
会计算的机器设备。——DeepCreator
计算机是怎样跑起来的
内容简介
本书倡导在计算机迅速发展、技术不断革新的今天,回归到计算机的基础知识上。通过探究计算机的本质,提升工程师对计算机的兴趣,在面对复杂的最新技术时,能够迅速掌握其要点并灵活运用。
本书以图配文,以计算机的三大原则为开端、相继介绍了计算机的结构、手工汇编、程序流程、算法、数据结构、面向对象编程、数据库、TCP/IP 网络、数据加密、XML、计算机系统开发以及SE 的相关知识。
目录
第1章 计算机的三大原则 1
1.1 计算机的三个根本性基础 3
1.2 输入、运算、输出是硬件的基础 4
1.3 软件是指令和数据的集合 6
1.4 对计算机来说什么都是数字 8
1.5 只要理解了三大原则,即使遇到难懂的最新技术,也能轻松应对 9
1.6 为了贴近人类,计算机在不断地进化 10
1.7 稍微预习一下第2章 13
第2章 试着制造一台计算机吧 15
2.1 制作微型计算机所必需的元件 17
2.2 电路图的读法 21
2.3 连接电源、数据和地址总线 23
2.4 连接I/O 26
2.5 连接时钟信号 27
2.6 连接用于区分读写对象是内存还是I/O的引脚 28
2.7 连接剩余的控制引脚 29
2.8 连接外部设备,通过DMA输入程序 34
2.9 连接用于输入输出的外部设备 35
2.10 输入测试程序并进行调试 36
第3章 体验一次手工汇编 39
3.1 从程序员的角度看硬件 41
3.2 机器语言和汇编语言 44
3.3 Z80 CPU的寄存器结构 49
3.4 追踪程序的运行过程 52
3.5 尝试手工汇编 54
3.6 尝试估算程序的执行时间 57
第4章 程序像河水一样流动着 59
4.1 程序的流程分为三种 61
4.2 用流程图表示程序的流程 65
4.3 表示循环程序块的“帽子”和“短裤” 68
4.4 结构化程序设计 72
4.5 画流程图来思考算法 75
4.6 特殊的程序流程——中断处理 77
4.7 特殊的程序流程——事件驱动 78
COLUMN 来自企业培训现场 电阻颜色代码的谐音助记口诀 82
第5章 与算法成为好朋友的七个要点 85
5.1 算法是程序设计的“熟语” 87
5.2 要点1:算法中解决问题的步骤是明确且有限的 88
5.3 要点2:计算机不靠直觉而是机械地解决问题 89
5.4 要点3:了解并应用典型算法 91
5.5 要点4:利用计算机的处理速度 92
5.6 要点5:使用编程技巧提升程序执行速度 95
5.7 要点6:找出数字间的规律 99
5.8 要点7:先在纸上考虑算法 101
第6章 与数据结构成为好朋友的七个要点 103
6.1 要点1:了解内存和变量的关系 105
6.2 要点2:了解作为数据结构基础的数组 108
6.3 要点3:了解数组的应用——作为典型算法的数据结构 109
6.4 要点4:了解并掌握典型数据结构的类型和概念 111
6.5 要点5:了解栈和队列的实现方法 114
6.6 要点6:了解结构体的组成 118
6.7 要点7:了解链表和二叉树的实现方法 120
第7章 成为会使用面向对象编程的程序员吧 125
7.1 面向对象编程 127
7.2 对OOP的多种理解方法 128
7.3 观点1:面向对象编程通过把组件拼装到一起构建程序 130
7.4 观点2:面向对象编程能够提升程序的开发效率和可维护性 132
7.5 观点3:面向对象编程是适用于大型程序的开发方法 134
7.6 观点4:面向对象编程就是在为现实世界建模 134
7.7 观点5:面向对象编程可以借助UML设计程序 135
7.8 观点6:面向对象编程通过在对象间传递消息驱动程序 137
7.9 观点7:在面向对象编程中使用继承、封装和多态 140
7.10 类和对象的区别 141
7.11 类有三种使用方法 143
7.12 在Java和.NET中有关OOP的知识不能少 145
第8章 一用就会的数据库 147
8.1 数据库是数据的基地 149
8.2 数据文件、DBMS和数据库应用程序 151
8.3 设计数据库 154
8.4 通过拆表和整理数据实现规范化 157
8.5 用主键和外键在表间建立关系 159
8.6 索引能够提升数据的检索速度 162
8.7 设计用户界面 164
8.8 向DBMS发送CRUD操作的SQL语句 165
8.9 使用数据对象向DBMS发送SQL语句 167
8.10 事务控制也可以交给DBMS处理 170
COLUMN 来自企业培训现场 培训新人编程时推荐使用什么编程语言? 172
第9章 通过七个简单的实验理解TCP/IP网络 175
9.1 实验环境 177
9.2 实验1:查看网卡的MAC地址 179
9.3 实验2:查看计算机的IP地址 182
9.4 实验3:了解DHCP服务器的作用 184
9.5 实验4:路由器是数据传输过程中的指路人 186
9.6 实验5:查看路由器的路由过程 188
9.7 实验6:DNS服务器可以把主机名解析成IP地址 190
9.8 实验7:查看IP地址和MAC地址的对应关系 192
9.9 TCP的作用及TCP/IP网络的层级模型 193
第10章 试着加密数据吧 197
10.1 先来明确一下什么是加密 199
10.2 错开字符编码的加密方式 201
10.3 密钥越长,解密越困难 205
10.4 适用于互联网的公开密钥加密技术 208
10.5 数字签名可以证明数据的发送者是谁 211
第11章 XML究竟是什么 215
11.1 XML是标记语言 217
11.2 XML是可扩展的语言 219
11.3 XML是元语言 220
11.4 XML可以为信息赋予意义 224
11.5 XML是通用的数据交换格式 227
11.6 可以为XML标签设定命名空间 230
11.7 可以严格地定义 XML的文档结构 232
11.8 用于解析XML的组件 233
11.9 XML可用于各种各样的领域 235
第12章 SE负责监管计算机系统的构建 239
12.1 SE是自始至终参与系统开发过程的工程师 241
12.2 SE未必担任过程序员 243
12.3 系统开发过程的规范 243
12.4 各个阶段的工作内容及文档 245
12.5 所谓设计,就是拆解 247
12.6 面向对象法简化了系统维护工作 249
12.7 技术能力和沟通能力 250
12.8 IT不等于引进计算机 252
12.9 计算机系统的成功与失败 253
12.10 大幅提升设备利用率的多机备份 255
深入理解计算机系统

Computer Systems: A Programmer’s Perspective
目录
出版说明
关于第二次印刷的几点说明
译 序
关于术语的翻译
在第二次印刷中一些重要术语的修订
前 言
关于作者
第1章 计算机系统漫游
1.1 信息就是位十上下文
1.2 程序被其他程序翻译成不同的格式
1.3 了解编译系统如何工作是大有益处的
1.4 处理器读并解释储存在存储器中的指令
1.5 高速缓存
1.6 形成层次结构的存储设备
1.7 操作系统管理硬件
1.8 利用网络系统和其他系统通信
1.9 下一步
1.10 小结
第1部分 程序结构和执行
第2章 信息的表示和处理
.2.1 信息存储
2.2 整数表示
2.3 整数运算
2.4 浮点
2.5 小结
第3章 程序的机器级表示
3.1 历史观点
3.2 程序编码
3.3 数据格式
3.4 访问信息
3.5 算术和逻辑操作
3.6 控制
3.7 过程
3.8 数组分配和访问
3.9 异类的数据结构
3.10 对齐(alignment)
3.11 综合:理解指针
3.12 现实生活:使用gdb调试器
3.13 存储器的越界引用和缓冲区溢出
3.14 浮点代码
3.15 在c程序中嵌入汇编代码
3.16 小结
第4章 处理器体系结构
4.1 y86指令集体系结构
4.2 逻辑设计和硬件控制语言hcl
4.3 y86的顺序(sequential)实现
4.4 流水线的通用原理
4.5 y86的流水线实现
4.6 小结
第5章 优化程序性能
5.1 优化编译器的能力和局限性
5.2 表示程序性能
5.3 程序示例
5.4 消除循环的低效率
5.5 减少过程调用
5.6 消除不必要的存储器引用
5.7 理解现代处理器
5.8 降低循环开销
5.9 转换到指针代码
5.10 提高并行性
5.11 综合:优化合并(combing)代码的效果小结
5.12 转移预测和预测错误处罚
5.13 解存储器性能
5.14 现实生活:性能提高技术
5.15 确认和消除性能瓶颈
5.16 小结
第6章 存储器层次结构
6.1 存储技术
6.2 局部性
6.3 存储器层次结构
6.4 高速缓存存储器
6.5 编写高速缓存友好的代码
6.6 综合:高速缓存对程序性能的影响
6.7 综合:利用程序中的局部性
6.8 小结
第2部分 在系统上运行程序
第7章 链接
7.1 编译器驱动程序
7.2 静态链接
7.3 标文件
7.4 可重定位目标文件
7.5 符号和符号表
7.6 符号解析
7.7 重定位
7.8 可执行目标文件
7.9 加载可执行目标文件
7.10 动态链接共享库
7.11 从应用程序中加载和链接共享库
7.12 与位置无关的代码(pic)
7.13 处理目标文件的工具
7.14 小结
第8章 异常控制流
8.1 异常
8.2 进程
8.3 系统调用和错误处理
8.4 进程控制
8.5 信号
8.6 非本地跳转
8.7 操作进程的工具
8.8 小结
第9章 测量程序执行时间
9.1 计算机系统上的时间流
9.2 通过间隔计数(interval counting)来测量时间
9.3 周期计数器
9.4 用周期计数器来测量程序执行时间
9.5 基于gettimeofday函数的测量
9.6 综合:一个实验协议
9.7 展望未来
9.8 现实生活:k次最优测量方法
9.9 得到的经验教训
9.10 小结
第10章 虚拟存储器
10.1 物理和虚拟寻址
10.2 地址空间
10.3 虚拟存储器作为缓存的工具
10.4 虚拟存储器作为存储器管理的工具
10.5 虚拟存储器作为存储器保护的工具
10.6 地址翻译
10.7 案例研究:pentium/linux存储器系统,
10.8 存储器映射
10.9 动态存储器分配
10.10 垃圾收集
10.11 c程序中常见的与存储器有关的错误
10.12 扼要重述一些有关虚拟存储器的关键概念
10.13 小结
第3部分 程序间的交互和通信
第11章 系统级i/o
11.1 unix i/o
11.2 打开和关闭文件
11.3 读和写文件
11.4 用rio包进行健壮地读和写
11.5 读取文件元数据
11.6 共享文件
11.7 i/o重定向
11.8 标准i/o
11.9 综合:我该使用哪些i/o函数?
11.10 小结
第12章 网络编程
12.1 客户端-服务器编程模型
12.2 网络
12.3 全球ip因特网
12.4 套接字接口
12.5 web服务器
12.6 综合:tinyweb服务器
12.7 小结
第13章 并发编程
13.1 基于进程的并发编程
13.2 基于i/o多路复用的并发编程
13.3 基于线程的并发编程
13.4 多线程程序中的共享变量
13.5 用信号量同步线程
13.6 综合:基于预线程化的并发服务器
13.7 其他并发性问题
13.8 小结
附录a 处理器控制逻辑的hcl描述
a.1 hcl参考手册
a.2 seq
a.3 seq+
a.4 pipe
附录b 错误处理
b.1 unix系统中的错误处理
b.2 错误处理封装函数
b.3 csapp.h头文件
b.4 csapp.c源文件
参考文献
索 引
NB学校的NB课程的NB教材——CSAPP
CMU是全美以至全球公认的CS最猛的大学之一,没办法,作为CS的发源地,再加上三位神一样的人先后在此任教:Alan Perlis(CS它祖宗+第一届Turing奖获得者)、Allen Newell(AI缔造者+Turing奖获得者)和Herbert Simon(AI缔造者+Turing奖获得者+Nobel经济学奖获得者,当代的Leibniz,偶佩服到死的一个天神下凡级的人物,他的自传 Models of my life偶特意珍藏了两本),三位巨头培养出一大摊小神级别的人物,这一大摊小神级的人物又培养出一大坨天才级人物(其中就有跳槽猥琐男开复哥)。
偶估计那个钢铁猥琐男和银行经管男在投资时肯定不会想到,这个以他们名字命名的破烂学院在未来会如此NB,尤其还是在CS这个上如此NB。
NB学校,自然用NB教材,更何况是CS里非常重要的计算机导论,而CMU的计算机导论教材就是CMU计算机系主任的作品:CSAPP。
CSAPP全称Computer Systems A Programmer’s perspective,国内通常的书名翻译是《深入理解计算机系统》(然而偶认为这本书叫做《程序员所需要了解的计算机知识》更为合适)。
偶在本科时曾经有过一个疑问,那就是作为一个程序员,究竟需要对计算机的硬件了解到什么程度呢,或者说,算法、数据结构和程序设计语言之外的东东,我们是否有必要了解,需要了解到什么程度呢?
至今记得学习计算机组成原理时,老师在上面拿着某个疑似打字机的东东给我们一顿演示,说这就是什么可编程逻辑器件,然后给我们展示了各种电路图,总之偶是看不明白,也想不明白这些与非门或非门异或门**门xx门会对偶编程序有什么帮助,所以这门课后来偶压根就听过,反正听也听不懂,听懂了也用不上(至少偶当时是这么想的)。
之后学习编译原理,偶承认写个语法制导的小型翻译器是挺磨练人的编程水平的,但符号流,语法制导,语义分析这些东东实际中的效用有多大,偶真没感觉到。至少偶身边没人用语法制导写interpreter,编译原理对偶的作用就是大大简化了学正则表达式的过程,除此之外,别无它用(别鄙视偶)。
至于操作系统,偶学完了之后脑子中除了进程和局部性这两个概念之外,可以说是一片空白,偶觉得,既然OS的设计初衷就是为程序员提供一个可编程易理解的通用接口,那我们为什么还得去把这个接口扒开然后去研究诸如硬盘的磁道有几圈寻道时间有几毫秒此类的问题,a fucking waste of time。
即使是在CS中,80/20原则依然适用,程序员平时用到的超过九成的计算机知识基本来自于这些计算机核心课程中的不到一成的内容,至于剩下的九成内容,虽然不至于没用,然而它们没有大用,至少,它们不会对你造成什么损害。举个例子,你可以不知道DMA的原理,不知道BNF范式,你依然可以编出不错的程序;但是如果你连内存布局分配或是同步限制区都不清楚的话,那就囧大了,要不然你就会在为什么不能初始化一个大小为16MB的局部变量这样的 NC问题上纠结半天,或者是对着多线程程序里变幻莫测的全局变量百思不得其解。
所以说CMU的两位作者以及CSAPP这本书背后的劳动者和贡献者是非常NB的,他们非常巧妙的把程序设计及优化、数字电路基础、指令集体系、汇编语言、存储器体系结构、链接与装载、进程、虚存这一摊来自各不同的学科的核心知识点搅和在一起,并以程序员的视角呈现,所以这本书的书名叫A programmer’s perspective。
曾经有人说过这本书名(指的是中文译名)不副实,讲解的并不深入。的确,这本书虽然涉及了计算机学科的各个方面,然而很多东西都是点到为止的感觉,作者的意思也很明确,这本书属于导论的性质(CSAPP对应CMU的 Introduction to computer systems这门本科课程,属于导论性质)。按照国内CS的课程安排的话,CSAPP介于计算机组成原理和操作系统之间,它的目的就是让你对这些计算机的基础学科有一个Overview,并尽可能的把作为一个程序员所必须了解的那些essence:那不到一成的计算机核心知识,尽早的灌输给你。
接下来聊聊偶阅读CSAPP的体会:
这本书的简介(引言)部分简介明了:一个简单的hello world程序在计算机上的执行过程,预处理->编译->汇编->链接->生成可执行目标文件->载入内存->数据流->屏幕输出显示,没有一句废话,简介扼要,总结成一句:计算机系统=位+上下文。
关于二进制的内容个人感觉有些冗余,这部分内容偶基本是一扫而过,毕竟从小到大这些内容学了都快有十多遍了,而平时编程真能用到的二进制技巧基本也就移位和bit flag这两招。不过这章里有不少small tricks值得一耍(最经典的就是不用临时变量交换两个数)。话说回来,真要想在二进制上玩出花来,参考Hacker’s delight会有更大的惊喜。
程序的机器级表示这一章偶花了不少时间阅读,毕竟偶没学过汇编,基础基本为0。不过这本书里出现的汇编指令绝大多数都由运算、取数存数、跳转这三种指令所组成,所以在阅读上不会存在任何难度。
这部分融合了程序员所需了解的编译和汇编这两样课程中的基础知识:想知道for、do..while、while三种循环的实质性区别?想知道多重if和 switch的本质区别?想知道数组的存储方式?想知道数组下标读取和指针读取的区别?想知道递归过程调用的背后实现机理?看看这一章,相信你会对C语言乃至程序设计语言有更深的理解。
指令集&体系结构这一章,两位作者为了让读者更好的理解指令集(X86),别具一格的搞出了一个简化版的Y86指令集,并用其表示基本的运算和控制,甚至连数字电路的HCL都来了一笔(暴汗)。数据流、组合逻辑和流水线,图示+详细的讲解,一目了然。国内的计组教科书应该多借鉴一下。
程序性能优化这一章对程序员尤其实用,毕竟,正如TDD和XP的开创者Kent Beck所说,make it run, make it right, make it fast。而第三步又是最麻烦的一步,确认和消除性能的瓶颈,有时比Debug还要恐怖,所以Knuth大神说:Premature optimization is the source of evil。
CSAPP通过展示一个简单的连续数求和和求积运算的小程序,通过性能监测,一步步的优化性能:减少过程调用、消除无关存储器引用、将下标引用切换到指针这些还是比较好理解的,然而后面的根据指令集展开循环、通过指令集来编写更具并行性的代码以及转移预测代价这些机器相关的优化的东东就开始颠覆我的世界观了,原来程序还可以这么搞,I服了U。
唯一的遗憾就是这章的篇幅有些短小,对程序员最为重要的机器无关的程序优化介绍的也并不充分,与此相比,偶感觉programming pearls和practice of programming里面对性能优化的介绍更胜一筹。
存储器体系结构的内容用五个字概括就是:利用局部性。
只有了解了计算机的梯形存储器体系结构,才能体会到为什么同样逻辑的程序会产生如此之大的性能差距,虽然计算机设计者的初衷是把存储器当成一个巨型数组。然而这个大号数组的不同体位的差距还是非常大地,搞不好就郁闷鸟。尤其是DRAM-Disk这一段,足足10的六次方的差距,所以CSAPP专门开了VM 一章来详细讲述。
链接这部分内容篇幅不多,原理上讲的很简洁,文件节和符号解析表只是给出了几个图示,并没有过多的关注其实现。CSAPP把重点放在了链接对源代码产生的影响,同时也让偶再次理解到了全局变量很邪恶。动态链接部分让偶恍然大悟,.net里面的反射和程序集,放到C里面就是动态调用和共享库,都是相通的,无非C的代码更诡异一些。
异常控制流这一章的名字比较囧,以至于我刚开始认为它会介绍点诸如try…catch的异常处理机制。然而看了才明白,它介绍的是更为广义的exception,既包括硬件中断,也包括故障中断,比如说陷入(trap)和故障(fault)。
这一章做的比较绝的是,通过讲述异常流,引入了OS中最核心的概念:进程。然而它并不在进程的具体特性上下文章,而是通过讲述unix下进程相关的api 及使用,从一种程序员的角度告诉你,进程是这么用的,进程之间是这么交换信息的。到最后捎带介绍了一下C里面的非局部跳转(更加强大的Goto,也就是 setjmp和longjmp),别以为只有C++和Java才有异常处理机制,C一样可以做到。
程序的时间度量这一章感觉用处不大,遂跳过
虚拟内存这一章从原理和实现两个不同的层面介绍了存储器体系结构的核心部分:VM。说实话,之前学习VM顶多就是冲着局部性去的,但没想到VM可以做的事有这么多,无论是存储器磁盘映射,还是malloc在磁盘上分配空间返回地址至PTE,都让偶对VM有了一个崭新的认识,原来VM还可以这么用。为了帮助读者深入理解内存的分配机制,作者甚至搞出了一个malloc的实现,从源代码来讲解内存分配、碎片合并、垃圾回收这些概念,帅气。
系统级IO,网络编程以及并发编程这些东东打算之后再慢慢研究,遂跳过
当然,要想深入学习的话,好书有的是,OS有Tanenbaum老爷子的Modern operating systems,计组有Stanford校长的量化研究和软/硬接口,编译自然就是Aho的龙书,链接可以参考Levine的 Linkers&Loaders,程序设计语言原理可以阅读Scott的Programming language pragmatics。如果需要更多的资源,可以参考CSAPP书后的Bibilography。
说实话,放低要求的话,CSAPP已经做的相当不错了。换句话说,把这本书看明白,作为程序员应该了解的OS、编译和机组的核心理论也就明白的差不多了。同时,鉴于现在越来越多的程序员还纠结在C#/Java这样的层次上,CSAPP已经相当相当相当的深入了,:-)
PS: 这本书刚刚出了第二版,不少内容都有更新,希望国内尽早引进。
Acronyms:
CS=Computer Science
CMU= Carnegie Mellon University
CSAPP=Computer Systems A Programmer’s perspective
VM= Virtual Memory
PTE= Page Table Entry
最后补充几句,拜托豆瓣上的各位大侠做书评时,好歹把书看一遍在评论,首先别人云亦云的,他捧你也捧,他砸你也砸的;其次,别就写那么一两句套话,诸如”这本书写的很精彩”这类的话,写了还不如不写;最后,书最重要的是内容,不是纸张开本这些参数,所以请别上来就直接拿书的纸张开涮,就算是要开涮也好歹介绍下书的内容,这是书评,不是纸评,thanks。
我提供一些资源给大家,我也是CS在校生,大家共勉。
CMU和ICS的课号为213,然后他的courseweb在这:
http://www.cs.cmu.edu/~213/index.html
里面有CMU往年的CS213的所有exam资料和答案:
http://www.cs.cmu.edu/~213/exams.html
还有另外一个资源是:
http://www.cs.cmu.edu/~213/lectures/
这里是FTP服务器,提供所有CS213的slides和笔记。
1.CSAPP 第一版英文电子书:
http://ishare.iask.sina.com.cn/f/6142916.html
2.CSAPP 第一版自带代码库:
http://ishare.iask.sina.com.cn/f/9878566.html
- CSAPP 第一版solution manual:
http://wenku.baidu.com/view/814bf32d2af90242a895e540.html - CSAPP 第二版的中文版的前半部分(不大有用):
http://ishare.iask.sina.com.cn/f/13864923.html
程序是怎样跑起来的

内容简介
本书从计算机的内部结构开始讲起,以图配文的形式详细讲解了二进制、内存、数据压缩、源文件和可执行文件、操作系统和应用程序的关系、汇编语言、硬件控制方法等内容,目的是让读者了解从用户双击程序图标到程序开始运行之间到底发生了什么。同时专设了“如果是你,你会怎样介绍?”专栏,以小学生、老奶奶为对象讲解程序的运行原理,颇为有趣。
目录
第1章 对程序员来说CPU是什么 1
1.1 CPU的内部结构解析 3
1.2 CPU是寄存器的集合体 6
1.3 决定程序流程的程序计数器 9
1.4 条件分支和循环机制 10
1.5 函数的调用机制 13
1.6 通过地址和索引实现数组 16
1.7 CPU的处理其实很简单 17
第2章 数据是用二进制数表示的 19
2.1 用二进制数表示计算机信息的原因 21
2.2 什么是二进制数 23
2.3 移位运算和乘除运算的关系 25
2.4 便于计算机处理的“补数” 27
2.5 逻辑右移和算术右移的区别 31
2.6 掌握逻辑运算的窍门 34
COLUMN 如果是你,你会怎样介绍?——向小学生讲解CPU和二进制 38
第3章 计算机进行小数运算时出错的原因 41
3.1 将0.1累加100次也得不到10 43
3.2 用二进制数表示小数 44
3.3 计算机运算出错的原因 46
3.4 什么是浮点数 47
3.5 正则表达式和 EXCESS系统 50
3.6 在实际的程序中进行确认 52
3.7 如何避免计算机计算出错 55
3.8 二进制数和十六进制数 56
第4章 熟练使用有棱有角的内存 59
4.1 内存的物理机制很简单 61
4.2 内存的逻辑模型是楼房 65
4.3 简单的指针 67
4.4 数组是高效使用内存的基础 69
4.5 栈、队列以及环形缓冲区 71
4.6 链表使元素的追加和删除更容易 75
4.7 二叉查找树使数据搜索更有效 79
第5章 内存和磁盘的亲密关系 81
5.1 不读入内存就无法运行 83
5.2 磁盘缓存加快了磁盘访问速度 84
5.3 虚拟内存把磁盘作为部分内存来使用 85
5.4 节约内存的编程方法 88
5.5 磁盘的物理结构 93
第6章 亲自尝试压缩数据 97
6.1 文件以字节为单位保存 99
6.2 RLE 算法的机制 100
6.3 RLE 算法的缺点 101
6.4 通过莫尔斯编码来看哈夫曼算法的基础 103
6.5 用二叉树实现哈夫曼编码 105
6.6 哈夫曼算法能够大幅提升压缩比率 109
6.7 可逆压缩和非可逆压缩 110
COLUMN 如果是你,你会怎样介绍?——向沉迷游戏的中学生讲解内存和磁盘 114
第7章 程序是在何种环境中运行的 117
7.1 运行环境=操作系统+硬件 119
7.2 Windows克服了CPU以外的硬件差异 122
7.3 不同操作系统的API不同 124
7.4 FreeBSD Port帮你轻松使用源代码 125
7.5 利用虚拟机获得其他操作系统环境 127
7.6 提供相同运行环境的 Java虚拟机 128
7.7 BIOS和引导 130
第8章 从源文件到可执行文件 133
8.1 计算机只能运行本地代码 135
8.2 本地代码的内容 137
8.3 编译器负责转换源代码 139
8.4 仅靠编译是无法得到可执行文件的 141
8.5 启动及库文件 143
8.6 DLL文件及导入库 145
8.7 可执行文件运行时的必要条件 146
8.8 程序加载时会生成栈和堆 148
8.9 有点难度的Q&A 150
第9章 操作系统和应用的关系 153
9.1 操作系统功能的历史 155
9.2 要意识到操作系统的存在 157
9.3 系统调用和高级编程语言的移植性 160
9.4 操作系统和高级编程语言使硬件抽象化 161
9.5 Windows操作系统的特征 163
COLUMN 如果是你,你会怎样介绍?——向超喜欢手机的女高中生讲解操作系统的作用 170
第10章 通过汇编语言了解程序的实际构成 173
10.1 汇编语言和本地代码是一一对应的 175
10.2 通过编译器输出汇编语言的源代码 177
10.3 不会转换成本地代码的伪指令 180
10.4 汇编语言语法是“操作码+操作数” 182
10.5 最常用的mov指令 185
10.6 对栈进行push和pop 185
10.7 函数调用机制 187
10.8 函数内部的处理 189
10.9 始终确保全局变量用的内存空间 191
10.10 临时确保局部变量用的内存空间 196
10.11 循环处理的实现方法 199
10.12 条件分支的实现方法 202
10.13 了解程序运行方式的必要性 204
第11章 硬件控制方法 209
11.1 应用和硬件无关? 211
11.2 支撑硬件输入输出的IN指令和OUT指令 212
11.3 编写测试用的输入输出程序 215
11.4 外围设备的中断请求 218
11.5 用中断来实现实时处理 221
11.6 DMA可以实现短时间内传送大量数据 222
11.7 文字及图片的显示机制 224
COLUMN 如果是你,你会怎样介绍?——向邻居老奶奶说明显示器和电视机的不同 226
第12章 让计算机“思考” 229
12.1 作为“工具”的程序和为了“思考”的程序 231
12.2 用程序来表示人类的思考方式 232
12.3 用程序来表示人类的思考习惯 235
12.4 程序生成随机数的方法 237
12.5 活用记忆功能以达到更接近人类的判断 239
12.6 用程序来表示人类的思考方式 242
COLUMN 如果是你,你会怎样介绍?——向常光临的酒馆老板讲解计算机的思考机制 245
附录 让我们开始C语言之旅 247
C语言的特点 247
变量和函数 248
数据类型 249
标准函数库 250
函数调用 251
局部变量和全局变量 254
数组和循环 255
其他语法结构 256
计算的本质——深入剖析程序和计算机
Understanding Computation: From Simple Machines to Impossible Programs

目录
封面介绍 X
前言 XI
第1章 刚好够用的Ruby基础 1
1.1 交互式Ruby Shell 1
1.2 值 2
1.2.1 基本数据 2
1.2.2 数据结构 3
1.2.3 proc 4
1.3 控制流 4
1.4 对象和方法 5
1.5 类和模块 6
1.6 其他特性 7
1.6.1 局部变量和赋值 7
1.6.2 字符串插值 8
1.6.3 检查对象 8
1.6.4 打印字符串 8
1.6.5 可变参数方法(variadic method) 9
1.6.6 代码块 9
1.6.7 枚举类型 10
1.6.8 结构体 11
1.6.9 给内置对象扩展方法(Monkey Patching) 12
1.6.10 定义常量 13
1.6.11 删除常量 13
第一部分 程序和机器
第2章 程序的含义 17
2.1 “含义”的含义 18
2.2 语法 19
2.3 操作语义 19
2.3.1 小步语义 20
2.3.2 大步语义 40
2.4 指称语义 46
2.4.1 表达式 46
2.4.2 语句 49
2.4.3 应用 51
2.5 形式化语义实践 52
2.5.1 形式化 52
2.5.2 找到含义 53
2.5.3 备选方案 53
2.6 实现语法解析器 54
第3章 最简单的计算机 59
3.1 确定性有限自动机 59
3.1.1 状态、规则和输入 60
3.1.2 输出 60
3.1.3 确定性 61
3.1.4 模拟 62
3.2 非确定性有限自动机 65
3.2.1 非确定性 65
3.2.2 自由移动(free move) 71
3.3 正则表达式 74
3.3.1 语法 75
3.3.2 语义 78
3.3.3 解析 86
3.4 等价性 88
第4章 增加计算能力 97
4.1 确定性下推自动机 100
4.1.1 存储 100
4.1.2 规则 101
4.1.3 确定性 103
4.1.4 模拟 103
4.2 非确定性下推自动机 110
4.2.1 模拟 113
4.2.2 不等价 115
4.3 使用下推自动机进行分析 116
4.3.1 词法分析 116
4.3.2 语法分析 118
4.3.3 实践性 122
4.4 有多少能力 123
第5章 终极机器 125
5.1 确定型图灵机 125
5.1.1 存储 126
5.1.2 规则 127
5.1.3 确定性 131
5.1.4 模拟 131
5.2 非确定型图灵机 136
5.3 最大能力 137
5.3.1 内部存储 137
5.3.2 子例程 140
5.3.3 多纸带 141
5.3.4 多维纸带 142
5.4 通用机器 142
5.4.1 编码 144
5.4.2 模拟 145
第二部分 计算与可计算性
第6章 从零开始编程 149
6.1 模拟lambda演算 150
6.1.1 使用proc工作 150
6.1.2 问题 152
6.1.3 数字 153
6.1.4 布尔值 156
6.1.5 谓词 160
6.1.6 有序对 161
6.1.7 数值运算 161
6.1.8 列表 168
6.1.9 字符串 172
6.1.10 解决方案 174
6.1.11 高级编程技术 178
6.2 实现lambda演算 184
6.2.1 语法 184
6.2.2 语义 186
6.2.3 语法分析 191
第7章 通用性无处不在 193
7.1 lambda演算 193
7.2 部分递归函数 196
7.3 SKI组合子演算 201
7.4 约塔(Iota) 210
7.5 标签系统 213
7.6 循环标签系统 220
7.7 Conway的生命游戏 229
7.8 rule 110 231
7.9 Wolfram的2,3图灵机 234
第8章 不可能的程序 235
8.1 基本事实 236
8.1.1 能执行算法的通用系统 236
8.1.2 能够替代图灵机的程序 239
8.1.3 代码即数据 239
8.1.4 可以永远循环的通用系统 241
8.1.5 能引用自身的程序 245
8.2 可判定性 250
8.3 停机问题 251
8.3.1 构建停机检查器 251
8.3.2 永远不会有结果 254
8.4 其他不可判定的问题 258
8.5 令人沮丧的暗示 260
8.6 发生上述情况的原因 261
8.7 处理不可计算性 262
第9章 在“玩偶国”中编程 265
9.1 抽象解释 266
9.1.1 路线规划 266
9.1.2 抽象:乘法的符号 267
9.1.3 安全和近似:增加符号 270
9.2 静态语义 274
9.2.1 实现 275
9.2.2 好处和限制 281
9.3 应用 284
后记 285
编码——隐匿在计算机软硬件背后的语言

Code: The Hidden Language of Computer Hardware and Software
内容简介
本书讲述的是计算机工作原理。作者用丰富的想象和清晰的笔墨将看似繁杂的理论阐述得通俗易懂,你丝毫不会感到枯燥和生硬。更重要的是,你会因此而获得对计算机工作原理较深刻的理解。这种理解不是抽象层面上的,而是具有一定深度的。
目录
第1章 至亲密友
第2章 编码与组合
第3章 布莱叶盲文与二进制码
第4章 手电筒的剖析
第5章 绕过拐角的通信
第6章 电报机与继电器
第7章 我们的十个数字
第8章 十的替代品
第9章 二进制数
第10章 逻辑与开关
第11章 门
第12章 二进制加法器
第13章 如何实现减法
第14章 反馈与触发器
第15章 字节与十六进制
第16章 存储器组织
第17章 自动操作
第18章 从算盘到芯片
第19章 两种典型的微处理器
第20章 ASCII码和字符转换
第21章 总线
第22章 操作系统
第23章 定点数和浮点数
第24章 高级语言与低级语言
第25章 图形化革命
地基上的脚印-读《编码的奥秘》有感
屈指算来,这几年看过不少计算机书籍,根据经济学中的边际效益递减原理,读书带来的知识的增加和智力的乐趣开始减少,于是自然形成了看书的几个原则。写得晦涩难懂得的书不看。人生的时光宝贵,把时间浪费在研究难懂或错误的书籍上实在不值。爱因斯坦曾说过,用复杂的理论解释事实,成功的机会为零。书写得晦涩难懂,估计作者也没弄懂,这样读者更是觉得云山雾海的。我喜欢读通俗易懂的书。书中要有新的思想或新的技术,能给人带来智力上的乐趣。书要深入浅出地讲述,从历史到现在,挖掘技术的来龙去脉,这样才能真正理解技术或理论。工程实用的书应该非常详细具体,让人很容易上手实践。这就是《编码的奥秘》吸引我的原因。我幸运得象个孩子,找到了这个庞大而有神秘的建筑物的秘密通道,找到了地基,在上面发现了脚印,揭开了神秘的面纱。
你是否想知道计算机如何工作和运行的?你是否想了解计算机是如何一步一步创造出来的?你是否想了解计算机知识的来龙去脉?你是否想了解计算机的历史?你是否想制造出一台自己的计算机?你是否想知道硬件与软件的区别?你是否想知道电报机、电的原理?你是否想创造自己的编程语言?你是否想知道你买的电脑中说明书上说的主频、内存、显示器象素、显存的概念和意义?你是否想知道我们常用的十进制的由来?你是否一直迷惑于二进制的理解?你是否想知道那些赫赫有名的IT公司的历史和发展?你是否想探询那些天才是如何思考和发明的?你是否想象科学家一样思考?本书将一一为你揭开谜底。本书的内容涉及数理逻辑、布尔代数、组合数学、集合、物理、化学和电子学等等知识。作者用简单、通俗易懂、流畅的词汇清楚地解释了如此多而且深奥的知识!在作者的笔下,原来学问是可以这么迷人的。
一年前曾在书店翻过本书,看到本书写手电筒的原理和逻辑电路,就不以为意,谁知现在才知道犯了大错。最近总找到一本讲述计算机基本理论的书,于是在网上看了本书的前三章,没想到,一看就着迷了,立马买了一本。本书解决了困惑我多年的一些难题,以前迷惑、一知半解的理论一下子迎刃而解,读书的过程中,不时惊叹,“原来如此”,念念有词,坐立不安,强忍要仰天长啸的冲动,真是感觉漫卷诗书喜欲狂,实在是痛快淋漓,如同武侠小说中武林高手打通任督二脉似的。这是我看过的最好的计算机书籍,这是我多年以来梦寐以求的书。
本书使我开始真正了解计算机的运行原理,理解软件和硬件的区别。通过本书,我终于可以把原来学习的计算机知识用一根主线串联起来,那些知识一一浮现在我以前。以前硬啃《设计模式》,学习《C++程序设计语言》,远没有本书带给我的知识的提高和智力的乐趣。如果说,《设计模式》是近十年来最重要的设计领域的书籍,那么我认为,本书是未来二十年最重要的计算机入门和揭密书。
本书从最基本的问题出发,深入浅出地解释了各种原理,在解释完一个问题后,又提出下一个问题,引导读者思考,然后给出详细和清楚的解答,如此循环,读者很轻松地进入作者的思路,跟着作者一起探询计算机的奥秘。这种思考方式也许比单个知识点更加重要,它能培养人的科学思维方式、科学方法论。著名经济学家张五常在加大读硕士期间,从不缺课的习惯就是为了要学老师的思考方法。所有要考的试过了,就转旁听老师的课。有一次,赫舒拉发在课后问张五常:“你旁听了我六个学期,难道我所知的经济学你还未学全吗?”张五常回答说:“你的经济学我早从你的著作中学会了,我听你的课与经济学无关――我要学的是你思考的方法。”终于他发现自己也能象老师一样思考问题,认识到什么是重要的问题,什么是不重要的问题,怎样才能提出一个好问题。一般人没有这样的机遇能碰上那样好的老师,但通过读好书,跟着作者的思路思考,可以弥补这一点。另外,书中还有很多简明清晰的图解,能很好的帮助读者理解那些深奥的理论。
本书还介绍了如贝尔实验室、施乐实验室等鼎鼎有名的实验室,以及如IBM、Microsoft、Apple等公司的起源和发展。这些公司和实验室可不是计划或规划出来的,而是自发演化(这里非要借用一下哈耶克的理论不可)而来,正如书中所写的“幸运的是,它的要求非常含糊,可以包含所有的事,聪明的人可以在此做他感兴趣的任何事”。在如此宽松的环境下,几十个天才的头脑在碰撞,异想天开的思想在交流,终于产生如此多不可思议的发明。可想而知,如果这些天才需要用论文来评职称,那些创造和发明是否会产生。
作者Charles Petzold可是鼎鼎大名,从事计算机编程方面的写作长达15年之久,是Windows编程领域的圣经《Programming Windows》的作者,该书影响了一代编程人员,只要你在Windows平台上开发,该书都是必读之书。
读完本书,我觉得自己也可以给别人讲解计算机的原理和应用,以前自己一知半解,模摸糊糊,所以在给别人讲时总解释不清楚,现在就清晰多了。女友是文科出身,对计算机原理一窍不通,我试着给她解释,她很快就能理解那些简单的理论。
对于网上争论众多的如“语言之争”、“数学在编程中是否重要之争”、“通用CPU”、“自己的操作系统”、“软件产业的未来”等等,读完本书后,将会有自己的更好的理解和认识,而不致于迷失期间,我们从自己出发,努力提高自己,中国的信息产业自然会发展。
另外,本书的翻译非常通畅,我在阅读时完全没有感觉到硬译的痕迹。作者的书如同房龙的书一样,有着梦幻般的气质,干燥无味的科学常识和原理,经作者的描述,将文学家的手法,拿来用以讲述科学,使读他书的人,都觉得娓娓忘倦了。
向作者致敬,感谢译者辛勤的翻译,感谢出版社引进如此好的书籍。我希望成为本书的吹鼓手,向所有计算机从业者推荐此书,向所有的理科学生、所有对计算机感兴趣的人强烈推荐本书。将来我将向我的子女推荐本书,引导他们进入迷人的信息技术领域。
如果你是一个非计算机专业的IT人员,那么本书最最适合你。因为本书就是专为非计算机专业人员所写,里面有你梦寐以求的知识。如果你是一个计算机专业人员,那么本书将给你锦上添花,使你对计算机知识有通盘的理解。只要你想了解计算机的知识,本书将是你决不后悔的选择。
今天,我怀有一个梦想。我梦想有一天,大家能够根据本书的制造出自己的计算机;我梦想有一天,本书不仅成为计算机专业的教科书,也成为其他专业的参考书;我梦想有一天,根据本书能出版一套配套的实验书,指导读者实践,自己动手组装计算机;我梦想有一天,中学老师能够用本书给学生讲述计算机的奥秘;我梦想有一天,政府官员能够阅读本书,了解信息技术的常识和基本原理;我梦想有一天,记者能够阅读本书,写出更专业性的报道;我梦想有一天,中国的科技实力能够屹立于世界之林。
朝闻道,夕死无憾。我终于明白了。
请原谅我用了如此多带有强烈感情色彩的词语,那是因为我太喜欢这本书了。
后记:最近读了《深入理解计算机系统》,然后又重读了《编码的奥秘》一遍,感觉又有很大的收获。个人觉得,两书结合起来看,将更有裨益。
计算机组成(第 6 版)——结构化方法

目录
Structured Computer Organization, Sixth Edition
出版者的话
译者序
前言
第1章 概述 1
1.1 结构化计算机组成 1
1.1.1 语言、层次和虚拟机 1
1.1.2 现代多层次计算机 3
1.1.3 多层次计算机的演化 5
1.2 计算机体系结构的里程碑 8
1.2.1 第零代——机械计算机(1642—1945) 8
1.2.2 第一代——电子管计算机(1945—1955) 10
1.2.3 第二代——晶体管计算机(1955—1965) 12
1.2.4 第三代——集成电路计算机(1965—1980) 14
1.2.5 第四代——超大规模集成电路计算机(1980年至今) 15
1.2.6 第五代——低功耗和无所不在的计算机 17
1.3 计算机家族 18
1.3.1 技术和经济推动 18
1.3.2 计算机扫视 20
1.3.3 一次性计算机 21
1.3.4 微型控制器 22
1.3.5 移动计算机和游戏计算机 23
1.3.6 个人计算机 24
1.3.7 服务器 25
1.3.8 大型主机 26
1.4 系列计算机举例 26
1.4.1 x86体系结构简介 27
1.4.2 ARM体系结构简介 31
1.4.3 AVR体系结构简介 32
1.5 公制计量单位 33
1.6 本书概览 34
习题 35
第2章 计算机系统组成 38
2.1 处理器 38
2.1.1 CPU组成 39
2.1.2 指令执行 40
2.1.3 RISC和CISC 42
2.1.4 现代计算机设计原则 43
2.1.5 指令级并行 44
2.1.6 处理器级并行 47
2.2 主存储器 50
2.2.1 存储位 50
2.2.2 内存编址 51
2.2.3 字节顺序 52
2.2.4 纠错码 53
2.2.5 高速缓存 56
2.2.6 内存封装及其类型 58
2.3 辅助存储器 59
2.3.1 层次存储结构 59
2.3.2 磁盘 60
2.3.3 IDE盘 62
2.3.4 SCSI盘 63
2.3.5 RAID盘 64
2.3.6 固盘 67
2.3.7 只读光盘 68
2.3.8 可刻光盘 71
2.3.9 可擦写光盘 73
2.3.10 DVD 73
2.3.11 Blu-Ray 74
2.4 输入/输出设备 75
2.4.1 总线 75
2.4.2 终端 78
2.4.3 鼠标 81
2.4.4 游戏控制器 83
2.4.5 打印机 84
2.4.6 电信设备 88
2.4.7 数码相机 94
2.4.8 字符编码 95
2.5 小结 99
习题 99
第3章 数字逻辑层 103
3.1 门和布尔代数 103
3.1.1 门 103
3.1.2 布尔代数 105
3.1.3 布尔函数的实现 107
3.1.4 等价电路 108
3.2 基本数字逻辑电路 110
3.2.1 集成电路 111
3.2.2 组合逻辑电路 111
3.2.3 算术电路 114
3.2.4 时钟 118
3.3 内存 119
3.3.1 锁存器 119
3.3.2 触发器 121
3.3.3 寄存器 122
3.3.4 内存组成 123
3.3.5 内存芯片 125
3.3.6 RAM和ROM 128
3.4 CPU芯片和总线 130
3.4.1 CPU芯片 130
3.4.2 计算机总线 132
3.4.3 总线宽度 134
3.4.4 总线时钟 135
3.4.5 总线仲裁 138
3.4.6 总线操作 141
3.5 CPU芯片举例 143
3.5.1 Intel Core i7 143
3.5.2 德州仪器的OMAP4430片上系统 147
3.5.3 Atmel的ATmega168微控制器 150
3.6 总线举例 152
3.6.1 PCI总线 152
3.6.2 PCI Express 159
3.6.3 通用串行总线USB 162
3.7 接口电路 165
3.7.1 输入/输出接口 165
3.7.2 地址译码 166
3.8 小结 169
习题 169
第4章 微体系结构层 173
4.1 微体系结构举例 173
4.1.1 数据通路 174
4.1.2 微指令 178
4.1.3 微指令控制:Mic-1 180
4.2 指令系统举例:IJVM 183
4.2.1 栈 183
4.2.2 IJVM内存模型 185
4.2.3 IJVM指令集 186
4.2.4 将Java编译为IJVM 189
4.3 实现举例 190
4.3.1 微指令和符号 190
4.3.2 用Mic-1实现IJVM 193
4.4 微体系结构层设计 201
4.4.1 速度与价格 202
4.4.2 缩短指令执行路径长度 203
4.4.3 带预取的设计:Mic-2 208
4.4.4 流水线设计:Mic-3 211
4.4.5 七段流水线设计:Mic-4 215
4.5 提高性能 217
4.5.1 高速缓存 218
4.5.2 分支预测 222
4.5.3 乱序执行和寄存器重命名 226
4.5.4 推测执行 230
4.6 微体系结构层举例 232
4.6.1 Core i7 CPU的微体系结构 232
4.6.2 OMAP4430 CPU的微体系结构 236
4.6.3 ATmega168微控制器的微体系结构 240
4.7 Core i7、OMAP4430和ATmega168三种CPU的比较 241
4.8 小结 242
习题 243
第5章 指令系统层 246
5.1 指令系统层概述 247
5.1.1 指令系统层的性质 247
5.1.2 存储模式 249
5.1.3 寄存器 250
5.1.4 指令 251
5.1.5 Core i7指令系统层概述 251
5.1.6 OMAP4430 ARM指令系统层概述 253
5.1.7 ATmega168 AVR指令系统层概述 255
5.2 数据类型 256
5.2.1 数值数据类型 257
5.2.2 非数值数据类型 257
5.2.3 Core i7的数据类型 258
5.2.4 OMAP4430 ARM CPU的数据类型 258
5.2.5 ATmega168 AVR CPU的数据类型 259
5.3 指令格式 259
5.3.1 指令格式设计准则 260
5.3.2 扩展操作码 261
5.3.3 Core i7指令格式 263
5.3.4 OMAP4430 ARM CPU指令格式 264
5.3.5 ATmega168 AVR指令格式 266
5.4 寻址 267
5.4.1 寻址方式 267
5.4.2 立即寻址 267
5.4.3 直接寻址 267
5.4.4 寄存器寻址 267
5.4.5 寄存器间接寻址 267
5.4.6 变址寻址 269
5.4.7 基址变址寻址 270
5.4.8 栈寻址 270
5.4.9 转移指令的寻址方式 272
5.4.10 操作码和寻址方式的关系 273
5.4.11 Core i7的寻址方式 274
5.4.12 OMAP4430 ARM CPU的寻址方式 276
5.4.13 ATmega168 AVR的寻址方式 276
5.4.14 寻址方式讨论 276
5.5 指令类型 277
5.5.1 数据移动指令 277
5.5.2 双操作数指令 278
5.5.3 单操作数指令 279
5.5.4 比较和条件转移指令 280
5.5.5 过程调用指令 281
5.5.6 循环控制指令 282
5.5.7 输入/输出指令 283
5.5.8 Core i7指令系统 285
5.5.9 OMAP4430 ARM CPU指令系统 287
5.5.10 ATmega168 AVR指令系统 289
5.5.11 指令集比较 291
5.6 控制流 291
5.6.1 顺序控制流和转移 291
5.6.2 过程 292
5.6.3 协同过程 295
5.6.4 陷阱 297
5.6.5 中断 297
5.7 详细举例:汉诺塔 300
5.7.1 Core i7汇编语言实现的汉诺塔 300
5.7.2 OMAP4430 ARM汇编语言实现的汉诺塔 302
5.8 IA-64体系结构和Itanium 2 303
5.8.1 IA-32的问题 303
5.8.2 IA-64模型:显式并行指令计算 304
5.8.3 减少内存访问 305
5.8.4 指令调度 305
5.8.5 减少条件转移:判定 307
5.8.6 推测加载 308
5.9 小结 309
习题 310
第6章 操作系统层 314
6.1 虚拟内存 314
6.1.1 内存分页 315
6.1.2 内存分页的实现 316
6.1.3 请求调页和工作集模型 319
6.1.4 页置换策略 320
6.1.5 页大小和碎片 321
6.1.6 分段 322
6.1.7 分段的实现 324
6.1.8 Core i7的虚拟内存 326
6.1.9 OMAP4430 ARM CPU的虚拟内存 329
6.1.10 虚拟内存和高速缓存 331
6.2 硬件虚拟化 331
6.3 操作系统层I/O指令 333
6.3.1 文件 333
6.3.2 操作系统层I/O指令的实现 335
6.3.3 目录管理指令 337
6.4 用于并行处理的操作系统层指令 338
6.4.1 进程创建 339
6.4.2 竞争条件 339
6.4.3 使用信号量的进程同步 342
6.5 操作系统实例 345
6.5.1 简介 345
6.5.2 虚拟内存实例 350
6.5.3 操作系统层I/O举例 352
6.5.4 进程管理实例 361
6.6 小结 365
习题 366
第7章 汇编语言层 371
7.1 汇编语言简介 371
7.1.1 什么是汇编语言 372
7.1.2 为什么使用汇编语言 372
7.1.3 汇编语言语句的格式 373
7.1.4 伪指令 374
7.2 宏 376
7.2.1 宏定义、调用和扩展 376
7.2.2 带参数的宏 377
7.2.3 高级特性 378
7.2.4 汇编器中宏处理的实现 378
7.3 汇编过程 379
7.3.1 两趟汇编的汇编器 379
7.3.2 第一趟扫描 379
7.3.3 第二趟扫描 382
7.3.4 符号表 384
7.4 链接和加载 385
7.4.1 链接器的处理过程 386
7.4.2 目标模块的结构 388
7.4.3 绑定时间和动态重定位 389
7.4.4 动态链接 390
7.5 小结 393
习题 393
第8章 并行计算机体系结构 396
8.1 片内并行 397
8.1.1 指令级并行 397
8.1.2 片内多线程 402
8.1.3 单片多处理器 406
8.2 协处理器 410
8.2.1 网络处理器 411
8.2.2 图形处理器 416
8.2.3 加密处理器 418
8.3 共享内存的多处理器 418
8.3.1 多处理器与多计算机 418
8.3.2 内存语义 424
8.3.3 UMA对称多处理器体系结构 426
8.3.4 NUMA多处理器系统 432
8.3.5 COMA多处理器系统 439
8.4 消息传递的多计算机 440
8.4.1 互联网络 441
8.4.2 MPP——大规模并行处理器 443
8.4.3 集群计算 450
8.4.4 多计算机的通信软件 454
8.4.5 调度 456
8.4.6 应用层的共享内存 457
8.4.7 性能 461
8.5 网格计算 465
8.6 小结 467
习题 468
参考文献 471
附录A 二进制数 479
附录B 浮点数 487
附录C 汇编语言程序设计 493
索引 534
自我实践
- 联系人——微创新
- 软件代表——项目管理
- 最佳导师——应届生培养
- 优秀小组——目标/体系/沟通/激励
- 创新培训——三步六法
- UiLite——Anroid,Java
- 设计模式
- 用户体验——数码爱好者
基本概念
四位计算机的原理及其实现
作者: 阮一峰
日期: 2011年3月12日
你是否想过,计算机为什么会加减乘除?或者更直接一点,计算机的原理到底是什么?
Waitingforfriday有一篇详细的教程,讲解了如何自己动手,制作一台四位计算机。从中可以看到,二进制、数理逻辑、电子学怎样融合在一起,构成了现代计算机的基础。
一、什么是二进制?
首先,从最简单的讲起。
计算机内部采用二进制,每一个数位只有两种可能”0”和”1”,运算规则是”逢二进一”。举例来说,有两个位A和B,它们相加的结果只可能有四种。
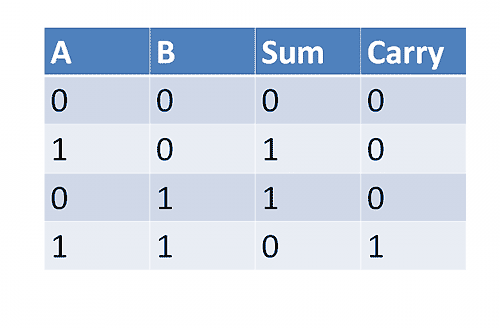
这张表就叫做”真值表”(truth table),其中的sum表示”和位”,carry表示”进位”。如果A和B都是0,和就是0,因此”和位”和”进位”都是0;如果A和B有一个为1,另一个为0,和就是1,不需要进位;如果A和B都是1,和就是10,因此”和位”为0,”进位”为1。
二、逻辑门(Logic Gate)
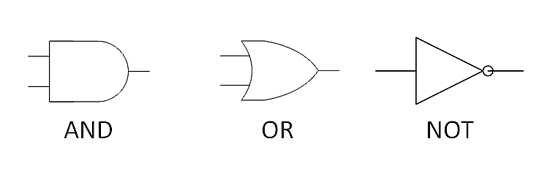
布尔运算(Boolean operation)的规则,可以套用在二进制加法上。布尔运算有三个基本运算符:AND,OR,NOT,又称”与门”、”或门”、”非门”,合称”逻辑门”。它们的运算规则是:
AND:如果( A=1 AND B=1 ),则输出结果为1。
OR:如果( A=1 OR B=1 ),则输出结果为1。
NOT:如果( A=1 ),则输出结果为0。
两个输入(A和B)都为1,AND(与门)就输出1;只要有任意一个输入(A或B)为1,OR(或门)就输出1;NOT(非门)的作用,则是输出一个输入值的相反值。它们的图形表示如下:
三、真值表的逻辑门表示
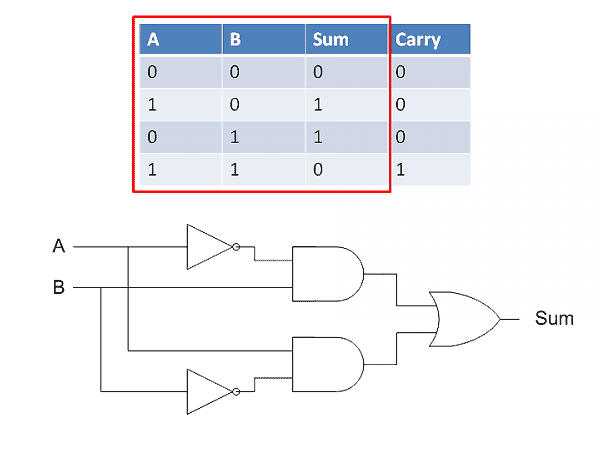
现在把”真值表”的运算规则,改写为逻辑门的形式。
先看sum(和位),我们需要的是这样一种逻辑:当两个输入不相同时,输出为1,因此运算符应该是OR;当两个输入相同时,输出为0,这可以用两组AND和NOT的组合实现。最后的逻辑组合图如下:
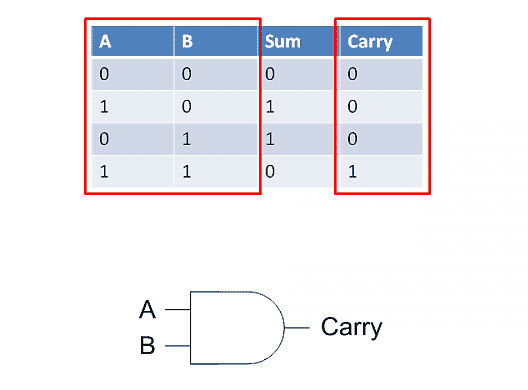
再看carry(进位)。它比较简单,两个输入A和B都为1就输出1,否则就输出0,因此用一个AND运算符就行了。
现在把sum和carry组合起来,就能得到整张真值表了。这被称为”半加器”(half-adder),因为它只考虑了单独两个位的相加,没有考虑可能还存在低位进上来的位。
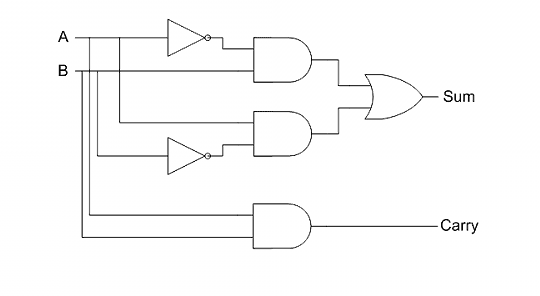
四、扩展的真值表和全加器
如果把低位进上来的位,当做第三个输入(input),也就是说,除了两个输入值A和B以外,还存在一个输入(input)的carry,那么问题就变成了如何在三个输入的情况下,得到输出(output)的sum(和位)和carry(进位)。
这时,真值表被扩展成下面的形式:
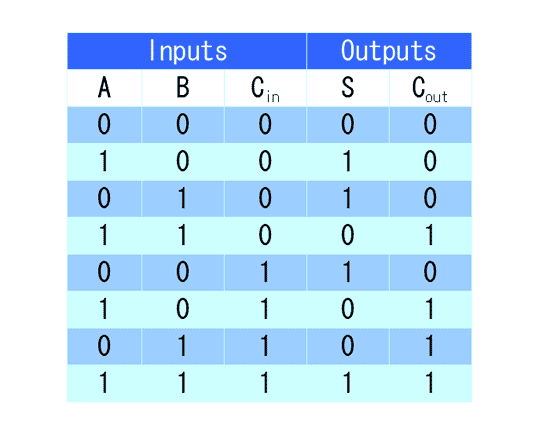
如果你理解了半加器的设计思路,就不难把它扩展到新的真值表,这就是”全加器”(full-adder)了。
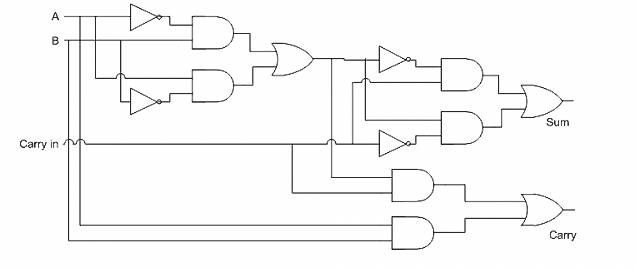
五、全加器的串联
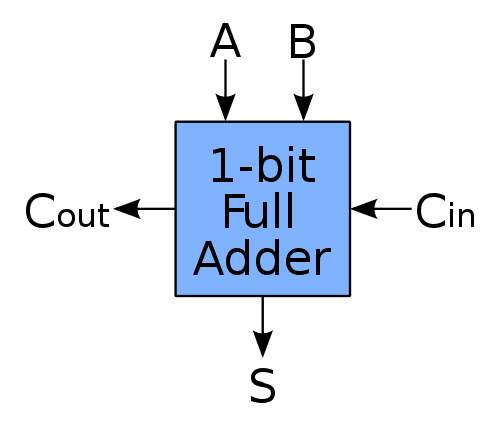
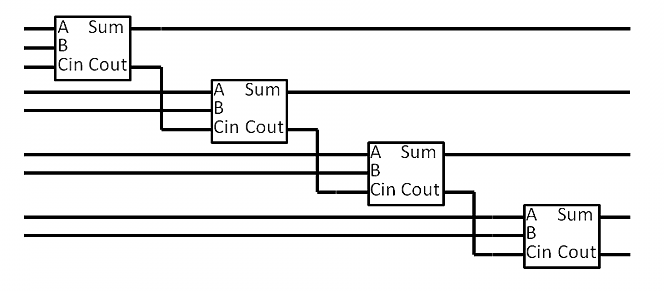
多个全加器串联起来,就能进行二进制的多位运算了。
先把全加器简写成方块形式,注明三个输入(A、B、Cin)和两个输出(S和Cout)。
然后,将四个全加器串联起来,就得到了四位加法器的逻辑图。
六、逻辑门的晶体管实现
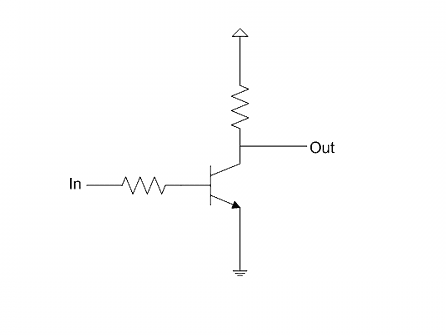
下一步,就是用晶体管做出逻辑门的电路。
先看NOT。晶体管的基极(Base)作为输入,集电极(collector)作为输出,发射极(emitter)接地。当输入为1(高电平),电流流向发射极,因此输出为0;当输入为0(低电平),电流从集电极流出,因此输出为1。
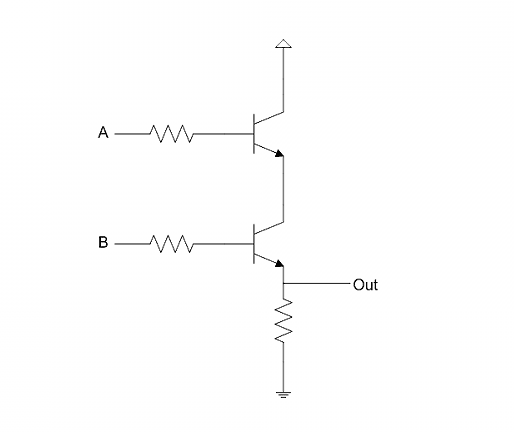
接着是AND。这需要两个晶体管,只有当两个基极的输入都为1(高电平),电流才会流向输出端,得到1。
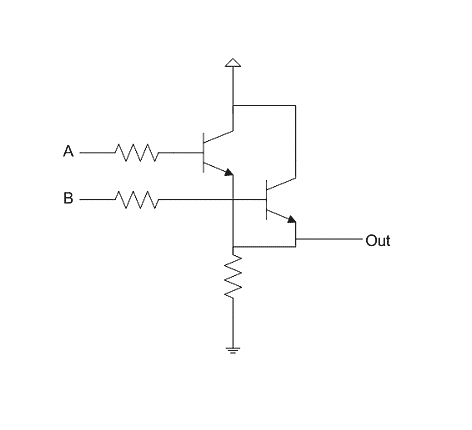
最后是OR。这也需要两个晶体管,只要两个基极中有一个为1(高电平),电流就会流向输出端,得到1。
七、全加器的电路
将三种逻辑门的晶体管实现,代入全加器的设计图,就可以画出电路图了。
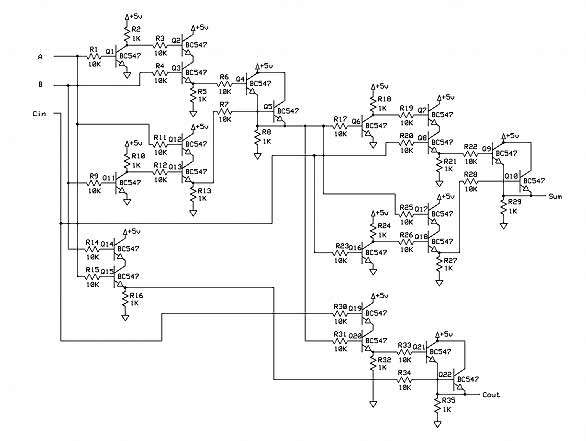
(点击看大图)
按照电路图,用晶体管和电路板组装出全加器的集成电路。

左边的三根黄线,分别代表三个输入A、B、Cin;右边的两根绿线,分别代表输出S和Cout。
八、制作计算机
将四块全加器的电路串联起来,就是一台货真价实的四位晶体管计算机了,可以计算0000~1111之间的加法。

电路板的下方有两组各四个开关,标注着”A”和”B”,代表两个输入数。从上图可以看到,A组开关是”上下上上”,代表1011(11);B组开关是”上下下下”,代表1000(8)。它们的相加结果用五个LED灯表示,上图中是”亮暗暗亮亮”,代表10011(19),正是1011与1000的和。
九、结论
虽然这个四位计算机非常简陋,但是从中不难体会到现代计算机的原理。
完成上面的四位加法,需要用到88个晶体管。虽然当代处理器包含的晶体管数以亿计,但是本质上都是上面这样简单电路的累加。
(完)
计算机是如何启动的?
作者: 阮一峰
日期: 2013年2月16日
从打开电源到开始操作,计算机的启动是一个非常复杂的过程。

我一直搞不清楚,这个过程到底是怎么回事,只看见屏幕快速滚动各种提示…… 这几天,我查了一些资料,试图搞懂它。下面就是我整理的笔记。
零、boot的含义
先问一个问题,”启动”用英语怎么说?
回答是boot。可是,boot原来的意思是靴子,”启动”与靴子有什么关系呢? 原来,这里的boot是bootstrap(鞋带)的缩写,它来自一句谚语:
“pull oneself up by one’s bootstraps”
字面意思是”拽着鞋带把自己拉起来”,这当然是不可能的事情。最早的时候,工程师们用它来比喻,计算机启动是一个很矛盾的过程:必须先运行程序,然后计算机才能启动,但是计算机不启动就无法运行程序!
早期真的是这样,必须想尽各种办法,把一小段程序装进内存,然后计算机才能正常运行。所以,工程师们把这个过程叫做”拉鞋带”,久而久之就简称为boot了。
计算机的整个启动过程分成四个阶段。
一、第一阶段:BIOS
上个世纪70年代初,”只读内存”(read-only memory,缩写为ROM)发明,开机程序被刷入ROM芯片,计算机通电后,第一件事就是读取它。

这块芯片里的程序叫做”基本輸出輸入系統”(Basic Input/Output System),简称为BIOS。
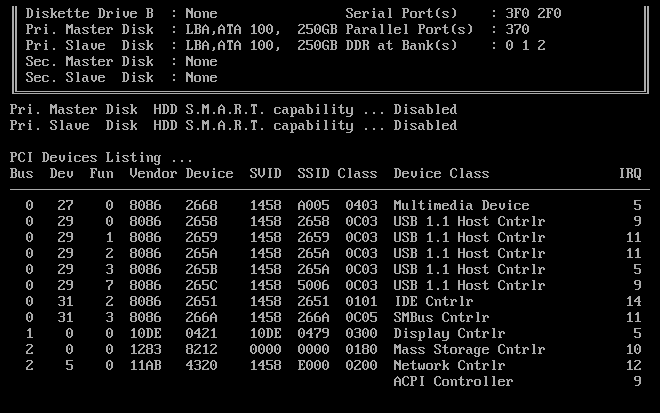
1.1 硬件自检
BIOS程序首先检查,计算机硬件能否满足运行的基本条件,这叫做”硬件自检”(Power-On Self-Test),缩写为POST。
如果硬件出现问题,主板会发出不同含义的蜂鸣,启动中止。如果没有问题,屏幕就会显示出CPU、内存、硬盘等信息。
1.2 启动顺序
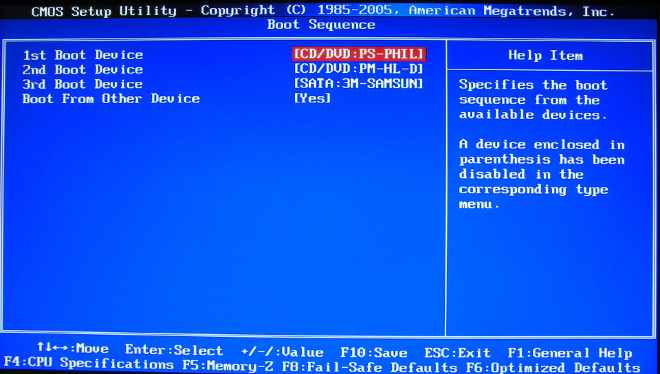
硬件自检完成后,BIOS把控制权转交给下一阶段的启动程序。
这时,BIOS需要知道,”下一阶段的启动程序”具体存放在哪一个设备。也就是说,BIOS需要有一个外部储存设备的排序,排在前面的设备就是优先转交控制权的设备。这种排序叫做”启动顺序”(Boot Sequence)。
打开BIOS的操作界面,里面有一项就是”设定启动顺序”。
二、第二阶段:主引导记录
BIOS按照”启动顺序”,把控制权转交给排在第一位的储存设备。
这时,计算机读取该设备的第一个扇区,也就是读取最前面的512个字节。如果这512个字节的最后两个字节是0x55和0xAA,表明这个设备可以用于启动;如果不是,表明设备不能用于启动,控制权于是被转交给”启动顺序”中的下一个设备。
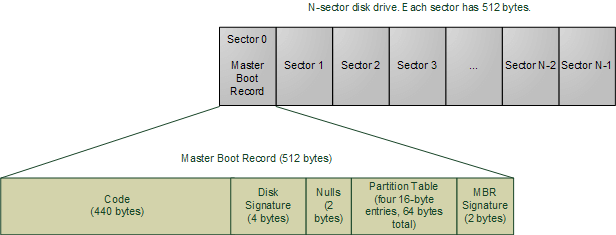
这最前面的512个字节,就叫做“主引导记录”(Master boot record,缩写为MBR)。
2.1 主引导记录的结构
“主引导记录”只有512个字节,放不了太多东西。它的主要作用是,告诉计算机到硬盘的哪一个位置去找操作系统。
主引导记录由三个部分组成:
(1) 第1-446字节:调用操作系统的机器码。
(2) 第447-510字节:分区表(Partition table)。
(3) 第511-512字节:主引导记录签名(0x55和0xAA)。
其中,第二部分”分区表”的作用,是将硬盘分成若干个区。
2.2 分区表
硬盘分区有很多好处。考虑到每个区可以安装不同的操作系统,”主引导记录”因此必须知道将控制权转交给哪个区。
分区表的长度只有64个字节,里面又分成四项,每项16个字节。所以,一个硬盘最多只能分四个一级分区,又叫做”主分区”。
每个主分区的16个字节,由6个部分组成:
(1) 第1个字节:如果为0x80,就表示该主分区是激活分区,控制权要转交给这个分区。四个主分区里面只能有一个是激活的。
(2) 第2-4个字节:主分区第一个扇区的物理位置(柱面、磁头、扇区号等等)。
(3) 第5个字节:主分区类型。
(4) 第6-8个字节:主分区最后一个扇区的物理位置。
(5) 第9-12字节:该主分区第一个扇区的逻辑地址。
(6) 第13-16字节:主分区的扇区总数。
最后的四个字节(”主分区的扇区总数”),决定了这个主分区的长度。也就是说,一个主分区的扇区总数最多不超过2的32次方。
如果每个扇区为512个字节,就意味着单个分区最大不超过2TB。再考虑到扇区的逻辑地址也是32位,所以单个硬盘可利用的空间最大也不超过2TB。如果想使用更大的硬盘,只有2个方法:一是提高每个扇区的字节数,二是增加扇区总数。
三、第三阶段:硬盘启动
这时,计算机的控制权就要转交给硬盘的某个分区了,这里又分成三种情况。
3.1 情况A:卷引导记录
上一节提到,四个主分区里面,只有一个是激活的。计算机会读取激活分区的第一个扇区,叫做”卷引导记录”(Volume boot record,缩写为VBR)。
“卷引导记录”的主要作用是,告诉计算机,操作系统在这个分区里的位置。然后,计算机就会加载操作系统了。
3.2 情况B:扩展分区和逻辑分区
随着硬盘越来越大,四个主分区已经不够了,需要更多的分区。但是,分区表只有四项,因此规定有且仅有一个区可以被定义成”扩展分区”(Extended partition)。
所谓”扩展分区”,就是指这个区里面又分成多个区。这种分区里面的分区,就叫做”逻辑分区”(logical partition)。
计算机先读取扩展分区的第一个扇区,叫做”扩展引导记录”(Extended boot record,缩写为EBR)。它里面也包含一张64字节的分区表,但是最多只有两项(也就是两个逻辑分区)。
计算机接着读取第二个逻辑分区的第一个扇区,再从里面的分区表中找到第三个逻辑分区的位置,以此类推,直到某个逻辑分区的分区表只包含它自身为止(即只有一个分区项)。因此,扩展分区可以包含无数个逻辑分区。
但是,似乎很少通过这种方式启动操作系统。如果操作系统确实安装在扩展分区,一般采用下一种方式启动。
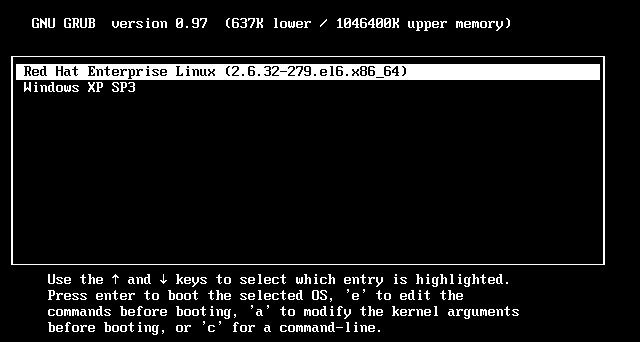
3.3 情况C:启动管理器
在这种情况下,计算机读取”主引导记录”前面446字节的机器码之后,不再把控制权转交给某一个分区,而是运行事先安装的”启动管理器”(boot loader),由用户选择启动哪一个操作系统。
Linux环境中,目前最流行的启动管理器是Grub。
四、第四阶段:操作系统
控制权转交给操作系统后,操作系统的内核首先被载入内存。
以Linux系统为例,先载入/boot目录下面的kernel。内核加载成功后,第一个运行的程序是/sbin/init。它根据配置文件(Debian系统是/etc/initab)产生init进程。这是Linux启动后的第一个进程,pid进程编号为1,其他进程都是它的后代。
然后,init线程加载系统的各个模块,比如窗口程序和网络程序,直至执行/bin/login程序,跳出登录界面,等待用户输入用户名和密码。
至此,全部启动过程完成。
(完)
为什么主引导记录的内存地址是0x7C00?
作者: 阮一峰
日期: 2015年9月28日
《计算机原理》课本说,启动时,主引导记录会存入内存地址0x7C00。
这个奇怪的地址,是怎么来的,课本就不解释了。我一直有疑问,为什么不存入内存的头部、尾部、或者其他位置,而偏偏存入这个比 32KB 小1024字节的地方?
昨天,我读到一篇文章,终于解开了这个谜。
首先,如果你不知道,主引导记录(Master boot record,缩写为MBR)是什么,可以先读《计算机是如何启动的?》。
简单说,计算机启动是这样一个过程。
通电
读取ROM里面的BIOS,用来检查硬件
硬件检查通过
BIOS根据指定的顺序,检查引导设备的第一个扇区(即主引导记录),加载在内存地址 0x7C00
主引导记录把操作权交给操作系统
所以,主引导记录就是引导”操作系统”进入内存的一段小程序,大小不超过1个扇区(512字节)。

0x7C00这个地址来自Intel的第一代个人电脑芯片8088,以后的CPU为了保持兼容,一直使用这个地址。

1981年8月,IBM公司最早的个人电脑IBM PC 5150上市,就用了这个芯片。
当时,搭配的操作系统是86-DOS。这个操作系统需要的内存最少是32KB。我们知道,内存地址从0x0000开始编号,32KB的内存就是0x0000~0x7FFF。
8088芯片本身需要占用0x0000~0x03FF,用来保存各种中断处理程序的储存位置。(主引导记录本身就是中断信号INT 19h的处理程序。)所以,内存只剩下0x0400~0x7FFF可以使用。
为了把尽量多的连续内存留给操作系统,主引导记录就被放到了内存地址的尾部。由于一个扇区是512字节,主引导记录本身也会产生数据,需要另外留出512字节保存。所以,它的预留位置就变成了:
0x7FFF - 512 - 512 + 1 = 0x7C00
0x7C00就是这样来的。
计算机启动后,32KB内存的使用情况如下。
+——————— 0x0
| Interrupts vectors
+——————— 0x400
| BIOS data area
+——————— 0x5??
| OS load area
+——————— 0x7C00
| Boot sector
+——————— 0x7E00
| Boot data/stack
+——————— 0x7FFF
| (not used)
+——————— (…)
(完)