
开源的奇迹,取之于众,用之于众。
User space 与 Kernel space
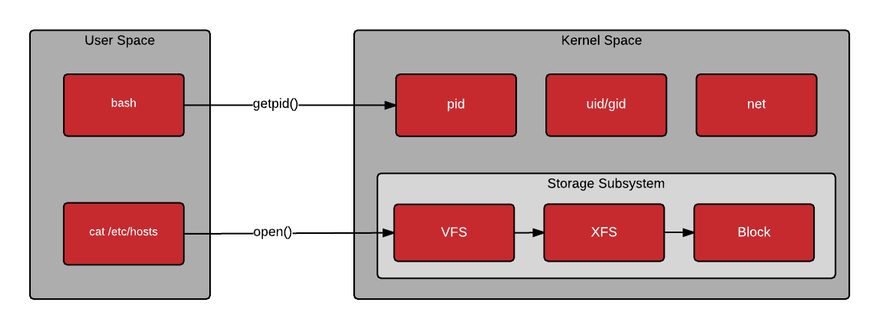
简单说,Kernel space 是 Linux 内核的运行空间,User space 是用户程序的运行空间。为了安全,它们是隔离的,即使用户的程序崩溃了,内核也不受影响。Kernel space 可以执行任意命令,调用系统的一切资源;User space 只能执行简单的运算,不能直接调用系统资源,必须通过系统接口(又称 system call),才能向内核发出指令。
如何读懂火焰图?
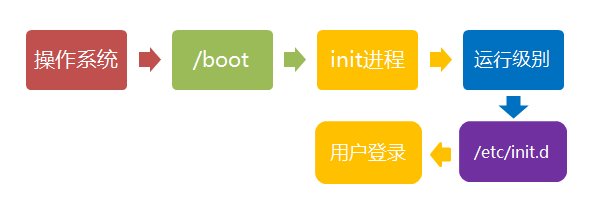
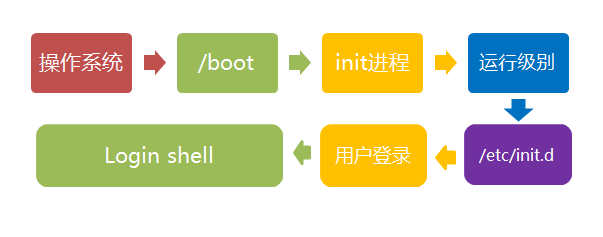
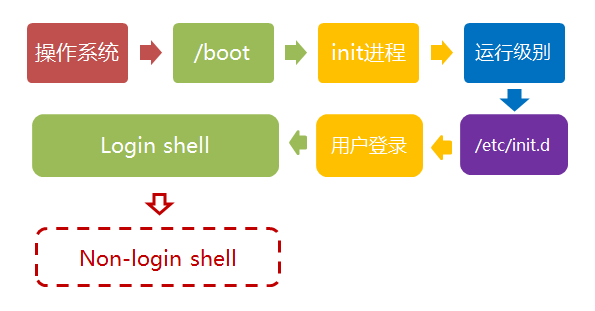
Linux 的启动流程
作者: 阮一峰
日期: 2013年8月17日
半年前,我写了《计算机是如何启动的?》,探讨BIOS和主引导记录的作用。
那篇文章不涉及操作系统,只与主板的板载程序有关。今天,我想接着往下写,探讨操作系统接管硬件以后发生的事情,也就是操作系统的启动流程。
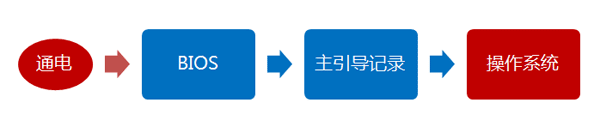
这个部分比较有意思。因为在BIOS阶段,计算机的行为基本上被写死了,程序员可以做的事情并不多;但是,一旦进入操作系统,程序员几乎可以定制所有方面。所以,这个部分与程序员的关系更密切。
我主要关心的是Linux操作系统,它是目前服务器端的主流操作系统。下面的内容针对的是Debian发行版,因为我对其他发行版不够熟悉。
第一步、加载内核
操作系统接管硬件以后,首先读入 /boot 目录下的内核文件。

以我的电脑为例,/boot 目录下面大概是这样一些文件:
$ ls /boot
config-3.2.0-3-amd64
config-3.2.0-4-amd64
grub
initrd.img-3.2.0-3-amd64
initrd.img-3.2.0-4-amd64
System.map-3.2.0-3-amd64
System.map-3.2.0-4-amd64
vmlinuz-3.2.0-3-amd64
vmlinuz-3.2.0-4-amd64
第二步、启动初始化进程
内核文件加载以后,就开始运行第一个程序 /sbin/init,它的作用是初始化系统环境。
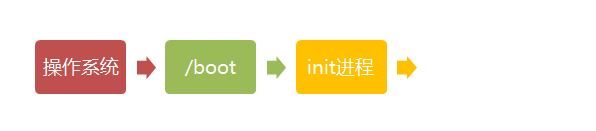
由于init是第一个运行的程序,它的进程编号(pid)就是1。其他所有进程都从它衍生,都是它的子进程。
第三步、确定运行级别
许多程序需要开机启动。它们在Windows叫做”服务”(service),在Linux就叫做”守护进程”(daemon)。
init进程的一大任务,就是去运行这些开机启动的程序。但是,不同的场合需要启动不同的程序,比如用作服务器时,需要启动Apache,用作桌面就不需要。Linux允许为不同的场合,分配不同的开机启动程序,这就叫做”运行级别”(runlevel)。也就是说,启动时根据”运行级别”,确定要运行哪些程序。

Linux预置七种运行级别(0-6)。一般来说,0是关机,1是单用户模式(也就是维护模式),6是重启。运行级别2-5,各个发行版不太一样,对于Debian来说,都是同样的多用户模式(也就是正常模式)。
init进程首先读取文件 /etc/inittab,它是运行级别的设置文件。如果你打开它,可以看到第一行是这样的:
id:2:initdefault:
initdefault的值是2,表明系统启动时的运行级别为2。如果需要指定其他级别,可以手动修改这个值。
那么,运行级别2有些什么程序呢,系统怎么知道每个级别应该加载哪些程序呢?……回答是每个运行级别在/etc目录下面,都有一个对应的子目录,指定要加载的程序。
/etc/rc0.d
/etc/rc1.d
/etc/rc2.d
/etc/rc3.d
/etc/rc4.d
/etc/rc5.d
/etc/rc6.d
上面目录名中的”rc”,表示run command(运行程序),最后的d表示directory(目录)。下面让我们看看 /etc/rc2.d 目录中到底指定了哪些程序。
$ ls /etc/rc2.d
README
S01motd
S13rpcbind
S14nfs-common
S16binfmt-support
S16rsyslog
S16sudo
S17apache2
S18acpid
…
可以看到,除了第一个文件README以外,其他文件名都是”字母S+两位数字+程序名”的形式。字母S表示Start,也就是启动的意思(启动脚本的运行参数为start),如果这个位置是字母K,就代表Kill(关闭),即如果从其他运行级别切换过来,需要关闭的程序(启动脚本的运行参数为stop)。后面的两位数字表示处理顺序,数字越小越早处理,所以第一个启动的程序是motd,然后是rpcbing、nfs……数字相同时,则按照程序名的字母顺序启动,所以rsyslog会先于sudo启动。
这个目录里的所有文件(除了README),就是启动时要加载的程序。如果想增加或删除某些程序,不建议手动修改 /etc/rcN.d 目录,最好是用一些专门命令进行管理(参考这里和这里)。
第四步、加载开机启动程序
前面提到,七种预设的”运行级别”各自有一个目录,存放需要开机启动的程序。不难想到,如果多个”运行级别”需要启动同一个程序,那么这个程序的启动脚本,就会在每一个目录里都有一个拷贝。这样会造成管理上的困扰:如果要修改启动脚本,岂不是每个目录都要改一遍?
Linux的解决办法,就是七个 /etc/rcN.d 目录里列出的程序,都设为链接文件,指向另外一个目录 /etc/init.d ,真正的启动脚本都统一放在这个目录中。init进程逐一加载开机启动程序,其实就是运行这个目录里的启动脚本。
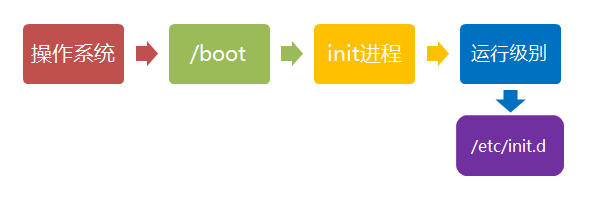
下面就是链接文件真正的指向。
$ ls -l /etc/rc2.d
README
S01motd -> ../init.d/motd
S13rpcbind -> ../init.d/rpcbind
S14nfs-common -> ../init.d/nfs-common
S16binfmt-support -> ../init.d/binfmt-support
S16rsyslog -> ../init.d/rsyslog
S16sudo -> ../init.d/sudo
S17apache2 -> ../init.d/apache2
S18acpid -> ../init.d/acpid
…
这样做的另一个好处,就是如果你要手动关闭或重启某个进程,直接到目录 /etc/init.d 中寻找启动脚本即可。比如,我要重启Apache服务器,就运行下面的命令:
$ sudo /etc/init.d/apache2 restart
/etc/init.d 这个目录名最后一个字母d,是directory的意思,表示这是一个目录,用来与程序 /etc/init 区分。
第五步、用户登录
开机启动程序加载完毕以后,就要让用户登录了。
一般来说,用户的登录方式有三种:
(1)命令行登录
(2)ssh登录
(3)图形界面登录
这三种情况,都有自己的方式对用户进行认证。
(1)命令行登录:init进程调用getty程序(意为get teletype),让用户输入用户名和密码。输入完成后,再调用login程序,核对密码(Debian还会再多运行一个身份核对程序/etc/pam.d/login)。如果密码正确,就从文件 /etc/passwd 读取该用户指定的shell,然后启动这个shell。
(2)ssh登录:这时系统调用sshd程序(Debian还会再运行/etc/pam.d/ssh ),取代getty和login,然后启动shell。
(3)图形界面登录:init进程调用显示管理器,Gnome图形界面对应的显示管理器为gdm(GNOME Display Manager),然后用户输入用户名和密码。如果密码正确,就读取/etc/gdm3/Xsession,启动用户的会话。
第六步、进入 login shell
所谓shell,简单说就是命令行界面,让用户可以直接与操作系统对话。用户登录时打开的shell,就叫做login shell。
Debian默认的shell是Bash,它会读入一系列的配置文件。上一步的三种情况,在这一步的处理,也存在差异。
(1)命令行登录:首先读入 /etc/profile,这是对所有用户都有效的配置;然后依次寻找下面三个文件,这是针对当前用户的配置。
~/.bash_profile
~/.bash_login
~/.profile
需要注意的是,这三个文件只要有一个存在,就不再读入后面的文件了。比如,要是 ~/.bash_profile 存在,就不会再读入后面两个文件了。
(2)ssh登录:与第一种情况完全相同。
(3)图形界面登录:只加载 /etc/profile 和 ~/.profile。也就是说,~/.bash_profile 不管有没有,都不会运行。
第七步,打开 non-login shell
老实说,上一步完成以后,Linux的启动过程就算结束了,用户已经可以看到命令行提示符或者图形界面了。但是,为了内容的完整,必须再介绍一下这一步。
用户进入操作系统以后,常常会再手动开启一个shell。这个shell就叫做 non-login shell,意思是它不同于登录时出现的那个shell,不读取/etc/profile和.profile等配置文件。
non-login shell的重要性,不仅在于它是用户最常接触的那个shell,还在于它会读入用户自己的bash配置文件 ~/.bashrc。大多数时候,我们对于bash的定制,都是写在这个文件里面的。
你也许会问,要是不进入 non-login shell,岂不是.bashrc就不会运行了,因此bash 也就不能完成定制了?事实上,Debian已经考虑到这个问题了,请打开文件 ~/.profile,可以看到下面的代码:
if [ -n “$BASH_VERSION” ]; then
if [ -f “$HOME/.bashrc” ]; then
. “$HOME/.bashrc”
fi
fi
上面代码先判断变量 $BASH_VERSION 是否有值,然后判断主目录下是否存在 .bashrc 文件,如果存在就运行该文件。第三行开头的那个点,是source命令的简写形式,表示运行某个文件,写成”source ~/.bashrc”也是可以的。
因此,只要运行~/.profile文件,~/.bashrc文件就会连带运行。但是上一节的第一种情况提到过,如果存在~/.bash_profile文件,那么有可能不会运行~/.profile文件。解决这个问题很简单,把下面代码写入.bash_profile就行了。
if [ -f ~/.profile ]; then
. ~/.profile
fi
这样一来,不管是哪种情况,.bashrc都会执行,用户的设置可以放心地都写入这个文件了。
Bash的设置之所以如此繁琐,是由于历史原因造成的。早期的时候,计算机运行速度很慢,载入配置文件需要很长时间,Bash的作者只好把配置文件分成了几个部分,阶段性载入。系统的通用设置放在 /etc/profile,用户个人的、需要被所有子进程继承的设置放在.profile,不需要被继承的设置放在.bashrc。
顺便提一下,除了Linux以外, Mac OS X 使用的shell也是Bash。但是,它只加载.bash_profile,然后在.bash_profile里面调用.bashrc。而且,不管是ssh登录,还是在图形界面里启动shell窗口,都是如此。
参考链接
[1] Debian Wiki, Environment Variables
[2] Debian Wiki, Dot Files
[3] Debian Administration, An introduction to run-levels
[4] Debian Admin,Debian and Ubuntu Linux Run Levels
[5] Linux Information Project (LINFO), Runlevel Definition
[6] LinuxQuestions.org, What are run levels?
[7] Dalton Hubble, Bash Configurations Demystified
(完)
Linux 守护进程的启动方法
“守护进程”(daemon)就是一直在后台运行的进程(daemon)。
daemon英 [ˈdi:mən] 美 [‘dimən]
n. (希腊神话中)半人半神的精灵; 守护神; [计]守护进程;
Systemd 入门教程:命令篇
Systemd 入门教程:实战篇
Systemd 定时器教程
Systemd 作为 Linux 的系统启动器,功能强大。
本文通过一个简单例子,介绍 Systemd 如何设置定时任务。这不仅实用,而且可以作为 Systemd 的上手教程。
理解Linux系统负荷
作者: 阮一峰
日期: 2011年7月31日
一、查看系统负荷
如果你的电脑很慢,你或许想查看一下,它的工作量是否太大了。
在Linux系统中,我们一般使用uptime命令查看(w命令和top命令也行)。(另外,它们在苹果公司的Mac电脑上也适用。)
你在终端窗口键入uptime,系统会返回一行信息。
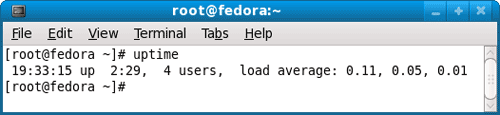
这行信息的后半部分,显示”load average”,它的意思是”系统的平均负荷”,里面有三个数字,我们可以从中判断系统负荷是大还是小。

为什么会有三个数字呢?你从手册中查到,它们的意思分别是1分钟、5分钟、15分钟内系统的平均负荷。
如果你继续看手册,它还会告诉你,当CPU完全空闲的时候,平均负荷为0;当CPU工作量饱和的时候,平均负荷为1。
那么很显然,”load average”的值越低,比如等于0.2或0.3,就说明电脑的工作量越小,系统负荷比较轻。
但是,什么时候能看出系统负荷比较重呢?等于1的时候,还是等于0.5或等于1.5的时候?如果1分钟、5分钟、15分钟三个值不一样,怎么办?
二、一个类比
判断系统负荷是否过重,必须理解load average的真正含义。下面,我根据”Understanding Linux CPU Load”这篇文章,尝试用最通俗的语言,解释这个问题。
首先,假设最简单的情况,你的电脑只有一个CPU,所有的运算都必须由这个CPU来完成。
那么,我们不妨把这个CPU想象成一座大桥,桥上只有一根车道,所有车辆都必须从这根车道上通过。(很显然,这座桥只能单向通行。)
系统负荷为0,意味着大桥上一辆车也没有。
系统负荷为0.5,意味着大桥一半的路段有车。
系统负荷为1.0,意味着大桥的所有路段都有车,也就是说大桥已经”满”了。但是必须注意的是,直到此时大桥还是能顺畅通行的。
系统负荷为1.7,意味着车辆太多了,大桥已经被占满了(100%),后面等着上桥的车辆为桥面车辆的70%。以此类推,系统负荷2.0,意味着等待上桥的车辆与桥面的车辆一样多;系统负荷3.0,意味着等待上桥的车辆是桥面车辆的2倍。总之,当系统负荷大于1,后面的车辆就必须等待了;系统负荷越大,过桥就必须等得越久。
CPU的系统负荷,基本上等同于上面的类比。大桥的通行能力,就是CPU的最大工作量;桥梁上的车辆,就是一个个等待CPU处理的进程(process)。
如果CPU每分钟最多处理100个进程,那么系统负荷0.2,意味着CPU在这1分钟里只处理20个进程;系统负荷1.0,意味着CPU在这1分钟里正好处理100个进程;系统负荷1.7,意味着除了CPU正在处理的100个进程以外,还有70个进程正排队等着CPU处理。
为了电脑顺畅运行,系统负荷最好不要超过1.0,这样就没有进程需要等待了,所有进程都能第一时间得到处理。很显然,1.0是一个关键值,超过这个值,系统就不在最佳状态了,你要动手干预了。
三、系统负荷的经验法则
1.0是系统负荷的理想值吗?
不一定,系统管理员往往会留一点余地,当这个值达到0.7,就应当引起注意了。经验法则是这样的:
当系统负荷持续大于0.7,你必须开始调查了,问题出在哪里,防止情况恶化。
当系统负荷持续大于1.0,你必须动手寻找解决办法,把这个值降下来。
当系统负荷达到5.0,就表明你的系统有很严重的问题,长时间没有响应,或者接近死机了。你不应该让系统达到这个值。
四、多处理器
上面,我们假设你的电脑只有1个CPU。如果你的电脑装了2个CPU,会发生什么情况呢?
2个CPU,意味着电脑的处理能力翻了一倍,能够同时处理的进程数量也翻了一倍。
还是用大桥来类比,两个CPU就意味着大桥有两根车道了,通车能力翻倍了。

所以,2个CPU表明系统负荷可以达到2.0,此时每个CPU都达到100%的工作量。推广开来,n个CPU的电脑,可接受的系统负荷最大为n.0。
五、多核处理器
芯片厂商往往在一个CPU内部,包含多个CPU核心,这被称为多核CPU。
在系统负荷方面,多核CPU与多CPU效果类似,所以考虑系统负荷的时候,必须考虑这台电脑有几个CPU、每个CPU有几个核心。然后,把系统负荷除以总的核心数,只要每个核心的负荷不超过1.0,就表明电脑正常运行。
怎么知道电脑有多少个CPU核心呢?
“cat /proc/cpuinfo”命令,可以查看CPU信息。”grep -c ‘model name’ /proc/cpuinfo”命令,直接返回CPU的总核心数。
六、最佳观察时长
最后一个问题,”load average”一共返回三个平均值—-1分钟系统负荷、5分钟系统负荷,15分钟系统负荷,—-应该参考哪个值?
如果只有1分钟的系统负荷大于1.0,其他两个时间段都小于1.0,这表明只是暂时现象,问题不大。
如果15分钟内,平均系统负荷大于1.0(调整CPU核心数之后),表明问题持续存在,不是暂时现象。所以,你应该主要观察”15分钟系统负荷”,将它作为电脑正常运行的指标。
==========================================
[参考文献]
Understanding Linux CPU Load
Wikipedia - Load (computing)
(完)
SSH原理与运用(一):远程登录
作者: 阮一峰
日期: 2011年12月21日
SSH是每一台Linux电脑的标准配置。
随着Linux设备从电脑逐渐扩展到手机、外设和家用电器,SSH的使用范围也越来越广。不仅程序员离不开它,很多普通用户也每天使用。
SSH具备多种功能,可以用于很多场合。有些事情,没有它就是办不成。本文是我的学习笔记,总结和解释了SSH的常见用法,希望对大家有用。
虽然本文内容只涉及初级应用,较为简单,但是需要读者具备最基本的”Shell知识”和了解”公钥加密”的概念。如果你对它们不熟悉,我推荐先阅读《UNIX / Linux 初学者教程》和《数字签名是什么?》。
=======================================
SSH原理与运用
作者:阮一峰
一、什么是SSH?
简单说,SSH是一种网络协议,用于计算机之间的加密登录。
如果一个用户从本地计算机,使用SSH协议登录另一台远程计算机,我们就可以认为,这种登录是安全的,即使被中途截获,密码也不会泄露。
最早的时候,互联网通信都是明文通信,一旦被截获,内容就暴露无疑。1995年,芬兰学者Tatu Ylonen设计了SSH协议,将登录信息全部加密,成为互联网安全的一个基本解决方案,迅速在全世界获得推广,目前已经成为Linux系统的标准配置。
需要指出的是,SSH只是一种协议,存在多种实现,既有商业实现,也有开源实现。本文针对的实现是OpenSSH,它是自由软件,应用非常广泛。
此外,本文只讨论SSH在Linux Shell中的用法。如果要在Windows系统中使用SSH,会用到另一种软件PuTTY,这需要另文介绍。
二、最基本的用法
SSH主要用于远程登录。假定你要以用户名user,登录远程主机host,只要一条简单命令就可以了。
$ ssh user@host
如果本地用户名与远程用户名一致,登录时可以省略用户名。
$ ssh host
SSH的默认端口是22,也就是说,你的登录请求会送进远程主机的22端口。使用p参数,可以修改这个端口。
$ ssh -p 2222 user@host
上面这条命令表示,ssh直接连接远程主机的2222端口。
三、中间人攻击
SSH之所以能够保证安全,原因在于它采用了公钥加密。
整个过程是这样的:(1)远程主机收到用户的登录请求,把自己的公钥发给用户。(2)用户使用这个公钥,将登录密码加密后,发送回来。(3)远程主机用自己的私钥,解密登录密码,如果密码正确,就同意用户登录。
这个过程本身是安全的,但是实施的时候存在一个风险:如果有人截获了登录请求,然后冒充远程主机,将伪造的公钥发给用户,那么用户很难辨别真伪。因为不像https协议,SSH协议的公钥是没有证书中心(CA)公证的,也就是说,都是自己签发的。
可以设想,如果攻击者插在用户与远程主机之间(比如在公共的wifi区域),用伪造的公钥,获取用户的登录密码。再用这个密码登录远程主机,那么SSH的安全机制就荡然无存了。这种风险就是著名的”中间人攻击”(Man-in-the-middle attack)。
SSH协议是如何应对的呢?
四、口令登录
如果你是第一次登录对方主机,系统会出现下面的提示:
$ ssh user@host
The authenticity of host ‘host (12.18.429.21)’ can’t be established.
RSA key fingerprint is 98:2e:d7:e0:de:9f:ac:67:28:c2:42:2d:37:16:58:4d.
Are you sure you want to continue connecting (yes/no)?
这段话的意思是,无法确认host主机的真实性,只知道它的公钥指纹,问你还想继续连接吗?
所谓”公钥指纹”,是指公钥长度较长(这里采用RSA算法,长达1024位),很难比对,所以对其进行MD5计算,将它变成一个128位的指纹。上例中是98:2e:d7:e0:de:9f:ac:67:28:c2:42:2d:37:16:58:4d,再进行比较,就容易多了。
很自然的一个问题就是,用户怎么知道远程主机的公钥指纹应该是多少?回答是没有好办法,远程主机必须在自己的网站上贴出公钥指纹,以便用户自行核对。
假定经过风险衡量以后,用户决定接受这个远程主机的公钥。
Are you sure you want to continue connecting (yes/no)? yes
系统会出现一句提示,表示host主机已经得到认可。
Warning: Permanently added ‘host,12.18.429.21’ (RSA) to the list of known hosts.
然后,会要求输入密码。
Password: (enter password)
如果密码正确,就可以登录了。
当远程主机的公钥被接受以后,它就会被保存在文件$HOME/.ssh/known_hosts之中。下次再连接这台主机,系统就会认出它的公钥已经保存在本地了,从而跳过警告部分,直接提示输入密码。
每个SSH用户都有自己的known_hosts文件,此外系统也有一个这样的文件,通常是/etc/ssh/ssh_known_hosts,保存一些对所有用户都可信赖的远程主机的公钥。
五、公钥登录
使用密码登录,每次都必须输入密码,非常麻烦。好在SSH还提供了公钥登录,可以省去输入密码的步骤。
所谓”公钥登录”,原理很简单,就是用户将自己的公钥储存在远程主机上。登录的时候,远程主机会向用户发送一段随机字符串,用户用自己的私钥加密后,再发回来。远程主机用事先储存的公钥进行解密,如果成功,就证明用户是可信的,直接允许登录shell,不再要求密码。
这种方法要求用户必须提供自己的公钥。如果没有现成的,可以直接用ssh-keygen生成一个:
$ ssh-keygen
运行上面的命令以后,系统会出现一系列提示,可以一路回车。其中有一个问题是,要不要对私钥设置口令(passphrase),如果担心私钥的安全,这里可以设置一个。
运行结束以后,在$HOME/.ssh/目录下,会新生成两个文件:id_rsa.pub和id_rsa。前者是你的公钥,后者是你的私钥。
这时再输入下面的命令,将公钥传送到远程主机host上面:
$ ssh-copy-id user@host
好了,从此你再登录,就不需要输入密码了。
如果还是不行,就打开远程主机的/etc/ssh/sshd_config这个文件,检查下面几行前面”#”注释是否取掉。
RSAAuthentication yes
PubkeyAuthentication yes
AuthorizedKeysFile .ssh/authorized_keys
然后,重启远程主机的ssh服务。
// ubuntu系统
service ssh restart
// debian系统
/etc/init.d/ssh restart
六、authorized_keys文件
远程主机将用户的公钥,保存在登录后的用户主目录的$HOME/.ssh/authorized_keys文件中。公钥就是一段字符串,只要把它追加在authorized_keys文件的末尾就行了。
这里不使用上面的ssh-copy-id命令,改用下面的命令,解释公钥的保存过程:
$ ssh user@host ‘mkdir -p .ssh && cat >> .ssh/authorized_keys’ < ~/.ssh/id_rsa.pub
这条命令由多个语句组成,依次分解开来看:(1)”$ ssh user@host”,表示登录远程主机;(2)单引号中的mkdir .ssh && cat >> .ssh/authorized_keys,表示登录后在远程shell上执行的命令:(3)”$ mkdir -p .ssh”的作用是,如果用户主目录中的.ssh目录不存在,就创建一个;(4)’cat >> .ssh/authorized_keys’ < ~/.ssh/id_rsa.pub的作用是,将本地的公钥文件~/.ssh/id_rsa.pub,重定向追加到远程文件authorized_keys的末尾。
写入authorized_keys文件后,公钥登录的设置就完成了。
==============================================
关于shell远程登录的部分就写到这里,下一次接着介绍《远程操作和端口转发》。
(完)
SSH原理与运用(二):远程操作与端口转发
作者: 阮一峰
日期: 2011年12月23日
接着前一次的文章,继续介绍SSH的用法。
=======================================
SSH原理与运用(二):远程操作与端口转发
作者:阮一峰
七、远程操作
SSH不仅可以用于远程主机登录,还可以直接在远程主机上执行操作。
上一节的操作,就是一个例子:
$ ssh user@host ‘mkdir -p .ssh && cat >> .ssh/authorized_keys’ < ~/.ssh/id_rsa.pub
单引号中间的部分,表示在远程主机上执行的操作;后面的输入重定向,表示数据通过SSH传向远程主机。
这就是说,SSH可以在用户和远程主机之间,建立命令和数据的传输通道,因此很多事情都可以通过SSH来完成。
下面看几个例子。
【例1】
将$HOME/src/目录下面的所有文件,复制到远程主机的$HOME/src/目录。
$ cd && tar czv src | ssh user@host ‘tar xz’
【例2】
将远程主机$HOME/src/目录下面的所有文件,复制到用户的当前目录。
$ ssh user@host ‘tar cz src’ | tar xzv
【例3】
查看远程主机是否运行进程httpd。
$ ssh user@host ‘ps ax | grep [h]ttpd’
八、绑定本地端口
既然SSH可以传送数据,那么我们可以让那些不加密的网络连接,全部改走SSH连接,从而提高安全性。
假定我们要让8080端口的数据,都通过SSH传向远程主机,命令就这样写:
$ ssh -D 8080 user@host
SSH会建立一个socket,去监听本地的8080端口。一旦有数据传向那个端口,就自动把它转移到SSH连接上面,发往远程主机。可以想象,如果8080端口原来是一个不加密端口,现在将变成一个加密端口。
九、本地端口转发
有时,绑定本地端口还不够,还必须指定数据传送的目标主机,从而形成点对点的”端口转发”。为了区别后文的”远程端口转发”,我们把这种情况称为”本地端口转发”(Local forwarding)。
假定host1是本地主机,host2是远程主机。由于种种原因,这两台主机之间无法连通。但是,另外还有一台host3,可以同时连通前面两台主机。因此,很自然的想法就是,通过host3,将host1连上host2。
我们在host1执行下面的命令:
$ ssh -L 2121:host2:21 host3
命令中的L参数一共接受三个值,分别是”本地端口:目标主机:目标主机端口”,它们之间用冒号分隔。这条命令的意思,就是指定SSH绑定本地端口2121,然后指定host3将所有的数据,转发到目标主机host2的21端口(假定host2运行FTP,默认端口为21)。
这样一来,我们只要连接host1的2121端口,就等于连上了host2的21端口。
$ ftp localhost:2121
“本地端口转发”使得host1和host3之间仿佛形成一个数据传输的秘密隧道,因此又被称为”SSH隧道”。
下面是一个比较有趣的例子。
$ ssh -L 5900:localhost:5900 host3
它表示将本机的5900端口绑定host3的5900端口(这里的localhost指的是host3,因为目标主机是相对host3而言的)。
另一个例子是通过host3的端口转发,ssh登录host2。
$ ssh -L 9001:host2:22 host3
这时,只要ssh登录本机的9001端口,就相当于登录host2了。
$ ssh -p 9001 localhost
上面的-p参数表示指定登录端口。
十、远程端口转发
既然”本地端口转发”是指绑定本地端口的转发,那么”远程端口转发”(remote forwarding)当然是指绑定远程端口的转发。
还是接着看上面那个例子,host1与host2之间无法连通,必须借助host3转发。但是,特殊情况出现了,host3是一台内网机器,它可以连接外网的host1,但是反过来就不行,外网的host1连不上内网的host3。这时,”本地端口转发”就不能用了,怎么办?
解决办法是,既然host3可以连host1,那么就从host3上建立与host1的SSH连接,然后在host1上使用这条连接就可以了。
我们在host3执行下面的命令:
$ ssh -R 2121:host2:21 host1
R参数也是接受三个值,分别是”远程主机端口:目标主机:目标主机端口”。这条命令的意思,就是让host1监听它自己的2121端口,然后将所有数据经由host3,转发到host2的21端口。由于对于host3来说,host1是远程主机,所以这种情况就被称为”远程端口绑定”。
绑定之后,我们在host1就可以连接host2了:
$ ftp localhost:2121
这里必须指出,”远程端口转发”的前提条件是,host1和host3两台主机都有sshD和ssh客户端。
十一、SSH的其他参数
SSH还有一些别的参数,也值得介绍。
N参数,表示只连接远程主机,不打开远程shell;T参数,表示不为这个连接分配TTY。这个两个参数可以放在一起用,代表这个SSH连接只用来传数据,不执行远程操作。
$ ssh -NT -D 8080 host
f参数,表示SSH连接成功后,转入后台运行。这样一来,你就可以在不中断SSH连接的情况下,在本地shell中执行其他操作。
$ ssh -f -D 8080 host
要关闭这个后台连接,就只有用kill命令去杀掉进程。
十二、参考文献
* SSH, The Secure Shell: The Definitive Guide: 2.4. Authentication by Cryptographic Key, O’reilly
* SSH, The Secure Shell: The Definitive Guide: 9.2. Port Forwarding, O’reilly
* Shebang: Tips for Remote Unix Work (SSH, screen, and VNC)
* brihatch: SSH Host Key Protection
* brihatch: SSH User Identities
* IBM developerWorks: 实战 SSH 端口转发
* Jianing YANG:ssh隧道技术简介
* WikiBooks: Internet Technologies/SSH
* Buddhika Chamith: SSH Tunneling Explained
(完)