2012年11月13日,83岁的柯达公司退休工程师布赖斯·拜尔(Bryce Bayer)离开了这个世界,永远离开了我们,离开了爱戴他的人们,而他在数字图像领域的杰出成就不应该就这样被淹没在历史的洪流里,所以,谨以2014年第一篇博文献给伟大的布赖斯·拜尔先生。
图像的历史
根据维基百科的记载,世界上的第一张照片是法国人约瑟夫·尼塞福尔·涅普斯于1826年拍摄完成。1825年时,涅普斯委托法国光学仪器商人夏尔·雪弗莱(Charles Chevalier)为他的暗箱(camera obscura)制作光学镜片,并于1826年(有说1827年)将其发明的感光材料放进暗箱,拍摄现存最早的照片。作品在其法国勃艮第的家里拍摄完成,通过其阁楼上的窗户拍摄,曝光时间超过8小时。
当年,他拍照时采用的感光剂是氯化银(silver chloride)。氯化银的一个非常重要的特性是当光线照射氯化银时,氯化银会分解成纯银和氯气,纯银在空气中很快氧化变成黑色。因此,底片颜色越深代表光线越强,颜色越浅代表光线越弱。黑白照片就是这样拍出来的。为了避免冲淡主题,如果想了解照片又是如何洗出来的盆友们,请点击[这里](http://zhishi.maigoo.com/7845.html)。
为了了解图像基础,我们首先需要一些额外知识来做铺垫和填充:图像的本质。不像声音,图像其实是我们人的视觉系统对外界的一种感受。 听着有点玄乎,还是让我们先从彩色图像说起吧!(因为黑白图像实在太简单了)
图像的本质
人类的视觉系统为什么能感知各种各样的颜色呢?这个问题最早可以追溯到18世纪,当时的Young(1809)和Helmholtz(1824)共同提出了人类视觉的三原色学说(也就是我们现在经常说提到的RGB色彩空间的鼻祖),他们认为即:人类的视网膜存在三种视锥细胞,分别含有对红、绿、蓝三种光线敏感的视色素,当一定波长的光线作用于视网膜时,以一定的比例使三种视锥细胞分别产生不同程度的兴奋,这样的信息传至中枢,就产生某一种颜色的感觉。
到了70年代,由于实验技术的进步,关于视网膜中有三种对不同波长光线特别敏感的视锥细胞的假说,已经被许多出色的实验所证实。例如:
①有人用不超过单个视锥直径的细小单色光束,逐个检查并绘制在体(最初实验是在金鱼和蝾螈等动物进行,以后是人)视锥细胞的光谱吸收曲线,发现所有绘制出来的曲线不外三种类型,分别代表了三类光谱吸收特性不同的视锥细胞,一类的吸收峰值在420nm处,一类在534nm处,一类在564nm处,差不多正好相当于蓝、绿、红三色光的波长。与上述视觉三原色学说的假设相符。
②用微电极记录单个视锥细胞感受器电位的方法,也得到了类似的结果,即不同单色光所引起的不同视锥细胞的超极化型感受器电位的大小也不同,峰值出现的情况也符合于三原色学说。
19世纪中期,英国物理学家麦克斯韦以视觉三原色作为前提和假设,提出红绿蓝作为基色,可以拍出彩色图片的论断。1861年,在麦克斯韦的指导下,人类的第一张彩色照片诞生了。拍摄采用的方法也非常简单,就是在镜头前分别用红丝带、绿丝带、蓝丝带过滤光线,曝光形成三张底片,然后用三部放映机向同一处投影这三张底片,每部放映机的镜头前都拧上对应颜色的镜头,它们的合成效果就是一张彩色照片。
然而,真正意义上的彩色胶卷其实是柯达公司1933年生产。虽然2013年柯达刚刚宣布破产,但也无法否认他曾在影像界的王者地位。
图像数字化的原理
第二次世界大战结束后,随着原子能技术、微电子、计算机、分子生物和遗传工程等领域的重大突破,标志着人类第三次科技革命的开始。随后的年代里,听到的最多的一个词就是“数字化”,到处都在谈数字化,就像当我们时下都说的“土豪”这个词。那时,如果你和人见面不聊点“e时代”的东西,还真不好意思。
很多人都可能不知道,图像领域数字化的理论基础是爱因斯坦的光电理论,通过图像传感器(image sensor)将光信号转换成电信号,然后再将模拟的电信号转换成数字信号来完成。**图像传感器本质上就是一个感光元件**,它与我们常见的太阳能电池有一些类似之处,**整块感光元件就是一个太阳能电池矩阵,每个像素点对应一个感光单位。** 当光照射到感光单元后,它会测量出光的强度然后产生一个相应的电信号,在经过模数转换电路A/D对电信号进行采样,紧接着是量化和编码并存储。这就是完成了图像的数字化。
然而,图像传感器有个非常大的缺陷:它只能感受光的强弱,无法感受光的波长。由于光的颜色是由波长决定的,所以图像传播器无法记录光的颜色值,也就是说,它只能拍黑白照片,这当然是无法容忍的。在前面麦克斯韦等人的影响下,人们开始尝试如何将彩色图片进行数字化。根据RGB三原色理论,一种解决办法就是照相机内置三个图像传感器,分别记录红、绿、蓝三种颜色,然后再将这三个值合并。这种方法能产生最准确的颜色信息,但是成本太高(现在很多高端大气上档次的人在追求这种模式,也已经有厂家推出了相应的设备,但价格非一般人能负担得起)。 1974年,柯达公司的工程师布赖斯·拜尔提出了一个全新方案,只用一块图像传感器,就解决了颜色的识别。他的做法是在图像传感器前面,设置一个滤光层(Color filter array),上面布满了滤光点,与下层的像素点逐一对应。也就是说,如果传感器是1600×1200个像素,那么它的上层就有1600×1200个滤光点。
每个感光单元就是一个像素,它前面的遮光片点只能允许通过红、绿、蓝之中的一种颜色,这意味着在它下层的像素点只可能有四种颜色:红、绿、蓝、黑(表示没有任何光通过),就像给每个像素点都“戴”了一个单色光的过滤眼镜一样。它的工作原理如下:
每个感光单元就像有刻度的小桶,光线就像雨一样洒在小桶里,小桶的容量越大,所能度量的雨的大小范围(图像的动态范围)就越大,桶的刻度越多(色彩位数越高)度量的精度就越高。
有些童鞋可能就纳闷了,既然每个像素点只能记录一种颜色,到底是如何拍出彩色图像的呢?所以说,感光元件上的滤光点的排列是有讲究的,这也是布赖斯·拜尔的智慧:每个绿点的四周,分布着2个红点、2个蓝点、4个绿点。这意味着,整体上,绿点的数量是其他两种颜色点的两倍。这是因为研究显示人眼对绿色最敏感,所以滤光层的绿点最多。

我们可以看到,每个滤光点周围有规律地分布其他颜色的滤光点,那么就有可能结合它们的值,判断出光线本来的颜色。以黄光为例,它由红光和绿光混合而成,那么通过滤光层以后,红点和绿点下面的像素都会有值,但是蓝点下面的像素没有值,因此看一个像素周围的颜色分布有红色和绿色,但是没有蓝色-就可以推测出来这个像素点的本来颜色应该是黄色。这个过程可以表示如下,而这种计算颜色的方法,就叫做”去马赛克”(demosaicing)法:
虽然,每个像素的颜色都是算出来的,并不是真正的值,但是由于计算的结果相当准确,因此这种做法得到广泛应用。目前,绝大部分的数码相机都采用它,来生成彩色数码照片。高级的数码相机,还提供未经算法处理的原始马赛克图像,这就是raw格式(raw image format)。为了纪念发明者布赖斯·拜尔,它被称作”拜尔模式”或”拜尔滤光法” (Bayer filter)。
数码相机成像原理
OK,有了以上知识的普及和扫盲,下面让我们看一下数码相机的成像过程和原理,其实前面已经提到一点。
前面我们提到的那个感光元件,是数码相机或数码录像机的核心部件,目前业界有两种感光介质:
一种是CCD,是英文 Charge Coupled Device (即电荷耦合器件)的缩写,是一种特殊的半导体器件,也是用来采集信号的一种感应元件,技术要求很高,全世界只有 6 家公司掌握了 CCD研制的核心技术,成品率较低,成本较高。
另一种是CMOS,全称是Complementary Metal-Oxide-Semiconductor(即互补金属氧化物半导体),它在微处理器和闪存等半导体技术上占有重要的地位,也是一种可用来感受光线变化的半导体,其组成元素主要是硅和锗,通过CMOS上带负电和带正电的晶体管来实现基本功能。这两个互补效应所产生的电流即可被处理芯片记录和解读成影像。
无论是CCD还是CMOS,其作用和地位都是完成光信号到电信号的转换。两者之争也是数码界一个亘古以来就很久远的话题,2009以前还是CCD的天下,2009年之后(标志性事件就是2008年索尼发布了背照式CMOS,代号Exmor R),CMOS一下子又火了,CCD逐渐沦落。随着技术、生产工艺、科技的进步,说不定哪天CCD又把CMOS甩开八百里开外,这个谁也说不准,我们就不搅和到这场口水战里了。这里大家只要知道在数码录制设备里,CCD和CMOS都是感光元器件,完成光电信号的转换对我们来说就OK了。
以前传统相机拍照时,光线通过镜头汇聚,再通过按动快门打开快门门帘让汇聚光投射到胶片上来成像,相机机身只充当了一个暗箱的作用。数码相机的原理和其类似,数码相机肯定也有镜头,通过镜头的光线不像传统相机那样直接投射到胶片,而是直接投射到上面我们提到的感光元件的光敏单元上,这些感光器由半导体元件构成,由数字相机的内置智能控制装置对入射光线进行分析处理,并自动调整合适的焦距、暴光时间、色度、白平衡等参数,然后将这些数据传送给模/数转换器ADC(Analog Digital Converter),ADC最后把这些电子模拟信号转换成数字信号。如果这个时候直接对数字信号进行存储,就是所谓的图像的Raw格式,照片的质量比普通的高,而且能在后期电脑上进行几乎无损的一些参数调整。严格意义上来说,Raw不应该算是一种图像格式,它仅仅是一个数据包而已。Raw仅仅是将数码相机图像传感器(CCD)感光产生的电信号数字化之后的采样值忠实地记录下来打包直接保存,并未进行任何计算和压缩,具有独特的设备相关性。它所记录的不是图像点的色彩、亮度信息,而是感光芯片的感光记录,是落在每个感光单元上的光线的多少,至于这个点处于什么位置,这个位置上是什么颜色的滤色片,需要根据芯片的型号来定义。
目前,大多数数码相机的图像感光器的量化位一般都是12bit或14bit,就是说每个感光单元的感光信息用 12 或 14 位的二进制数字记录下来,对于 12 位的器件,每个点的亮度可以有2^12=4096 级的梯度区别,14 位的器件每个点的亮度可以有 2^14=16384 级的梯度区别,而一般JPEG 格式只能记录 24 位的 RGB 位图(尽管实际是以 YCbCr 色彩空间模型来记录,但图像处理、显示软件打开这些图像时,以及屏幕显示这些图片时,仍然要转换为 RGB分量),但每个点 24位的数据要记录 R、G、B 三种颜色,分解到一种颜色就只能有 8 位了,最终能记录的亮度梯度就只有256 级了。数码相机早期还有一种格式,现在用的比较少,那就是TIFF 格式。虽然TIFF可记录 48 位(每个色彩 16 位)的图像信息,可以不丢失色彩位,但那样文件体积将变得十分庞大,而且多出的数据位只能用空白数据来填补,浪费存储资源。色彩位的差别直接关系到图像的动态范围和色彩饱和度,一旦保存为低色彩位的图像文件,将有相当量的感光信息被舍弃,这些舍弃的信息将无法找回。 另外,无论拍摄时采用 TIFF还是 JPEG,都是相机利用内部的图像处理芯片预先将数据计算过的,这个计算过程中就要用到相机的白平衡设置、色彩空间设置、曝光补偿设置等等,万一这些设置不准确,计算所产生的图像就会偏色或者曝光不准,一旦这种错误比较严重,信息损失过多,会导致照片报废。然而,JPEG图像格式是目前大众化数码相机缺省的图像保存格式。
总结
好了,本文如果还有人没看明白,我只能很遗憾的说我已经尽了自己最大的努力,力争用最简单的文字来表述复杂的概念和理论,剩下的就只能靠每个人的修为了。最后,我再将数码相机成像的整个过程总结一下:
从镜头进来的光线,投射到数码相机感光元件的很多个微小光敏感光单元上,每个感光单元以电信号的形式记录下照射到它上面的光的强度,然后通过DSP芯片的运算,将电信号通过预先内置在芯片里设定好的算法计算成符合现实标准的数码图像文件并加以存储,最后我们后期就可以编辑、修改、或者通过网络来传输图像了。
后记
最后,如果有朋友选购数码相机时,看到一个数码相机声称其最高像素是2040万,但它标注的分辨率却为5184×3888=2015万像素,你也不能说人家在忽悠咱们。因为人家也没说2040万像素都拿来成像,这也符合相关标准。在你选择不同的拍照质量时,分辨率当然会降下来,用高分辨率的镜头拍出低分辨率的数字图像?你认为是怎么实现的呢?其似乎也不难,对于这种需求当今大多数相机都是通过主控芯片让感光器件“遮挡”部分感光单元,只让另一部分感光单元接受光照即可实现。关于图像质量的问题,每个感光单元的比特位直接决定了图像最终的表现亮度和色彩的性能,反映到图像上就是每个像素点所占的bit数,或者说字节数。
以上便是我对数字图像入门知识的一点简单的记录和分享,毕竟不是专业搞图像的,欢迎各位路过的专业达人、高人、达人、大虾们指点拍砖。
相似图片搜索的原理
作者: 阮一峰
日期: 2011年7月21日
上个月,Google把”相似图片搜索”正式放上了首页。
你可以用一张图片,搜索互联网上所有与它相似的图片。点击搜索框中照相机的图标。

一个对话框会出现。
你输入网片的网址,或者直接上传图片,Google就会找出与其相似的图片。下面这张图片是美国女演员Alyson Hannigan。

上传后,Google返回如下结果:

类似的”相似图片搜索引擎”还有不少,TinEye甚至可以找出照片的拍摄背景。
==========================================================
这种技术的原理是什么?计算机怎么知道两张图片相似呢?
根据Neal Krawetz博士的解释,原理非常简单易懂。我们可以用一个快速算法,就达到基本的效果。
这里的关键技术叫做”感知哈希算法”(Perceptual hash algorithm),它的作用是对每张图片生成一个”指纹”(fingerprint)字符串,然后比较不同图片的指纹。结果越接近,就说明图片越相似。
下面是一个最简单的实现:
第一步,缩小尺寸。
将图片缩小到8x8的尺寸,总共64个像素。这一步的作用是去除图片的细节,只保留结构、明暗等基本信息,摒弃不同尺寸、比例带来的图片差异。

第二步,简化色彩。
将缩小后的图片,转为64级灰度。也就是说,所有像素点总共只有64种颜色。
第三步,计算平均值。
计算所有64个像素的灰度平均值。
第四步,比较像素的灰度。
将每个像素的灰度,与平均值进行比较。大于或等于平均值,记为1;小于平均值,记为0。
第五步,计算哈希值。
将上一步的比较结果,组合在一起,就构成了一个64位的整数,这就是这张图片的指纹。组合的次序并不重要,只要保证所有图片都采用同样次序就行了。
 = = 8f373714acfcf4d0
= = 8f373714acfcf4d0
得到指纹以后,就可以对比不同的图片,看看64位中有多少位是不一样的。在理论上,这等同于计算”汉明距离”(Hamming distance)。如果不相同的数据位不超过5,就说明两张图片很相似;如果大于10,就说明这是两张不同的图片。
具体的代码实现,可以参见Wote用python语言写的imgHash.py。代码很短,只有53行。使用的时候,第一个参数是基准图片,第二个参数是用来比较的其他图片所在的目录,返回结果是两张图片之间不相同的数据位数量(汉明距离)。
这种算法的优点是简单快速,不受图片大小缩放的影响,缺点是图片的内容不能变更。如果在图片上加几个文字,它就认不出来了。所以,
它的最佳用途是根据缩略图,找出原图。
实际应用中,往往采用更强大的pHash算法和SIFT算法,它们能够识别图片的变形。只要变形程度不超过25%,它们就能匹配原图。这些算法虽然更复杂,但是原理与上面的简便算法是一样的,就是先将图片转化成Hash字符串,然后再进行比较。
相似图片搜索的原理(二)
昨天,我在isnowfy的网站看到,还有其他两种方法也很简单,这里做一些笔记。
一、颜色分布法
每张图片都可以生成颜色分布的直方图(color histogram)。如果两张图片的直方图很接近,就可以认为它们很相似。
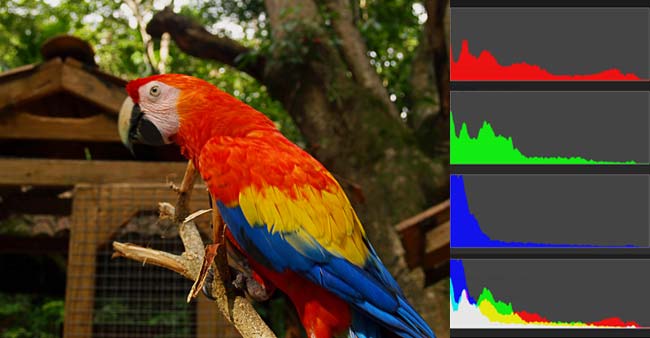
任何一种颜色都是由红绿蓝三原色(RGB)构成的,所以上图共有4张直方图(三原色直方图 + 最后合成的直方图)。
如果每种原色都可以取256个值,那么整个颜色空间共有1600万种颜色(256的三次方)。针对这1600万种颜色比较直方图,计算量实在太大了,因此需要采用简化方法。可以将0~255分成四个区:0~63为第0区,64~127为第1区,128~191为第2区,192~255为第3区。这意味着红绿蓝分别有4个区,总共可以构成64种组合(4的3次方)。
任何一种颜色必然属于这64种组合中的一种,这样就可以统计每一种组合包含的像素数量。
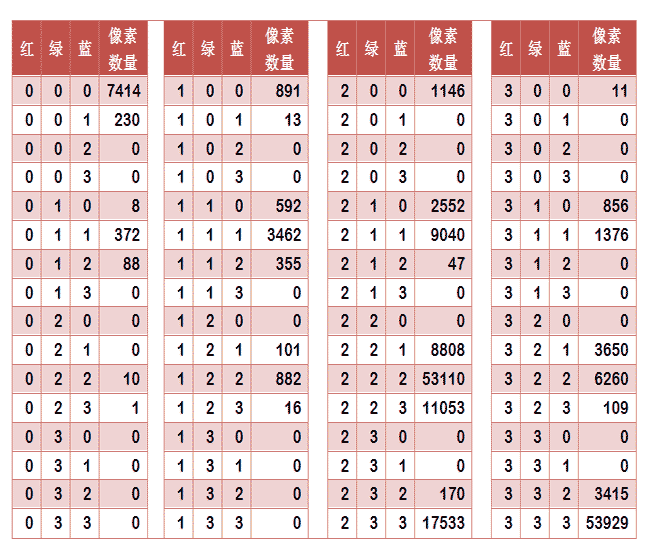
上图是某张图片的颜色分布表,将表中最后一栏提取出来,组成一个64维向量(7414, 230, 0, 0, 8, …, 109, 0, 0, 3415, 53929)。这个向量就是这张图片的特征值或者叫”指纹”。
于是,寻找相似图片就变成了找出与其最相似的向量。这可以用皮尔逊相关系数或者余弦相似度算出。
二、内容特征法
除了颜色构成,还可以从比较图片内容的相似性入手。
首先,将原图转成一张较小的灰度图片,假定为50x50像素。然后,确定一个阈值,将灰度图片转成黑白图片。

如果两张图片很相似,它们的黑白轮廓应该是相近的。于是,问题就变成了,第一步如何确定一个合理的阈值,正确呈现照片中的轮廓?
显然,前景色与背景色反差越大,轮廓就越明显。这意味着,如果我们找到一个值,可以使得前景色和背景色各自的”类内差异最小”(minimizing the intra-class variance),或者”类间差异最大”(maximizing the inter-class variance),那么这个值就是理想的阈值。
1979年,日本学者大津展之证明了,”类内差异最小”与”类间差异最大”是同一件事,即对应同一个阈值。他提出一种简单的算法,可以求出这个阈值,这被称为”大津法“(Otsu’s method)。下面就是他的计算方法。
假定一张图片共有n个像素,其中灰度值小于阈值的像素为 n1 个,大于等于阈值的像素为 n2 个( n1 + n2 = n )。w1 和 w2 表示这两种像素各自的比重。
w1 = n1 / n
w2 = n2 / n
再假定,所有灰度值小于阈值的像素的平均值和方差分别为 μ1 和 σ1,所有灰度值大于等于阈值的像素的平均值和方差分别为 μ2 和 σ2。于是,可以得到
类内差异 = w1(σ1的平方) + w2(σ2的平方)
类间差异 = w1w2(μ1-μ2)^2
可以证明,这两个式子是等价的:得到”类内差异”的最小值,等同于得到”类间差异”的最大值。不过,从计算难度看,后者的计算要容易一些。
下一步用”穷举法”,将阈值从灰度的最低值到最高值,依次取一遍,分别代入上面的算式。使得”类内差异最小”或”类间差异最大”的那个值,就是最终的阈值。具体的实例和Java算法,请看这里。

有了50x50像素的黑白缩略图,就等于有了一个50x50的0-1矩阵。矩阵的每个值对应原图的一个像素,0表示黑色,1表示白色。这个矩阵就是一张图片的特征矩阵。
两个特征矩阵的不同之处越少,就代表两张图片越相似。这可以用”异或运算”实现(即两个值之中只有一个为1,则运算结果为1,否则运算结果为0)。对不同图片的特征矩阵进行”异或运算”,结果中的1越少,就是越相似的图片。
如何识别图像边缘?
作者: 阮一峰
日期: 2016年7月22日
图像识别(image recognition)是现在的热门技术。
文字识别、车牌识别、人脸识别都是它的应用。但是,这些都算初级应用,现在的技术已经发展到了这样一种地步:计算机可以识别出,这是一张狗的照片,那是一张猫的照片。

这是怎么做到的?
让我们从人眼说起,学者发现,人的视觉细胞对物体的边缘特别敏感。也就是说,我们先看到物体的轮廓,然后才判断这到底是什么东西。
计算机科学家受到启发,第一步也是先识别图像的边缘。
加州大学的学生 Adit Deshpande 写了一篇文章《A Beginner’s Guide To Understanding Convolutional Neural Networks》,介绍了一种最简单的算法,非常具有启发性,体现了图像识别的基本思路。

首先,我们要明白,人看到的是图像,计算机看到的是一个数字矩阵。所谓”图像识别”,就是从一大堆数字中找出规律。
怎样将图像转为数字呢?一般来说,为了过滤掉干扰信息,可以把图像缩小(比如缩小到 49 x 49 像素),并且把每个像素点的色彩信息转为灰度值,这样就得到了一个 49 x 49 的矩阵。
然后,从左上角开始,依次取出一个小区块,进行计算。
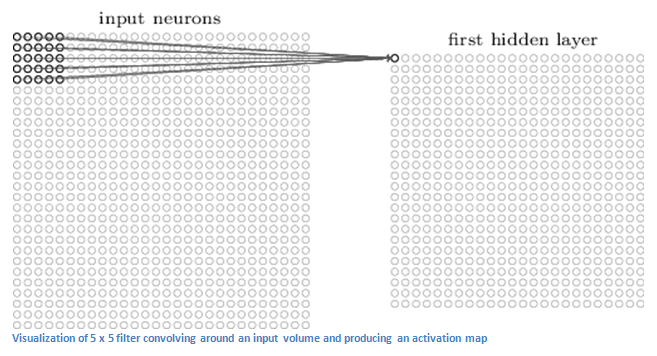
上图是取出一个 5 x 5 的区块。下面的计算以 7 x 7 的区块为例。
接着,需要有一些现成的边缘模式,比如垂直、直角、圆、锐角等等。
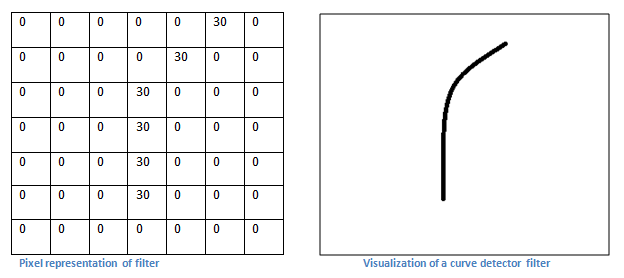
上图右边是一个圆角模式,左边是它对应的 7 x 7 灰度矩阵。可以看到,圆角所在的边缘灰度值比较高,其他地方都是0。
现在,就可以进行边缘识别了。下面是一张卡通老鼠的图片。
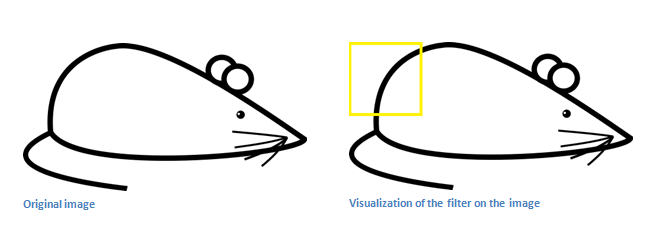
取出左上角的区块。
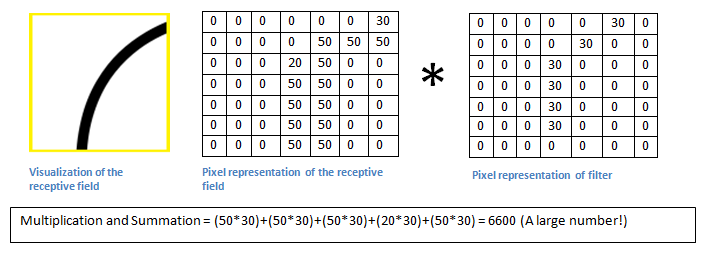
取样矩阵与模式矩阵对应位置的值相乘,进行累加,得到6600。这个值相当大,它说明什么呢?

取样矩阵移到老鼠头部,与模式矩阵相乘,得到的值是0。
乘积越大就说明越匹配,可以断定区块里的图像形状是圆角。通常会预置几十种模式,每个区块计算出最匹配的模式,然后再对整张图进行判断。
高斯模糊的算法
作者: 阮一峰
日期: 2012年11月14日
通常,图像处理软件会提供”模糊”(blur)滤镜,使图片产生模糊的效果。

“模糊”的算法有很多种,其中有一种叫做”高斯模糊”(Gaussian Blur)。它将正态分布(又名”高斯分布”)用于图像处理。
本文介绍”高斯模糊”的算法,你会看到这是一个非常简单易懂的算法。本质上,它是一种数据平滑技术(data smoothing),适用于多个场合,图像处理恰好提供了一个直观的应用实例。
一、高斯模糊的原理
所谓”模糊”,可以理解成每一个像素都取周边像素的平均值。
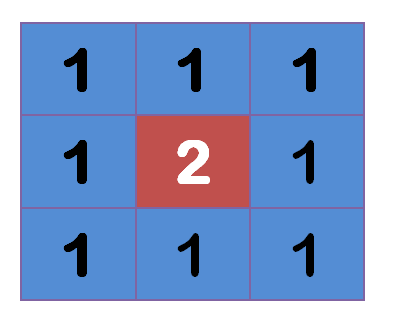
上图中,2是中间点,周边点都是1。
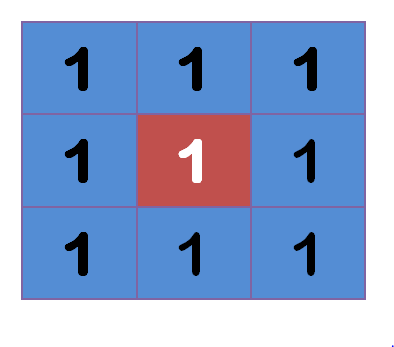
“中间点”取”周围点”的平均值,就会变成1。在数值上,这是一种”平滑化”。在图形上,就相当于产生”模糊”效果,”中间点”失去细节。

显然,计算平均值时,取值范围越大,”模糊效果”越强烈。

上面分别是原图、模糊半径3像素、模糊半径10像素的效果。模糊半径越大,图像就越模糊。从数值角度看,就是数值越平滑。
接下来的问题就是,既然每个点都要取周边像素的平均值,那么应该如何分配权重呢?
如果使用简单平均,显然不是很合理,因为图像都是连续的,越靠近的点关系越密切,越远离的点关系越疏远。因此,加权平均更合理,距离越近的点权重越大,距离越远的点权重越小。
二、正态分布的权重
正态分布显然是一种可取的权重分配模式。
在图形上,正态分布是一种钟形曲线,越接近中心,取值越大,越远离中心,取值越小。
计算平均值的时候,我们只需要将”中心点”作为原点,其他点按照其在正态曲线上的位置,分配权重,就可以得到一个加权平均值。
三、高斯函数
上面的正态分布是一维的,图像都是二维的,所以我们需要二维的正态分布。
正态分布的密度函数叫做”高斯函数”(Gaussian function)。它的一维形式是:
%3D%5Cfrac%7B1%7D%7B%5Csigma%5Csqrt%7B2%5Cpi%20%7D%20%7D%7De%5E%7B-(x-%5Cmu%20)%5E%7B2%7D%2F2%5Csigma%5E%7B2%7D%7D&chs=120)
其中,μ是x的均值,σ是x的方差。因为计算平均值的时候,中心点就是原点,所以μ等于0。
%3D%5Cfrac%7B1%7D%7B%5Csigma%5Csqrt%7B2%5Cpi%20%7D%20%7D%7De%5E%7B-x%5E%7B2%7D%2F2%5Csigma%5E%7B2%7D%7D&chs=120)
根据一维高斯函数,可以推导得到二维高斯函数:
%3D%5Cfrac%7B1%7D%7B2%5Cpi%20%5Csigma%20%5E%7B2%7D%7De%5E%7B-(x%5E2%2By%5E2)%2F2%5Csigma%5E2%7D&chs=80)
有了这个函数 ,就可以计算每个点的权重了。
四、权重矩阵
假定中心点的坐标是(0,0),那么距离它最近的8个点的坐标如下:
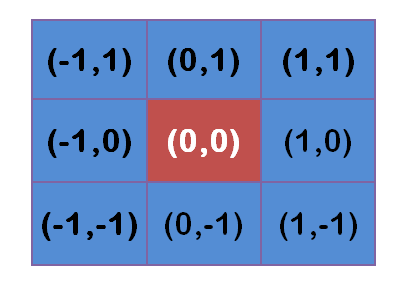
更远的点以此类推。
为了计算权重矩阵,需要设定σ的值。假定σ=1.5,则模糊半径为1的权重矩阵如下:
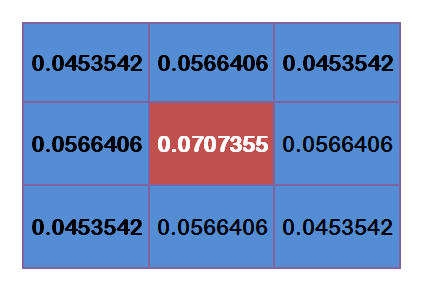
这9个点的权重总和等于0.4787147,如果只计算这9个点的加权平均,还必须让它们的权重之和等于1,因此上面9个值还要分别除以0.4787147,得到最终的权重矩阵。
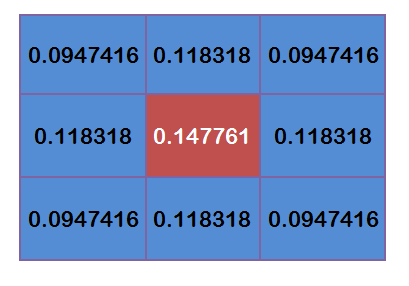
五、计算高斯模糊
有了权重矩阵,就可以计算高斯模糊的值了。
假设现有9个像素点,灰度值(0-255)如下:
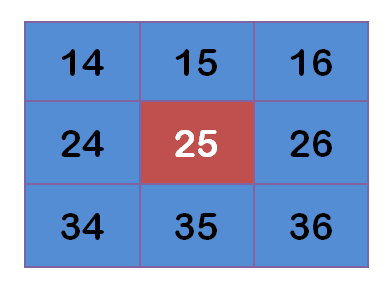
每个点乘以自己的权重值:
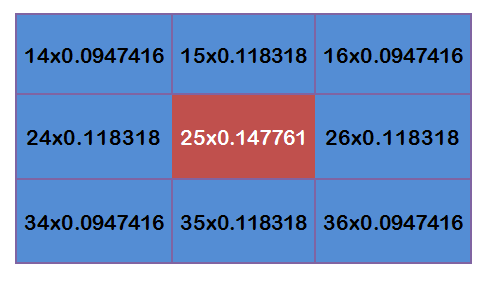
得到
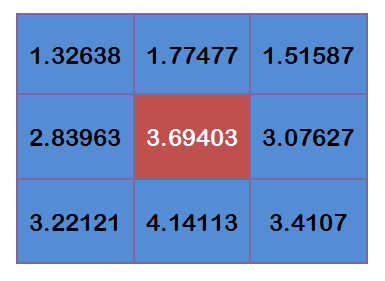
将这9个值加起来,就是中心点的高斯模糊的值。
对所有点重复这个过程,就得到了高斯模糊后的图像。如果原图是彩色图片,可以对RGB三个通道分别做高斯模糊。
六、边界点的处理
如果一个点处于边界,周边没有足够的点,怎么办?
一个变通方法,就是把已有的点拷贝到另一面的对应位置,模拟出完整的矩阵。
七、参考文献
How to program a Gaussian Blur without using 3rd party libraries
看得“深”、看得“清” —— 深度学习在图像超清化的应用
日复一日的人像临摹练习使得画家能够仅凭几个关键特征画出完整的人脸。同样地,我们希望机器能够通过低清图像有限的图像信息,推断出图像对应的高清细节,这就需要算法能够像画家一样“理解”图像内容。至此,传统的规则算法不堪重负,新兴的深度学习照耀着图像超清化的星空。
本文首发于《程序员》杂志
图1. 最新的Pixel递归网络在图像超清化上的应用。左图为低清图像,右图为其对应的高清图像,中间为算法生成结果。这是4倍超清问题,即将边长扩大为原来的4倍。

得益于硬件的迅猛发展,短短几年间,手机已更新了数代,老手机拍下的照片在大分辨率的屏幕上变得模糊起来。同样地,图像分辨率的提升使得网络带宽的压力骤增。如此,图像超清化算法就有了用武之地。
对于存放多年的老照片,我们使用超清算法令其细节栩栩如生;面对网络传输的带宽压力,我们先将图像压缩传输,再用超清化算法复原,这样可以大大减少传输数据量。
传统的几何手段如三次插值,传统的匹配手段如碎片匹配,在应对这样的需求上皆有心无力。
深度学习的出现使得算法对图像的语义级操作成为可能。本文即是介绍深度学习技术在图像超清化问题上的最新研究进展。
深度学习最早兴起于图像,其主要处理图像的技术是卷积神经网络,关于卷积神经网络的起源,业界公认是Alex在2012年的ImageNet比赛中的煌煌表现。虽方五年,却已是老生常谈。因此卷积神经网络的基础细节本文不再赘述。在下文中,使用CNN(Convolutional Neural Network)来指代卷积神经网络。
CNN出现以来,催生了很多研究热点,其中最令人印象深刻的五个热点是:
深广探索:VGG网络的出现标志着CNN在搜索的深度和广度上有了初步的突破。
结构探索:Inception及其变种的出现进一步增加了模型的深度。而ResNet的出现则使得深度学习的深度变得“名副其实”起来,可以达到上百层甚至上千层。
内容损失:图像风格转换是CNN在应用层面的一个小高峰,涌现了一批以Prisma为首的小型创业公司。但图像风格转换在技术上的真正贡献却是通过一个预训练好的模型上的特征图,在语义层面生成图像。
对抗神经网络(GAN):虽然GAN是针对机器学习领域的架构创新,但其最初的应用却是在CNN上。通过对抗训练,使得生成模型能够借用监督学习的东风进行提升,将生成模型的质量提升了一个级别。
Pixel CNN:将依赖关系引入到像素之间,是CNN模型结构方法的一次比较大的创新,用于生成图像,效果最佳,但有失效率。
这五个热点,在图像超清这个问题上都有所体现。下面会一一为大家道来。
CNN的第一次出手
图2. 首个应用于图像超清问题的CNN网络结构.输入为低清图像,输出为高清图像.该结构分为三个步骤:低清图像的特征抽取、低清特征到高清特征的映射、高清图像的重建。

图像超清问题的特点在于,低清图像和高清图像中很大部分的信息是共享的,基于这个前提,在CNN出现之前,业界的解决方案是使用一些特定的方法,如PCA、Sparse Coding等将低分辨率和高分辨率图像变为特征表示,然后将特征表示做映射。
基于传统的方法结构,CNN也将模型划分为三个部分,即特征抽取、非线性映射和特征重建。由于CNN的特性,三个部分的操作均可使用卷积完成。因而,虽然针对模型结构的解释与传统方法类似,但CNN却是可以同时联合训练的统一体,在数学上拥有更加简单的表达。
不仅在模型解释上可以看到传统方法的影子,在具体的操作上也可以看到。在上述模型中,需要对数据进行预处理,抽取出很多patch,这些patch可能互有重叠,将这些Patch取合集便是整张图像。上述的CNN结构是被应用在这些Patch而不是整张图像上,得到所有图像的patch后,将这些patch组合起来得到最后的高清图像,重叠部分取均值。
更深更快更准的CNN
图3. 基于残差的深度CNN结构。该结构使用残差连接将低清图像与CNN的输出相加得到高清图像。即仅用CNN结构学习低清图像中缺乏的高清细节部分。

图2中的方法虽然效果远高于传统方法,但是却有若干问题:
训练层数少,没有足够的视野域;
训练太慢,导致没有在深层网络上得到好的效果;
不能支持多种倍数的高清化。
针对上述问题,图3算法提出了采用更深的网络模型。并用三种技术解决了图2算法的问题。
第一种技术是残差学习,CNN是端到端的学习,如果像图2方法那样直接学习,那么CNN需要保存图像的所有信息,需要在恢复高清细节的同时记住所有的低分辨率图像的信息。如此,网络中的每一层都需要存储所有的图像信息,这就导致了信息过载,使得网络对梯度十分敏感,容易造成梯度消失或梯度爆炸等现象。而图像超清问题中,CNN的输入图像和输出图像中的信息很大一部分是共享的。残差学习是只针对图像高清细节信息进行学习的算法。如上图所示,CNN的输出加上原始的低分辨率图像得到高分辨率图像,即CNN学习到的是高分辨率图像和低分辨率图像的差。如此,CNN承载的信息量小,更容易收敛的同时还可以达到比非残差网络更好的效果。
高清图像之所以能够和低清图像做加减法,是因为,在数据预处理时,将低清图像使用插值法缩放到与高清图像同等大小。于是虽然图像被称之为低清,但其实图像大小与高清图像是一致的。
第二种技术是高学习率,在CNN中设置高学习率通常会导致梯度爆炸,因而在使用高学习率的同时还使用了自适应梯度截断。截断区间为[-θ/γ, θ/γ],其中γ为当前学习率,θ是常数。
第三种技术是数据混合,最理想化的算法是为每一种倍数分别训练一个模型,但这样极为消耗资源。因而,同之前的算法不同,本技术将不同倍数的数据集混合在一起训练得到一个模型,从而支持多种倍数的高清化。
感知损失
在此之前,使用CNN来解决高清问题时,对图像高清化的评价方式是将CNN生成模型产生的图像和实际图像以像素为单位计算损失函数(一般为欧式距离)。此损失函数得到的模型捕捉到的只是像素级别的规律,其泛化能力相对较弱。
而感知损失,则是指将CNN生成模型和实际图像都输入到某个训练好的网络中,得到这两张图像在该训练好的网络上某几层的激活值,在激活值上计算损失函数。
由于CNN能够提取高级特征,那么基于感知损失的模型能够学习到更鲁棒更令人信服的结果。
图4. 基于感知损失的图像风格转换网络。该网络也可用于图像超清问题。左侧是一个待训练的转换网络,用于对图像进行操作;右侧是一个已训练好的网络,将使用其中的几层计算损失。

图4即为感知损失网络,该网络本是用于快速图像风格转换。在这个结构中,需要训练左侧的Transform网络来生成图像,将生成的图像Y和内容图像与风格图像共同输入进右侧已经训练好的VGG网络中得到损失值。如果去掉风格图像,将内容图像变为高清图像,将输入改为低清图像,那么这个网络就可以用于解决图像超清问题了。
对抗神经网络(GAN)
图5. 对抗训练的生成网络G和判别网络结构D。上半部分是生成网络G,层次很深且使用了residual block和skip-connection结构;下半部分是判别网络D。

对抗神经网络称得上是近期机器学习领域最大的变革成果。其主要思想是训练两个模型G和D。G是生成网络而D是分类网络,G和D都用D的分类准确率来进行训练。G用于某种生成任务,比如图像超清化或图像修复等。G生成图像后,将生成图像和真实图像放到D中进行分类。使用对抗神经网络训练模型是一个追求平衡的过程:保持G不变,训练D使分类准确率提升;保持D不变,训练G使分类准确率下降,直到平衡。GAN框架使得无监督的生成任务能够利用到监督学习的优势来进行提升。
基于GAN框架,只要定义好生成网络和分类网络,就可以完成某种生成任务。
而将GAN应用到图像高清问题的这篇论文,可以说是集大成之作。生成模型层次深且使用了residual block和skip-connection;在GAN的损失函数的基础上同时添加了感知损失。
GAN的生成网络和分类网络如图5,其中,生成网络自己也可以是一个单独的图像超清算法。论文中分析了GAN和non-GAN的不同,发现GAN主要在细节方面起作用,但无法更加深入地解释。“无法解释性”也是GAN目前的缺点之一。
像素递归网络(Pixel CNN)
图5中的GAN虽然能够达到比较好的效果,但是由于可解释性差,难免有套用之嫌。
其实,对于图像超清这个问题来说,存在一个关键性的问题,即一张低清图像可能对应着多张高清图像,那么问题来了。
假如我们把低分辨率图像中需要高清化的部分分成A,B,C,D等几个部分,那么A可能对应A1,A2,A3,A4,B对应B1,B2,B3,B4,以此类推。假设A1,B1,C1,D1对应一张完美的高清图片。那么现有的算法可能生成的是A1,B2,C3,D4这样的混搭,从而导致生成的高清图像模糊。
为了验证上述问题的存在,设想一种极端情况。
图6. 图像超清模糊性问题分析图示。上半部分为分析问题所用数据集的构建。下半部分为现有的损失函数在这个问题上的效果。可以通过对比看出,PixelCNN能够防止这种模糊的出现。

为了分析图像模糊问题的成因,在图6的上半部分,基于MNist数据集生成一个新的数据集。生成方法如下:将MNIST数据集中的图片A长宽各扩大两倍,每张图片可以生成两张图片A1和A2,A1中A处于右下角,A2中A处于左上角。
把原图当做低清图片,生成的图当成高清图片。使用图6下半部分所列举的三种方法进行训练,得到的模型,在生成图像的时候,会产生图6下半部分的结果。即每个像素点可能等概率地投射到左上部分和右下部分,从而导致生成的图片是错误的。而引入PixelCNN后,由于像素之间产生了依赖关系,很好地避免了这种情况的发生。
为了解决上述问题,需要在生成图像的同时引入先验知识。画家在拥有了人脸的知识之后,就可以画出令人信服的高清细节。类比到图像超清问题中,先验知识即是告知算法该选择哪一种高清结果。
在图像超清问题中,这样的知识体现为让像素之间有相互依赖的关系。这样,就可以保证A、B、C、D四个不同的部分对于高清版的选择是一致的。
图7. 基于PixelCNN的解决图像超清问题的CNN网络结构。其中先验网络(prior network)为PixelCNN;条件网络(conditioning network)为图像生成网络,其结构与作用同GAN中的生成网络、感知损失中的转换网络均类似。

模型架构如图7。其中条件网络是一个在低清图像的基础上生成高清图像的网络。它能以像素为单位独立地生成高清图像,如同GAN中的G网络,感知损失中的转换网络。而先验网络则是一个Pixel CNN组件,它用来增加高清图像像素间的依赖,使像素选择一致的高清细节,从而看起来更加自然。
那么Pixel CNN是如何增加依赖的呢?在生成网络的时候,Pixel CNN以像素为单位进行生成,从左上角到右下角,在生成当前像素的时候,会考虑之前生成的像素。
若加上先验网络和条件网络的混合, PixelCNN在生成图像的时候,除了考虑前面生成的像素,还需要考虑条件网络的结果。
总结
上述算法是图像超清问题中使用的较为典型的CNN结构,此外,还有很多其他的结构也达到了比较好的效果。随着CNN网络结构层次的日益加深,距离实用场景反而越来越远。譬如,基于GAN的网络结构的训练很难稳定,且结果具有不可解释性;基于PixelCNN的网络在使用中由于要在pixel级别生成,无法并行,导致生成效率极为低下。
更进一步地,从实用出发,可以在数据方向上进行进一步的优化。譬如,现在的算法输入图像都是由低清图像三次插值而来,那么,是否可以先用一个小网络得到的结果来作为初始化的值呢?再如,多个小网络串联是否能得到比一个大网络更好的结果等等。
图像超清问题是一个相对来说比较简单的图像语义问题,相信这只是图像语义操作的一个开始,今后越来越多的图像处理问题将会因为CNN的出现迎刃而解。
参考文献
[1] Dong C, Loy C C, He K, et al. Image super-resolution using deep convolutional networks[J]. IEEE transactions on pattern analysis and machine intelligence, 2016, 38(2): 295-307.
[2] Kim J, Kwon Lee J, Mu Lee K. Accurate image super-resolution using very deep convolutional networks[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016: 1646-1654.
[3] Johnson J, Alahi A, Fei-Fei L. Perceptual losses for real-time style transfer and super-resolution[C]//European Conference on Computer Vision. Springer International Publishing, 2016: 694-711.
[4] Ledig C, Theis L, Huszár F, et al. Photo-realistic single image super-resolution using a generative adversarial network[J]. arXiv preprint arXiv:1609.04802, 2016.
[5] Dahl R, Norouzi M, Shlens J. Pixel Recursive Super Resolution[J]. arXiv preprint arXiv:1702.00783, 2017.
深度学习之图像修复
图像修复问题就是还原图像中缺失的部分。基于图像中已有信息,去还原图像中的缺失部分。

从直观上看,这个问题能否解决是看情况的,还原的关键在于剩余信息的使用,剩余信息中如果存在有缺失部分信息的patch,那么剩下的问题就是从剩余信息中判断缺失部分与哪一部分相似。而这,就是现在比较流行的PatchMatch的基本思想。
CNN出现以来,有若干比较重要的进展:
被证明有能力在CNN的高层捕捉到图像的抽象信息。
Perceptual Loss的出现证明了一个训练好的CNN网络的feature map可以很好的作为图像生成中的损失函数的辅助工具。
GAN可以利用监督学习来强化生成网络的效果。其效果的原因虽然还不具可解释性,但是可以理解为可以以一种不直接的方式使生成网络学习到规律。
基于上述三个进展,参考文献[1]提出了一种基于CNN的图像复原方法。
CNN网络结构

该算法需要使用两个网络,一个是内容生成网络,另一个是纹理生成网络。内容生成网络直接用于生成图像,推断缺失部分可能的内容。纹理生成网络用于增强内容网络的产出的纹理,具体则为将生成的补全图像和原始无缺失图像输入进纹理生成网络,在某一层feature_map上计算损失,记为Loss NN。
内容生成网络需要使用自己的数据进行训练,而纹理生成网络则使用已经训练好的VGG Net。这样,生成图像可以分为如下几个步骤:
定义缺失了某个部分的图像为x0
x0输入进内容生成网络得到生成图片x
x作为最后生成图像的初始值
保持纹理生成网络的参数不变,使用Loss NN对x进行梯度下降,得到最后的结果。
关于内容生成网络的训练和Loss NN的定义,下面会一一解释
内容生成网络

生成网络结构如上,其损失函数使用了L2损失和对抗损失的组合。所谓的对抗损失是来源于对抗神经网络.



在该生成网络中,为了是训练稳定,做了两个改变:
将所有的ReLU/leaky-ReLU都替换为ELU层
使用fully-connected layer替代chnnel-wise的全连接网络。
纹理生成网络
纹理生成网络的Loss NN如下:

它分为三个部分,即Pixel-wise的欧式距离,基于已训练好纹理网络的feature layer的perceptual loss,和用于平滑的TV Loss。
α和β都是5e-6,
Pixel-wise的欧氏距离如下:

TV Loss如下:

Perceptual Loss的计算比较复杂,这里利用了PatchMatch的信息,即为缺失部分找到最近似的Patch,为了达到这一点,将缺失部分分为很多个固定大小的patch作为query,也将已有的部分分为同样固定大小的patch,生成dataset PATCHES,在匹配query和PATCHES中最近patch的时候,需要在纹理生成网络中的某个layer的激活值上计算距离而不是计算像素距离。
但是,寻找最近邻Patch这个操作似乎是不可计算导数的,如何破解这一点呢?同MRF+CNN类似,在这里,先将PATCHES中的各个patch的的feature_map抽取出来,将其组合成为一个新的卷积层,然后得到query的feature map后输入到这个卷积层中,最相似的patch将获得最大的激活值,所以将其再输入到一个max-pooling层中,得到这个最大值。这样,就可以反向传播了。
高清图像上的应用
本算法直接应用到高清图像上时效果并不好,所以,为了更好的初始化,使用了Stack迭代算法。即先将高清图像down-scale到若干级别[1,2,3,…,S],其中S级别为原图本身,然后在级别1上使用图像均值初始化缺失部分,得到修复后的结果,再用这个结果,初始化下一级别的输入。以此类推。

效果

上图从上往下一次为,有缺失的原图,PatchMatch算法,Context Decoder算法(GAN+L2)和本算法。
内容生成网络的作用

起到了内容限制的作用,上图比较了有内容生成网络和没有内容生成网络的区别,有的可以在内容上更加符合原图。
应用
图像的语义编辑,从左到右依次为原图,扣掉某部分的原图,PatchMatch结果,和本算法结果。

可知,该方法虽然不可以复原真实的图像,但却可以补全成一张完整的图像。这样,当拍照中有不想干的物体或人进入到摄像头中时,依然可以将照片修复成一张完整的照片。
总结
CNN的大发展,图像越来越能够变得语义化了。有了以上的图像复原的基础,尽可以进行发挥自己的想象,譬如:在图像上加一个东西,但是光照和颜色等缺明显不搭,可以用纹理网络进行修复。
该方法的缺点也是很明显:
性能和内存问题
只用了图片内的patch,而没有用到整个数据集中的数据。
参考文献
[1]. Yang C, Lu X, Lin Z, et al. High-Resolution Image Inpainting using Multi-Scale Neural Patch Synthesis[J]. arXiv preprint arXiv:1611.09969, 2016.
图像风格转换(Image style transfer)
图像风格转换是最近新兴起的一种基于深度学习的技术,它的出现一方面是占了卷积神经网络的天时,卷积神经网络所带来的对图像特征的高层特征的抽取使得风格和内容的分离成为了可能。另一方面则可能是作者的灵感,内容的表示是卷积神经网络所擅长,但风格却不是,如何保持内容而转换风格则是本文所要讲述的。
本篇属于论文阅读笔记系列。论文即[1].
引入
风格转换属于纹理转换问题,纹理转换问题在之前采用的是一些非参方法,通过一些专有的固定的方法来渲染。
传统的方法的问题在于只能提取底层特征而非高层抽象特征。随着CNN的日渐成熟,终于,这个领域被渗透了进来。
最近的很多应用型的研究成果都是将CNN渗透进各个领域,从而,在普遍意义上完成一次技术的升级。
方法
可以进行风格转换的基本就是将内容和风格区分开来,接下来我们来看CNN如何做到这一点。
内容提取
和之前类似,内容就是采用CNN的某一层或者某几层来表示,一般来说,层级越高,表示就越抽象。这里,需要有几个形式化的表达:
Ml: 第l层的feature map的大小
Nl: 第l层的filter的数目
Fl: 图像在第l层的特征表示,是一个矩阵,矩阵大小为Ml * Nl.
Flij: 第l层第i个filter上位置j处的激活值。
p: 原始内容图片
x: 生成图片
Pl: 原始图片在CNN中第l层的表示
Fl: 生成图片在CNN中第l层的表示
因而,我们就得到了内容的loss。

求导即为:

有了这个公式之后要怎么做呢? 使用现在公布的训练好的某些CNN网络,随机初始化一个输入图片大小的噪声图像x,然后保持CNN参数不变,将原始图片P和x输入进网络,然后对x求导,这样,x就会在内容上越来越趋近于P。
风格提取
而风格的转换则是这篇论文的神来之笔,论文使用相关矩阵来表示图像的风格。当然,风格的抽取仍然是以层为单位的。
a: 初始风格图片
Al: 风格图片某一层的风格特征表示。
Gl: 生成图片某一层的风格特征表示,大小为Nl * Nl

其中,Glij的值是l层第i个feature map和第j个feature map的内积。
从而,我们得到了风格损失函数。
单独某层的损失函数:

各层综合的损失函数:

求偏导:

与内容表示类似,如果我们用随机初始化的x,保持CNN参数不变,将风格图片A和x输入进网络,然后对x求导,x就会在风格上趋近于A。
内容重建与风格重建
不考虑风格转换,只单独的考虑内容或者风格,可以看到如图所示:
图的上半部分是风格重建,由图可见,越用高层的特征,风格重建的就越粗粒度化。下半部分是内容重建,由图可见,越是底层的特征,重建的效果就越精细,越不容易变形。

风格转换
有了内容与风格,风格转换就呼之欲出了,即两种loss的加权。

也可如图示:

即同时将三张图片(a, p, x)输入进三个相同的网络,对a求出风格特征,对p求出内容特征,然后对x求导,这样,得到的x就有a的风格和p的内容。
实验
实验使用的是训练好的19层VGG,并通过调整权重使得每一层的激活值得均值为0。权重的调整并不会影响VGG的输出。在试验中没有使用全连接层。
实验调整了一些参数,相对其他论文而言,本论文的参数其实并不多,有:
loss加权的权重之比
层级的选择
初始化的方法。
loss权重之比
比例越大,内容就越强势。

层级的选择
固定住风格的层级,变动内容的层级,可以看到,内容层级越低,结果图片中的内容就越明显。

初始化方法的选择
A: 从内容图片初始化
B: 从风格图片初始化
C: 随机初始化
可以看到,初始化的不同似乎对最后结果影响不大。

效果
一张图片对应到各种风格:



照片风格转换:

讨论
速度,因为每张图片的生成都要求导很多遍,因而高清图片的生成非常慢。
会引入噪声,在风格转换上不明显,但风格和内容都是照片的情况下,就变得非常明显了。但这个问题估计可以很容易解决。
风格转换的边界非常不明显,人类也无法量化一张图片中哪一些属于风格,哪一些属于内容。
风格转换的成功为生物学中人类视觉原理的研究提供了一条可以切入的点。
最后一个优势我觉得充分体现作者的视野。
思考
说了那么多,为何相关矩阵可以提取风格?我百思不得其解。
直观上看,风格肯定是一种遍布整个图片的共性,而相关性矩阵,我认为正是把这些共性抽象的加以提取。在这个思路下,或许可以探讨其他可以提取共性的方式。比如
多项式方式
两两相乘变成三三相乘。
是不是可以通过控制给相关性矩阵加mask的方式来探讨各种feature map的真实作用。
参考文献
[1]. Gatys L A, Ecker A S, Bethge M. Image style transfer using convolutional neural networks[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016: 2414-2423.