有过多次讨论,看看机器学习可以为这个领域解决什么样的问题。我们最近开发了一个机器学习云产品,可以让人们在谷歌云基础设施上运行机器学习算法。有很多公司对于他们怎么在起业务背景下使用这个产品感兴趣。
我认为要实现这个转变的途径之一,要经历几个层次。在这些层次中你能使用 AI 技术和机器学习方法来解决问题。在一些领域,了解图像中有什么东西,对很多行业来说是普遍有用的。谷歌和其他公司正在提供使用简便的接口,你不需要知道什么机器学习的知识就可以使用这个接口。你可以只给出一个图像,然后说“跟我说说这个图像”,软件工程即使没有机器学习方面的技能就可以使用,他们得到的信息会像是“照片上是一个体育场,人们在那里打棒球,而且图像中还有一堆文字,文字内容是……”即使没有应用机器学习,这也是非常有用的。
然后将已开发好的模型用公司的数据再次训练得到一个定制的方案,而不需要做核心机器学习研究去开发一个全新模型。有一个好例子,我们已经应用序列到序列的成果,解决了谷歌六七个不同的难题。另一个好例子,有一个模型可以采集图像然后找出图像中有趣的部分。这个通用模型的一个使用案例是,检测街景图片中的文本信息。你想要能去读取所有的文本,但是首先,你必须能够在店面、路标等上面找到它。这个通用模型同样适用于在医疗设置中,当你诊断糖尿病患者视网膜病变时,你给出一张视网膜的扫描图片,你想要找到这个图片中的病变的指标。这是相同的模型结构,只是换了不同的数据。在这里不是找出街景图片的文本,而是指出视网膜扫描图像中的病变部位。我相信这个通用方法可以很好地解决各类型的难题。
High:2016 年 3 月,你在韩国现场目睹了 AlphaGo 的首场胜利。亲眼见证这个成果的感受如何?鉴于人工智能已经更广泛地影响到了我们的日常生活,你如何看待这种世界博览会般的展示,以及人工智能对激发人类想象力和好奇心的广泛影响?
Dean:我在现场观看了首场比赛,赛程的一半时间我都留在韩国。那种激动的心情真的难以言说。有 3 亿中国人现场观看了首场比赛直播,他们用了 8 个电视频道,每场都有不同的评论员报道这个比赛。韩国也处于同样的兴奋状态。真是很精彩。
我认为这种高调的事件,展示了与人工智能相关的各种难题取得了重大意义的进步。我需要指出的是,AlphaGo的大部分工作都是我们伦敦的 DeepMind 团队完成。在项目开始的阶段我们与他们有过一些合作,他们还使用了我们的机器学习软件来训练一些 AlphaGo 模型。他们还使用了张量处理单元(Tensor Processing Unit)——这是一种谷歌设计的定制机器学习硬件芯片,在某种意义上来说这是 AlphaGo 的比赛中的额外的“秘密武器”。人们注意到计算机现在拥有了四五前不曾有的能力,这使我们感到兴奋。在全球范围内,计算机科学系机器学习课程的招生量已经猛增。我认为这个意义重大。受益的不仅仅是计算机科学,还包括公司和业界。有越多聪明的人思考这类问题,我们的社会就会更进步。
High:许多科技界的知名人士比如埃隆·马斯克、比尔·盖茨 和 斯蒂芬·霍金都对人工智能的安全问题发出过警告。你怎么看到这方面的风险?当你对人工智能的思考不断进步成熟时,你如何把这方面的风险也考虑进去?
Dean:我觉得我并不太赞同你提到的那些人所担忧的末日场景。我觉得那不够贴近现实。我确实认为 AI 会带来社会变革,首先最大的问题就是自动化比较难进行,我们有大量的劳动力会参与到其中。有些事情会被自动化代替,尽管不是完全代替。电脑会以多种方式给予我们帮助,比如阅读医学图像数据,这是一个狭窄但是高技能的领域。我认为电脑不久之后就会相当擅长这方面的工作,更别提自动驾驶了。我不确定政府都在认真思考这些技术的一些影响,以及这对社会总的来说意味着什么。我认为这才是急切需要担忧的。确保决策者仔细考虑这些类型的问题,将是一个非常重要的一步。
Reference
识别门牌号的移动应用
大规模Tensorflow网络的一些技巧
在Android上使用Tensorflow
在移动平台上使用tensorflow图片分类 (android and ios)
在Android上使用Tensorflow
在Android端使用TensorFlow
新手向的TensorFlow学习之路2(Learning paths 2)
利用TF重训练Google Inception模型
TFLearn: Deep learning library featuring a higher-level API for TensorFlow.
Neural Networks (General)
Deep Learning for Java
将 TensorFlow 移植到 Android手机,实现物体识别、行人检测和图像风格迁移详细教程
02:一文全解:利用谷歌深度学习框架Tensorflow识别手写数字图片(初学者篇)
TensorFlow深度学习,一篇文章就够了
TensorFlow 资源大全中文版
GitHub 上 57 款最流行的开源深度学习项目
人人都可以做深度学习应用:入门篇
9 个超酷的深度学习案例