
保持节奏感、创造成就感
世界正变得越来越自动化。因此我认为,并非每个人都需要学习编程,而是每个人都需要学习和理解如何实现自动化。
– 《不学习编码,学习自动化》
A Compiler Writing Journey
一个英文介绍,一步步讲解如何写一个最小的 C 语言编译器。
谷歌的 Python 课程
谷歌公司开发的免费 Python 课程,内容包含 Python 语言知识、Git 和计算机自动化。
Git 从2005年4月3日开始开发,4月6日完成开发,对外宣布,4月7日上线使用。
– 维基百科
High一下!
酷 壳 – CoolShell
享受编程和技术所带来的快乐 – Coding Your Ambition
该网页提供32位浮点数和64位浮点数的二进制结构图,可以方便地设置每一个二进制位,显示对应的数字。

程序员的搜索工具,将各种网络资源汇总在一个搜索框里面。
我原本没想发明 Node.js,而是想用 Haskell 语言完成我的项目,但是失败了。我又不够聪明,没有能力改进 GHC(Haskell 语言的运行时),只好发明新的工具。
– Ryan Dahl,Node.js 的发明者
影响编程效率最大的因素,不是使用何种编程语言,而是昨晚你的睡眠是否充足。
– 《我的软件工程信念》

作者给进入这个行业的新人,提供了几点建议(上图),我觉得说得相当好。新人对这些建议肯定没有很深的体会,但是工作几年以后,再回头看,你会觉得这才是正确的路。
对我来说,英语是比 C 或 Java 更难写的语言。
– 《解释器开发》的写作感受
微软公司透露,该公司 47,000名程序员每月产生近30,000个 bug。
我原想为自己的著作起名为《算法分析》,出版商说:”那将永远卖不出去”。
– 高德纳,《计算机编程艺术》的作者
grep.app
GitHub 非官方的代码搜索引擎,支持正则搜索。
掘金资源搜索
作者对掘金社区的官方搜索不满意,于是基于官方接口,做了一个开源的自定义搜索,可以过滤出更有效的结果。
开源安卓 App
该仓库收集开源的安卓 App。

Stack Overflow 的《2020年开发者调查》显示,美国平均工资最高的程序员依次是Scala、Go 和 Objective-C。Rust 语言连续五年排名程序员最喜欢的编程语言。
NPM 现在有130万个软件包,绝大部分都不是长期维护的。即使你找到一个长期维护的软件包,它可能会有10层或更多的依赖,涉及其他数百个包,你根本不可能每一个都去验证。
– 《NPM 生态系统令人担忧》
输入要保持开放,输出要保持保守。(Be liberal in what you accept, and conservative in what you send.)
– Jon Postel 谈如何设计接口
40年前算法很重要,大部分程序员都需要懂,因为硬件差,必须靠算法保证性能。
但是今天只剩下不到1%的程序员直接跟算法打交道,其他人都使用现成的软件包,或从大公司购买算法,算法已成为一种商品,普通程序员不再需要自己生产了,也不需要有很深入的了解。
– 《算法现在是商品》

一个在线的编译器学习工具,可以显示高级语言对应的汇编代码,支持多种语言。

这是代码长度不超过1024字节的 JS 程序的比赛,2020年的结果已经公布了。第一名是一个钢琴键盘,第二名和第三名是动画渲染,第四名是一个游戏。
StackOverflow 上面高票排名的 C/C++ 问题的中文翻译。
作者介绍 LeetCode 刷题体会:”坚持在 leetcode 刷题已经有近两年了,刷着刷着就成习惯了,就像每天刷牙吃饭一样,不刷会很不自然。”
一个面向初学者的英文的简单教程,介绍数据压缩知识,了解压缩算法。
作者讨论了表示算法效率的大 O 表示法的含义,提出对于一般的应用,提高算法效率并不太重要,因为你的 n 根本不够大。
Facebook 推出的一个静态代码分析工具,可以分析 Java、C++、Objective-C、C 代码里面的错误。
虽然我很赞成从小学习计算机,但总感到有点疑惑: 编程正变得越来越容易,门槛越来越低,小朋友们真有必要牺牲周末的睡眠和体育时间,专门去学编程语言(比如 Python)吗?
上个世纪要当程序员,你必须懂汇编语言。到了如今,编程几乎已经没有门槛了,大多数人一天内就能学会,怎么写一个简单的网页 JavaScript 脚本。那么,你告诉我,未来会怎样?
再过15年或20年,等到现在的小孩进入就业市场,编程可能已经变得极其傻瓜化、智能化,也许只需要动动嘴,说出你想要什么程序,人工智能就自动生成了代码。
那时还会有程序员,但是人数应该很少,而且只负责编写底层代码,就像今天的汇编语言程序员非常少一样。因此我怀疑,孩子们没必要专门去学编程,因为未来可能根本不是今天这样编程。
大家知道吗,世界上用户最多的编程工具是什么软件?
答案是 Excel。无数财务人员、管理人员、销售人员都在用它,解决各种问题,尽管他们根本不懂编程。

我觉得,这就是未来编程工具的趋势,你不需要或者只需要懂一点点代码,就能做出软件,解决你的问题。最近正在兴起的”低代码”(low code)和”无代码”(no code)工具,正好呼应了这种趋势。未来人人都是软件工程师,都能够做出自己需要的软件,但是几乎没人知道如何编程。
美国资深程序员 Geoffrey James 在1987年写了《编程之道》(The Tao of Programming),曾一度成为美国程序员圈的文化热点,书中的佳句和故事被大家津津乐道。
我完成日常工作后,每晚还要花四五个小时在 Bootstrap 上工作。下班后,我不能和别人约晚饭,因为我觉得这会让用户失望:我不应该出去玩耍,我应该在Bootstrap上工作!
– 桑顿(Jacob Thornton),开源 CSS 框架 Bootstrap 的创造者之一,他已经在该项目上工作了九年。
自学是门手艺
One has no future if one couldn’t teach themself.
作者:李笑来
特别感谢霍炬(@virushuo)、洪强宁(@hongqn) 两位良师诤友在此书写作过程中给予我的巨大帮助!
1 | # pseudo-code of selfteaching in Python |
本书的版权协议为 CC-BY-NC-ND license。

01. 前言
想写一本关于自学能力的书,还真的不是一天两天的事,所以肯定不是心血来潮。
等我快把初稿框架搭完,跟霍炬说起我正在写的内容时,霍炬说:
你还记得吗,你第一次背个包来我家的时候,咱们聊的就是咋写本有意思的编程书……
我说:
真是呢!十三年就这么过去了……
不过,这次真的写了。写出来的其实并不是,或者说,并不仅仅是 “一本编程书”。
这本 “书” 是近些年我一直在做却没做完整的事情,讲清楚 “学习学习再学习”:
学会学习之后再去学习……
只不过,这一次我阐述地更具体 —— 不是 “学会学习”,而是 “学会自学” —— 这一点点的变化,让十多年前没写顺的东西,终于在这一次迎刃而解,自成体系。
以前,我在写作课里讲,写好的前提就是 “Narrow down your topic” —— 把话题范围缩小缩小再缩小…… 这次算是给读者一个活生生的实例了罢。
自学能力,对每个个体来说,是这个变化频率和变化幅度都在不断加大的时代里最具价值的能力。具备这个能力,不一定能直接增加一个人的幸福感(虽然实际上常常确实能),但它一定会缓解甚至消除一个人的焦虑 —— 若是在一个以肉眼可见的方式变化着的环境里生存,却心知肚明自己已然原地踏步许久,自己正在被这个时代甩在身后,谁能不焦虑呢?
实际上,这些年来我写的书,都是关于学习的,无论是《把时间当作朋友》,还是《通往财富自由之路》,甚至《韭菜的自我修养》,你去看就知道,背后都是同样的目标:学习、进步 —— 甚至进化。
这一次的《自学是门手艺》,首先,可以看作是之前内容的 “实践版”:
完成这本书的内容,起码会习得一个新技能:编程。
更为重要的是,可以把《自学是门手艺》当作之前内容的 “升级版”:
自学能力,是持续学习持续成长的发动机……
仔细观察整个人群,你就会发现一个惊人且惊悚的事实:
至少有 99% 的人终生都没有掌握自学能力!
其实这个数字根本不夸张。根据 2017 年的统计数据,从 1977 年到 2017 年,40 年间全国大学录取人数总计为 1.15 亿左右(11518.2 万),占全国人口数量的 10% 不到,另外,这其中一半以上是专科生…… 你觉得那些 4% 左右的本科毕业生中,带着自学能力走入社会的比例是多少?不夸张地讲,我觉得 1% 都是很高的比例了 —— 所以,前面提到的 99% 都是很客气的说法。
绝大多数人,终其一生都没有自学过什么。他们也不是没学过,也不是没辛苦过,但事实却是:他们在有人教、有人带、有人逼的情况下都没真学明白那些基础知识…… 更可怕的是,他们学的那些东西中,绝大多数终其一生只有一个用处:考试。于是,考试过后,那些东西就 “考过即弃” 了…… 不得不承认,应试教育的确是磨灭自学能力的最有效方法。
在随后的生活里,尽管能意识到自己应该学点什么,常有 “要是我也会这个东西就好了” 的想法,但基本上百分之百以无奈结束 —— 再也没有人教、再也没有人带、再也没有人逼…… 于是,每次 “决心重新做人” 都默默地改成 “继续做人” 而后逢年过节再次许愿 “重新做人”……
这是有趣而又尴尬的真相:
没有不学习的人。
你仔细观察就知道了,就算被你认为不学无术的人,其实也在学习,只不过,他们的选择不同,他们想学的是投机取巧,并天天琢磨怎样才能更好地投机取巧……
但他们不是最倒霉的人。最倒霉的人是那种人,也 “认真学了”,可总是最终落得个越来越焦虑的下场……
经常有一些人指责另外一些人 “贩卖焦虑” —— 根据我的观察,这种指责的肤浅在于,焦虑不是被卖方贩卖的产品,焦虑其实是买方长期自行积累的结果。
别人无法贩卖给你焦虑,是你自己焦虑 —— 是你自己在为自己不断积累越来越多的焦虑……
然而,又有谁不想解决掉焦虑呢?又有谁不想马上解决掉焦虑呢?
于是,你焦虑,你就要找解决方案。而焦虑的你找到的解决方案,就是花个钱买本书,报个班,找个老师,上个课…… 这能说是别人贩卖焦虑给你吗?
自学能力强的人,并非不花钱,甚至他们花的钱可能更多。他们也花钱买书,而且买更多的书;他们也可能花钱上课,而且要上就上最好的课、最好的班;他们更经常费尽周折找到恰当的人咨询、求教、探讨 —— 所以,事实上,他们更可能花了更多的钱……
但自学能力强的人不焦虑,起码他们不会因为学习以及学习过程而焦虑 —— 这是重大差别。
而焦虑的大多数,并不是因为别人贩卖焦虑给他们,他们才 “拥有” 那些焦虑 —— 他们一直在焦虑,并且越来越焦虑……
为什么呢?总也学不会、学不好,换做是你,你不焦虑吗?!
生活质量就是这样一点一点被消磨掉的 —— 最消耗生活质量的东西,就是焦虑。
我相信,若是《自学是门手艺》这本书真的有用,它的重要用处之一就是能够缓解你的焦虑,让你明白,首先焦虑没用,其次,有办法也有途径让你摆脱过往一事无成的状况,逐步产生积累,并且逐步体会到那积累的作用,甚至最后还能感觉到更多积累带来的加速度…… 到那时候,焦虑就是 “别人的事情” 了。
自学没有什么 “秘诀”。它是一门手艺,并且,严格意义上来讲,它只是一门手艺。
手艺的特点就是无需天分。手艺的特点就是熟练程度决定一切。从这一点上来看,自学这门手艺和擀饺子皮没什么区别 —— 就那点事,刚开始谁都笨手笨脚,但熟练了之后,就那么回事…… 而已。
做什么事都有技巧,这不可否认。
自学当然也有技巧…… 不过,请做好思想准备:
这儿的空间,没什么新鲜……
—— 这是崔健一首歌里的歌词片段,但放在这里竟然非常恰当到位。
一切与自学相关的技巧都是老生常谈。
中国人说,熟能生巧;老外说,Practice makes perfect —— 你看,与自学相关的技巧,干脆不分国界……
—— 因为这事人类从起点开始就没变过 —— 每代人都有足够多的人在自学这件事上挣扎…… 有成的有不成的;成的之中有大成有小成…… 可有一件事同样不变:留下的文字、留下的信息,都是大成或者小成之人留下的,不成的人不声不响就销声匿迹。
并且,从各国历史上来看,自学技巧这个话题从未涉及到政治,无论是在东方还是西方都是如此。结果就是,在自学能力这个小领域中,留下并流传下来的信息,几乎从未被审查,从未被摧毁,从未被侵犯,从未被扭曲 —— 真的是个特别罕见的 “纯净的领域” —— 这真的是整个人类不可想像之意外好运。
这就是为什么一切的自学技巧到最后肯定是老生常谈的原因。
大部分年轻人讨厌老生常谈。
但这还真的是被误导的结果。年轻人被什么误导了呢?
每一代人都是新鲜出生,每一代人出生时都在同一水准…… 随着时间的推移,总是庸者占绝大多数,这个 “绝大多数” 不是 51%,不是 70%,而是 99%!—— 年轻人吃亏就吃在没把这个现象考虑进来。
也就是说,虽然有用的道理在不断地传播,可终究还是 99% 的人做不到做不好,于是:
讲大道理的更可能是庸者、失败者,而不是成功者。
人类有很多天赋。就好像我反复提到的那样,“就算不懂也会用” 是人类的特长。同样的道理,人类在这方面同样擅长:
无论自己什么样,在 “判断别人到底是不是真的很成功” 上,基本上有 99% 的把握……
所以,十岁不到的时候,绝大多数小朋友就 “看穿” 了父母,后来再 “看穿” 了老师…… 发现他们整天说的都是他们自己做不到的事情…… 于是误以为自己 “看穿” 了整个世界。
那时候小朋友们还没学、或者没学好概率这个重要知识,于是,他们并不知道那只不过是 99% 的情况,而且更不知道 “因素的重要性与它所占的比例常常全无正相关”,所以当然不知道那自己尚未见到的 1% 才可能是最重要的……
于是,99% 的小朋友们一不小心就把自己 “搭了进去”:
不仅讨厌老生常谈,而且偏要对着干,干着干着就把自己变成了另外一个属于那 99% 的另外一个老生……
这是 99% 的人终其一生的生动写照。
做 1% 很难吗?真的很简单,有时仅仅一条就可能奏效:
在自学这件事上,重视一切老生常谈……
很难吗?不难,只不过是一个 “开关” 而已。
当我动手写这本 “书” 的时候,是 47 岁那年(2019)的春节前 —— 显然,这个时候我也早就是一位 “老生” 了…… 并且,这些道理我已经前后讲了二十年!算是 “常谈” 甚至 “长谈” 了罢……
开始在新东方教书那年,我 28 岁;用之前那一点三脚猫的编程能力辅助着去写《TOEFL 核心词汇 21 天突破》是 2003 年;后来写《把时间当作朋友》是 2007 年,这本书的印刷版出版发行是在 2009 年;再后来陆续写了很多内容,包括没有纸质版发行只有在线版的《人人都能用英语》(2013);以及因为在罗振宇的得到 App 上开专栏,把之前写过的《学习学习再学习》重构且扩充而出版的《通往财富自由之路》(2017);甚至连《韭菜的自我修养》(2018)都是讲思考、学习、和认知升级的……
说来说去,就那些事 —— 没什么新鲜。
这中间也有很多写了却没写完,或者因为写得自己不满意扔在柜子里的东西,比如《人人都是工程师》(2016)—— 哈!我就是这么坚韧,有了目标就会死不放弃…… 3 年后的今天,我终于用那个时候完全想不到的方式完成了当时的目标,并且,做到了很多 3 年前自己都完全想象不到的事情。
在写当前这本《自学是门手艺》的过程中,我从一开始就干脆没想给读者带来什么 “新鲜” 的或者 “前所未见” 的自学技巧 —— 因为真的就没有,根本就没有什么新鲜的自学技巧…… 没有,真的没有 —— 至少,我自己这么久了还是真的没见识过。
然而,我算是最终能做到的人。知道、得到、做到之间,均各不相同。
二十年前,在拥挤的课堂里坐在台下听我讲课的小朋友们,绝大多数在当时应该没有想到他们遇到了这样一个人 —— 二十年后,刚认识我的人也不会自动知道我是这样的人。
但是,这些年里,看到我在一点一点进步、从未原地踏步的人很多很多…… 我猜,所谓的 “榜样”,也不过如此了罢。
不夸张地讲,这可能是当前世界上最硬核的鸡汤书了 —— 因为,虽然它就是鸡汤(李笑来自认就是个鸡汤作者),但它不是 “只是拿话糊弄你” 那种,也不是 “只不过是善意的鼓励” 那种,它是那种 “教会你人生最重要的技能” 的鸡汤,并且还不仅仅只有一种技能,起码两个:“自学能力” 和 “编程能力”…… 而这两个能力中的无论哪一种,都是能确定地提高读者未来收入的技能,对,就是 100% 地确定 —— 有个会计专业的人求职的时候说 “我还会编程” 且还能拿出作品,你看看他可不可能找不到工作?你看看他是不是能薪水更高?
#! —— 这是个程序员能看懂的梗。
关键在于,这个老生不是说说而已的老生,他是能够做到的人:
- 一个末流大学的会计专业毕业的人不得已去做了销售;
- 这个销售后来去国内最大的课外辅导机构当了 7 年 TOEFL/GRE/GMAT 老师;
- 这个英语老师后来同时成了很多畅销书、长销书的作者;
- 这个作者后来居然成了著名天使投资人;
- 这个投资人后来竟然写了本关于编程入门的书籍;
- 这本 “书” 最终竟然还是一个完整的产品,不仅仅是 “一本书”……
然而呢?
—— 然而,即便是这样的老生,也讲不出什么新鲜道理。
因为啊,历史上留下来的所有关于自学的技巧,都是人类史上最聪明的人留下来的 —— 你我这样的人,照做就可以了…… 现在你明白怎么回事了吧?
记住罢 ——
千万不要一不小心就把自己搭进去……
李笑来
初稿完成于 2019 年 2 月 27 日
02. 如何证明你真的读过这本书?
積ん読
日语里有个很好玩的词,“積ん読”(tsundoku):
指那些买回来堆在那里还没读过的(甚至后来干脆不看了的)书……
细想想,每个人都有很多很多 “積ん読”。小时候我们拿回家的教科书中就有相当一部分,其实就是 “積ん読”,虽然那时候掏钱买书的是父母,不仔细看、或者干脆不看的时候,也知道自己在偷懒…… 再后来就是 “主动犯罪” 了 —— 比如,很多人买到手里的英语词汇书是根本就没有翻到过第二个列表的,乃至于过去我常常开玩笑说,中国学生都认识一个单词,abandon,不是吗?这个单词是很多很多人 “决心重新做人” 而后 “就这样罢” 的铁板钉钉的见证者。
在没有电子书的时代,印刷版书籍多少还有一点 “装饰品” 功用,可是到了电子书时代,谁知道你的设备里有多少付费书籍呢?攒下那么多,其实并没有炫耀的地方,给谁看呢?据说,Kindle 的后台数据里可以看到清楚的 “打开率”,大抵上也是在 ¼ ~ ⅓ 之间,也就是说,差不多有 ⅔ ~ ¾ 的电子书籍被购买下载之后,从来就没有被打开过。
如此看来,付费之后并不阅读,只能欺骗一个对象了:自己。跟心理学家们之前想象的不同,我认为人们通常是不会欺骗自己的,至少很难 “故意欺骗自己”。所以,对于 “买了之后坚决不读” 这个现象,我不认为 “给自己虚妄的满足感” 是最好的解释。
更朴素一点,更接近真相的解释是:
那百分之七八十的人,其实是想着给自己一个希望……
—— 等我有空了一定看。嗯。
说来好笑,其实每个人共同拥有的目标之一是这样的:
成为前百分之二十的少数人……
然而,PK 掉百分之七八十的人的方法真的很简单很简单啊:
把买来的书都真真切切地认真读过就可以了。
这实在是太简单了罢?!可是…… 我知道你刚刚那个没出息的闪念:
那我少买书甚至不买书不就可以了吗?
你自己都知道这是荒谬的,却忍不住为你的小聪明得意 —— 其实吧,幸亏有你们在,否则我们怎么混进前百分之二十呢?
PoW
比特币这个地球上第一个真正被证明为可行的区块链应用中有一个特别重要的概念,叫做 “工作证明”(Proof of Work)—— 你干活了就是干活了,你没干活就是没干活,你的工作是可被证明的……
借用这个思路,我设计了个方法,让你有办法证明自己就是看过这本书,就是读完了这本书 —— 你能向自己也向别人证明自己曾经的工作…… 是不是挺好?
证明的方法是使用 github.com 这个网站以及版本控制工具 git。
具体步骤
请按照以下步骤操作:
- 注册 github.com 帐号 —— 无论如何你都必须有 github 账户;
- 使用浏览器访问 https://github.com/selfteaching/the-craft-of-selfteaching;
- 在页面右上部找到 “Fork” 按钮,将该仓库 Fork 到你自己的账户中;
- 使用
git clone命令或者使用 Desktop for Github 将 the craft of selfteaching 这个你 Fork 过来的仓库克隆到本地;- 按照 Jupyterlab 的安装与配置 的说明在本地搭建好 Jupyterlab —— 如果在 Jupyterlab 中浏览本书的话,其中的所有代码都是可以 “当场执行” 的,并且,你还可以直接改着玩……
- 在阅读过程中,可以不断通过修改文章中的代码作为练习 —— 这样做的结果就是已阅读过的文件会发生变化…… 每读完一章,甚至时时刻刻,你都可以通过
git commit命令向你自己 Fork 过来的仓库提交变化 —— 这就是你的阅读工作证明;- 仓库里有一个目录,
my-notes,你可以把你在学习过程中写的笔记放在那里;- 仓库里还有另外一个目录,
from-readers;那是用来收集读者反馈的 —— 将来你可以写一篇《我的自学之路》,放在这个目录里,单独创建一个分支,而后提交pull request,接受其他读者投票,若是达到一定的赞同率,那么你的文章就会被收录到主仓库中被更多人看到,激励更多的人像你一样走上自学之路……
当然,为了这么做,你还要多学一样反正你早晚都必须学会的东西,Git —— 请参阅附录《Git 入门》。
时间就是这样,我们没办法糊弄它。而有了 git 这样的工具之后,我们在什么时候做了什么样的工作,是很容易证明的 —— 这对我们来说真是天大的好事。
如何使用 Pull Request 为这本书校对
另外,在你阅读的过程中,发现有错别字啊、代码错误啊,甚至有 “更好的表述” 等等,都可以通过 pull request 来帮我改进 —— 这也是一种 “工作证明”。
(1) 使用浏览器访问 https://github.com/selfteaching/the-craft-of-selfteaching
(2) 点击右上角的 “Fork 按钮”,将该仓库 Fork 到你的 Github 账户中

(3) 创建一个新分支,可以取名为 from-<your_username>,比如,by git.basic.tutorial;之后点击 Create Branch 建立新分支。
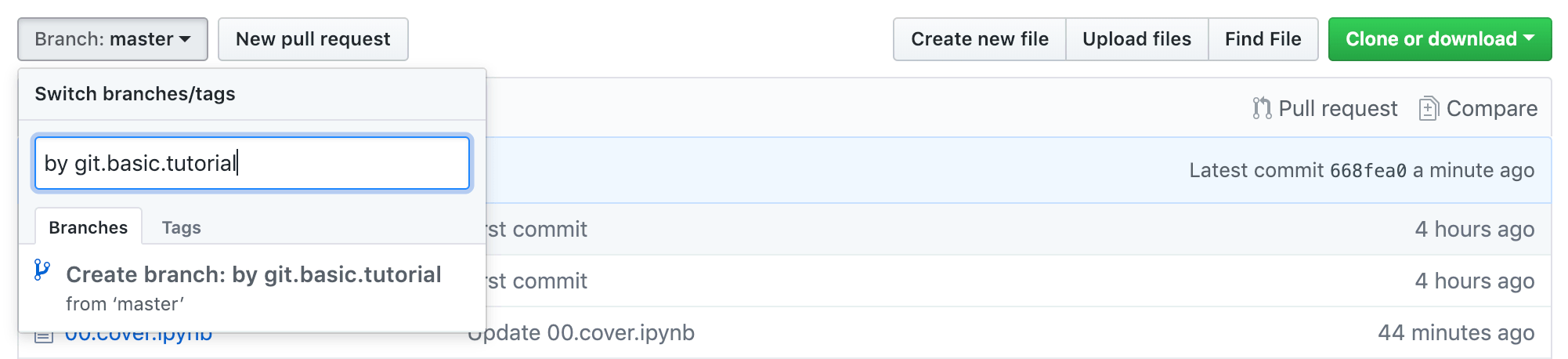
(4) 在新分支下进行修改某个文件,而后提交 —— 提交前不要嫌麻烦,一定要在 Comment 中写清楚修改说明:

以上示例图片中是修改了 README.md 文件 —— 事实上,你应该提交的是的确有必要的校对。
另外,请注意:在创建分支之前,要将你的 Fork 更新到最新版。具体操作方法见下一节《如何在 Github 网站上将自己的 Fork 与原仓库同步》。
(5) 在页面顶部选择 Pull request 标签:
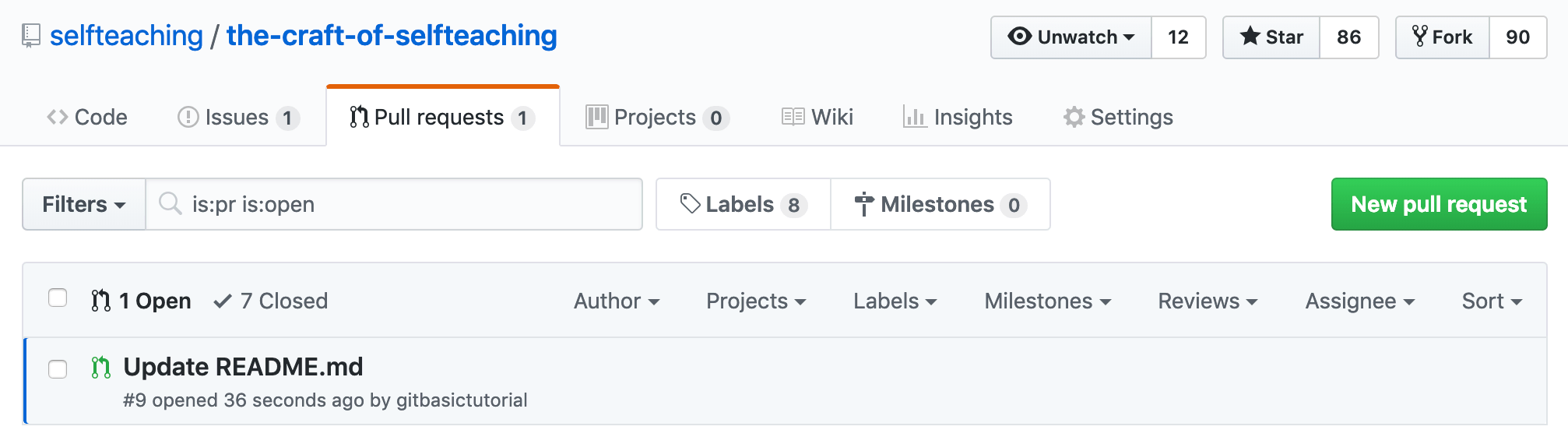
而后点击 Compare & pull request 按钮 —— 如果看不到这个按钮,那就点击下面刚刚修改文件的链接,如上图中的 “Update README.md”(这是你刚刚提交修改时所填写的标题)。
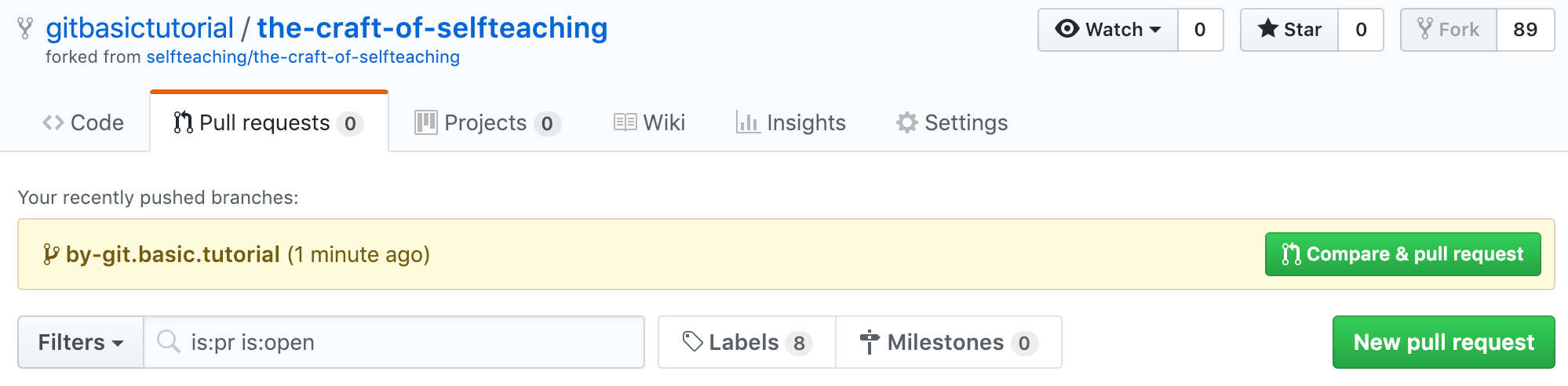
确认无误之后,点击 Create pull request 按钮。
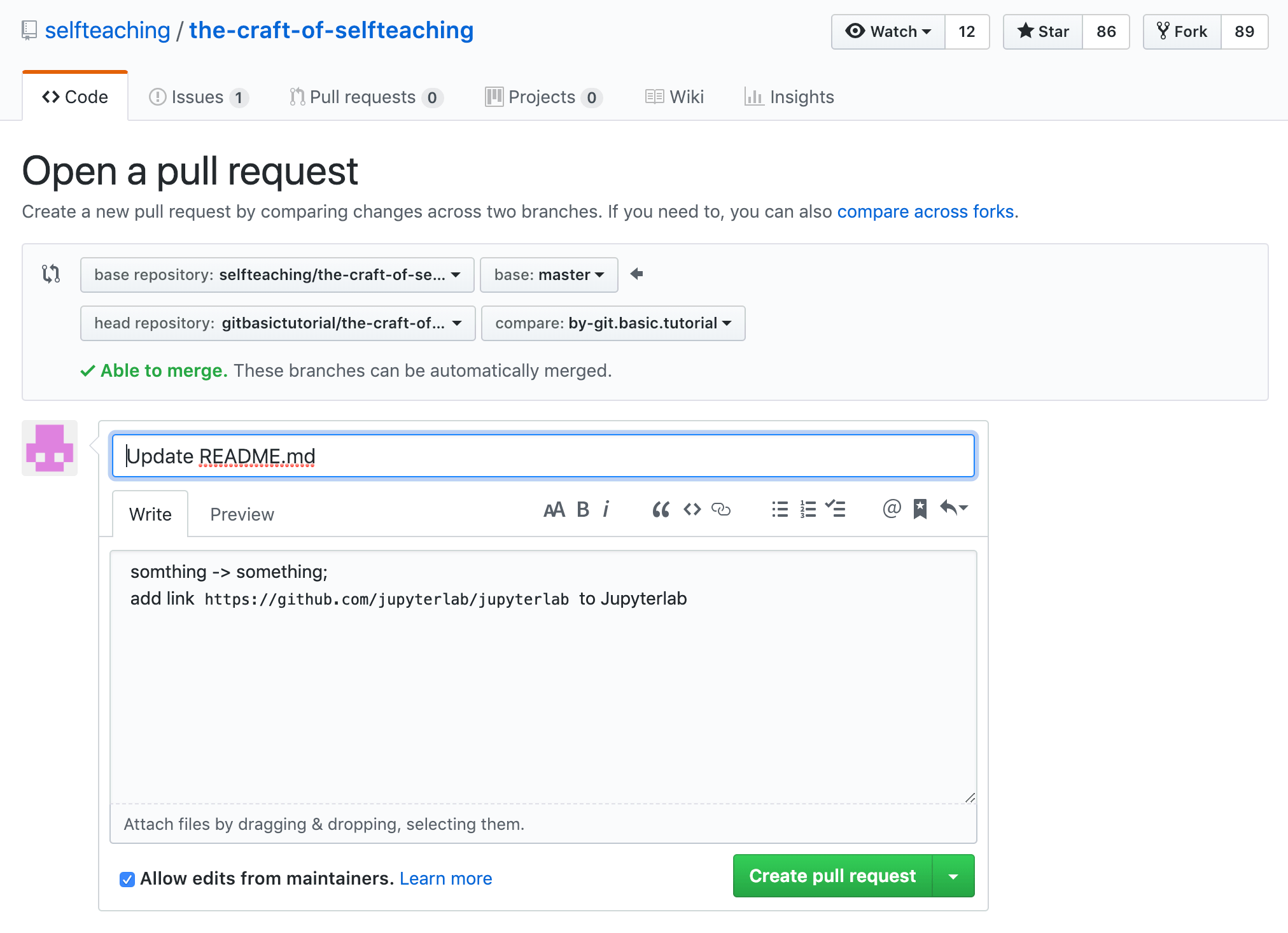
(6) 随后,Github 用户 @xiaolai —— 就是我,即,the-craft-of-selfteaching 这个仓库的所有者,会被通知有人提交了 Pull request,我会看到:
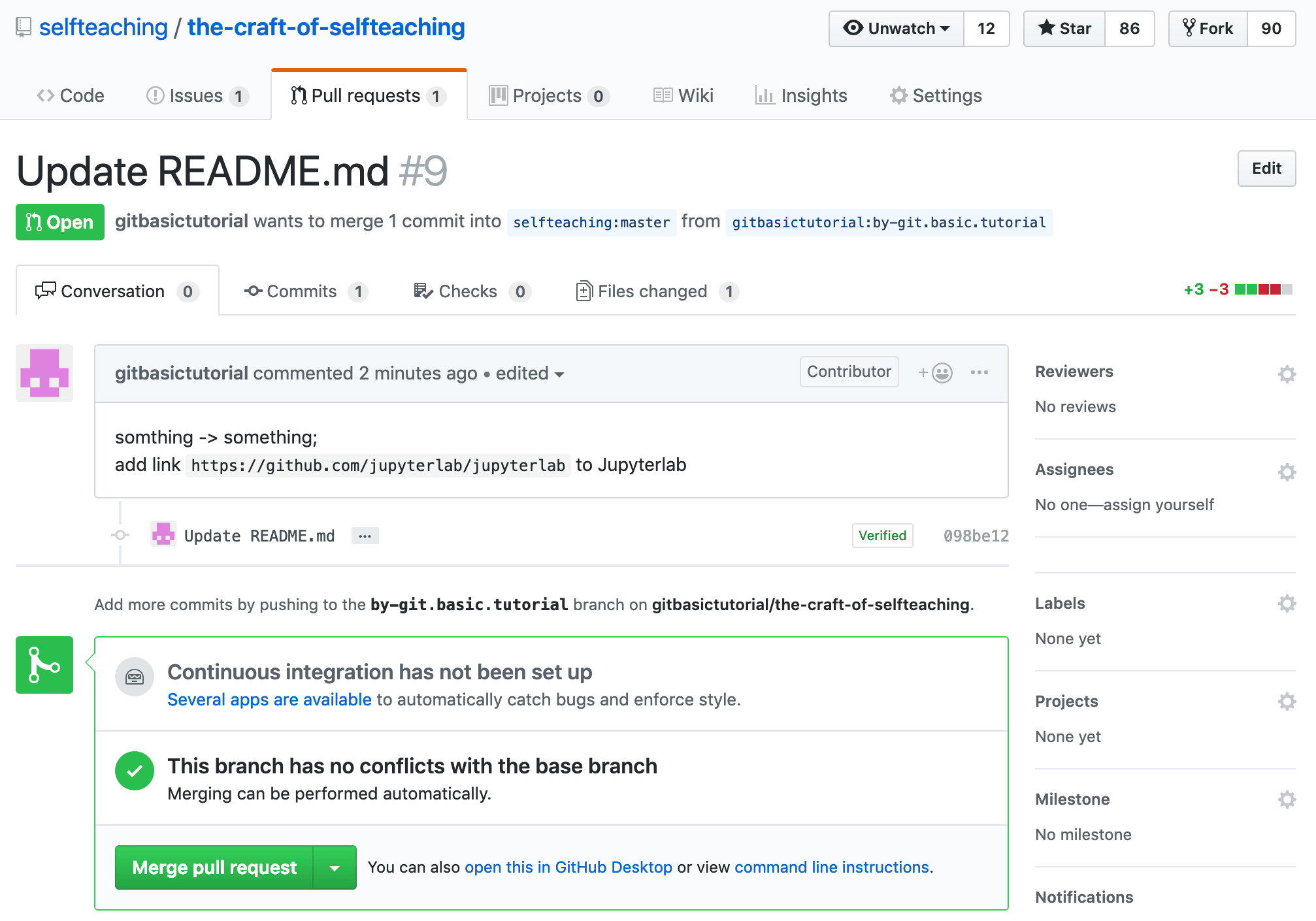
在我确认这个 Pull request 修改是正确的、可接受的之后,我就会按 Merge pull request 按钮 —— 如此这般,一个修正就由你我共同完成了。
注意
提交 Pull request 的时候,最佳策略如下:
- 提交 Pull request 之前,必须先将你的 Fork 的 master 与原仓库同步到最新;
- 从 master 创建 新的 branch 进行增补、修改等操作;
- 尽量每次只提交一个小修改;
- 提交时尽量简短且清楚地说明修改原因;
- 耐心等待回复。
当自己的 Fork 过来的仓库已经被你在本地 “玩残” 了的时候,它千万不能被当作用来提交 Pull request 的版本。自己本地怎么玩都无所谓,但需要向别人提交 Pull request 的时候,必须重新弄一个当前最新版本到本地,而后再在其基础上修改。
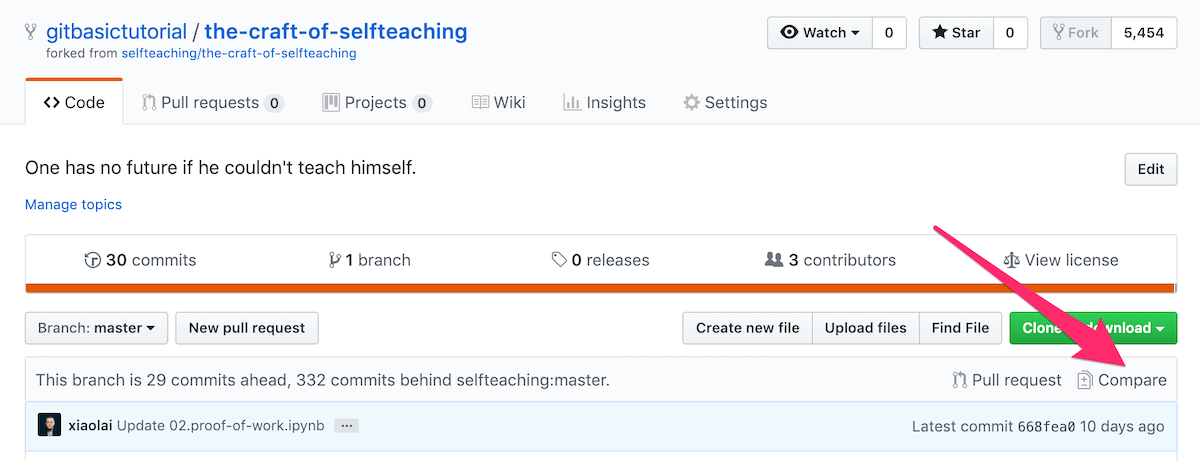
如何在 Github 网站上将自己的 Fork 与原仓库同步
(1) 在你的 Fork 页面中如下图所示,点击 Compare 链接:
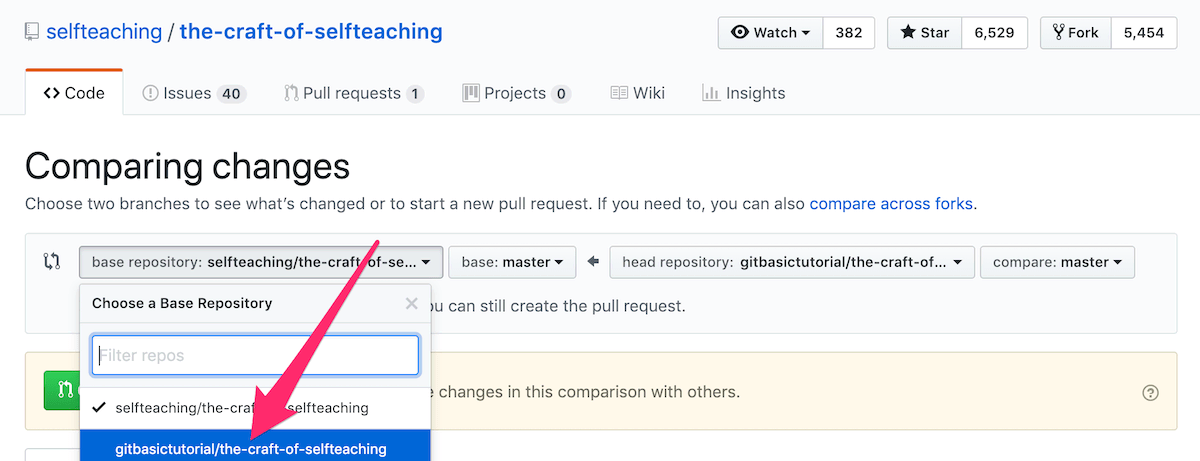
(2) 将 base repository 更改成当前自己的 Fork,在图示中即为 gitbasictutorial/the-craft-of-selfteaching:
(3) 这时候,页面会显示 There isn't anything to compare.,因为你在比较 “自己” 和 “自己”。点击 compare across forks 链接:
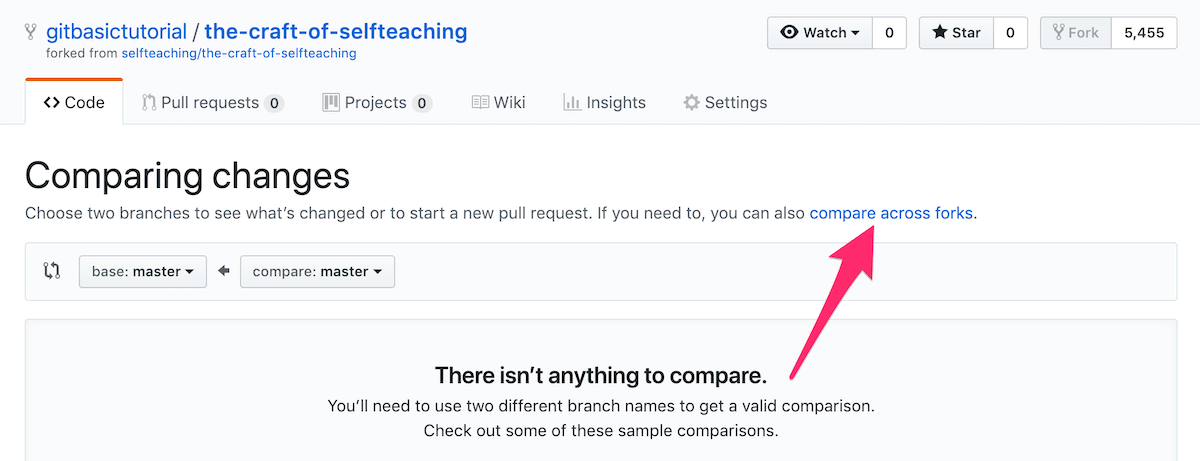
(4) 将 head repository 更改成 Upstream Repository(即,上游仓库),在图示中即为 selfteaching/the-craft-of-selfteaching:
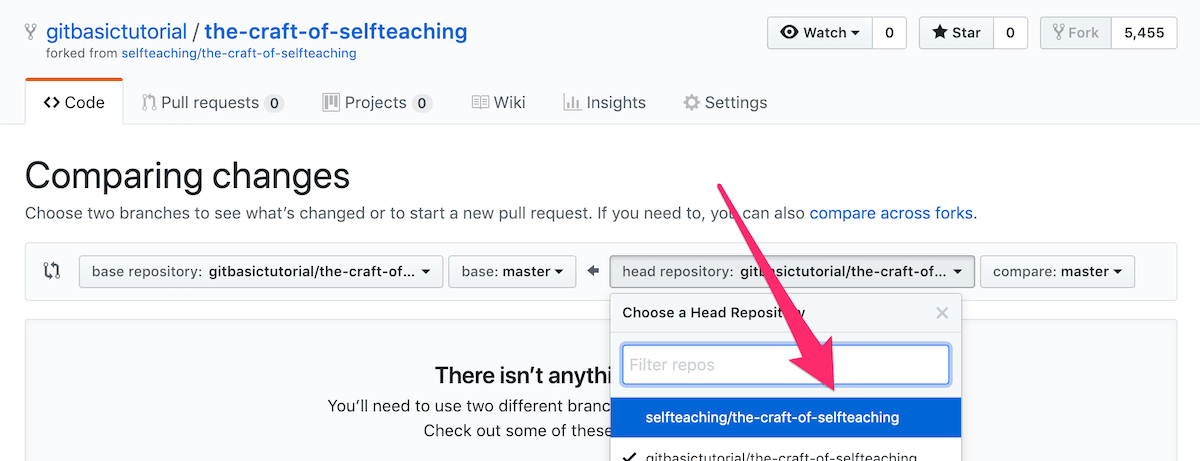
(5) 稍等片刻,你会看到比较结果;而后你可以创建一个 Pull request —— 这是一个由你自己向你自己的 Fork 仓库提交的 Pull request:
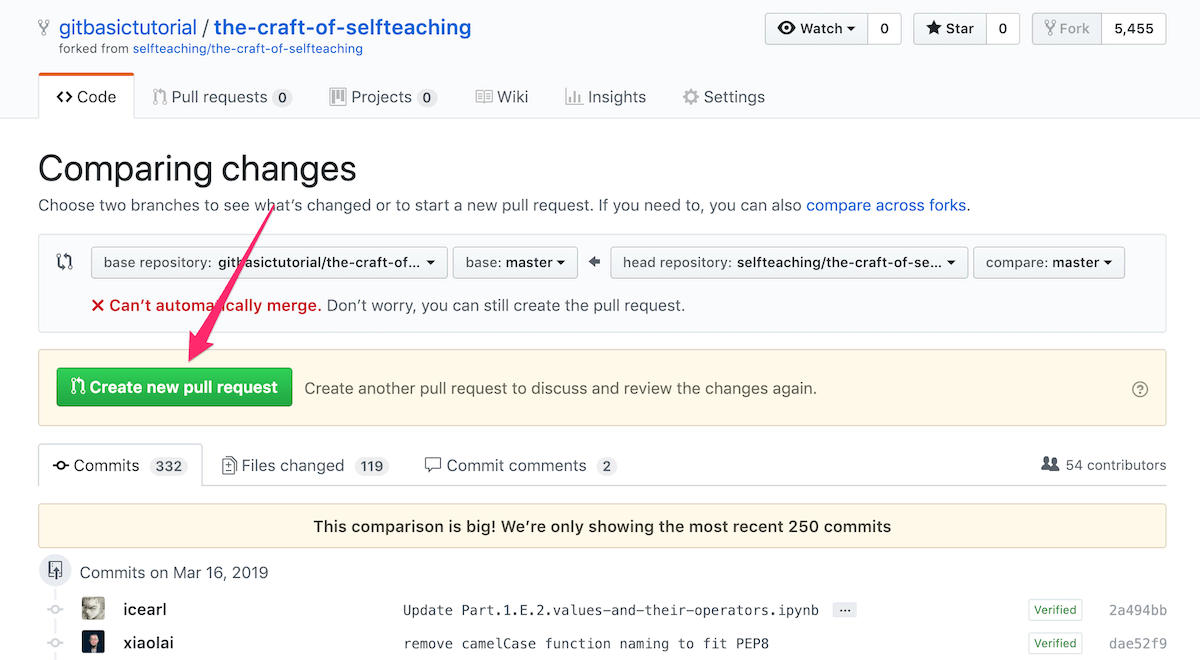
(6) 而后你在 Pull requests 标签页里会看到你刚刚提交的 Pull request:
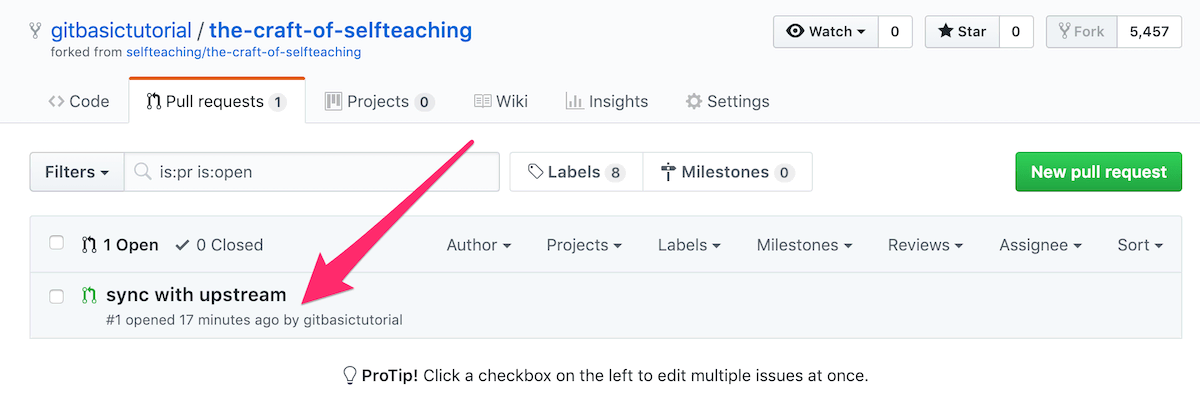
(7) 同意并合并之后的结果是,你的 Fork 与上游仓库同步完成了:
当然,有时会出现一些你无法解决的问题,那么,还有一个最后的方法:
将你的 Fork 删除,而后重新到 https://github.com/selfteaching/the-craft-of-selfteaching 页面按一次
Fork按钮……
如何使用 github 记录自己的学习过程
你可以在本地建立一个分支(branch),例如,取名为 study:
1 | git branch study |
如此这般之后,你在本地工作目录中所做的任何修改,都可以提交到 study 这个分支之中。
你每次在 Jupyterlab 中浏览 ipynb 文件,按 ^ + Enter 执行 code cell 中的代码的时候,该文件都会发生一些变化;你也可以随意修改文件中的任何地方,比如,添加一个 code cell,将某段代码从头至尾 “敲” 一遍;也可以修改某个 code cell 中的代码看看执行结果有什么不同;还可以添加或者修改任何 markdown cell —— 就当自己做笔记了……
总而言之,当你阅读完某一章节并如上所说那样做了一些改动之后,那个 ipynb 文件就发生了一些变化。于是,你就可以执行以下命令:
1 | git add . |
如此这般,在 study 这个分支中就记录着你的学习轨迹。
当然,如果在这过程中,你发现本书自身有需要校对的地方,那么,你需要切换到 master 分支,执行以下命令:
1 | git checkout master |
而后再修改,进而按照上一节的方法提交 Pull request。
未来,在 https://github.com/selfteaching 下我会专门设置一个 repo,用来自动扫描 github 上本书的学习记录 —— 这种记录在过往的书籍当中是不可能存在的,然而,现在却可以了。在我看来,将来这种记录的作用甚至有可能比 “学历” 还要重要。
为什么一定要掌握自学能力?
一句话解释清楚:
没有自学能力的人没有未来。
有两个因素需要深入考虑:
- 未来的日子还很长
- 这世界进步得太快
我有个观察:
很多人都会不由自主地去复刻父母的人生时刻表。
比如,你也可能观察到了,父母晚婚的人自己晚婚的概率更高,父母晚育的人自己晚育的概率也更高……
再比如,绝大多数人的内心深处,会不由自主地因为自己的父母在五十五岁的时候退休了,所以就默认自己也会在五十五岁前后退休…… 于是,到了四十岁前后的时候就开始认真考虑退休,在不知不觉中就彻底丧失了斗志,早早就活得跟已经老了很多岁似的。
但是,这很危险,因为很多人完全没有意识到自己所面临的人生,与父母所面临的人生可能完全不一样 —— 各个方面都不一样。单举一个方面的例子,也是比较容易令人震惊的方面:
全球范围内都一样,在过去的五十年里,人们的平均寿命预期增长得非常惊人……
拿中国地区做例子,根据世界银行的数据统计,中国人在出生时的寿命预期,从 1960 年的 43.73 岁,增长到了 2016 年的 76.25 岁,56 年间的增幅竟然有 74.39% 之多!
1 | import matplotlib.pyplot as plt |
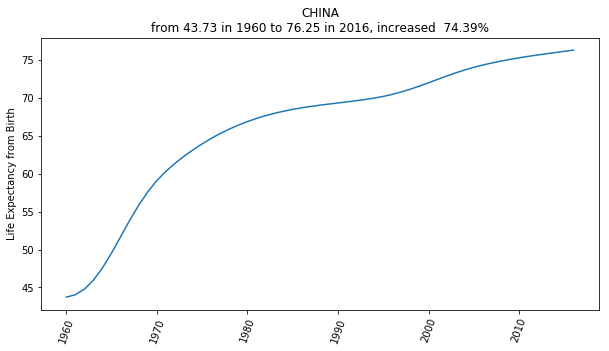
如此发展下去,虽然人类不大可能永生不死,但平均寿命依然在持续延长是个不争的事实。与上一代不同,现在的千禧一代,需要面对的是百岁人生 —— 毫无疑问,不容置疑。
这么长的人生,比默认的想象中可能要多出近一倍的人生,再叠加上另外一个因素 —— 这是个变化越来越快的世界 —— 会是什么样子?
我是 1972 年出生的。从交通工具来看,我经历过出门只能靠步行,大街上都是牛车马车,机动车顶多见过拖拉机,到有自行车,到见过摩托车,到坐小汽车,到自己开车,到开有自动辅助驾驶功能的电动车…… 从阅读来看,我经历过只有新华书店,到有网络上的文字,到可以在当当上在线买到纸质书,到有了国际信用卡后可以在 Amazon 上第一时间阅读新书的电子版、听它的有声版,到现在可以很方便地获取最新知识的互动版,并直接参与讨论…… 从技能上来看,我经历过认为不识字是文盲,到不懂英语是文盲,到不懂计算机是文盲,到现在,不懂数据分析的基本与文盲无异……
我也见识过很多当年很有用很赚钱很令人羡慕的技能 “突然” 变成几乎毫无价值的东西,最明显的例子是驾驶。也就是二十多年前,的哥还是很多人羡慕的职业呢!我本科的时候学的是会计专业,那时候我们还要专门练习打算盘呢!三十年之后的今天,就算有人打算盘打得再快,有什么具体用处嘛?我上中学的时候,有个人靠出版字帖赚了大钱 —— 那时候据说只要写字漂亮就能找到好工作;可今天,写字漂亮与否还是决定工作好坏的决定性因素吗?打印机很便宜啊!
这两个因素叠加在一起的结果就是,这世界对很多人来说,其实是越来越残忍的。
我见过太多的同龄人,早早就停止了进步,早早就被时代甩在身后,早早就因此茫然不知所措 —— 早早晚晚,你也会遇到越来越多这样的人。他们的共同特征只有一个:
没有自学能力
有一个统计指数,叫做人类发展指数(Human Development Index),它的曲线画出来,怎么看都有即将成为指数级上升的趋势。
1 | import matplotlib.pyplot as plt |
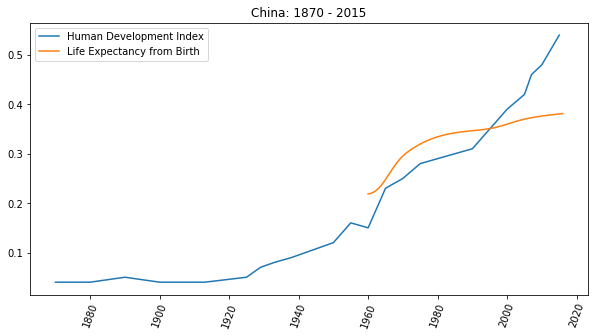
社会发展越来越快,你要面对的人生越来越长,在那一段与你的直觉猜想并不相同的漫漫人生路上,你居然没有磨练过自学能力,竟然只能眼睁睁地看着自己被甩下且无能为力,难道接下来要在那么长的时间里 “苦中作乐” 吗?
没有未来的日子,怎么过呢?
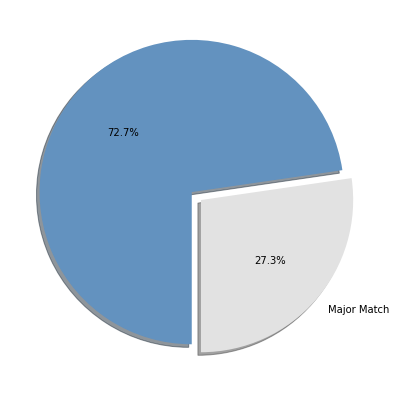
我本科学的是会计,研究生跑到国外读宏观经济学没读完,跑回国内做计算机硬件批发,再后来去新东方应聘讲授托福课程,离开新东方之后创业,再后来做投资,这期间不断地写书…… 可事实上,我的经历在这个时代并不特殊。有多少人在后来的职业生涯中所做的事情与当年大学里所学的专业相符呢?
纽约联邦储蓄银行在 2012 年做过一个调查,发现人们的职业与自己大学所学专业相符的比例连 30% 都不到。而且,我猜,这个比例会持续下降的 —— 因为这世界变化快,因为大多数教育机构与世界发展脱钩的程度只能越来越严重……
1 | import matplotlib.pyplot as plt |
绝大多数人终生都饱受时间幻觉的拖累。
小时候觉得时间太长,那是幻觉;长大了觉得时间越来越快,那还是幻觉 —— 时间从来都是匀速的。最大的幻觉在于,总是以为 “时间不够了” —— 这个幻觉最坑人。许多年前,有一次我开导我老婆。她说,“啊?得学五年才行啊?!太长了!” 我说,
“你回头看看呗,想想呗,五年前你在做什么?是不是回头一看的时候,五年前就好像是昨天?道理是一样的,五年之后的某一天你回头想今天,也是 ‘一转眼五年就过去’ 了…… 只不过,你今天觉得需要时间太多,所以不肯学 —— 但是,不管你学还是不学,五年还是会 ‘一转眼就过去’ 的…… 到时候再回头,想起这事的时候,没学的你,一定会后悔 —— 事实上,你已经有很多次后悔过 ‘之前要是学了就好了’,不是吗?”
现在回头看,开导是非常成功的。十多年后的今天,她已经真的可以被称为 “自学专家” —— 各种运动在她那儿都不是事。健身,可以拿个北京市亚军登上健与美杂志封面;羽毛球,可以参加专业比赛;潜水,潜遍全球所有潜水胜地,到最后拿到的各种教练证比她遇到的各地教练的都多、更高级;帆船,可以组队横跨大西洋;爬山,登上喜马拉雅……
都说,人要有一技之长。那这一技究竟应该是什么呢?
自学能力是唯一值得被不断磨练的长技。
磨练出自学能力的好处在于,无论这世界需要我们学什么的时候,我们都可以主动去学,并且还是马上开始 —— 不需要等别人教、等别人带。
哪怕有很强的自学能力的意思也并不是说,什么都能马上学会、什么都能马上学好,到最后无所不精无所不通…… 因为这里有个时间问题。无论学什么,都需要耗费时间和精力,与此同时更难的事情在于不断填补耐心以防它过早耗尽。另外,在极端的情况下,多少也面临天分问题。比如身高可能影响打篮球的表现,比如长相可能影响表演的效果,比如唱歌跑调貌似是很难修复的,比如有些人的粗心大意其实是基因决定的,等等。不过,以我的观察,无论是什么,哪怕只是学会一点点,都比不会强。哪怕只是中等水平,就足够应付生活、工作、养家糊口的需求。
我在大学里学的是会计专业,毕业后找不到对口工作,只好去做销售 —— 没人教啊!怎么办?自学。也有自学不怎么样的时候,比如当年研究生课程我就读不完。后来想去新东方教书 —— 因为听说那里赚钱多 —— 可英语不怎么样啊!怎么办?自学。离开新东方去创业,时代早就变了,怎么办?自学,学的不怎么样,怎么办?硬挺。虽然创业这事后来也没怎么大成,但竟然在投资领域开花结果 —— 可赚了钱就一切平安如意了吗?并不是,要面对之前从来没可能遇到的一些险恶与困境,怎么办?自学。除了困境之外,更痛苦的发现在于对投资这件事来说,并没有受过任何有意义的训练,怎么办?自学。觉得自己理解的差不多了,一出手就失败,怎么办?接着学。
我出身一般,父母是穷教师。出生在边疆小镇,儿时受到的教育也一般,也是太淘气 —— 后来也没考上什么好大学。说实话,我自认天资也一般,我就是那种被基因决定了经常马虎大意的人。岁数都这么大了,情商也都不是一般的差 —— 还是跟年轻的时候一样,经常莫名其妙就把什么人给得罪透了……
但我过得一直不算差。
靠什么呢?人么,一个都靠不上。到最后,我觉得只有一样东西真正可靠 —— 自学能力。于是,经年累月,我磨练出了一套属于我自己的本领:只要我觉得有必要,我什么都肯学,学什么都能学会到够用的程度…… 编程,我不是靠上课学会的;英语,不是哪个老师教我的;写作,也不是谁能教会我的;教书,没有上过师范课程;投资,更没人能教我 —— 我猜,也没人愿意教我…… 自己用的东西自己琢磨,挺好。
关键在于,自学这事并不难,也不复杂,挺简单的,因为它所需要的一切都很朴素。
于是,从某个层面上来看,我每天都过的很开心。为什么?因为我有未来。凭什么那么确信?因为我知道我自己有自学能力。
—— 我希望你也有。
准确地讲,希望你有个更好的未来。
而现在我猜,此刻,你心中也是默默如此作想的罢。
为什么把编程当作自学的入口?
很多人误以为 “编程” 是很难的事情。
…… 实则不然 —— 这恰恰是我们选择 “编程” 作为自学的第一个 “执行项目” 的原因。
一本关于自学能力的书,若是真的能够起到作用,那么它就必须让读者在读之前和读之后不一样 —— 比如,之前可能没有自学能力,或者自学能力很差,之后就有了一定的自学能力……
然而,这很难。不但对读者来说很难,对作者来说更难 —— 我当过那么多年被学生高度评价的老师,出版过若干本畅销且长销的书籍,所以更是清楚地知道例子的重要性。
道理当然很重要;可是,在传递道理的时候,例子相对来看好像更重要。
同样的道理,例子不准,人就可能会理解错;例子不精彩,人就可能听不进去;例子居然可以令人震惊,那就可以做到让听众、让读者 “永生不忘”。
许多年前,有位后来在美国读书已经博士毕业了的学生来信,大意是说:
好多年前,我在新东方上课,听您讲,人学习就好像是动物进化一样…… 很多人很早就开始停止了进化,本质上跟猴子没啥区别。
那段类比好长,我记不太清楚细节了…… 可是,当时我是出了一身汗的,因为我忽然觉得自己是一只猴子。可是,突然之间,我不想继续做猴子,更不想一直做猴子!
从那之后,我好像变了一个人似的…… 现在我已经博士毕业了,觉得应该写封信告诉您,我不再是猴子了,最起码是大猩猩,而且我保证,我会一直进化。
……
所以啊,在我看来,写书讲课之前,最重要的工作,也是做得最多的事情,其实就是 “找到好例子” —— 那即意味着说,先要找到很多很多恰当合适的例子,而后再通过反复比较试验,挑出那个效果最好的例子。了解了这一点,将来你准备任何演讲,都会不由自主地多花一点时间在这方面,效果肯定比 “把幻灯片做得更花哨一些” 要好太多了罢?
后来,我选中了一个例子:“自学编程” —— “尽量只通过阅读学会编程”。
(一)
选择它的理由,首先就在于:
事实证明,它就是无论是谁都能学会的 —— 千万别不信。
它老少皆宜 —— 也就是说,“只要你愿意”,根本没有年龄差异。十二岁的孩子可以学;十八岁的大学生可以学;在职工作人员可以学…… 就算你已经退休了,想学就能学,谁也拦不住你。
它也不分性别,男性可以学,女性同样可以学,性别差异在这里完全不存在。
它也不分国界,更没有区域差异 —— 互联网的恩惠在于,你在北京、纽约也好,老头沟、门头沟也罢,在这个领域里同样完全没有任何具体差异。
尤其是在中国。现状是,中国的人口密度极高,优质教育资源的确就是稀缺…… 但在计算机科学领域,所有的所谓 “优质教育资源” 事实上完全没有任何独特的竞争力 —— 编程领域,实际上是当今世上极为罕见的 “教育机会公平之地”。又不仅在中国如此,事实上,在全球范围内也都是如此。
(二)
编程作为 “讲解如何习得自学能力的例子”,实在是太好了。
首先,编程这个东西反正要自学 —— 不信你问问计算机专业的人,他们会如实告诉你的,学校里确实也教,但说实话都教得不太好……
其次,编程这个东西最适合 “仅靠阅读自学” —— 这个领域发展很快,到最后,新东西出来的时候,没有老师存在,任由你是谁,都只能去阅读 “官方文档”,只此一条路。
然后,也是最重要的一条,别管是不是很多人觉得编程是很难的东西,事实上它就是每个人都应该具备的技能。
许多年前,不识字,被称为文盲……
后来,人们反应过来了,不识英文,也是文盲,因为科学文献的主导语言是英文,读不懂英文,什么都吃不上热乎的;等菜好不容易端上来了吧,早就凉了不说,味道都常常会变……
再后来,不懂基本计算机操作技能的,也算是文盲,因为他们无论做什么事情,效率都太低下了,明明可以用快捷键一下子完成的事情,却非要手动大量重复……
到了最近,不懂数据分析的,也开始算作文盲了。许多年前人们惊呼信息时代来了的时候,其实暂时体会不到什么太多的不同。然而,许多年过去,互联网上的格式化数据越来越多,不仅如此,实时产出的格式化数据也越来越多,于是,数据分析不仅成了必备的能力,而且早就开始直接影响一个人的薪资水平。
你作为一个个体,每天都在产生各种各样的数据,然后时时刻刻都在被别人使用着、分析着…… 然而你自己却全然没有数据分析能力,甚至不知道这事很重要,是不是感觉很可怕?你看看周边那么多人,有多大的比例想过这事?反正那些天天看机器算法生成的信息流的人好像就是全然不在意自己正在被支配……
怎么办?学呗,学点编程罢 —— 巧了,这还真是个正常人都能学会的技能。
(三)
编程作为 “讲解如何习得自学能力的例子” 最好的地方在于,这个领域的知识结构,最接近每个人所面对的人生中的知识结构。
这是什么意思呢?
编程入门的门槛之所以高,有个比较特殊的原因:
它的知识点结构不是线性的。
我们在中小学里所遇到的教科书,其中每个章节所涉及到的知识点之间,全都是线性关联。第一章学好了,就有基础学第二章;在第二章的概念不会出现在第一章之中……
很遗憾,编程所涉及到的知识点没办法这样组织 —— 就是不行。编程教材之所以难以读懂,就是因为它的各章中的知识点结构不是线性排列的。你经常在某一章读到不知道后面第几章才可能讲解清楚的概念。
比如,几乎所有的 Python 编程书籍上来就举个例子:
1 | print('Hello, world!') |
姑且不管这个例子是否意义非凡或者意义莫名,关键在于,print() 是个函数,而函数这个概念,不可能一上来就讲清楚,只能在后面若干章之后才开始讲解……
想要理解当前的知识点,需要依赖对以后才能开始学习的某个甚至多个知识点的深入了解……
这种现象,可以借用一个专门的英文概念,叫做 “Forward References” —— 原本是计算机领域里的一个术语。为了配合当前的语境,姑且把它翻译为 “过早引用” 罢,或者 “前置引用” 也行。
学校里的课本,都很严谨 —— 任何概念,未经声明就禁止使用。所以,学完一章,就能学下一章;跳到某一章遇到不熟悉的概念,往前翻肯定能找到……
在学校里习惯了这种知识体系的人,离开学校之后马上抓瞎 —— 社会的知识结构不仅不是这样的,而且几乎全都不是这样的。工作中、生活里,充满了各式各样的 “过早引用”。为什么总是要到多年以后你才明白父母曾经说过的话那么有道理?为什么总要到孩子已经长大之后才反应过来当初自己对孩子做错过很多事情?为什么在自己成为领导之前总是以为他们只不过是在忽悠你?为什么那么多人创业失败了之后才反应过来当初投资人提醒的一些观念其实是千真万确的?—— 因为很多概念很多观念是 “过早引用”,在当时就是非常难以理解……
自学编程在这方面的好处在于,在自学的过程中,其实你相当于过了一遍 “模拟人生” —— 于是,面对同样的 “过早引用”,你不会觉得那么莫名其妙,你有一套你早已在 “模拟人生” 中练就的方法论去应对。
(四)
另外一个把编程作为 “讲解如何习得自学能力的例子” 最好的地方在于,你在这个过程中将不得不习得英语 —— 起码是英文阅读能力,它能让你在不知不觉中 “脱盲”。
学编程中最重要的活动就是 “阅读官方文档”。学 Python 更是如此。Python 有很多非常优秀的地方,其中一个令人无法忽视的优点就是它的文档完善程度极好。它甚至有专门的文档生成工具,Sphinx:
Sphinx is a tool that makes it easy to create intelligent and beautiful documentation, written by Georg Brandl and licensed under the BSD license.
It was originally created for the Python documentation, and it has excellent facilities for the documentation of software projects in a range of languages. Of course, this site is also created from reStructuredText sources using Sphinx!
最好的 Python 教程,是官方网站上的 The Python Tutorial,读它就够了。我个人完全没兴趣从头到尾写一本 Python 编程教材,不仅因为人家写得真好,而且它就放在那里。
虽然你在官方网站上就是很难找到它的中文版,虽然就不告诉你到底在哪里也显得很不厚道,但是,我建议你就只看英文版 —— 因为离开了这个教程之后,还是要面对绝大多数都是英文的现实。
为了照顾那些也想读完本书,但因为种种原因想着读中文可以快一些的人,链接还是放在这里:
- https://docs.python.org/zh-cn/3/tutorial/index.html (for v.3.7.2)
- http://www.pythondoc.com/pythontutorial3/ (for v.3.6.3)
我曾经专门写过一本书发布在网上,叫《人人都能用英语》。其中的观点就是,大多数人之所以在英语这事上很矬,是因为他们花无数的时间去 “学”,但就是 “不用”。学以致用,用以促学。可就是不用,无论如何就是不用,那英语学了那么多年能学好吗?
自学编程的一个 “副作用” 就是,你不得不用英语。而且还是天天用,不停地用。
当年我上大学的时候,最初英语当然也不好。不过,因为想读当时还是禁书的《动物庄园》(Animal Farm),就只好看原版(当时好不容易搞到的是本英法对照版)…… 然后英语阅读就基本过关了。
这原理大抵上是这样,刚开始,英语就好像一层毛玻璃,隔在你和你很想要了解的内容之间。然而,由于你对那内容的兴趣和需求是如此强烈,乃至于即便隔着毛玻璃你也会挣扎着去看清楚…… 挣扎久了(其实没两天就不一样),你的 “视力” 就进化了,毛玻璃还在那里,但你好像可以穿透它看清一切……
自学编程,也算是一举两得了!
(五)
当然,把编程作为 “讲解如何习得自学能力的例子”,实在是太好了的最重要原因在于,自学编程对任何人来说都绝对是:
- 现实的(Practical)
- 可行动的(Actionable)
- 并且还是真正是可达成的(Achievable)
最重要的就是最后这个 “可达成的”。虽然对读者和作者来说,一个做到没那么容易,另一个讲清楚也非常难,但是,既然是所有人都 “可达成的”,总得试试吧?但是,请相信我,这事比减肥容易多了 —— 毕竟,你不是在跟基因作斗争。
这只是个起点。
尽量只靠阅读学会编程,哪怕仅仅是入门,这个经历和经验都是极为宝贵的。
自学是门手艺。只不过它并不像卖油翁的手艺那样很容易被别人看到,也不是很容易拿它出来炫耀 —— 因为别人看不到么!然而,经年累月,就不一样了,那好处管他别人知不知道,自己却清楚得很!
你身边总有些人能把别人做不好的事做得极好,你一定很羡慕。可他们为什么能做到那样呢?很简单啊,他们的自学能力强,所以他们能学会大多数自学能力差的人终生学不到的东西。而且他们的自学能力会越来越强,每学会一样新东西,他们就积累了更多自学经验,难以对外言表的经验,再遇到什么新东西,相对没那么吃力。
另外,自学者最大的感受就是万物相通。他们经常说的话有这么一句:“…… 到最后,都是一样的呢。”
(六)
最后一个好处,一句话就能说清楚,并且,随着时间的推移,你对此的感触会越来越深:
在这个领域里,自学的人最多……
没有什么比这句话更令人舒心的了:相信我,你并不孤独。
只靠阅读习得新技能
习得自学能力的终极目标就是:
有能力只靠阅读就能习得新技能。
退而求其次,是 “尽量只靠阅读就习得新技能” —— 当然,刚开始的时候可能需要有人陪伴,一起学,一起讨论,一起克服困难…… 但就是要摆脱 “没人教,没人带,没人逼,就彻底没戏” 的状态。
小时候总是听大人说:
不是什么东西都可以从书本里学到的……
一度,我觉得他们说的有道理。再后来,隐约感觉这话哪儿有毛病,但竟然又感觉无力反驳……
那时,真被他们忽悠到了;后来,也差点被他们彻底忽悠到!
幸亏后来我渐渐明白,且越来越相信:
自己生活工作学习上遇到的所有疑问,书本里应该都有答案 —— 起码有所参考。
“不是什么东西都可以从书本里学到的……” 这话听起来那么有道理,只不过是因为自己读书不够多、不够对而已。
过了 25 岁,我放弃了读小说,虚构类作品,我只选择看电影;而非虚构类作品,我选择尽量只读英文书,虽然那时候买起来很贵也很费劲,但我觉得值 —— 英文世界和中文世界的文化风格略有不同。在英文世界里,你看到的正常作者好像更多地把 “通俗易懂”、“逻辑严谨” 当作最基本的素养;而在中文世界里,好像 “故弄玄虚”、“偷梁换柱” 更常见一些;在英文世界里,遇到读不懂的东西可以很平静地接受自己暂时的愚笨,心平气和地继续努力就好;在中文世界里,遇到装神弄鬼欺世盗名的,弄不好最初根本没认出来,到最后跟 “认贼作父” 一样令人羞辱难当不堪回首。
说实话,我真觉得这事跟崇洋媚外没什么关系。我是朝鲜族,去过韩国,真觉得韩国的书更没法看(虽然明显是个人看法)…… 2015 年年底,我的律师告诉我,美国移民就快帮我办下来了,可那时候我开始觉得美国政府也各种乱七八糟,于是决定停止办理。我是个很宅的人,除了餐馆基本上哪儿都不去,陪家人朋友出去所谓旅游的时候,我只不过是换个房间继续宅着…… 可这些都不是重点,重点在于:
知识原本就应该无国界…… 不是吗?不是吗!
再说,这些年我其实还读了不少中国人写的英文书呢,比如,张纯如的书很值得一看;郑念的 Life and Death in Shanghai,真的很好很好。我也读了不少老外写的关于中国的书 —— 这些年我一直推荐费正清的剑桥中国史(The Cambridge History of China),当然有中文版的,不过,能读英文版的话感受很不一样。
当然,英文书里同样烂书也很多,烂作者也同样一大堆,胡说八道欺世盗名的一大串…… 但总体上来看,非小说类著作质量的确更高一点。
还有,英语在科学研究领域早已成为 “主导语言”(Dominant Language)也是不争的事实。不过,英语成为主导语言的结果,就是英语本身被不断 “强奸”,外来语越来越多,“Long time no see” 被辞典收录就是很好的例子。事实上,英语本身就是个大杂烩……
读书越多越明白读书少会被忽悠…… 很多人真的会大头捣蒜一般地认同 “不是什么东西都可以从书本里学到的……”
另外,很多人在如此教导小朋友的时候,往往是因为 “人心叵测” 啊,“江湖险恶” 啊,所以害怕小朋友吃亏。可事实上,如若说,人间那些勾心斗角的事貌似从书本里学不来的话,其实也不过还是历史书看少了 —— 勾心斗角的套路历史上全都被反复用过了。倒是有本中文书值得吐血推荐,民国时代的作者连阔如先生写的《江湖丛谈》,粗略扫过你就知道了,江湖那点事,也早就有人给你里里外外翻了个遍…… 只不过这书不太容易买到就是了。
我也遇到过这样的反驳:
书本能教会你做生意吗?!
说实话,去回驳这个反驳还真挺难,因为反驳者是脑容量特别有限才能说出这种话 —— 世界上有那么多商学院都是干嘛的?搞得它们好像不存在一样。首先,它们的存在说明,商业这事是有迹可循的,是可学习的;其次,商业类书籍非常多,是非虚构类书籍中的一大品类;更为重要的是,做生意这事,看谁做 —— 有本事(即,比别人拥有更多技能)的人做生意和没本事的人做生意,用同样的商业技巧,能有一样的效果吗?最后啊,这世界在这方面从来没有变过:一技傍身的人,总是不愁生活……
更为重要的是,这才几年啊,互联网本身已经成了一本大书 —— 关于全世界的一整本大书。仅仅是 10 多年前,大约在 2008 年前后,经过几年发展的 Wikipedia 被众多西方大学教授们群起而攻,指责它错误百出…… 可现在呢?Wikipedia 好像有天生的自我修复基因,它变得越来越值得信赖,越来越好用。
七零后八零后长大的过程中,还经常被父母无故呵斥:“怎么就你事这么多!” 或者无奈敷衍:“等你长大了就明白了……” 九零后、零零后呢?他们很少有什么疑问需要向父母提问,直接问搜索引擎,效果就是父母们天天被惊到甚至吓到。最近两年更不一样了,我有朋友在旧金山生活,他的孩子整天跟 Google 说话,有点什么问题,就直接 “Hey Google…”
我长大的那个年代,一句 “通过阅读了解世界” 好像还是很抽象甚至很不现实的话,现在呢?现在,除了阅读之外,你还能想出什么更有效的方法吗?反正我想不出。
有个很有趣的现象:
人么,只要识字,就忍不住阅读……
只不过,人们阅读的选择很不同而已。有自学能力的人和没有自学能力的人,在这一点上很容易分辨:
- 有自学能力的人,选择阅读 “有繁殖能力” 的内容;
- 没有自学能力的人,阅读只是为了消磨时光……
我把那些能给你带来新视野,能让你改变思考模式,甚至能让你拥有一项新技能的内容称之为 “有繁殖能力的内容”。
人都一样,拥有什么样的能力之后,就会忍不住去用,甚至总是连下意识中也要用。
那些靠阅读机器算法推送的内容而杀时间的人,恰恰就是因为他们有阅读能力才去不断地读,读啊读,像是那只被打了兴奋剂后来死在滚轮上的小白鼠。如果这些人哪怕有一点点自学能力,那么他们很快就会分辨出自己正在阅读的东西不会刺激自己的产出,只会消磨自己的时间;那么,他们就会主动放弃阅读那些杀时间的内容,把那时间和精力自然而然地用在筛选有繁殖能力的内容,让自己进步,让自己习得更多技能上去了。
所以,只要你有一次 “只靠阅读习得一项新技能” 的经验,你就变成另外一个人了。你会不由自主、哪怕下意识里都会去运用你新习得的能力…… 从这个角度看,自学很上瘾!能上瘾,却不仅无害,还好处无穷,这样的好事,恐怕也就这一个了罢。
我有过只靠阅读学会游泳的经历…… 听起来不像真的吧?更邪门的是,罗永浩同学的蛙泳,是我站在游泳池边,仅靠言语讲解,就让他从入水就扑腾开始三十分钟之内可以开始蛙泳的 —— 虽然当天他第一次蛙泳,一个来回五十米都坚持不下来。
仅靠阅读学会新技能不仅是可能的,并且,你随后会发现的真相是:
绝大多数情况下,没人能教你,也不一定有人愿意教你…… 到最后,你想学会或你必须学会什么东西的时候,你只能靠阅读! —— 因为其实你谁都靠不上……
我有很多偶像,英国数学家乔治・布尔就是其中一个 —— 因为他就是个基本上只靠阅读自学成才的人。十八、九岁,就自学了微积分 —— 那是将近两百年前,没有 Google,没有 Wikipedia…… 然后他还自己创办了学校,给自己打工…… 从来没有上过大学,后来却被皇家学院聘请为该学院第一个数学教授。然后,人家发明的布尔代数,在百年之后引发了信息革命…… 达芬奇也是这样的人 —— 要说惨,他比所有人都惨…… 因为几乎从一开始就貌似没有谁有资格有能力教他。
这些例子都太遥远了。给你讲个我身边的人,我亲自打过很长时间交道的人 —— 此人姓邱,人称邱老板。
邱老板所写的区块链交易所引擎,在 Github 上用的是个很霸气的名字,“貔貅”(英文用了一个生造的词,Peatio)—— 这个 Repo 至 2019 年春节的时候,总计有 2,913 个 Star,有 2,150 个 Fork…… 绝对是全球这个领域中最受关注的开源项目。2017 年 9 月,云币应有关部门要求关闭之前,是全球排名前三的区块链交易所。
邱老板当年上学上到几年级呢?初中未读完,所以,跟他聊天随口说成语是很有负担的,因为他真的可能听不懂…… 然而,他的编程、他的英语,全是自学的…… 学到什么地步呢?学到可以创造极有价值的商业项目的地步。他什么学习班都没上过,全靠阅读 —— 基本上只读互联网这本大书。
讲真,你没有选择,只靠阅读习得新技能,这是你唯一的出路。
开始阅读前的一些准备
内容概要
关于 Python 编程的第一部分总计 7 章,主要内容概括为:
- 以布尔值为入口开始理解程序本质
- 了解值的分类和运算方法
- 简要了解流程控制的原理
- 简要了解函数的基本构成
- 相对完整地了解字符串的操作
- 了解各种容器的基础操作
- 简要了解文件的读写操作
阅读策略
首先,不要试图一下子就全部搞懂。这不仅很难,在最初的时候也完全没必要。
因为这部分的知识结构中,充满了 “过早引用”。请在第一遍粗略完成第 1 部分中的 E1 ~ E7 之后,再去阅读《如何从容应对 “过早引用”?》。
其次,这一部分,注定要反复阅读若干遍。
在开始之前,要明确这一部分的阅读目标。
这一部分的目标,不是让你读完之后就可以开始写程序;也不是让你读完之后就对编程或者 Python 编程有了完整的了解,甚至不是让你真的学会什么…… 这一部分的目标,只是让你 “脱盲”。
不要以为脱盲是很容易的事情。你看,所有人出生的时候,都天然是 “文盲”;人们要上好多年的学,才能够真正 “脱盲” —— 仔细想想吧,小学毕业的时候,所有人就真的彻底脱盲了吗?
以中文脱盲为例,学字的同时,还要学习笔划;为了学更多的字,要学拼音,要学如何使用《新华字典》……
学会了一些基础字之后,要学更多的词,而后在练习了那么多造词造句之后,依然会经常用错…… 你看,脱盲,和阅读能力强之间距离很长呢;不仅如此,阅读能力强和写作能力强之间的距离更长……
反复阅读这一部分的结果是:
- 你对基本概念有了一定的了解
- 你开始有能力相对轻松地阅读部分官方文档
- 你可以读懂一些简单的代码
仅此而已。
心理建设
当我们开始学习一项新技能的时候,我们的大脑会不由自主地紧张。可这只不过是多年之间在学校里不断受挫的积累效应 —— 学校里别的地方不一定行,可有个地方特别行:给学生制造全方位、无死角、层层递进的挫败感。
可是,你要永远记住两个字:
别怕!
用四个字也行:
啥也别怕!
六个字也可以:
没什么可怕的!
我遇到最多的孱弱之语大抵是这样的:
我一个文科生……
哈哈,从某个层面望过去,其实吧,编程既不是文科也不是理科…… 它更像是 “手工课”。你越学就越清楚这个事实,它就好像是你做木工一样,学会使用一个工具,再学会使用另外一个工具,其实总共就没多少工具。然后,你更多做的是各种拼接的工作,至于能做出什么东西,最后完全靠你的想象力……
十来岁的孩子都可以学会的东西,你怕什么?
别怕,无论说给自己,还是讲给别人,都是一样的,它可能是人生中最重要的鼓励词。
关于这一部分内容中的代码
所有的代码,都可以在选中代码单元格(Code Cell)之后,按快捷键 ⇧ ⏎ 或 ^ ⏎ 执行,查看结果。
少量执行结果太长的代码,其输出被设置成了 “Scrolled”,是可以通过触摸板或鼠标滑轮上下滑动的。
为了避免大量使用 print() 才能看到输出结果,在很多的代码单元格中,开头插入了以下代码:
1 | from IPython.core.interactiveshell import InteractiveShell |
你可以暂时忽略它们的意义和工作原理。注意:有时,你需要在执行第二次的时候,才能看到全部输出结果。
另外,有少量代码示例,为了让读者每次执行的时候看到不同的结果,使用了随机函数,为其中的变量赋值,比如:
1 | import random |
同样,你可以暂时忽略它们的意义和工作原理;只需要知道因为有它们在,所以每次执行那个单元格中的代码会有不同的结果就可以了。
如果你不是直接在网站上浏览这本 “书”、或者不是在阅读印刷版,而是在本地自己搭建 Jupyterlab 环境使用,那么请参阅附录《Jupyterlab 的安装与配置》。
注意:尤其需要仔细看看《Jupyterlab 的安装与配置》的《关于 Jupyter lab themes》这一小节 —— 否则,阅读体验会有很大差别。
另外,如果你使用的是 nteract 桌面版 App 浏览 .ipynb 文件,那么有些使用了 input() 函数的代码是无法在 nteract 中执行的。
入口
“速成”,对绝大多数人[1]来说,在绝大多数情况下,是不大可能的。
编程如此,自学编程更是如此。有时,遇到复杂度高一点的知识,连快速入门都不一定是很容易的事情。
所以,这一章的名称,特意从 “入门” 改成了 “入口” —— 它的作用是给你 “指一个入口”,至于你能否从那个入口进去,是你自己的事了……
不过,有一点不一样的地方,我给你指出的入口,跟别的编程入门书籍不一样 —— 它们几乎无一例外都是从一个 “Hello World!” 程序开始的…… 而我们呢?
让我们从认识一个人开始罢……
乔治・布尔
1833 年,一个 18 岁的英国小伙脑子里闪过一个念头:
逻辑关系应该能用符号表示。
这个小伙子叫乔治・布尔(George Boole,其实之前就提到过我的这位偶像),于 1815 年出生于距离伦敦北部 120 英里之外的一个小镇,林肯。父亲是位对科学和数学有着浓厚兴趣的鞋匠。乔治・布尔在父亲的影响下,靠阅读自学成才。14 岁的时候就在林肯小镇名声大噪,因为他翻译了一首希腊语的诗歌并发表在本地的报纸上。
到了 16 岁的时候,他被本地一所学校聘为教师,那时候他已经在阅读微积分书籍。19 岁的时候布尔创业了 —— 他办了一所小学,自任校长兼教师。23 岁,他开始发表数学方面的论文。他发明了 “操作演算”,即,通过操作符号来研究微积分。他曾经考虑过去剑桥读大学,但后来放弃了,因为为了入学他必须放下自己的研究,还得去参加标准本科生课程。这对一个长期只靠自学成长的人来说,实在是太无法忍受了。
1847 年,乔治 32 岁,出版了他人生的第一本书籍,THE MATHEMATICAL ANALYSIS OF LOGIC —— 18 岁那年的闪念终于成型。这本书很短,只有 86 页,但最终它竟然成了人类的瑰宝。在书里,乔治・布尔很好地解释了如何使用代数形式表达逻辑思想。
1849 年,乔治・布尔 34 岁,被当年刚刚成立的女皇学院(Queen’s College)聘请为第一位数学教授。随后他开始写那本最著名的书,AN INVESTIGATION OF THE LAWS OF THOUGHT。他在前言里写到:
“The design of the following treatise is to investigate the fundamental laws of those operations of the mind by which reasoning is performed; to give expression to them in the symbolical language of a Calculus, and upon this foundation to establish the science of Logic and construct its method; …”
“本书论述的是,探索心智推理的基本规律;用微积分的符号语言进行表达,并在此基础上建立逻辑和构建方法的科学……”
在大学任职期间,乔治・布尔写了两本教科书,一本讲微分方程,另外一本讲差分方程,而前者,A TREATISE ON DIFFERENTIAL EQUATIONS,直到今天,依然难以超越。

乔治・布尔于 1864 年因肺炎去世。
乔治・布尔在世的时候,人们并未对他的布尔代数产生什么兴趣。直到 70 年后,克劳德・香农(Claude Elwood Shannon)发表那篇著名论文,A SYMBOLIC ANALYSIS OF RELAY AND SWITCHING CIRCUITS 之后,布尔代数才算是开始被大规模应用到实处。
有本书可以闲暇时间翻翻,The Logician and the Engineer: How George Boole and Claude Shannon Created the Information Age。可以说,没有乔治・布尔的布尔代数,没有克劳德・香农的逻辑电路,就没有后来的计算机,就没有后来的互联网,就没有今天的信息时代 —— 世界将会怎样?
2015 年,乔治・布尔诞辰 200 周年,Google 设计了专门的 Logo 纪念这位为人类作出巨大贡献的自学奇才。
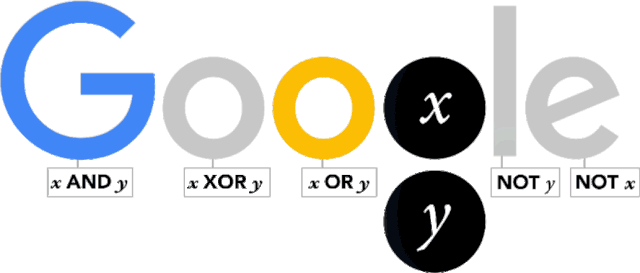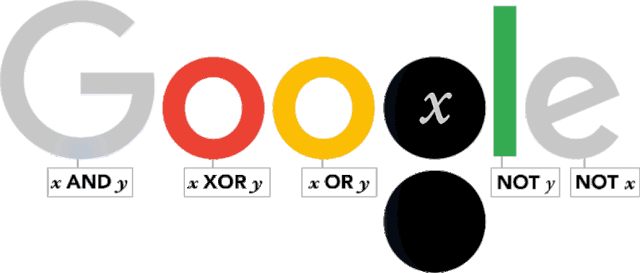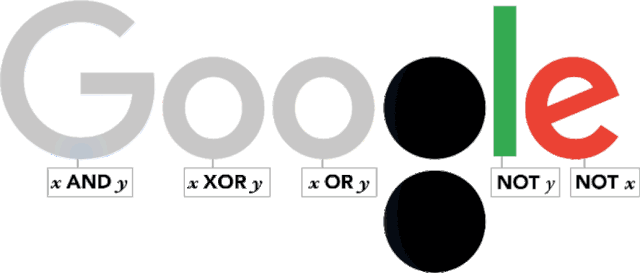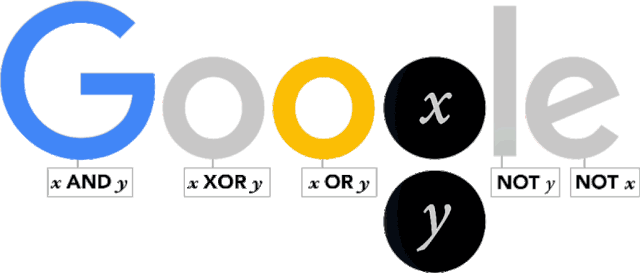
Google Doodle 的寄语是这样的:
A very happy 11001000_th_ birthday to genius George Boole!
布尔运算
从定义上来看,所谓程序(Programs)其实一点都不神秘。
因为程序这个东西,不过是按照一定顺序完成任务的流程(Procedures)。根据定义,日常生活中你做盘蛋炒饭给自己吃,也是完成了一个 “做蛋炒饭” 的程序 —— 你按部就班完成了一系列的步骤,最终做好了一碗蛋炒饭给自己吃 —— 从这个角度望过去,所有的菜谱都是程序……
只不过,菜谱这种程序,编写者是人,执行者还是人;而我们即将要学会写的程序,编写者是人,执行者是计算机 —— 当然,菜谱用自然语言编写,计算机程序由程序员用编程语言编写。
然而,这些都不是最重要的差异 —— 最重要的差异在于计算机能做布尔运算(Boolean Operations)。
于是,一旦代码编写好之后,计算机在执行的过程中,除了可以 “按照顺序执行任务” 之外,还可以 “根据不同情况执行不同的任务”,比如,“如果条件尚未满足则重复执行某一任务”。
计算器和计算机都是电子设备,但计算机更为强大的原因,用通俗的说法就是它 “可编程”(Programable)—— 而所谓可编程的核心就是布尔运算及其相应的流程控制(Control Flow);没有布尔运算能力就没有办法做流程控制;没有流程控制就只能 “按顺序执行”,那就显得 “很不智能”……
布尔值
在 Python 语言中,布尔值(Boolean Value)用 True 和 False 来表示。
注意:请小心区分大小写 —— 因为 Python 解释器是对大小写敏感的,对它来说,True 和 true 不是一回事。
任何一个逻辑表达式都会返回一个布尔值。
1 | from IPython.core.interactiveshell import InteractiveShell |
False
True
1 == 2,用自然语言描述就是 “1 等于 2 吗?” —— 它的布尔值当然是 False。
1 != 2,用自然语言描述就是 “1 不等于 2 吗?” —— 它的布尔值当然是 True。
注意:自然语言中的 “等于”,在 Python 编程语言中,使用的符号是 ==,不是一个等号!
请再次注意:单个等号 =,有其他的用处。初学者最不适应的就是,在编程语言里所使用的操作符,与他们之前在其他地方已经习惯了的使用方法并不相同 —— 不过,适应一段时间就好了。
逻辑操作符
Python 语言中的逻辑操作符(Logical Operators)如下表所示 —— 为了理解方便,也可以将其称为 “比较操作符”。
| 比较操作符 | 意义 | 示例 | 布尔值 |
|---|---|---|---|
== |
等于 | 1 == 2 |
False |
!= |
不等于 | 1 != 2 |
True |
> |
大于 | 1 > 2 |
False |
>= |
大于等于 | 1 >= 1 |
True |
< |
小于 | 1 < 2 |
True |
<= |
小于等于 | 1 <= 2 |
True |
in |
属于 | 'a' in 'basic' |
True |
除了等于、大于、小于之外,Python 还有一个逻辑操作符,in:
这个表达式 'a' in 'basic' 用自然语言描述就是:
“
'a'存在于'basic'这个字符串之中吗?”(属于关系)
布尔运算操作符
以上的例子中,逻辑操作符的运算对象(Operands)是数字值和字符串值。
而针对布尔值进行运算的操作符很简单,只有三种:与、或、非:
分别用
and、or、not表示
注意:它们全部是小写。因为布尔值只有两个,所以布尔运算结果只有几种而已,如下图所示:

先别管以下代码中 print() 这个函数的工作原理,现在只需要关注其中布尔运算的结果:
1 | print('(True and False) yields:', True and False) |
(True and False) yields: False
(True and True) yields: True
(False and True) yields: False
(True or False) yields: True
(False or True) yields: True
(False or False) yields: False
(not True) yields: False
(not False) yields: True
千万不要误以为布尔运算是理科生才必须会、才能用得上的东西…… 文理艺分科是中国的特殊分类方式,真挺害人的。比如,设计师们在计算机上创作图像的时候,也要频繁使用或与非的布尔运算操作才能完成各种图案的拼接…… 抽空看看这个网页:Boolean Operations used by Sketch App —— 这类设计软件,到最后是每个人都用得上的东西呢。另,难道艺术生不需要学习文科或者理科?—— 事实上,他们也有文化课……
流程控制
有了布尔运算能力之后,才有根据情况决定流程的所谓流程控制(Control Flow)的能力。
1 | import random |
693 is odd.
你可以多执行几次以上程序,看看每次不同的执行结果。执行方法是,选中上面的 Cell 之后按快捷键 shift + enter。
现在看代码,先忽略其它的部分,只看关键部分:
1 | ... |
这个 if/else 语句,完成了流程的分支功能。% 是计算余数的符号,如果 r 除以 2 的余数等于 0,那么它就是偶数,否则,它就是奇数 —— 写成布尔表达式,就是 r % 2 == 0。
这一次,你看到了单个等号 =:r = random.randrange(1, 1000)。
这个符号在绝大多数编程语言中都是 “赋值”(Assignment)的含义。
在 r = 2 之中,r 是一个名称为 r 的变量(Variable)—— 现在只需要将变量理解为程序保存数值的地方;而 = 是赋值符号,2 是一个整数常量(Literal)。
语句 r = 2 用自然语言描述就是:
“把
2这个值保存到名称为r的变量之中”。
现在先别在意头两行代码的工作原理,只关注它的工作结果:random.randrange(1, 1000) 这部分代码的作用是返回一个 1 到 1000 之间(含左侧 1 但不含右侧 1000)的随机整数。每次执行以上的程序,它就生成一个新的随机整数,然后因为 = 的存在,这个数就被保存到 r 这个变量之中。
计算机程序的所谓 “智能”(起码相对于计算器),首先是因为它能做布尔运算。计算机的另外一个好处是 “不知疲倦”(反正它也不用自己交电费),所以,它最擅长处理的就是 “重复”,这个词在程序语言中,术语是循环(Loop)。以下程序会打印出 10 以内的所有奇数:
1 | for i in range(10): |
1
3
5
7
9
其中 range(10) 的返回值,是 0~9 的整数序列(默认起始值是 0;含左侧 0,不含右侧 10)。
用自然语言描述以上的程序,大概是这样的 —— 自然语言写在 # 之后:
1 | for i in range(10): # 对于 0~9 中的所有数字都带入 i 这个变量,执行一遍以下任务: |
就算你让它打印出一百亿以内的奇数,它也毫不含糊 —— 你只需要在 range() 这个函数的括号里写上一个那么大的整数就行……
让它干一点稍微复杂的事吧,比如,我们想要打印出 100 以内所有的质数(Primes)。
根据质数的定义,它大于等于 2,且只有在被它自身或者 1 做为除数时余数为 0。判断一个数字是否是质数的算法是这样的:
- 设
n为整数,n >= 2;- 若
n == 2,n是质数;- 若
n > 2,就把n作为被除数,从2开始一直到n - 1都作为除数,逐一计算看看余数是否等于0?
- 如果是,那就不用接着算了,它不是质数;
- 如果全部都试过了,余数都不是
0,那么它是质数。
于是,你需要两个嵌套的循环,第一个是负责让被除数 n 从 2 遍历(就是依次经历一次)到 99(题目是 100 以内,所以不包含 100)的循环,第二个是在前者内部负责让除数 i 从 2 遍历到 n - 1 的循环:
1 | for n in range(2, 100): #range(2,100)表示含左侧 2,不含右侧 100,是不是第三次看到这个说法了? |
2
3
5
7
11
13
17
19
23
29
31
37
41
43
47
53
59
61
67
71
73
79
83
89
97
所谓算法
从
2作为除数开始试,试到 2√n 之后的一个整数就可以了……
1 | for n in range(2, 100): |
2
3
5
7
11
13
17
19
23
29
31
37
41
43
47
53
59
61
67
71
73
79
83
89
97
你看,寻找更有效的算法,或者说,不断优化程序,提高效率,最终是程序员的工作,不是编程语言本身的工作。关于判断质数最快的算法,可以看 Stackoverflow 上的讨论,有更多时间也可以翻翻 Wikipedia。
到最后,所有的工具都一样,效用取决于使用它的人。所以,学会使用工具固然重要,更为重要的是与此同时自己的能力必须不断提高。
虽然写代码这事刚开始学起来好像门槛很高,那只不过是幻觉,其实门槛比它更高的多的去了。到最后,它就是个最基础的工具,还是得靠思考能力 —— 这就好像识字其实挺难的 —— 小学初中高中加起来十来年,我们才掌握了基本的阅读能力;可最终,即便是本科毕业、研究生毕业,真的能写出一手好文章的人还是少之又少一样 —— 因为用文字值得写出来的是思想,用代码值得写出来的是创造,或者起码是有意义的问题的有效解决方案。有思想,能解决问题,是另外一门手艺 —— 需要终生精进的手艺。
所谓函数
我们已经反复见过 print() 这个函数(Functions)了。它的作用很简单,就是把传递给它的值输出到屏幕上 —— 当然,事实上它的使用细节也很多,以后慢慢讲。
现在,最重要的是初步理解一个函数的基本构成。关于函数,相关的概念有:函数名(Function Name)、参数(Parameters)、返回值(Return Value)、调用(Call)。
拿一个更为简单的函数作为例子,abs()。它的作用很简单:接收一个数字作为参数,经过运算,返回该数字的绝对值。
1 | a = abs(-3.1415926) |
3.1415926
在以上的代码的第 1 行中,
- 我们调用了一个函数名为
abs的函数;写法是abs(-3.1415926);- 这么写,就相当于向它传递了一个参数,其值为:
-3.1415926;- 该函数接收到这个参数之后,根据这个参数的值在函数内部进行了运算;
- 而后该函数返回了一个值,返回值为之前接收到的参数的值的绝对值
3.1415926;- 而后这个值被保存到变量
a之中。
从结构上来看,每个函数都是一个完整的程序,因为一个程序,核心构成部分就是输入、处理、输出:
- 它有输入 —— 即,它能接收外部通过参数传递的值;
- 它有处理 —— 即,内部有能够完成某一特定任务的代码;尤其是,它可以根据 “输入” 得到 “输出”;
- 它有输出 —— 即,它能向外部输送返回值……
被调用的函数,也可以被理解为子程序(Sub-Program)—— 主程序执行到函数调用时,就开始执行实现函数的那些代码,而后再返回主程序……
我们可以把判断一个数字是否是质数的过程,写成函数,以便将来在多处用得着的时候,随时可以调用它:
1 | def is_prime(n): # 定义 is_prime(),接收一个参数 |
83
89
97
101
103
107
109
细节补充
语句
一个完整的程序,由一个或者多个语句(Statements)构成。通常情况下,建议每一行只写一条语句。
1 | for i in range(10): |
1
3
5
7
9
语句块
在 Python 语言中,行首空白(Leading whitespace,由空格 ' ' 或者 Tab ⇥ 构成)有着特殊的含义。
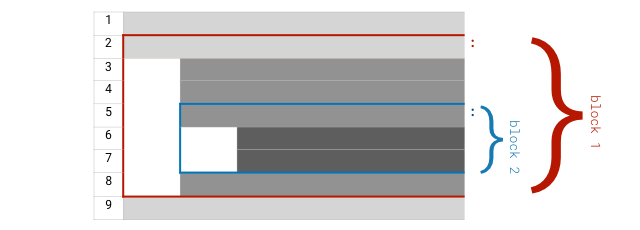
如果有行首空白存在,那么,Python 将认为这一行与其他邻近有着相同行首空白的语句同属于一个语句块 —— 而一个语句块必然由一个行末带有冒号 : 的语句起始。同属于一个语句块中的语句,行首空白数量应该相等。这看起来很麻烦,可实际上,程序员一般都使用专门的文本编辑器,比如 Visual Studio Code,其中有很多的辅助工具,可以让你很方便地输入具备一致性的行首空白。
以上程序,一共三个语句,两个语句块,一个 for 循环语句块中包含着一个 if 条件语句块。注意第一行和第二行末尾的冒号 :。
在很多其他的语言中,比如,JavaScript,用大括号 {} 作为语句块标示 —— 这是 Python 比较特殊的地方,它组织语句块的方式如下图所示:
注意:在同一个文件里,不建议混合使用 Tab 和 Space;要么全用空格,要么全用制表符。
注释
在 Python 程序中可以用 # 符号标示注释语句。
所谓的注释语句,就是程序文件里写给人看而不是写给计算机看的部分。本节中的代码里就带着很多的注释。
人写的 Python 语言代码,要被 Python 解释器翻译成机器语言,而后才能让计算机 “读懂”,随后计算机才可以按照指令执行。解释器在编译程序的过程中,遇到 # 符号,就会忽略其后的部分(包括这个注释符号)。
操作符
在本节,我们见到的比较操作符可以比较它左右的值,而后返回一个布尔值。
我们也见过两个整数被操作符 % 连接,左侧作为被除数,右侧作为除数,11 % 3 这个表达式的值是 2。对于数字,我们可用的操作符有 +、-、*、/、//、%、** —— 它们分别代表加、减、乘、除、商、余、幂。
赋值符号与操作符的连用
你已经知道变量是什么了,也已经知道赋值是什么了。于是,你看到 x = 1 就明白了,这是为 x 赋值,把 1 这个值保存到变量 x 之中去。
但是,若是你看到 x += 1,就迷惑了,这是什么意思呢?
这只是编程语言中的一种惯用法。它相当于 x = x + 1。
看到 x = x + 1 依然会困惑…… 之所以困惑,是因为你还没有习惯把单等号 = 当作赋值符号,把双等号 == 当作逻辑判断的 “等于”。
x = x + 1 的意思是说,把表达式 x + 1 的值保存到变量 x 中去 —— 如此这般之后,x 这个变量中所保存的就不再是原来的值了……
1 | x = 0 |
1
其实不难理解,只要习惯了就好。理论上,加减乘除商余幂这些操作符,都可以与赋值符号并用。
1 | x = 11 |
2
总结
以下是这一章中所提到的重要概念。了解它们以及它们之间的关系,是进行下一步的基础。
- 数据:整数、布尔值;操作符;变量、赋值;表达式
- 函数、子程序、参数、返回值、调用
- 流程控制、分支、循环
- 算法、优化
- 程序:语句、注释、语句块
- 输入、处理、输出
- 解释器
你可能已经注意到了,这一章的小节名称罗列出来的话,看起来像是一本编程书籍的目录 —— 只不过是概念讲解顺序不同而已。事实上还真的就是那么回事。
这些概念,基本上都是独立于某一种编程语言的(Language Independent),无论将来你学习哪一种编程语言,不管是 C++,还是 JavaScript,抑或是 Golang,这些概念都在那里。
学会一门编程语言之后,再学其它的就会容易很多 —— 而且,当你学会了其中一个之后,早晚你会顺手学其它的,为了更高效使用微软办公套件,你可能会花上一两天时间研究一下 VBA;为了给自己做个网页什么的,你会顺手学会 JavaScript;为了修改某个编辑器插件,你发现人家是用 Ruby 写的,大致读读官方文档,你就可以下手用 Ruby 语言了;为了搞搞数据可视化,你会发现不学会 R 语言有点不方便……
你把这些概念装在脑子里,而后就会发现几乎所有的编程入门教学书籍结构都差不多是由这些概念构成的。因为,所有的编程语言基础都一样,所有的编程语言都是我们指挥计算机的工具。无论怎样,反正都需要输入输出,无论什么语言,不可能没有布尔运算,不可能没有流程控制,不可能没有函数,只要是高级语言,就都需要编译器…… 所以,掌握这些基本概念,是将来持续学习的基础。
脚注
[1]:对于自学能力强、有很多自学经验的人来说,速成往往真的是可能、可行的。因为他们已经积累的知识与经验会在习得新技能时发挥巨大的作用,乃至于他们看起来相对别人花极少的时间就能完成整个自学任务。也就是说,将来的那个已经习得自学能力、且自学能力已经磨练得很强的你,常常真的可以做到在别人眼里 “速成”。
值及其相应的运算
从结构上来看,一切的计算机程序,都由且只由两个最基本的成分构成:
- 运算(Evaluation)
- 流程控制(Control Flow)
没有流程控制的是计算器而已;有流程控制的才是可编程设备。
看看之前我们见过的计算质数的程序:(按一下 ⎋,即 ESC,确保已经进入命令模式,⇧ L 可以切换是否显示代码行号)
1 | def is_prime(n): # 定义 is_prime(),接收一个参数 |
83
89
97
101
103
107
109
if...,for... 在控制流程:在什么情况下运算什么,在什么情况下重复运算什么;
第 13 行 is_prime() 这个函数的调用,也是在控制流程 —— 所以我们可以把函数看作是 “子程序” ;
一旦这个函数被调用,流程就转向开始执行在第 1 行中定义的 is_prime() 函数内部的代码,而这段代码内部还是计算和流程控制,决定一个返回值 —— 返回值是布尔值;再回到第 13 行,将返回值交给 if 判断,决定是否执行第 14 行……
而计算机这种可编程设备之所以可以做流程控制,是因为它可以做布尔运算,即,它可以对布尔值进行操作,而后将布尔值交给分支和循环语句,构成了程序中的流程控制。
值
从本质上看,程序里的绝大多数语句包含着运算(Evaluation),即,在对某个值进行评价。这里的 “评价”,不是 “判断某人某事的好坏”,而是 “计算出某个值究竟是什么” —— 所以,我们用中文的 “运算” 翻译这个 “Evaluation” 可能表达得更准确一些。
在程序中,被运算的可分为常量(Literals)和变量(Variables)。
1 | a = 1 + 2 * 3 |
在以上代码中,
1、2、3,都是常量。Literal 的意思是 “字面的”,顾名思义,常量的值就是它字面上的值。1 的值,就是 1。
a 是变量。顾名思义,它的值将来是可变的。比如,在第 2 句中,这个变量的值发生了改变,之前是 7,之后变成了 8。
第 1 句中的 +、*,是操作符(Operators),它用来对其左右的值进行相应的运算而后得到一个值。先是由操作符 * 对 2 和 3 进行运算,
生成一个值,6;然后再由操作符 + 对 1 和 6 进行运算,生成一个值 7。先算乘除后算加减,这是操作符的优先级决定的。
= 是赋值符号,它的作用是将它右边的值保存到左边的变量中。
值是程序的基础成分(Building blocks),它就好像盖房子用的砖块一样,无论什么样的房子,到最后都主要是由砖块构成。
常量,当然有个值 —— 就是它们字面所表达的值。
变量必须先赋值才能使用,也就是说,要先把一个值保存到变量中,它才能在其后被运算。
在 Python 中每个函数都有返回值,即便你在定义一个函数的时候没有设定返回值,它也会加上默认的返回值 None……(请注意 None 的大小写!)
1 | def f(): |
None
None
None
当我们调用一个函数的时候,本质上来看,就相当于:
我们把一个值交给某个函数,请函数根据它内部的运算和流程控制对其进行操作而后返回另外一个值。
比如,abs() 函数,就会返回传递给它的值的绝对值;int() 函数,会将传递给它的值的小数部分砍掉;float() 接到整数参数之后,会返回这个整数的浮点数形式:
1 | from IPython.core.interactiveshell import InteractiveShell |
3.14159
3
3.0
值的类型
在编程语言中,总是包含最基本的三种数据类型:
- 布尔值(Boolean Value)
- 数字(Numbers):整数(Int)、浮点数(Float)、复数(Complex Numbers)
- 字符串(Strings)
既然有不同类型的数据,它们就分别对应着不同类型的值。
运算的一个默认法则就是,通常情况下应该是相同类型的值才能相互运算。
显然,数字与数字之间的运算是合理的,但你让 + 这个操作符对一个字符串和一个数字进行运算就不行:
1 | from IPython.core.interactiveshell import InteractiveShell |
20.0
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-18-e922b7565e53> in <module>
3
4 11 + 10 - 9 * 8 / 7 // 6 % 5
----> 5 '3.14' + 3 # 这一句会报错
TypeError: can only concatenate str (not "int") to str
所以,在不得不对不同类型的值进行运算之前,总是要事先做 Type Casting(类型转换)。比如,
- 将字符串转换为数字用
int()、float();- 将数字转换成字符串用
str();
另外,即便是在数字之间进行计算的时候,有时也需要将整数转换成浮点数字,或者反之:
- 将整数转换成浮点数字用
float();- 将浮点数字转换成整数用
int();
有个函数,type(),可以用来查看某个值属于什么类型:
1 | from IPython.core.interactiveshell import InteractiveShell |
int
float
str
bool
range
list
tuple
set
dict
操作符
针对不同类型的数据,有各自专用的操作符。
数值操作符
针对数字进行计算的操作符有加减乘除商余幂:+、-、*、/、//、%、**。
其中 + 和 - 可以对单个值进行操作,-3;其它的操作符需要有两个值才能操作。
从优先级来看,这些操作符中:
- 对两个值进行操作的
+、-的优先级最低;- 稍高的是
*、/、//、%;- 更高的是对单个值进行操作的
+、-;- 优先级最高的是
**。
完整的操作符优先级列表,参见官方文档:
https://docs.python.org/3/reference/expressions.html#operator-precedence
布尔值操作符
针对布尔值,操作符有与、或、非:and、or、not。
它们之中,优先级最低的是或 or,然后是与 and, 优先级最高的是非 not:
1 | True and False or not True |
False
最先操作的是 not,因为它优先级最高。所以,上面的表达式相当于 True and False or (not True),即相当于 True and False or False;
然后是 and,所以,True and False or False 相当于是 (True and False) or False,即相当于 False or False;
于是,最终的值是 False。
逻辑操作符
数值之间还可以使用逻辑操作符,1 > 2 返回布尔值 False。逻辑操作符有:<(小于)、<=(小于等于)、>(大于)、>=(大于等于)、!=(不等于)、==(等于)。
逻辑操作符的优先级,高于布尔值的操作符,低于数值计算的操作符。
即:数值计算的操作符优先级最高,其次是逻辑操作符,布尔值的操作符优先级最低。
1 | n = -95 |
True
字符串操作符
针对字符串,有三种操作:
- 拼接:
+和' '(后者是空格)- 拷贝:
*- 逻辑运算:
in、not in;以及,<、<=、>、>=、!=、==
1 | from IPython.core.interactiveshell import InteractiveShell |
'AwesomePython'
'AwesomePython'
'Python, Awesome! Awesome! Awesome! '
False
字符之间,字符串之间,除了 == 和 != 之外,也都可以被逻辑操作符 <、<=、>、>= 运算:
1 | 'a' < 'b' |
True
这是因为字符对应着 Unicode 码,字符在被比较的时候,被比较的是对应的 Unicode 码。
1 | from IPython.core.interactiveshell import InteractiveShell |
False
65
97
当字符串被比较的时候,将从两个字符串各自的第一个字符开始逐个比较,“一旦决出胜负马上停止”:
1 | 'PYTHON' > 'Python 3' |
False
列表的操作符
数字和字符串(由字符构成的序列)是最基本的数据类型,而我们往往需要批量处理数字和字符串,这样的时候,我们需要数组(Array)。不过,在 Python 语言中,它提供了一个容器(Container)的概念,用来容纳批量的数据。
Python 的容器有很多种 —— 字符串,其实也是容器的一种,它的里面容纳着批量的字符。
我们先简单接触一下另外一种容器:列表(List)。
列表的标示,用方括号 [];举例来说,[1, 2, 3, 4, 5] 和 ['ann', 'bob', 'cindy', 'dude', 'eric'],或者 ['a', 2, 'b', 32, 22, 12] 都是一个列表。
因为列表和字符串一样,都是有序容器(容器还有另外一种是无序容器),所以,它们可用的操作符其实相同:
- 拼接:
+和' '(后者是空格)- 拷贝:
*- 逻辑运算:
in、not in;以及,<、<=、>、>=、!=、==
两个列表在比较时(前提是两个列表中的数据元素类型相同),遵循的还是跟字符串比较相同的规则:“一旦决出胜负马上停止”。但实际上,由于列表中可以包含不同类型的元素,所以,通常情况下没有实际需求对他们进行 “大于、小于” 的比较。(比较时,类型不同会引发 TypeError……)
1 | from IPython.core.interactiveshell import InteractiveShell |
False
True
True
更复杂的运算
对于数字进行加、减、乘、除、商、余、幂的操作,对于字符串进行拼接、拷贝、属于的操作,对布尔值进行或、与、非的操作,这些都是相对简单的运算。
更为复杂一点的,我们要通过调用函数来完成 —— 因为在函数内部,我们可以用比 “单个表达式” 更为复杂的程序针对传递进来的参数进行运算。换言之,函数就相当于各种事先写好的子程序,给它传递一个值,它会对其进行运算,而后返回一个值(最起码返回一个 None)。
以下是 Python 语言所有的内建函数(Built-in Functions):
现在倒不用着急一下子全部了解它们 —— 反正早晚都会的。
这其中,针对数字,有计算绝对值的函数 abs(),有计算商余的函数 divmod() 等等。
1 | from IPython.core.interactiveshell import InteractiveShell |
3.1415926
(3, 2)
这些内建函数也依然只能完成 “基本操作”,比如,对于数字,我们想计算三角函数的话,内建函数就帮不上忙了,于是,我们需要调用标准库(Standard Library)中的 math 模块(Module):
1 | import math |
-0.9589242746631385
代码 math.sin(5) 这里的 .,也可以被理解为 “操作符”,它的作用是:
从其它模块中调用函数。
代码 math.sin(5) 的作用是:
把
5这个值,传递给math这个模块里的sin()函数,让sin()根据它内部的代码对这个值进行运算,而后返回一个值(即,计算结果)。
类(Class)中定义的函数,也可以这样被调用 —— 虽然你还不明白类(Class)究竟是什么,但从结构上很容易理解,它实际上也是保存在其他文件中的一段代码,于是,那段代码内部定义的函数,也可以这样调用。
比如,数字,其实属于一个类,所以,我们可以调用那个类里所定义的函数,比如,float.as_integer_ratio(),它将返回两个值,第一个值除以第二个值,恰好等于传递给它的那个浮点数字参数:
1 | 3.1415926.as_integer_ratio() |
(3537118815677477, 1125899906842624)
关于布尔值的补充
当你看到以下这样的表达式,而后再看看它的结果,你可能会多少有点迷惑:
1 | True or 'Python' |
True
这是因为 Python 将 True 定义为:
By default, an object is considered true unless its class defines either a __bool__() method that returns
Falseor a __len__() method that returns zero, when called with the object.https://docs.python.org/3/library/stdtypes.html#truth-value-testing
这一段文字,初学者是看不懂的。但下一段就好理解了:
Here are most of the built-in objects considered
False:
- constants defined to be false:
NoneandFalse.- zero of any numeric type:
0,0.0,0j,Decimal(0),Fraction(0, 1)- empty sequences and collections:
'',(),[],{},set(),range(0)
所以,'Python' 是个非空的字符串,即,不属于是 empty sequences,所以它不被认为是 False,即,它的布尔值是 True
于是,这么理解就轻松了:
每个变量或者常量,除了它们的值之外,同时还相当于有一个对应的布尔值。
关于值的类型的补充
除了数字、布尔值、字符串,以及上一小节介绍的列表之外,还有若干数据类型,比如 range()(等差数列)、tuple(元组)、set(集合)、dictionary(字典),再比如 Date Type(日期)等等。
它们都是基础数据类型的各种组合 —— 现实生活中,更多需要的是把基础类型组合起来构成的数据。比如,一个通讯簿,里面是一系列字符串分别对应着若干字符串和数字。
1 | entry[3662] = { |
针对不同的类型,都有相对应的操作符,可以对其进行运算。
这些类型之间有时也有不得不相互运算的需求,于是,在相互运算之前同样要 Type Casting,比如将 List 转换为 Set,或者反之:
1 | from IPython.core.interactiveshell import InteractiveShell |
[1, 2, 3, 4, 5, 6, 7]
{1, 2, 3, 4, 5, 6, 7}
[1, 2, 3, 4, 5, 6, 7]
总结
回到最开始:从结构上来看,一切的计算机程序,都由且只由两个最基本的成分构成:
- 运算(Evaluation)
- 流程控制(Control Flow)
这一章主要介绍了基础数据类型的运算细节。而除了基础数据类型,我们需要由它们组合起来的更多复杂数据类型。但无论数据的类型是什么,被操作符操作的总是该数据的值。所以,虽然绝大多数编程书籍按照惯例会讲解 “数据类型”,但为了究其本质,我们在这里关注的是 “值的类型”。虽然只是关注焦点上的一点点转换,但实践证明,这一点点的不同,对初学者更清楚地把握知识点有巨大的帮助。
针对每一种值的类型,无论简单复杂,都有相应的操作方式:
- 操作符
- 值运算
- 逻辑运算
- 函数
- 内建函数
- 其他模块里的函数
- 其本身所属类之中所定义的函数
所以,接下来要学习的,无非就是熟悉各种数据类型,及其相应的操作,包括能对它们的值进行操作的操作符和函数;无论是操作符还是函数,最终都会返回一个相应的值,及其相应的布尔值 —— 这么看来,编程知识结构没多复杂。因为换句话讲,
接下来你要学习的无非是各种数据类型的运算而已。
另外,虽然现在尚未来得及对函数进行深入讲解,但最终你会发现它跟操作符一样,在程序里无所不在。
备注
另外,以下几个链接先放在这里,未来你会返回来参考它们,还是不断地参考它们:
- 关于表达式:https://docs.python.org/3/reference/expressions.html
- 关于所有操作的优先级:https://docs.python.org/3/reference/expressions.html#operator-precedence
- 上一条链接不懂 BNF 的话根本读不懂:https://en.wikipedia.org/wiki/Backus-Naur_form
- Python 的内建函数:https://docs.python.org/3/library/functions.html
- Python 的标准数据类型:https://docs.python.org/3/library/stdtypes.html
另外,其实所有的操作符,在 Python 内部也是调用函数完成的……
流程控制
在相对深入了解了值的基本操作之后,我们需要再返回来对流程控制做更深入的了解。
之前我们看过这个寻找质数的程序:
1 | for n in range(2, 100): |
这其中,包含了分支与循环 —— 无论多复杂的流程控制用这两个东西就够了,就好像无论多复杂的电路最终都是由通路和开路仅仅两个状态构成的一样。
今天的人们觉得这是 “天经地义” 的事情,可实际上并非如此。这是 1966 年的一篇论文所带来的巨大改变 —— Flow diagrams, turing machines and languages with only two formation rules by Böhm and Jacopini (1966)。实际上,直到上个世纪末,
GOTO语句才从各种语言里近乎 “灭绝”……任何进步,无论大小,其实都相当不容易,都非常耗时费力 —— 在哪儿都一样。有兴趣、有时间,可以去浏览 Wikipedia 上的简要说明 —— Wikipedia: Minimal structured control flow。
if 语句
if 语句的最简单构成是这样 —— 注意第 1 行末尾的冒号 : 和第 2 行的缩进:
1 | if expression: |
如果表达式 expression 返回值为真,执行 if 语句块内部的 statements,否则,什么都不做,执行 if 之后的下一个语句。
1 | import random |
372 is even.
如果,表达式 expression 返回值无论真假,我们都需要做一点相应的事情,那么我们这么写:
1 | if expression: |
如果表达式 expression 返回值为真,执行 if 语句块内部的 statements_for_True,否则,就执行 else 语句块内部的 statements_for_False
1 | import random |
945 is odd.
有时,表达式 <expression> 返回的值有多种情况,并且针对不同的情况我们都要做相应的事情,那么可以这么写:
1 | if expression_1: |
Python 用 elif 处理这种多情况分支,相当于其它编程语言中使用 switch 或者 case……
elif 是 else if 的缩写,作用相同。
以下程序模拟投两个骰子的结果 —— 两个骰子数字加起来,等于 7 算平,大于 7 算大,小于 7 算小:
1 | import random |
Big!
当然你还可以模拟投飞了的情况,即,最终的骰子数是 0 或者 1,即,< 2:
1 | import random |
Small!
for 循环
Python 语言中,for 循环不使用其它语言中那样的计数器,取而代之的是 range() 这个我称其为 “整数等差数列生成器” 的函数。
用 C 语言写循环是这样的:
1 | for( a = 0; a < 10; a = a + 1 ){ |
用 Python 写同样的东西,是这样的:
1 | for a in range(10): |
value of a: 0
value of a: 1
value of a: 2
value of a: 3
value of a: 4
value of a: 5
value of a: 6
value of a: 7
value of a: 8
value of a: 9
range() 函数
range() 是个内建函数,它的文档是这样写的:
range(stop)
range(start, stop[, step])
只有一个参数的时候,这个参数被理解为 stop,生成一个从 0 开始,到 stop - 1 的整数数列。
这就解释了为什么有的时候我们会在 for ... in range(...): 这种循环内的语句块里进行计算的时候,经常会在变量之后写上 + 1,因为我们 range(n) 的返回数列中不包含 n,但我们有时候却需要 n。点击这里返回看看第一章里提到的例子:所谓算法那一小节。
1 | from IPython.core.interactiveshell import InteractiveShell |
range(0, 10)
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
start 参数的默认值是 0。如需指定起点,那么得给 range() 传递两个参数,比如,range(2, 13)……
1 | list(range(2, 13)) |
[2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12]
第三个参数可选;step,步长,就相当于是 “等差数列” 当中的 “差”,默认值是 1。例如,range(1, 10, 2) 生成的是这样一个数列 [1, 3, 5, 7, 9]。所以,打印 0 ~ 10 之间的所有奇数,可以这样写:
1 | for i in range(1, 10, 2): |
1
3
5
7
9
我们也可以生成负数的数列:
1 | list(range(0, -10, -1)) |
[0, -1, -2, -3, -4, -5, -6, -7, -8, -9]
Continue、Break 和 Pass
在循环的过程中,还可以用 continue 和 break 控制流程走向,通常是在某条件判断发生的情况下 —— 正如你早就见过的那样:
1 | for n in range(2, 100): |
continue 语句将忽略其后的语句开始下次循环,而 break 语句将从此结束当前循环,开始执行循环之后的语句:

for 语句块还可以附加一个 else —— 这是 Python 的一个比较有个性的地方。附加在 for 结尾的 else 语句块,在没有 break 发生的情况下会运行。
1 | for n in range(2, 100): |
2
3
5
7
11
13
17
19
23
29
31
37
41
43
47
53
59
61
67
71
73
79
83
89
97
试比较以下两段代码:
1 | for n in range(2, 100): |
1 | for n in range(2, 100): |
2
3
5
5
5
7
7
7
7
7
9
11
11
11
...
97
97
97
97
99
pass 语句什么都不干:
再比如,1
2def someFunction():
pass
又或者:
1 | for i in range(100): |
换个角度去理解的话可能更清楚:pass 这个语句更多是给写程序的人用的。当你写程序的时候,你可以用 pass 占位,而后先写别的部分,过后再回来补充本来应该写在 pass 所在位置的那一段代码。
写嵌套的判断语句或循环语句的时候,最常用 pass,因为写嵌套挺费脑子的,一不小心就弄乱了。所以,经常需要先用 pass 占位,而后逐一突破。
while 循环
今天,在绝大多数编程语言中,都提供两种循环结构:
- Collection-controlled loops(以集合为基础的循环)
- Condition-controlled loops(以条件为基础的循环)
之前的 for ... in ... 就是 Collection-controlled loops;而在 Python 中提供的 Condition-controlled loops 是 while 循环。
while 循环的格式如下:
1 | while expression: |
输出 1000 以内的斐波那契数列的程序如下:
1 | n = 1000 |
0 1 1 2 3 5 8 13 21 34 55 89 144 233 377 610 987
for 和 while 的区别在哪里?什么时候应该用哪个?
for 更适合处理序列类型的数据(Sequence Type)的迭代,比如处理字符串中的每一个字符,比如把 range() 返回的数列当作某种序列类型的索引。
while 更为灵活,因为它后面只需要接上一个逻辑表达式即可。
一个投骰子赌大小的游戏
虽然还不可能随心所欲写程序,但是,你现在具备了起码的 “阅读能力”。有了以上大概的介绍,你也许可以读懂一些代码了 —— 它们在你眼里再也不是天书了……
以下是一个让用户和程序玩掷骰子赌大小的程序。规则如下:
- 每次计算机随机生成一个
2... 12之间的整数,用来模拟机器人投两个骰子的情况;- 机器人和用户的起始资金都是 10 个硬币
- 要求用户猜大小:
- 用户输入
b代表 “大”;- 用户输入
s代表 “小”;- 用户输入
q代表 “退出”;- 用户的输入和随机产生的数字比较有以下几种情况:
- 随机数小于
7,用户猜小,用户赢;- 随机数小于
7,用户猜大,用户输;- 随机数等于
7,用户无论猜大还是猜小,结局平,不输不赢;- 随机数大于
7,用户猜小,用户输;- 随机数大于
7,用户猜大,用户赢;- 游戏结束条件:
- 机器人和用户,若任意一方硬币数量为
0,则游戏结束;- 用户输入了
q主动终止游戏。
1 | from random import randrange |
总结
有控制流,才能算得上是程序。
- 只处理一种情况,用
if ...- 处理
True/False两种情况,用if ... else ...- 处理多种情况,用
if ... elif ... elif ... else ...- 迭代有序数据类型,用
for ... in ...,如果需要处理没有break发生的情况,用for ... else ...- 其它循环,用
while ...- 与循环相关的语句还有
continue、break、pass- 函数从控制流角度去看其实就是子程序
函数
函数,实际上是可被调用的完整的程序。它具备输入、处理、输出的功能。又因为它经常在主程序里被调用,所以它总是更像是个子程序。
了解一个函数,无非是要了解它的两个方面:
- 它的输入是怎么构成的(都有哪些参数?如何指定?);
- 以及它的输出是什么(返回值究竟是什么?)……
从这个角度看,牛,对人类来说就是个函数,它吃的是草,挤出来的是奶…… 开玩笑了。
在我们使用函数的过程中,我们常常有意忽略它的内部如何完成从输入到输出之间的处理过程 —— 这就好像我们平日里用灯泡一样,大多数情况下,我们只要知道开关的使用方法就够了 —— 至于为什么按到这个方向上灯会亮,为什么按到另外一个方向上灯会灭,并不是我们作为用户必须关心的事情……
当然,如果你是设计开关的人就不一样了,你必须知道其中的运作原理;但是,最终,你还是希望你的用户用最简单方便的操作界面,而不是必须搞懂所有原理才能够使用你所设计的产品……
当我们用 Python 编程的时候,更多的情况下,我们只不过是在使用别人已经写好的函数,或者用更专业一点的词藻,叫做 “已完好封装的函数”。而我们所需要做的事情(所谓的 “学习使用函数”),其实只不过是 “通过阅读产品说明书了解如何使用产品” 而已,真的没多神秘……
注意
这一章的核心目的,不是让你学会如何写函数;而是通过一些例子,让你大抵上学会 “如何阅读官方文档中关于函数的使用说明”。也请注意之前的那个词:“大抵上”,所以千万别怕自己最初的时候理解不全面。
另外,这一章中用来举例的函数,全部来自于同一个官方文档页面,Built-in Functions:
示例 print()
基本的使用方法
print() 是初学者最常遇到的函数 —— 姑且不说是不是最常用到的。
它最基本的作用就是把传递给它的值输出到屏幕上,如果不给它任何参数,那么它就输出一个空行:
1 | print('line 1st') |
line 1st
line 2nd
line 4th
你也可以向它传递多个参数,参数之间用 , 分开,它就会把那些值逐个输出到屏幕,每个值之间默认用空格分开。
1 | print('Hello,', 'jack', 'mike', '...', 'and all you guys!') |
Hello, jack mike ... and all you guys!
当我们想把变量或者表达式的值插入字符串中的时候,可以用 f-string:
1 | name = 'Ann' |
Ann is 22 years old.
但这并不是 print() 这个函数的功能,这实际上是 f-string 的功能,f-string 中用花括号 {} 括起来的部分是表达式,最终转换成字符串的时候,那些表达式的值(而不是变量或者表达式本身)会被插入相应的位置……
1 | name = 'Ann' |
'Ann is 22 years old.'
所以,print(f'{name} is {age} years old.') 这一句中,函数 print() 完成的还是它最基本的功能:给它什么,它就把什么输出到屏幕上。
print() 的官方文档说明
以下,是 print() 这个函数的官方文档:

最必须读懂的部分,就是这一行:
print(*object, sep=' ', end='\n', file=sys.stdout, flush=False)[1]
先只注意那些有着 = 的参数,sep=' '、end='\n'、file=sys.stdout,和 flush=False。
这其中,先关注这三个 sep=' '、end='\n'、file=sys.stdout:
sep=' ':接收多个参数之后,输出时,分隔符号默认为空格,' ';end='\n':输出行的末尾默认是换行符号'\n';file=sys.stdout:默认的输出对象是sys.stdout(即,用户正在使用的屏幕)……
也就是说,这个函数中有若干个具有默认值的参数,即便我们在调用这个函数的时候,就算没有指定它们,它们也存在于此。
即,当我们调用 print('Hello', 'world!') 的时候,相当于我们调用的是 print('Hello', 'world!', sep=' ', end='\n', file=sys.stdout, flush=False)
1 | import sys # 如果没有这一行,代码会报错 |
Hello world!
Hello world!
Hello-world! Hello~world!
Hello
world!
很多人只看各种教材、教程,却从来不去翻阅官方文档 —— 到最后非常吃亏。只不过是多花一点点的功夫而已,看过之后,就会知道:原来 print() 这个函数是可以往文件里写数据的,只要指定 file 这个参数为一个已经打开的文件对象就可以了(真的有很多人完全不知道)……
另外,现在可以说清楚了:
print()这个函数的返回值是None—— 注意,它向屏幕输出的内容,与print()这个函数的返回值不是一回事。
做为例子,看看 print(print(1)) 这个语句 —— print() 这个函数被调用了两次,第一次是 print(1),它向屏幕输出了一次,完整的输出值实际上是 str(1) + '\n',而后返回一个值,None;而第二次调用 print(),这相当于是向屏幕输出这个 None:
1 | print(print(1)) |
1
None
“看说明书” 就是这样,全都看了,真不一定全部看懂,但看总是比不看强,因为总是有能看懂的部分……
关键字参数
在 Python 中,函数的参数,有两种:
- 位置参数(Positional Arguments,在官方文档里常被缩写为 arg)
- 关键字参数(Keyword Arguments,在官方文档里常被缩写为 kwarg)
在函数定义中,带有 = 的,即,已为其设定了默认值的参数,叫做 Keyword Arguments,其它的是 Positional Arguments。
在调用有 Keyword Arguments 的函数之时,如若不提供这些参数,那么参数在执行时,启用的是它在定义的时候为那些 Keyword Arguments 所设定的默认值;如若提供了这些参数的值,那么参数在执行的时候,启用的是接收到的相应值。
比如,sorted() 函数,它的定义如下:
sorted(iterable, *, key=None, reverse=False)
现在先只关注它的 Keyword Arguments,reverse:
1 | from IPython.core.interactiveshell import InteractiveShell |
['a', 'b', 'c', 'd']
['d', 'c', 'b', 'a']
位置参数
位置参数,顾名思义,是 “由位置决定其值的参数”。拿 divmod() 为例,它的官方文档是这样写的:

它接收且必须接收两个参数。
- 当你调用这个函数的时候,括号里写的第一个参数,是被除数,第二个参数是除数 —— 此为该函数的输入;
- 而它的返回值,是一个元组(Tuple,至于这是什么东西,后面讲清楚),其中包括两个值,第一个是商,第二个是余 —— 此为该函数的输出。
作为 “这个函数的用户”,你不能(事实上也没必要)调换这两个参数的意义。因为,根据定义,被传递的值的意义就是由参数的位置决定的。
1 | from IPython.core.interactiveshell import InteractiveShell |
(3, 2)
3
2
(0, 3)
0
3
可选位置参数
有些函数,如 pow(),有可选的位置参数(Optional Positional Arguments)。

于是,pow() 有两种用法,各有不同的结果:
pow(x, y)—— 返回值是x ** ypow(x, y, z)—— 返回值是x ** y % z
1 | from IPython.core.interactiveshell import InteractiveShell |
8
0
注意 pow() 函数定义部分中,圆括号内的方括号 [, z] —— 这是非常严谨的标注,如果没有 z,那么那个逗号 , 就是没必要的。
看看 exec() 的官方文档(先别管这个函数干嘛用的),注意函数定义中的两个嵌套的方括号:

这些方括号的意思是说:
- 没在方括号里的
object是不可或缺的参数,调用时必须提供;- 可以有第二个参数,第二个参数会被接收为
globals;- 在有第二个参数的情况下,第三个参数会被接收为
locals;- 但是,你没办法在不指定
globals这个位置参数的情况下指定locals……
可接收很多值的位置参数
再回头看看 print(),它的第一个位置参数,object 前面是有个星号的:*object, ...。
对函数的用户来说,这说明,这个位置可以接收很多个参数(或者说,这个位置可以接收一个列表或者元组)。
再仔细看看 print(),它只有一个位置参数:

因为位置决定了值的定义,一般来说,一个函数里最多只有一个这种可以接收很多值的位置参数 —— 否则如何获知谁是谁呢?
如果与此同时,还有若干个位置参数,那么,能够接收很多值的位置参数只能放置最后,就好像 max() 函数那样:

Class 也是函数
虽然你现在还不一定知道 Class 究竟是什么,但在阅读官方文档的时候,遇到一些内建函数前面写着 Class,比如 Class bool([x]),千万别奇怪,因为 Class 本质上来看就是一种特殊类型的函数,也就是说,它也是函数:

1 | from IPython.core.interactiveshell import InteractiveShell |
False
True
True
False
False
总结
本章需要(大致)了解的重点如下,其实很简单:
- 你可以把函数当作一个产品,而你自己是这个产品的用户;
- 既然你是产品的用户,你要养成好习惯,一定要亲自阅读产品说明书;
- 调用函数的时候,注意可选位置参数的使用方法和关键字参数的默认值;
- 函数定义部分,注意两个符号就行了,
[]和=;- 所有的函数都有返回值,即便它内部不指定返回值,也有一个默认返回值:
None;- 另外,一定要耐心阅读该函数在使用的时候需要注意什么 —— 产品说明书的主要作用就在这里……
知道这些就很好了!
这就好像你拿着一张地图,不可能一下子掌握其中所有的细节,但花几分钟搞清楚 “图例”(Legend)部分总是可以的,知道什么样的线标示的是公交车,什么样的线标示的是地铁,什么样的线标示的是桥梁,然后知道上北下南左西右东 —— 这之后,就可以开始慢慢研究地图了……
为了学会使用 Python,你以后最常访问的页面一定是这个:
对了,还有就是,在这一章之后,你已经基本上 “精通” 了 print() 这个函数的用法。
脚注
(2019.02.14)[1]:print() 函数的官方文档里,sep='' 肯定是 sep=' ' 的笔误 —— 可以用以下代码验证:
1 | print('a', 'b', sep='') |
(2019.03.16)有读者提醒:https://github.com/selfteaching/the-craft-of-selfteaching/issues/111
而现在(2019.03.16)复制粘贴文档中的
sep=' ',会发现是有空格的。这是改了么?
我回去查看了一下 2019.02.13 我提交的 bug track:https://bugs.python.org/issue35986,结论是 “人家没问题,是我自己的浏览器字体设置有问题”……
然而,我决定将这段文字保留在此书里,以便人们看到 “平日里软件维护是什么样的” —— 作为一个实例放在这里,很好。
字符串
在任何一本编程书籍之中,关于字符串的内容总是很长 —— 就好像每本英语语法书中,关于动词的内容总是占全部内容的至少三分之二。这也没什么办法,因为处理字符串是计算机程序中最普遍的需求 —— 因为程序的主要功能就是完成人机交互,人们所用的就是字符串而不是二进制数字。
在计算机里,所有的东西最终都要被转换成数值。又由于计算机靠的是电路,所以,最终只能处理 1 和 0,于是,最基本的数值是二进制;于是,连整数、浮点数字,都要最终转换成二进制数值。这就是为什么在所有编程语言中 1.1 + 2.2 并不是你所想象的 3.3 的原因。
1 | 1.1 + 2.2 |
3.3000000000000003
因为最终所有的值都要转换成二进制 —— 这时候,小数的精度就有损耗,多次浮点数字转换成二进制相互运算之后再从二进制转换为十进制之后返回的结果,精度损耗就更大了。因此,在计算机上,浮点数字的精度总有极限。有兴趣进一步可以看看关于 decimal 模块的文档。
字符串也一样。一个字符串由 0 个字符或者多个字符构成,它最终也要被转换成数值,再进一步被转换成二进制数值。空字符串的值是 None,即便是这个 None —— 也最终还是要被转换成二进制的 0。
字符码表的转换
很久以前,计算机的中央处理器最多只能够处理 8 位二进制数值,所以,那时候的计算机只能处理 256 个字符,即,28 个字符。那个时候计算机所使用的码表叫 ASCII。现在计算机的中央处理器,大多是 64 位的,所以可以使用 264 容量的码表,叫做 Unicode。随着多年的收集,2018 年 6 月 5 日公布的 11.0.0 版本已经包含了 13 万个字符 —— 突破 10 万字符是在 2005 年[1]。
把单个字符转换成码值的函数是 ord(),它只接收单个字符,否则会报错;它返回该字符的 unicode 编码。与 ord() 相对的函数是 chr(),它接收且只接收一个整数作为参数,而后返回相应的字符。ord() 接收多个字符的话会报错。
1 | from IPython.core.interactiveshell import InteractiveShell |
97
'z'
27653
'挊'
字符串的标示
标示一个字符串,有 4 种方式,用单引号、用双引号,用三个单引号或者三个双引号:
1 | 'Simple is better than complex.' # 用单引号 |
'Simple is better than complex.'
1 | "Simple is better than complex." # 用双引号 |
'Simple is better than complex.'
1 | # 用三个单引号。注意输出结果中的 \n |
'\nSimple is better than complex.\nComplex is better than complicated.\n'
1 | #用三个双引号。注意输出结果中的 \n |
'\nSimple is better than complex.\nComplex is better than complicated.\n'
1 | print( |
Simple is better than complex.
Complex is better than complicated.
字符串与数值之间的转换
由数字构成的字符串,可以被转换成数值,转换整数用 int(),转换浮点数字用 float()。
与之相对,用 str(),可以将数值转换成字符串类型。
注意,int() 在接收字符串为参数的时候,只能做整数转换。下面代码最后一行会报错:
1 | from IPython.core.interactiveshell import InteractiveShell |
3
3.0
'3.1415926'
input() 这个内建函数的功能是接收用户的键盘输入,而后将其作为字符串返回。它可以接收一个字符串作为参数,在接收用户键盘输入之前,会把这个参数输出到屏幕,作为给用户的提示语。这个参数是可选参数,直接写 input(),即,没有提供参数,那么它在要求用户输入的时候,就没有提示语。
以下代码会报错,因为 age < 18 不是合法的逻辑表达式,因为 age 是由 input() 传递过来的字符串;于是,它不是数字,那么它不可以与数字比较……
1 | age = input('Please tell me your age: ') |
Please tell me your age: 19
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-9-0573fe379e83> in <module>
1 age = input('Please tell me your age: ')
----> 2 if age < 18:
3 print('I can not sell you drinks...')
4 else:
5 print('Have a nice drink!')
TypeError: '<' not supported between instances of 'str' and 'int'
要改成这样才可能行:
为什么是可能行而不是一定行?如果用户 input 键盘输入的是 eighteen 或者 十八 等,依然会导致 int() 失败并得到 ValueError 的报错。用户输入的不可控,可能会导致千奇百怪的报错。但在这里,我们先简化处理,在引导语中加入一个正确的示例并默认用户会按引导语正确输入。
1 | age = int(input('''Please tell me your age: |
Please tell me your age: 19
Have a nice drink!
注意:如果你用来浏览当前 .ipynb 文件的是那个桌面 App Nteract,它目前不支持 input() 这个函数的调用……
转义符
有一个重要的字符,叫做 “转义符”,\,也有的地方把它称为 “脱字符”,因为它的英文原文是 Escaping Character。它本身不被当作字符,你要想在字符串里含有这个字符,得这样写 \\:
1 | '\\' |
'\\'
1 | '\' |
File "<ipython-input-10-d44a383620ab>", line 1
'\'
^
SyntaxError: EOL while scanning string literal
上面这一行报错信息是 SyntaxError: EOL while scanning string literal。这是因为 \' 表示的是单引号字符 '(Literal)—— 是可被输出到屏幕的 ',而不是用来标示字符串的那个 ' —— 别急,无论哪个初学者第一次读到前面的句子都觉得有点莫名其妙…… —— 于是,Python 编译器扫描这个 “字符串” 的时候,还没找到标示字符串末尾的另外一个 ' 的时候就读到了 EOL(End Of Line)。
如果你想输出这么个字符串,He said, it's fine.,如果用双引号扩起来 " 倒没啥问题,但是如果用单引号扩起来就麻烦了,因为编译器会把 it 后面的那个单引号 ' 当作字符串结尾。
1 | 'He said, it's fine.' |
File "<ipython-input-11-2bcf2ca6dd95>", line 1
'He said, it's fine.'
^
SyntaxError: invalid syntax
于是你就得用转义符 \:
1 | from IPython.core.interactiveshell import InteractiveShell |
"He said, it's fine."
"He said, it's fine."
"He said, it's fine."
转义符号 \ 的另外两个常用形式是和 t、n 连起来用,\t 代表制表符(就是用 TAB ⇥ 键敲出来的东西),\n 代表换行符(就是用 Enter ⏎ 敲出来的东西)。
由于历史原因,Linux/Mac/Windows 操作系统中,换行符号的使用各不相同。Unix 类操作系统(包括现在的 MacOS),用的是 \n;Windows 用的是 \r\n,早期苹果公司的 Macintosh 用的是 \r(参见 Wikipedia: Newline)。
所以,一个字符串,有两种形式,raw 和 presentation,在后者中,\t 被转换成制表符,\n 被转换成换行。
在写程序的过程中,我们在代码中写的是 raw,而例如当我们调用 print() 将字符串输出到屏幕上时,是 presentation:
1 | s = "He said, it\'s fine." # raw |
He said, it's fine.
以后有时间去看看这两个内建函数,能了解更多细节:
- ascii(object) https://docs.python.org/3/library/functions.html#ascii
- repr(object) https://docs.python.org/3/library/functions.html#repr
字符串的操作符
字符串可以用空格 ' ' 或者 + 拼接:
1 | 'Hey!' + ' ' + 'You!' # 使用操作符 + |
'Hey! You!'
1 | 'Hey!' 'You!' # 空格与 + 的作用是相同的。 |
'Hey!You!'
字符串还可以与整数倍操作符 * 操作,'Ha' * 3 的意思是说,把字符串 'Ha' 复制三遍:
1 | 'Ha' * 3 |
'HaHaHa'
1 | '3.14' * 3 |
'3.143.143.14'
字符串还可以用 in 和 not in 操作符 —— 看看某个字符或者字符串是否被包含在某个字符串中,返回的是布尔值:
1 | 'o' in 'Hey, You!' |
True
字符串的索引
字符串是由一系列的字符构成的。在 Python 当中,有一个容器(Container)的概念,这个概念前面提到过,后面还会深入讲解。现在需要知道的是,字符串是容器的一种;容器可分为两种,有序的和无序的 —— 字符串属于有序容器。
字符串里的每个字符,对应着一个从 0 开始的索引。比较有趣的是,索引可以是负数:
| 0 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| P | y | t | h | o | n |
| -6 | -5 | -4 | -3 | -2 | -1 |
1 | s = 'Python' |
0 P
1 y
2 t
3 h
4 o
5 n
对于有序容器中的元素 —— 字符串就是字符的有序容器 —— 由于它们是有索引的,所以我们可以根据索引提取容器中的值,你可以把 [] 当作是有序容器的操作符之一,我们姑且将其称为 “索引操作符”。注意以下代码第 3 行中,s 后面的 [],以及里面的变量 i:
1 | s = 'Python' |
P
y
t
h
o
n
我们可以使用索引操作符根据索引**提取*字符串这个有序容器中的一个或多个元素*,即,其中的字符或字符串。这个 “提取” 的动作有个专门的术语,叫做 “Slicing”(切片)。索引操作符 [] 中可以有一个、两个或者三个整数参数,如果有两个参数,需要用 : 隔开。它最终可以写成以下 4 种形式:
s[index]—— 返回索引值为index的那个字符s[start:]—— 返回从索引值为start开始一直到字符串末尾的所有字符s[start:stop]—— 返回从索引值为start开始一直到索引值为stop的那个字符之前的所有字符s[:stop]—— 返回从字符串开头一直到索引值为stop的那个字符之前的所有字符s[start:stop:step]—— 返回从索引值为start开始一直到索引值为stop的那个字符之前的,以step为步长提取的所有字符
提醒:无论是 range(1,2),或者 random.randrange(100, 1000) 又或者 s[start:stop] 都有一个相似的规律,包含左侧的 1, 100, start,不包含右侧的 2, 1000, stop。
1 | from IPython.core.interactiveshell import InteractiveShell |
'y'
'thon'
'tho'
'Pytho'
'yh'
处理字符串的内建函数
Python 内建函数中,把字符串当做处理对象的有:ord()、input()、int()、float()、len()、print()。再次注意,ord() 只接收单个字符为参数。
1 | from IPython.core.interactiveshell import InteractiveShell |
10
9
13
'A'
请照抄一遍这个数字 3.14: 3.14
3
28.26
4
3.143.143.14
处理字符串的 Method
在 Python 中,字符串是一个对象 —— 更准确地讲,是 str 类(Class str)的对象。
第一部分尚未读完的你,暂时不用了解对象究竟是什么;只需要知道的是,一个对象的内部有很多函数…… 这些写在对象内部的函数,有个专门的名称,类的方法(Method)。问题在于,在讲解编程的内容里,“方法” 这个词(比如,处理数值的方法是……)随处可见;所以,为了避免歧义,以后的文字里,提到 “类的方法” 的时候,直接用 Method 这个英文单词……
字符串有很多可以调用的 Methods。以下介绍的 str Methods,在官方文档 “Text Sequence Type“ 中都可以找到。
调用 str 类的 Methods 是使用 . 这个符号,比如:
1 | 'Python'.upper() |
大小写转换
转换字符串大小写的是 str.upper()、str.lower() 和 str.swapcase(),以及 str.casefold();另外,还有专门针对行首字母大写的 str.capitalize() 和针对每个词的首字母大写的 str.title():
1 | from IPython.core.interactiveshell import InteractiveShell |
'NOW IS BETTER THAN NEVER.'
'now is better than never.'
1 | from IPython.core.interactiveshell import InteractiveShell |
'ss'
2
'ß'
1
'IJ'
'ij'
'ij'
1
1 | from IPython.core.interactiveshell import InteractiveShell |
'Now is better than never.'
'Now Is Better Than Never.'
1 | s = 'Now is better than never.' |
'nOW IS BETTER THAN NEVER.'
'Now Is Better Than Never.'
'nOW iS bETTER tHAN nEVER.'
另外,还有个 str.encode() 在处理非英文字符串(比如中文)的时候,经常会用到:
1 | # str.encode(encoding="utf-8", errors="strict") |
b'\xe7\xae\x80\xe5\x8d\x95\xe4\xbc\x98\xe4\xba\x8e\xe5\xa4\x8d\xe6\x9d\x82\xe3\x80\x82'
搜索与替换
让我们从 str.count() 这个搜寻子字符串出现次数的 Method(即,str 这个 Class 中定义的函数)开始。
官方文档是这么写的:
str.count(sub[,start[,end]])
下面的函数说明加了默认值,以便初次阅读更容易理解:
str.count(sub [,start=0[, end=len(str)]])
这里的方括号 [] 表示该参数可选;方括号里再次嵌套了一个方括号,这个意思是说,在这个可选参数 start 出现的情况下,还可以再有一个可选参数 end;
而 = 表示该参数有个默认值。上述这段说明如果你感到熟悉的话,说明前面的内容确实阅读到位了…… 与大量 “前置引用” 相伴随的是知识点的重复出现。
- 只给定
sub一个参数的话,于是从第一个字符开始搜索到字符串结束;- 如果,随后给定了一个可选参数的话,那么它是
start,于是从start开始,搜索到字符串结束;- 如果
start之后还有参数的话,那么它是end;于是从start开始,搜索到end - 1结束(即不包含索引值为end的那个字符)。返回值为字符串中
sub出现的次数。
注意:字符串中第一个字符的索引值是 0。
1 | from IPython.core.interactiveshell import InteractiveShell |
4
3
1
以下是 str 的搜索与替换的 Methods:str.find(), str.rfind(), str.index() 的示例:
1 | from IPython.core.interactiveshell import InteractiveShell |
Example of str.find():
2
24
-1
Example of str.rfind():
56
56
-1
Example of str.index():
2
56
str.startswith() 和 str.endswith() 是用来判断一个字符串是否以某个子字符串起始或者结束的:
1 | s = """Simple is better than complex. |
s.lower().startswith('S'): False
s.lower().startswith('b', 10): True
s.lower().startswith('e', 11, 20): True
s.lower().endswith('.'): True
s.lower().endswith('.', 10): True
s.lower().endswith('.', 10, 20): False
为了找到位置而进行搜索之前,你可能经常需要事先确认需要寻找的字符串在寻找对象中是否存在,这个时候,可以用 in 操作符:
1 | s = """Simple is better than complex. |
True
能搜索,就应该能替换 —— str.replace(),它的函数说明是这样的:
str.replace(old, new[, count])
用 new 替换 old,替换 count 个实例(实例:exmpale,每次处理的对象就是实例,即具体的操作对象),其中,count 这个参数是可选的。
1 | s = """Simple is better than complex. |
s.lower().replace('mp', '[ ]', 2):
si[ ]le is better than co[ ]lex.
complex is better than complicated.
另外,还有个专门替换 TAB(\t)的 Method,
str.expandtabs( tabsize=8)
它的作用非常简单,就是把字符串中的 TAB(\t)替换成空格,默认是替换成 8 个空格 —— 当然你也可以指定究竟替换成几个空格
1 | from IPython.core.interactiveshell import InteractiveShell |
"Special cases aren't special enough to break the rules."
"Special cases aren't special enough to break the rules."
去除子字符
str.strip([chars])
它最常用的场景是去除一个字符串首尾的所有空白,包括空格、TAB、换行符等等。
1 | from IPython.core.interactiveshell import InteractiveShell |
'\r \t Simple is better than complex. \t \n'
'Simple is better than complex.'
但是,如果给定了一个字符串作为参数,那么参数字符串中的所有字母都会被当做需要从首尾剔除的对象,直到新的首尾字母不包含在参数中,就会停止剔除:
1 | from IPython.core.interactiveshell import InteractiveShell |
'Simple is better than complex.'
'mple is better than comple'
' is better than co'
还可以只对左侧处理,str.lstrip() 或者只对右侧处理,str.rstrip()
1 | from IPython.core.interactiveshell import InteractiveShell |
'Simple is better than complex.'
'mple is better than complex.'
' is better than complex.'
1 | from IPython.core.interactiveshell import InteractiveShell |
'Simple is better than complex.'
'Simple is better than comple'
'Simple is better than co'
拆分字符串
在计算机里,数据一般保存在文件之中。计算机擅长处理的是 “格式化数据”,即,这些数据按照一定的格式排列 —— 电子表格、数据库,就是一种保存方式。Microsoft 的 Excel 和 Apple 的 Numbers,都可以将表格导出为 .csv 文件。这是文本文件,里面的每一行可能由多个数据构成,数据之间用 ,(或 ;、\t)分隔:
1 | Name,Age,Location |
文本文件中的这样一段内容,被读进来之后,保存在某个变量,那么,那个变量的值长成这个样子:
'Name,Age,Location\nJohn,18,New York\nMike,22,San Francisco\nJanny,25,Miami\nSunny,21,Shanghai'
我们可以对这样的字符串进行很多操作,最常用的比如,str.splitlines(), str.split();还有个 str.partition(),有空的人可以去官方文档看看说明。
str.splitlines() 返回的是个列表(List)—— 这又是一个前面曾简要提起过,但会在后面的章节才能详细讲解的概念 —— 由被拆分的每一行作为其中的元素。
1 | from IPython.core.interactiveshell import InteractiveShell |
'Name,Age,Location\nJohn,18,New York\nMike,22,San Francisco\nJanny,25,Miami\nSunny,21,Shanghai'
['Name,Age,Location',
'John,18,New York',
'Mike,22,San Francisco',
'Janny,25,Miami',
'Sunny,21,Shanghai']
str.split(), 是将一个字符串,根据分隔符进行拆分:
str.split(sep=None, maxsplit=-1)
1 | from IPython.core.interactiveshell import InteractiveShell |
'Mike,22,San Francisco'
['Mike,22,San', 'Francisco']
['Mike', '22', 'San Francisco']
['Mike', '22', 'San Francisco']
['Mike', '22,San Francisco']
['Mike,22,San Francisco']
['Mike', '22', 'San Francisco']
拼接字符串
str.join() 是将来非常常用的,它的官方文档说明却很少:
str.join(_iterable_)Return a string which is the concatenation of the strings in iterable. A
TypeErrorwill be raised if there are any non-string values in iterable, includingbytesobjects. The separator between elements is the string providing this method.
它接收的参数是 iterable,虽然你还没办法知道 iterable 究竟是什么,但这个 Method 的例子貌似可以看懂(可能你会产生 “那个方括号究竟是干什么的” 的疑问,也可能对前面章节提到的列表还有印象):
1 | s = '' |
'Python'
字符串排版
将字符串居中放置 —— 前提是设定整行的长度:
str.center(width[, fillchar])
注意,第 2 个参数可选,且只接收单个字符 —— char 是 character 的缩写。
1 | from IPython.core.interactiveshell import InteractiveShell |
' Sparse Is Better Than Dense! '
'================Sparse Is Better Than Dense!================'
'Sparse Is Better Than Dense!'
' Sparse Is Better Than Dense!'
'................................Sparse Is Better Than Dense!'
将字符串靠左或者靠右对齐放置:
str.ljust(width)str.rjust(width)
另外,还有个字符串 Method 是,将字符串转换成左侧由 0 填充的指定长度字符串。例如,这在批量生成文件名的时候就很有用……
1 | for i in range(1, 11): |
001.mp3
002.mp3
003.mp3
004.mp3
005.mp3
006.mp3
007.mp3
008.mp3
009.mp3
010.mp3
格式化字符串
所谓对字符串进行格式化,指的是将特定变量插入字符串特定位置的过程。常用的 Methods 有两个,一个是 str.format(),另外一个是 f-string。
使用 str.format()
这个 Method 的官方文档说明,你现在是死活看不懂的:
str.format(*args, **kwargs)
参数前面多了个 *…… 没办法,现在讲不清楚,讲了也听不明白…… 先跳过,以下只关注怎么用这个 Method。
它的作用是:
- 在一个字符串中,插入一个或者多个占位符 —— 用大括号
{}括起来;- 而后将
str.format()相应的参数,依次插入占位符中;
占位符中可以使用由零开始的索引。
1 | from IPython.core.interactiveshell import InteractiveShell |
'John is 25 years old.'
'Are you John? :-{+}'
'John is a grown up? True'
使用 f-string
f-string 与 str.format() 的功用差不多,只是写法简洁一些 —— 在字符串标示之前加上一个字母 f:
1 | from IPython.core.interactiveshell import InteractiveShell |
'John is 25 years old.'
'John is a grown up? True'
只不过,str.format() 的用法中,索引顺序可以任意指定,于是相对更为灵活,下面的例子只是为了演示参数位置可以任意指定:
1 | name = 'John' |
'25 is John years old.'
字符串属性
字符串还有一系列的 Methods,返回的是布尔值,用来判断字符串的构成属性:
1 | # str.isalnum() |
'1234567890'.isalnum(): True
'abcdefghij'.isalpha(): True
'山巅一寺一壶酒'.isascii(): False
'0.123456789'.isdecimal(): False
'0.123456789'.isdigit(): False
'0.123456789'.isnumeric(): False
'Continue'.islower(): False
'Simple Is Better Than Complex'.isupper(): False
'Simple Is Better Than Complex'.istitle(): True
' '.isprintable(): False
' '.isspace(): True
'for'.isidentifier(): True
总结
这一章节显得相当繁杂。然而,这一章和下一章(关于容器),都是 “用来锻炼自己耐心的好材料”……
不过,若是自己动手整理成一个表格,总结归纳一下这一章节的内容,你就会发现其实没多繁杂,总之就还是那点事,怎么处理字符串?用操作符、用内建函数,用 Methods。只不过,字符串的操作符和数值的操作符不一样 —— 类型不一样,操作符就当然不一样了么!—— 最不一样的地方是,字符串是有序容器的一种,所以,它有索引,所以可以根据索引提取…… 至于剩下的么,就是很常规的了,用函数处理,用 Methods 处理,只不过,Methods 相对多了一点而已。
整理成表格之后,就会发现想要全部记住其实并没多难……
- 为了表格在一屏中可以正确显示,本来应该规规矩矩写
str.xxx,但写成了s.xxx……- 另外,操作那一行,为了分类记忆方便,把
len()和s.join()也放进去了……

“记住” 的方法并不是马上就只盯着表格看…… 正确方法是反复阅读这一章内容中的代码,并逐一运行,查看输出结果;还要顺手改改看看,多多体会。多次之后,再看着表格回忆知识点,直到牢记为止。
为什么数值没有像字符串值这样详细论述?
上一章中,我们概括地讲了各种类型的值的运算。而后并没有继续深入讲解数字的运算,而是直接 “跳” 到了这一章关于字符串的内容。其实,只要一张表格和一个列表就足够了(因为之前零零散散都讲过):
Python 针对数字常用的操作符和内建函数,按照优先级从低到高排列:
| 名称 | 操作 | 结果 | 官方文档链接 |
|---|---|---|---|
| 加 | 1 + 2 |
3 | |
| 减 | 2 - 1 |
1 | |
| 乘 | 3 * 5 |
15 | |
| 除 | 6 / 2 |
3.0 | |
| 商 | 7 // 3 |
2 | |
| 余 | 7 % 3 |
1 | |
| 负 | -6 |
-6 | |
| 正 | +6 |
6 | |
| 绝对值 | abs(-1) |
1 | abs() |
| 转换为整数 | int(3.14) |
3 | int() |
| 转换为浮点数 | float(3) |
3.0 | float() |
| 商余 | divmod(7, 3) |
2, 1 | divmod() |
| 幂 | pow(2, 10) |
1024 | pow() |
| 幂 | 3 ** 2 |
9 |
Python 用来处理数值的内建函数:
abs(n)函数返回参数n的绝对值;int(n)用来将浮点数字n转换成整数;float(n)用来将整数n转换成浮点数字;divmod(n, m)用来计算n除以m,返回两个整数,一个是商,另外一个是余;pow(n, m)用来做乘方运算,返回n的m次方;round(n)返回离浮点数字n最近的那个整数。
Python 做更为复杂的数学计算的模块(Module)是 math module,参阅:
脚注
[1]:请查阅 https://en.wikipedia.org/wiki/Unicode
数据容器
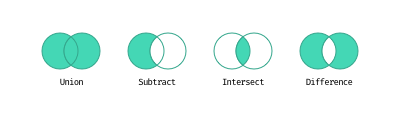
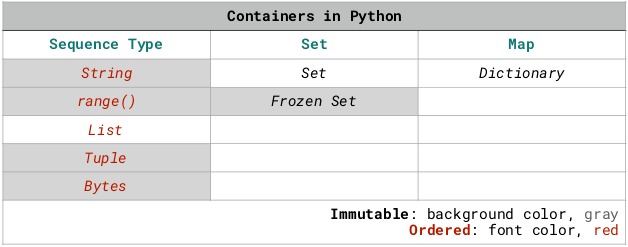
在 Python 中,有个数据容器(Container)的概念。
其中包括字符串、由 range() 函数生成的等差数列、列表(List)、元组(Tuple)、集合(Set)、字典(Dictionary)。
这些容器,各有各的用处。其中又分为可变容器(Mutable)和不可变容器(Immutable)。可变的有列表、集合、字典;不可变的有字符串、range() 生成的等差数列、元组。集合,又分为 Set 和 Frozen Set;其中,Set 是可变的,Frozen Set 是不可变的。
字符串、由 range() 函数生成的等差数列、列表、元组是有序类型(Sequence Type),而集合与字典是无序的。
另外,集合没有重合元素。
迭代(Iterate)
数据容器里的元素是可以被迭代的(Iterable),它们其中包含的元素,可以被逐个访问,以便被处理。
对于数据容器,有一个操作符,in,用来判断某个元素是否属于某个容器。
由于数据容器的可迭代性,再加上这个操作符 in,在 Python 语言里写循环格外容易且方便(以字符串这个字符的容器作为例子):
1 | for c in 'Python': |
P
y
t
h
o
n
在 Python 出现之前,想要完成这样一个访问字符串中的每一个字符的循环,大抵上应该是这样的(比如 C 语言):
1 | # Written in C |
在 Python 中,简单的 for 循环,只需要指定一个次数就可以了,因为有 range() 这个函数:
1 | for i in range(10): |
0
1
2
3
4
5
6
7
8
9
即便是用比 C 更为 “现代” 一点的 JavaScript,也大抵上应该是这样的:
1 | var i; |
当然,有时候我们也需要比较复杂的计数器,不过,Python 也不只有 for 循环,还有 while 循环,在必要的时候可以写复杂的计数器。
列表(List)
列表和字符串一样,是个有序类型(Sequence Type)的容器,其中包含着有索引编号的元素。
列表中的元素可以是不同类型。不过,在解决现实问题的时候,我们总是倾向于创建由同一个类型的数据构成的列表。遇到由不同类型数据构成的列表,我们更可能做的是想办法把不同类型的数据分门别类地拆分出来,整理清楚 —— 这种工作甚至有个专门的名称与之关联:数据清洗。
列表的生成
生成一个列表,有以下几种方式:
1 | a_list = [] |
1 | a_list = [] |
[1, 2] has a length of 2.
[1, 2, 3, 4, 5, 6, 7, 8, 11] has a length of 9.
[1, 2, 4, 8, 16, 32, 64, 128] has a length of 8.
这最后一种方式颇为神奇:
1 | [2**x for x in range(8)] |
这种做法,叫做 List Comprehension。
Comprehend 这个词的意思除了 “理解” 之外,还有另外一个意思,就是 “包括、囊括” —— 这样的话,你就大概能理解这种做法为什么被称作 List Comprehension 了。中文翻译中,怎么翻译的都有,“列表生成器”、“列表生成式” 等等,都挺好。但是,被翻译成 “列表解析器”,就不太好了,给人的感觉是操作反了……
List comprehension 可以嵌套使用 for,甚至可以加上条件 if。官方文档里有个例子,是用来把两个元素并不完全相同的列表去同后拼成一个列表(下面稍作了改写):
1 | import random |
a_list comprehends 10 random numbers: [52, 34, 7, 96, 33, 79, 95, 18, 37, 46]
... and it has 5 even numbers: [52, 34, 96, 18, 46]
列表的操作符
列表的操作符和字符串一样,因为它们都是有序容器。列表的操作符有:
- 拼接:
+(与字符串不一样的地方是,不能用空格' '了)- 复制:
*- 逻辑运算:
in和not in,<、<=、>、>=、!=、==
而后两个列表也和两个字符串一样,可以被比较,即,可以进行逻辑运算;比较方式也跟字符串一样,从两个列表各自的第一个元素开始逐个比较,“一旦决出胜负马上停止”:
1 | from IPython.core.interactiveshell import InteractiveShell |
[1, 2, 3, 4, 5, 6, 4, 5, 6, 4, 5, 6]
True
False
根据索引提取列表元素
列表当然也可以根据索引操作,但由于列表是可变序列,所以,不仅可以提取,还可以删除,甚至替换。
1 | import random |
[77, 66, 79]
[77, 66, 79, 'L', 'Z', 'R', 77, 66, 79, 77, 66, 79]
L
[77, 66, 79, 'L', 'Z', 'R', 77, 66, 79, 77, 66, 79]
['R', 77, 66, 79, 77, 66, 79]
[77, 66, 79]
[79, 'L', 'Z', 'R']
[77, 66, 79, 'Z', 'R', 77, 66, 79, 77, 66, 79]
[77, 66, 79, 'Z', 'R', 77, 66, 79]
[77, 'a', 79, 2, 'R', 77, 66, 79]
需要注意的地方是:列表(List)是可变序列,而字符串(str)是不可变序列,所以,对字符串来说,虽然也可以根据索引提取,但没办法根据索引删除或者替换。
1 | s = 'Python'[2:5] |
tho
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-7-c9c999709965> in <module>
1 s = 'Python'[2:5]
2 print(s)
----> 3 del s[3] # 这一句会报错
TypeError: 'str' object doesn't support item deletion
之前提到过:
字符串常量(String Literal)是不可变有序容器,所以,虽然字符串也有一些 Methods 可用,但那些 Methods 都不改变它们自身,而是在操作后返回一个值给另外一个变量。
而对于列表这种可变容器,我们可以对它进行操作,结果是它本身被改变了。
1 | s = 'Python' |
Python
['P', 'y', 't', 'h', 'o', 'n']
['P', 'y', 'h', 'o', 'n']
列表可用的内建函数
列表和字符串都是容器,它们可使用的内建函数也其实都是一样的:
len()max()min()
1 | import random |
[89, 84, 85]
['X', 'B', 'X']
[89, 84, 85, 'X', 'B', 'X', 89, 84, 85, 89, 84, 85]
[89, 84, 85, 89, 84, 85, 89, 84, 85]
12
X
B
False
Methods
字符串常量和 range() 都是不可变的(Immutable);而列表则是可变类型(Mutable type),所以,它最起码可以被排序 —— 使用 sort() Method:
1 | import random |
a_list comprehends 10 random numbers:
[98, 9, 95, 15, 80, 70, 98, 82, 88, 46]
the list sorted:
[9, 15, 46, 70, 80, 82, 88, 95, 98, 98]
the list sorted reversely:
[98, 98, 95, 88, 82, 80, 70, 46, 15, 9]
如果列表中的元素全都是由字符串构成的,当然也可以排序:
1 | import random |
a_list comprehends 10 random string elements:
['B', 'U', 'H', 'D', 'C', 'V', 'V', 'Q', 'U', 'P']
the list sorted:
['B', 'C', 'D', 'H', 'P', 'Q', 'U', 'U', 'V', 'V']
the list sorted reversely:
['V', 'V', 'U', 'U', 'Q', 'P', 'H', 'D', 'C', 'B']
b_list comprehends 10 random string elements:
['Nl', 'Mh', 'Ta', 'By', 'Ul', 'Nc', 'Gu', 'Rp', 'Pv', 'Bu']
the sorted:
['Bu', 'By', 'Gu', 'Mh', 'Nc', 'Nl', 'Pv', 'Rp', 'Ta', 'Ul']
the sorted reversely:
['Ul', 'Ta', 'Rp', 'Pv', 'Nl', 'Nc', 'Mh', 'Gu', 'By', 'Bu']
注意:不能乱比较…… 被比较的元素应该是同一类型 —— 所以,不是由同一种数据类型元素构成的列表,不能使用 sort() Method。下面的代码会报错:
1 | a_list = [1, 'a', 'c'] |
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-12-acb9480a455d> in <module>
1 a_list = [1, 'a', 'c']
----> 2 a_list = a_list.sort() # 这一句会报错
TypeError: '<' not supported between instances of 'str' and 'int'
可变序列还有一系列可用的 Methods:a.append(),a.clear(),a.copy(),a.extend(t),a.insert(i,x),a.pop([i]),a.remove(x),a.reverse()……
1 | import random |
[90, 88, 73]
[90, 88, 73, 'T', 'N', 'Y', 90, 88, 73, 90, 88, 73]
[90, 88, 73, 'T', 'N', 'Y', 90, 88, 73, 90, 88, 73, '100']
[90, 88, 73]
[]
[90, 88, 73, 'T', 'N', 'Y', 90, 88, 73, 90, 88, 73, '100']
[90, 88, 73, 'T', 'N', 'Y', 73, 90, 88, 73, '100']
[90, 88, 73, 'T', 'N', 'Y', 90, 88, 73, 90, 88, 73, '100']
[90, 88, 73, 'T', 'N', 'Y', 88, 73, '100']
[90, 88, 73, 'T', 'N', 'Y', 88, 73, '100']
[]
[90, 88, 73, 'T', 'N', 'Y', 90, 88, 73, 90, 88, 73, '100']
[90, 88, 73, 'T', 'N', 'Y', 90, 88, 73, 90, 88, 73, '100']
[90, 'example', 88, 'example', 73, 'T', 'N', 'Y', 90, 88, 73, 90, 88, 73, '100']
[90, 'example', 88, 'example', 73, 'T', 'N', 'Y', 90, 88, 73, 90, 88, 73, '100']
['100', 73, 88, 90, 73, 88, 90, 'Y', 'N', 'T', 73, 'example', 88, 'example', 90]
None
有一个命令、两个 Methods 与删除单个元素相关联,del,a.pop([i]),a.remove(x),请注意它们之间的区别。
1 | import random |
[88, 84, 69]
[88, 'example', 84, 69]
[88, 84, 69]
[88, 84, 69]
[88, 84]
69
[88, 84, 'example', 'example']
[88, 84, 'example']
None
[88, 84]
小结
看起来是个新概念,例子全部读完也很是要花上一段时间,然而,从操作上来看,操作列表和操作字符串的差异并不大,重点在于一个是 Immutable,另外一个是 Mutable,所以,例如像 a.sort(),a.remove() 这样的事,列表能做,字符串不能做 —— 字符串也可以排序,但那是排序之后返回给另外一个变量;而列表可以直接改变自身……
而整理成表格之后呢,理解与记忆真的是零压力:
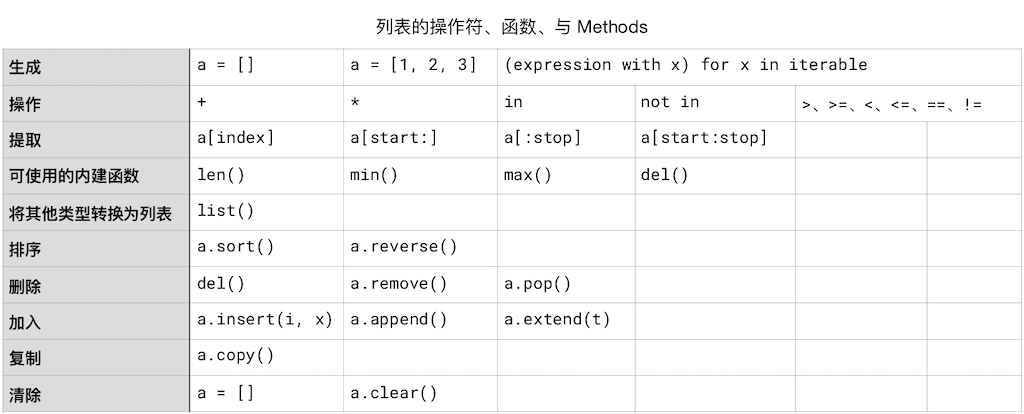
元组(Tuple)
在完整掌握列表的创建与操作之后,再理解元组(Tuple)就容易了,因为它们之间的主要区别只有两个:
- List 是可变有序容器,Tuple 是不可变有序容器。
- List 用方括号标识
[],Tuple 用圆括号 标识()。
创建一个元组的时候,用圆括号:
1 | a = () |
这样就创建了一个空元组。
多个元素之间,用 , 分离。
创建一个含多个元素的元组,可以省略这个括号。
1 | a = 1, 2, 3 # 不建议这种写法 |
(1, 2, 3)
(1, 2, 3)
True
注意:创建单个元素的元组,无论是否使用圆括号,在那唯一的元素后面一定要补上一个逗号 ,:
1 | from IPython.core.interactiveshell import InteractiveShell |
(2,)
2
2
int
(2,)
True
元组是不可变序列,所以,你没办法从里面删除元素。
但是,你可以在末尾追加元素。所以,严格意义上,对元组来讲,“不可变” 的意思是说,“当前已有部分不可变”……
1 | a = 1, |
(1,)
4593032496
(1, 3, 5)
4592468976
初学者总是很好奇 List 和 Tuple 的区别。首先是使用场景,在将来需要更改的时候,创建 List
;在将来不需要更改的时候,创建 Tuple。其次,从计算机的角度来看,Tuple 相对于 List 占用更小的内存。
1 | from IPython.core.interactiveshell import InteractiveShell |
48
80024
90088
等你了解了 Tuple 的标注方式,你就会发现,range() 函数返回的等差数列就是一个 Tuple —— range(6) 就相当于 (0, 1, 2, 3, 4, 5)。
集合(Set)
集合(Set)这个容器类型与列表不同的地方在于,首先它不包含重合元素,其次它是无序的;进而,集合又分为两种,Set,可变的,Frozen Set,不可变的。
创建一个集合,用花括号 {} 把元素括起来,用 , 把元素隔开:
1 | primes = {2, 3, 5, 7, 11, 13, 17} |
{2, 3, 5, 7, 11, 13, 17}
创建
注意:创建空集合的时候,必须用 set(),而不能用 {}:
1 | from IPython.core.interactiveshell import InteractiveShell |
dict
set
也可以将序列数据转换(Casting)为集合。转换后,返回的是一个已去重的集合。
1 | from IPython.core.interactiveshell import InteractiveShell |
{'a', 'b', 'c', 'd', 'e', 'f'}
{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
{1, 2, 3}
{'a', 'b', 'e'}
Set 当然也可以进行 Comprehension:
1 | a = "abcabcdeabcdbcdef" |
{'d', 'e', 'f'}
操作
将序列类型数据转换成 Set,就等于去重。当然,也可以用 in 来判断某个元素是否属于这个集合。len()、max()、min(),也都可以用来操作 Set,但 del 却不行 —— 因为 Set 中的元素没有索引(它不是有序容器)。从 Set 里删除元素,得用 set.remove(elem);而 Frozen Set 是不可变的,所以不能用 set.remove(elem) 操作。
对于集合,有相应的操作符可以对它们进行集合运算:
- 并集:
|- 交集:
&- 差集:
-- 对称差集:
^
之前用 set('abcabcdeabcdbcdef') 作为简单例子还凑合能用;但这样对读者无意义的集合,无助于进一步的理解。
事实上,每种数据结构(Data Structures —— 在这一章里,我们一直用的概念是 “容器”,其实是指同一事物的两种称呼)都有自己的应用场景。比如,当我们需要管理很多用户时,集合就可以派上很大用场。
假定两个集合中有些人是 admins,有些人是 moderators:
1 | admins = {'Moose', 'Joker', 'Joker'} |
那么:
1 | admins = {'Moose', 'Joker', 'Joker'} |
{'Joker', 'Moose'}
True
False
{'Ann', 'Chris', 'Jane', 'Joker', 'Moose', 'Zero'}
{'Moose'}
{'Joker'}
{'Ann', 'Chris', 'Jane', 'Joker', 'Zero'}
1 | # 这个 cell 集合运算图示需要安装 matplotlib 和 matplotlib-venn |
以上的操作符,都有另外一个版本,即,用 Set 这个类的 Methods 完成。
| 意义 | 操作符 | Methods | Methods 相当于 |
|---|---|---|---|
| 并集 | | |
set.union(*others) |
set | other | … |
| 交集 | & |
set.intersection(*others) |
set & other & ... |
| 差集 | - |
set.difference(*others) |
set - other - ... |
| 对称差集 | ^ |
set.symmetric_difference(other) |
set ^ other |
注意,并集、交集、差集的 Methods,可以接收多个集合作为参数 (*other),但对称差集 Method 只接收一个参数 (other)。
对于集合,推荐更多使用 Methods 而不是操作符的主要原因是:更易读 —— 对人来说,因为有意义、有用处的代码终将需要人去维护。
1 | from IPython.core.interactiveshell import InteractiveShell |
{'Chris', 'Jane', 'Joker', 'Moose', 'Zero'}
{'Moose'}
{'Joker'}
{'Chris', 'Jane', 'Joker', 'Zero'}
逻辑运算
两个集合之间可以进行逻辑比较,返回布尔值。
set == other
True: set 与 other 相同
set != other
True: set 与 other 不同
isdisjoint(other)
True: set 与 other 非重合;即,set & other == None
issubset(other),set <= other
True: set 是 other 的子集
set < other
True: set 是 other 的真子集,相当于set <= other && set != other
issuperset(other),set >= other
True: set 是 other 的超集
set > other
True: set 是 other 的真超集,相当于set >= other && set != other
更新
对于集合,有以下更新它自身的 Method:
add(elem)
把 elem 加入集合
remove(elem)
从集合中删除 elem;如果集合中不包含该 elem,会产生 KeyError 错误。
discard(elem)
如果该元素存在于集合中,删除它。
pop(elem)
从集合中删除 elem,并返回 elem 的值,针对空集合做此操作会产生 KeyError 错误。
clear()
从集合中删除所有元素。
set.update(*others),相当于 set |= other | ...
更新 set, 加入 others 中的所有元素;
set.intersection_update(*others),相当于 set &= other & ...
更新 set, 保留同时存在于 set 和所有 others 之中的元素;
set.difference_update(*others),相当于 set -= other | ...
更新 set, 删除所有在 others 中存在的元素;
set.symmetric_difference_update(other),相当于 set ^= other
更新 set, 只保留存在于 set 或 other 中的元素,但不保留同时存在于 set 和 other 中的元素;注意,该 Method 只接收一个参数。
冻结集合
还有一种集合,叫做冻结集合(Frozen Set),Frozen Set 之于 Set,正如 Tuple 之于 List,前者是不可变容器(Immutable),后者是可变容器(Mutable),无非是为了节省内存使用而设计的类别。
有空去看看这个链接就可以了:
字典(Dictionary)
Map 是容器中的单独一类,映射(Map)容器。映射容器只有一种,叫做字典(Dictionary)。先看一个例子:
1 | phonebook = {'ann':6575, 'bob':8982, 'joe':2598, 'zoe':1225} |
字典里的每个元素,由两部分组成,key(键)和 value(值),二者由一个冒号连接。
比如,'ann':6575 这个字典元素,key 是 'ann',value 是 6575。
字典直接使用 key 作为索引,并映射到与它匹配的 value:
1 | phonebook = {'ann':6575, 'bob':8982, 'joe':2598, 'zoe':1225} |
8982
在同一个字典里,key 都是唯一的。当创建字典的时候,如果其中有重复的 key 的话,就跟 Set 那样会 “自动去重” —— 保留的是众多重复的 key 中的最后一个 key:value(或者说,最后一个 key:value “之前那个 key 的 value 被更新了”)。字典这个数据类型之所以叫做 Map(映射),是因为字典里的 key 都映射且只映射一个对应的 value。
1 | phonebook = {'ann':6575, 'bob':8982, 'joe':2598, 'zoe':1225, 'ann':6585} |
{'ann': 6585, 'bob': 8982, 'joe': 2598, 'zoe': 1225}
在已经了解如何操作列表之后,再去理解字典的操作,其实没什么难度,无非就是字典多了几个 Methods。
提蓄一下自己的耐心,把下面的若干行代码都仔细阅读一下,猜一猜输出结果都是什么?
字典的生成
1 | from IPython.core.interactiveshell import InteractiveShell |
{}
{'a': 1, 'b': 2, 'c': 3}
更新某个元素
1 | from IPython.core.interactiveshell import InteractiveShell |
2598
{'ann': 6585, 'bob': 8982, 'joe': 5802, 'zoe': 1225}
5802
添加元素
1 | from IPython.core.interactiveshell import InteractiveShell |
{'ann': 6585,
'bob': 8982,
'joe': 2598,
'zoe': 1225,
'john': 9876,
'mike': 5603,
'stan': 6898,
'eric': 7898}
删除某个元素
1 | from IPython.core.interactiveshell import InteractiveShell |
{'bob': 8982, 'joe': 2598, 'zoe': 1225}
逻辑操作符
1 | phonebook1 = {'ann':6575, 'bob':8982, 'joe':2598, 'zoe':1225, 'ann':6585} |
True
dict_keys(['ann', 'bob', 'joe', 'zoe'])
False
dict_values([6585, 8982, 2598, 1225])
True
dict_items([('ann', 6585), ('bob', 8982), ('joe', 2598), ('zoe', 1225)])
False
可用来操作的内建函数
1 | from IPython.core.interactiveshell import InteractiveShell |
8
'zoe'
'ann'
['ann', 'bob', 'joe', 'zoe', 'john', 'mike', 'stan', 'eric']
('ann', 'bob', 'joe', 'zoe', 'john', 'mike', 'stan', 'eric')
{'ann', 'bob', 'eric', 'joe', 'john', 'mike', 'stan', 'zoe'}
['ann', 'bob', 'eric', 'joe', 'john', 'mike', 'stan', 'zoe']
['zoe', 'stan', 'mike', 'john', 'joe', 'eric', 'bob', 'ann']
常用 Methods
1 | from IPython.core.interactiveshell import InteractiveShell |
{'john': 9876, 'mike': 5603, 'stan': 6898, 'eric': 7898}
{}
{'john': 9876, 'mike': 5603, 'stan': 6898, 'eric': 7898}
('zoe', 1225)
{'ann': 6585, 'bob': 8982, 'joe': 2598}
3538
{'ann': 6585, 'bob': 8982, 'joe': 2598}
3538
{'ann': 6585, 'bob': 8982, 'joe': 2598}
3538
{'ann': 6585, 'bob': 8982, 'joe': 2598, 'adam': 3538}
迭代各种容器中的元素
我们总是有这样的需求:对容器中的元素逐一进行处理(运算)。这样的时候,我们就用 for 循环去迭代它们。
对于迭代 range() 和 list 中的元素我们已经很习惯了:
1 | for i in range(3): |
0
1
2
1 | for i in [1, 2, 3]: |
1
2
3
迭代的同时获取索引
有时,我们想同时得到有序容器中的元素及其索引,那么可以调用 enumerate() 函数来帮我们:
1 | s = 'Python' |
0 P
1 y
2 t
3 h
4 o
5 n
1 | for i, v in enumerate(range(3)): |
0 0
1 1
2 2
1 | L = ['ann', 'bob', 'joe', 'john', 'mike'] |
0 ann
1 bob
2 joe
3 john
4 mike
1 | t = ('ann', 'bob', 'joe', 'john', 'mike') |
0 ann
1 bob
2 joe
3 john
4 mike
迭代前排序
可以用 sorted() 和 reversed() 在迭代前先排好序:
1 | t = ('bob', 'ann', 'john', 'mike', 'joe') |
0 ann
1 bob
2 joe
3 john
4 mike
1 | t = ('bob', 'ann', 'john', 'mike', 'joe') |
0 mike
1 john
2 joe
3 bob
4 ann
1 | t = ('bob', 'ann', 'john', 'mike', 'joe') |
0 joe
1 mike
2 john
3 ann
4 bob
同时迭代多个容器
可以在 zip() 这个函数的帮助下,同时迭代两个或者两个以上的容器中的元素(这样做的前提是,多个容器中的元素数量最好相同):
1 | chars = 'abcdefghijklmnopqrstuvwxyz' |
Let's assume a represents 1.
Let's assume b represents 2.
Let's assume c represents 3.
Let's assume d represents 4.
Let's assume e represents 5.
Let's assume f represents 6.
Let's assume g represents 7.
Let's assume h represents 8.
Let's assume i represents 9.
Let's assume j represents 10.
Let's assume k represents 11.
Let's assume l represents 12.
Let's assume m represents 13.
Let's assume n represents 14.
Let's assume o represents 15.
Let's assume p represents 16.
Let's assume q represents 17.
Let's assume r represents 18.
Let's assume s represents 19.
Let's assume t represents 20.
Let's assume u represents 21.
Let's assume v represents 22.
Let's assume w represents 23.
Let's assume x represents 24.
Let's assume y represents 25.
Let's assume z represents 26.
迭代字典中的元素
1 | phonebook1 = {'ann':6575, 'bob':8982, 'joe':2598, 'zoe':1225, 'ann':6585} |
ann 6585
bob 8982
joe 2598
zoe 1225
1 | phonebook1 = {'ann':6575, 'bob':8982, 'joe':2598, 'zoe':1225, 'ann':6585} |
ann 6585
bob 8982
joe 2598
zoe 1225
总结
这一章的内容,只不过是 “多” 而已,一旦逻辑关系理顺,就会觉得很简单。而这一章的开头,已经是最好的总结了。
最后需要补充的,只是两个参考链接,以后有什么搞不明白的地方,去那里翻翻就能找到答案:
文件
我们需要处理的数据,一定是很多,所以才必须由计算机帮我们处理 —— 大量的数据保存、读取、写入,需要的就是文件(Files)。在这一章里,我们只介绍最简单的文本文件。
创建文件
创建一个文件,最简单的方式就是用 Python 的内建函数 open()。
open() 函数的官方文档很长,以下是个简化版:
open(file, mode='r')
第二个参数,mode,默认值是 'r',可用的 mode 有以下几种:
| 参数字符 | 意义 |
|---|---|
'r' |
只读模式 |
'w' |
写入模式(重建) |
'x' |
排他模式 —— 如果文件已存在则打开失败 |
'a' |
追加模式 —— 在已有文件末尾追加 |
'b' |
二进制文件模式 |
't' |
文本文件模式(默认) |
'+' |
读写模式(更新) |
创建一个新文件,用这样一个语句就可以:
1 | open('/tmp/test-file.txt', 'w') |
<_io.TextIOWrapper name='/tmp/test-file.txt' mode='w' encoding='UTF-8'>
当然,更多的时候,我们会把这个函数的返回值,一个所谓的 file object,保存到一个变量中,以便后面调用这个 file object 的各种 Methods,比如获取文件名 file.name,比如关闭文件 file.close():
1 | f = open('/tmp/test-file.txt', 'w') |
/tmp/test-file.txt
删除文件
删除文件,就得调用 os 模块了。删除文件之前,要先确认文件是否存在,否则删除命令会失败。
1 | import os |
/tmp/test-file1.txt
/tmp/test-file1.txt deleted.
读写文件
创建文件之后,我们可以用 f.write() 把数据写入文件,也可以用 f.read() 读取文件。
1 | f = open('/tmp/test-file.txt', 'w') |
first line
second line
third line
文件有很多行的时候,我们可以用 file.readline() 操作,这个 Method 每次调用,都会返回文件中的新一行。
1 | f = open('/tmp/test-file.txt', 'w') |
first line
second line
注意,返回结果好像跟你想的不太一样。这时候,之前见过的 str.strip() 就派上用场了:
1 | f = open('/tmp/test-file.txt', 'w') |
first line
second line
与之相对的,我们可以使用 file.readlines() 这个 Method,将文件作为一个列表返回,列表中的每个元素对应着文件中的每一行:
1 | f = open('/tmp/test-file.txt', 'w') |
['first line\n', 'second line\n', 'third line\n']
既然返回的是列表,那么就可以被迭代,逐一访问每一行:
1 | f = open('/tmp/test-file.txt', 'w') |
first line
second line
third line
与之相对的,我们也可以用 file.writelines() 把一个列表写入到一个文件中,按索引顺序(从 0 开始)逐行写入列表的对应元素::
1 | a_list = ['first line\n', 'second line\n', 'third line\n'] |
first line
second line
third line
with 语句块
针对文件操作,Python 有个另外的语句块写法,更便于阅读:
1 | with open(...) as f: |
这样,就可以把针对当前以特定模式打开的某个文件的各种操作都写入同一个语句块了:
1 | import os |
first line
second line
third line
test-file.txt deleted.
另外,用 with 语句块的另外一个附加好处就是不用写 file.close() 了……
另一个完整的程序
若干年前,我在写某本书的时候,需要一个例子 —— 用来说明 “即便是结论正确,论证过程乱七八糟也不行!”
作者就是这样,主要任务之一就是给论点找例子找论据。找得到不仅恰当且又精彩的例子和论据的,就是好作者。后面这个 “精彩” 二字要耗费很多时间精力,因为它意味着说 “要找到很多例子而后在里面选出最精彩的那个!” —— 根本不像很多人以为的那样,是所谓的 “信手拈来”。
找了很多例子都不满意…… 终于有一天,我看到这么个说法:
如果把字母
a计为1、b计为2、c计为3……z计为26,那么:
- knowledge = 96
- hardwork = 98
- attitude = 100
所以结论是:
- 知识(knowledge)与勤奋(hardwork)固然都很重要;
- 但是,决定成败的却是态度(attitude)!
结论虽然有道理 —— 可这论证过程实在是太过分了罢……
我很高兴,觉得这就是个好例子!并且,加工一下,会让读者觉得很精彩 —— 如果能找到一些按照同样的计算方式能得到 100 的单词,并且还是那种一看就是 “反例” 的单词……
凭直觉,英文单词几十万,如此这般等于 100 的单词岂不是数不胜数?并且,一定会有很多负面意义的单词如此计算也等于 100 罢?然而,这种事情凭直觉是不够的,手工计算又会被累死…… 于是,面对如此荒谬的论证过程,我们竟然 “无话可说”。
幸亏我是会写程序的人。所以,不会 “干着急没办法”,我有能力让计算机帮我把活干了。
很快就搞定了,找到很多很多个如此计算加起来等于 100 的英文单词,其中包括:
- connivance(纵容)
- coyness(羞怯)
- flurry(慌张)
- impotence(阳痿)
- stress(压力)
- tuppence(微不足道的东西)
- ……
所以,决定成败的可以是 “慌张”(flurry),甚至是 “阳痿”(impotence)?这不明显是胡说八道嘛!
—— 精彩例子制作完毕,我把它放进了书里。
那,具体的过程是什么样的呢?
首先我得找到一个英文单词列表,很全的那种。这事用不着写程序,Google 一下就可以了。我搜索的关键字是 “english word list”,很直观吧?然后就找到一个:https://github.com/dwyl/english-words;这个链接里有一个 words-alpha.txt 文件,其中包含接近 37,0101 个单词,应该够用了!下载下来用程序处理就可以了!
因为文件里每行一个单词,所以,就让程序打开文件,将文件读入一个列表,而后迭代这个列表,逐一计算那个单词每个字母所代表的数字,并加起来看看是否等于 100?如果是,就将它们输出到屏幕…… 好像不是很难。
1 | with open('words_alpha.txt', 'r') as file: |
按照上面那说法,把 a 记为 1,直至把 z 记为 26,这事并不难,因为有 ord() 函数啊 —— 这个函数返回字符的 Unicode 编码:ord('a') 的值是 97,那按上面的说法,用 ord('a') - 96 就相当于得到了 1 这个数值…… 而 ord('z') - 96 就会得到 26 这个数值。
1 | ord('a') |
97
那么,计算 'knowledge' 这个字符串的代码很简单:
1 | word = 'knowledge' |
96
果然,得到的数值等于 96 —— 不错。把它写成一个函数罢:sum_of_word(word):
1 | def sum_of_word(word): |
100
那让程序就算把几十万行都算一遍也好像很简单了:
1 | def sum_of_word(word): |
abstrusenesses
acupuncturist
adenochondrosarcoma
...
worshipability
zeuctocoelomatic
zygapophysis
嗯?怎么输出结果跟想得不一样?找到的词怎么都 “奇形怪状” 的…… 而且,输出结果中也没有 attitude 这个词。
插入个中止语句,break,把找到的第一个词中的每个字符和它所对应的值都拿出来看看?
1 | def sum_of_word(word): |
abstrusenesses
a 1
b 2
s 19
t 20
r 18
u 21
s 19
e 5
n 14
e 5
s 19
s 19
e 5
s 19
-86
怎么有个 -86?!仔细看看输出结果,看到每一行之间都被插入了一个空行,想到应该是从文件里读出的行中,包含 \n 这种换行符…… 如果是那样的话,那么 ord('\n') -96 返回的结果是 -86 呢,怪不得找到的词都 “奇形怪状” 的……
1 | ord('\n') -96 |
-86
改进一下呗 —— 倒也简单,在计算前把读入字符串前后的空白字符都给删掉就好了,用 str.strip() 就可以了:
1 | def sum_of_word(word): |
abactinally
abatements
abbreviatable
...
zithern
zoogleas
zorgite
如果想把符合条件的词保存到一个文件 results.txt 里的话,那么:
1 | def sum_of_word(word): |
竟然这么简单就搞定了?!
这 10 行的代码,在几秒钟内从 370,101 个英文单词中找到 3,771 个如此计算等于 100 的词汇。
喝着咖啡翻一翻 results.txt,很快就找到了那些用来做反例格外恰当的词汇。
真无法想象当年的自己若是不懂编程的话现在会是什么样子……
总结
这一章我们介绍了文本文件的基本操作:
- 打开文件,直接用内建函数,
open(),基本模式有r和w;- 删除文件,得调用
os模块,使用os.remove(),删除文件前最好确认文件确实存在……- 读写文件分别有
file.read()、file.write()、file.readline()、file.readlines()、file.writelines();- 可以用
with把相关操作都放入同一个语句块……
如何从容应对含有过多 “过早引用” 的知识?
“过早引用”(Forward References,另译为 “前置引用”),原本是计算机领域的术语。
在几乎所有的编程语言中,对于变量的使用,都有 “先声明再使用” 的要求。直接使用未声明的变量是被禁止的。Python 中,同样如此。如果在从未给 an_undefined_variable 赋值的情况下,直接调用这个变量,比如,print(an_undefined_variable),那就会报错:NameError: name 'an_undefined_variable' is not defined。
1 | print(an_undefined_variable) |
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-1-7e0e1cc14e37> in <module>
----> 1 print(an_undefined_variable)
NameError: name 'an_undefined_variable' is not defined
充满过早引用的知识结构,在大脑中会构成类似 M.C. Escher 善画的那种 “不可能图形” 那样的 “结构”。
在上图中,前三个椎形一般不会造成视觉困惑 —— 尤其是第一个。
若是加上虚线,比如,第二个和第三个,那么由于我们预设虚线表示 “原本应该看不见的部分”,于是,C 点的位置相对于 B 和 D 应该更靠近自己;C' 的位置,相对于 B' 和 D' 应该更远离自己……
然而,在第四个椎形中,由于 B"D" 和 A"C" 都是实线,于是,我们一下子就失去了判断依据,不知道 C" 究竟是离自己更近还是更远?
对一个点的位置困惑,连带着它与其它三个点之间的关系。可若那不是锥体,而是立方体呢?每个点的位置困惑会造成对它与更多点之间的更多联系的困惑…… 若是更多面体呢?

把这些令人困惑的点,比喻成 “过早引用”,你就明白为什么 “很多过早引用” 的知识结构会那么令人困惑,处理起来那么令人疲惫了吧?
过早引用就是无所不在
可生活、学习、工作,都不是计算机,它们可不管这套,管它是否定义过,管它是否定义清晰,直接甩出来就用的情况比比皆是。
对绝大多数 “不懂事” 的小朋友来说,几乎所有痛苦的根源都来自这里:“懂事” 的定义究竟是怎样的呢?什么样算作懂事,什么样算作不懂事?弄不好,即便整个童年都在揣摩这个事,到最后还是迷迷糊糊。他们的父母,从未想过对孩子说话也好提要求也好,最好 “先声明再使用”,或者即便事先声明过也语焉不详…… 于是,这些可怜的孩子,能做的只有在惶恐中摸索,就好像在黑暗中拼图一样。
可事实上,他们的父母也不容易。因为确实有太多细节,给小朋友讲了也没用,或者讲也讲不清楚,又或者拼命解释清楚了,但小朋友就是听不进去…… 所以,令人恼火的 “过早引用”,有时候真的是只能那样的存在。
谈恋爱的时候也是这样。太多的概念,千真万确地属于过早引用。爱情这东西究竟是什么,刚开始的时候谁都弄不大明白。并且事实证明,身边的绝大多数人跟自己一样迷糊。至于从小说电影里获得的 “知识”,虽然自己看心神愉悦,但几乎肯定给对方带来无穷无尽的烦恼 —— 于对方来说你撒出来的是漫天飞舞的过早引用……
到了工作阶段,技术岗位还相对好一点,其他领域,哪哪儿都是过早引用,并且还隐藏着不可见,搞得人们都弄出了一门玄学,叫做 “潜规则”。
人们岁数越大,交朋友越来越不容易。最简单的解释就是,每个人的历史,对他人来说都构成 “过早引用”。所以,理解万岁?太难了吧,幼儿园、小学的时候,人们之间几乎不需要刻意相互理解,都没觉得有这个必要;中学的时候,相互理解就已经开始出现不同程度的困难了,因为过早引用的积累。大学毕业之后,再工作上几年,不仅相互理解变得越来越困难,还有另外一层更大的压力 —— 生活中要处理的事情越来越多,脑力消耗越来越大,遇到莫名其妙的过早引用,哪儿有心思处理?
不懂也要硬着头皮读完
这是事实:大多数难以掌握的技能都有这个特点。人们通常用 “学习曲线陡峭” 来形容这类知识,只不过,这种形容只限于形容而已,对学习没有实际的帮助。面对这样的实际情况,有没有一套有效的应对策略呢?
首先是要学会一个重要的技能:
读不懂也要读完,然后重复很多遍。
这是最重要的起点。听起来简单,甚至有点莫名其妙 —— 但以后你就会越来越深刻地体会到,这么简单的策略,绝大多数人竟然不懂,也因此吃了很多很多亏。
充满了过早引用的知识结构,就不可能是一遍就读懂的。别说这种信息密度极高的复杂且重要的知识获取了,哪怕你去看一部好电影,也要多刷几遍才能彻底看懂,不是嘛?比如,Quentin Tarantino 导演的 Pulp Fiction (1994)、David Fincher 导演的 Fight Club (1999)、Christopher Nolan 导演的 Inception (2010)、或者 Martin Scorsese 导演的 Shutter Island (2010)……
所以,从一开始就要做好将要重复很多遍的准备,从一开始就要做好第一次只能读懂个大概的准备。
古人说,读书百遍其义自见,道理就在这里了 —— 只不过,他们那时候没有计算机术语可以借用,所以,这道理本身成了 “过早引用”,对那些根本就没有过 “读书百遍” 经历的人,绝对以为那只不过是在忽悠自己……
有经验的读书者,拿来一本书开始自学技能的时候,他会先翻翻目录(Table Of Contents),看看其中有没有自己完全没有接触过的概念;然后再翻翻术语表(Glossary),看看是否可以尽量理解;而后会看看索引(Index),根据页码提示,直接翻到相关页面进一步查找…… 在通读书籍之前,还会看看书后的参考文献(References),看看此书都引用了哪些大牛的书籍,弄不好会顺手多买几本。
这样做,显然是老到 —— 这么做的最大好处是 “尽力消解了大量的过早引用”,为自己减少了极大的理解负担。
所以,第一遍的正经手段是 “囫囵吞枣地读完”。
囫囵吞枣从一开始就是贬义词。但在当前这个特殊的情况下,它是最好的策略。那些只习惯于一上来就仔细认真的人,在这里很吃亏,因为他们越是仔细认真,越是容易被各种过早引用搞得灰心丧气;相应地,他们的挫败感积累得越快;到最后弄不好最先放弃的是他们 —— 失败的原因竟然是因为 “太仔细了”……
第一遍囫囵吞枣,用个正面一点的描述,就是 “为探索未知领域先画个潦草的地图”。地图这东西,有总比没有好;虽然说它最好精确,但即便是 “不精确的地图” 也比 “完全没地图” 好一万倍,对吧?更何况,这地图总是可以不断校正的,不是吗?世界上哪个地图不是一点一点校正过来才变成今天这般精确的呢?
磨练 “只字不差” 的能力
通过阅读习得新技能(尤其是 “尽量只通过阅读习得新技能”),肯定与 “通过阅读获得心灵愉悦” 很不相同。
读个段子、读个小说,读个当前热搜文章,通常情况下不需要 “精读” —— 草草浏览已经足够,顶多对自己特别感兴趣的地方,慢下来仔细看看……
但是,若是为了习得新技能去阅读,就要施展 “只字不差地阅读” 这项专门的技能。
对,“只字不差地阅读” 是所有自学能力强的人都会且都经常使用的技能。尤其是当你在阅读一个重要概念的定义之时,你就是这么干的:定义中的每个字都是有用的,每个词的内涵外延都是需要进行推敲的,它是什么,它不是什么,它的内涵外延都是什么,因此,在使用的时候需要注意什么……
很有趣的一个现象是,绝大多数自学能力差的人,都是把一切都当作小说去看,随便看看,粗略看看……
你有没有注意到一个现象,人们在看电影的时候,绝大多数人会错过绝大多数细节;但这好像并不会削减他们的观影体验;并且,他们有能力使用错过了无数细节之后剩下的那些碎片拼接出一个 “完整的故事” —— 当然,通常干脆是 “另一个貌似完整的故事”。于是,当你在跟他们讨论同一个电影的时候,常常像是你们没坐在同一个电影院,看的不是同一个电影似的……
所谓的自学能力差,很可能最重要的坑就在这里:
每一次学习新技能的时候,很多人只不过是因为做不到只字不差地阅读,于是总是会错过很多细节;于是,最终就好像 “看了另外一个山寨版电影一样”,实际上 “习得了另外一个山寨版技能”……
在学习 Python 语言的过程中,有个例子可以说明以上的现象。
在 Python 语言中,for 循环可以附加一个 else 部分。你到 Google 上搜索一下 for else python 就能看到有多少人在 “追问” 这是干什么的?还有另外一些链接,会告诉你 “for… else” 这个 “秘密” 的含义,将其称为 “语法糖” 什么的……
其实,官方教程里写的非常清楚的,并且还给出了一个例子:
Loop statements may have an else clause; it is executed when the loop terminates through exhaustion of the list (with for) or when the condition becomes false (with while), but not when the loop is terminated by a break statement. This is exemplified by the following loop, which searches for prime numbers:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
> ... for x in range(2, n):
> ... if n % x == 0:
> ... print(n, 'equals', x, '*', n//x)
> ... break
> ... else:
> ... # loop fell through without finding a factor
> ... print(n, 'is a prime number')
> ...
> 2 is a prime number
> 3 is a prime number
> 4 equals 2 * 2
> 5 is a prime number
> 6 equals 2 * 3
> 7 is a prime number
> 8 equals 2 * 4
> 9 equals 3 * 3
>
只有两种情况,
- 要么干脆就没读过,
- 要么是读了,却没读到这个细节……
—— 后者更为可怕,跟花了同样的钱看了另外一个残缺版本的电影似的……
为什么说 “只字不差地阅读” 是一项专门的技能呢?你自己试过就知道了。明明你已经刻意让自己慢下来,也刻意揣摩每个字每个词的含义,甚至为了理解正确,做了很多笔记…… 可是,当你再一次 “只字不差地阅读” 的时候,你经常会 “惊讶地发现”,自己竟然有若干处遗漏的地方!对,这就是一种需要多次练习、长期训练才能真正掌握的技能。绝对不像听起来那么简单。
所以,到了第二遍第三遍就必须施展 “只字不差地阅读” 这项专门的技能了,只此一点,你就已然与众不同了。
好的记忆力很重要
“就算读不懂也要读完” 的更高境界,是 “就算不明白也要先记住”。
人们普遍讨厌 “死记硬背”…… 不过,说实话,这很肤浅。虽然确实也有 “擅长死记硬背却就是什么都不会的人”,但是,其实有更多记忆力强的人,实际上更可能是 “博闻强识”。
面对 “过早引用” 常见的知识领域,好记忆力是超强加分项。记不清、记不住、甚至干脆忘了 —— 这是自学过程中最耽误事的缺点。尤其在有 “过早引用知识点” 存在的时候,更是如此。
然而,很多人并没有意识到的是,记忆力也是 “一门手艺” 而已。并且,事实上,它是任何时候都可以通过刻意练习加强的 “手艺”。
更为重要的是,记忆力这个东西,有一百种方法去弥补 —— 比如,最明显、最简单的办法就是 “好记性不如烂笔头”……
所以,在绝大多数正常情况下,所谓的 “记不清、记不住、甚至干脆忘了”,都只不过是懒的结果 —— 若是一个人懒,且不肯承认自己懒,又因为不肯承认而已就不去纠正,那…… 那就算了,那就那么活下去罢。
然而,提高对有效知识的记忆力还有另外一个简单实用的方法 —— 而市面上有各种 “快速记忆法”,通常相对于这个方法来看用处并不大。
这个方法就是以下要讲到的 “整理归纳总结” —— 反复做整理归纳总结,记不住才怪呢!
尽快开始整理归纳总结
从另外一个角度,这类体系的知识书籍,对作者来说,不仅是挑战,还是摆脱不了的负担。
Python 官方网站上的 The Python Tutorial,是公认的最好的 Python 教材 —— 因为那是 Python 语言的作者 Guido van Rossum 写的……
虽然 Guido van Rossum 已经很小心了,但还是没办法在讲解上避免大量的过早引用。他的小心体现在,在目录里就出现过五次 More:
- More Control Flow Tools
- More on Defining Functions
- More on Lists
- More on Conditions
- More on Modules
好几次,他都是先粗略讲过,而后在另外一处再重新深入一遍…… 这显然是一个最尽力的作者了 —— 无论是在创造一个编程语言上,还是在写一本教程上。
然而,即便如此,这本书对任何初学者来说,都很难。当个好作者不容易。
于是,这只能是读者自己的工作了 —— 因为即便是最牛的作者,也只能到这一步了。
第一遍囫囵吞枣之后,马上就要开始 “总结、归纳、整理、组织 关键知识点” 的工作。自己动手完成这些工作,是所谓学霸的特点。他们只不过是掌握了这样一个其他人从未想过必须掌握的简单技巧。他们一定有个本子,里面是各种列表、示意图、表格 —— 这些都是最常用的知识(概念)整理组织归纳工具,这些工具的用法看起来简单的要死。
这个技巧说出来、看起来都非常简单。然而,也许正因为它看起来如此简单,才被绝大多数人忽略…… 与学霸们相对,绝大多数非学霸都有一模一样的糊弄自己的理由:反正有别人做好的,拿过来用就是了!—— 听起来那么理直气壮……
可实际上,自己动手做做就知道了 —— 整理、归纳、组织,再次反复,是个相当麻烦的过程。非学霸们自己不动手做的真正原因只不过是:嫌麻烦、怕麻烦。一个字总结,就是,懒!可是,谁愿意承认自己懒呢?没有人愿意。于是,都给自己找个冠冕堂皇的理由,比如,上面说的 “反正别人已经做好了,我为什么还要再做一遍呢?” 再比如,“这世界就是懒人推进的!”
久而久之,各种爱面子的说法完美地达成了自我欺骗的效果,最后连自己都信了!于是,身上多了一个明明存在却永远找不到的漏洞 —— 且不自知。
我在第一次粗略读过整个 Python Official Tutorial 中的第五章之后,顺手整理了一下 Containers 的概念表格:
可这张图错了!
因为我最早 “合理囫囵吞枣” 的时候,Bytes 这种数据类型全部跳过;而后来多轮反复之后继续深入,又去读 The Python Language Reference 的第五章 Data Model 之后,发现 Set 也有 Immutable,是 Frozen Set…… 当然,最错的是,整理的过程中,一不小心把 “Ordered” 给弄反了!
于是肯定需要再次整理,若干次改进之后,那张图就变成了下面这个样子:
另外,从 Python 3.7 开始,Dictionary 是 insertion ordered 了:
https://docs.python.org/3/library/collections.html#ordereddict-objects
这个自己动手的过程其实真的 “很麻烦”,但它实际上是帮助自己强化记忆的过程,并且对自我记忆强化来说,绝对是不可或缺的过程。习惯于自己动手做罢!习惯于自己不断修改罢!
再给你看个善于学习的人的例子:
作者 Vincent Driessen 在这个帖子里写到:
I’m writing this post as a pocket reference for later.
人家随手做个图,都舍不得不精致:
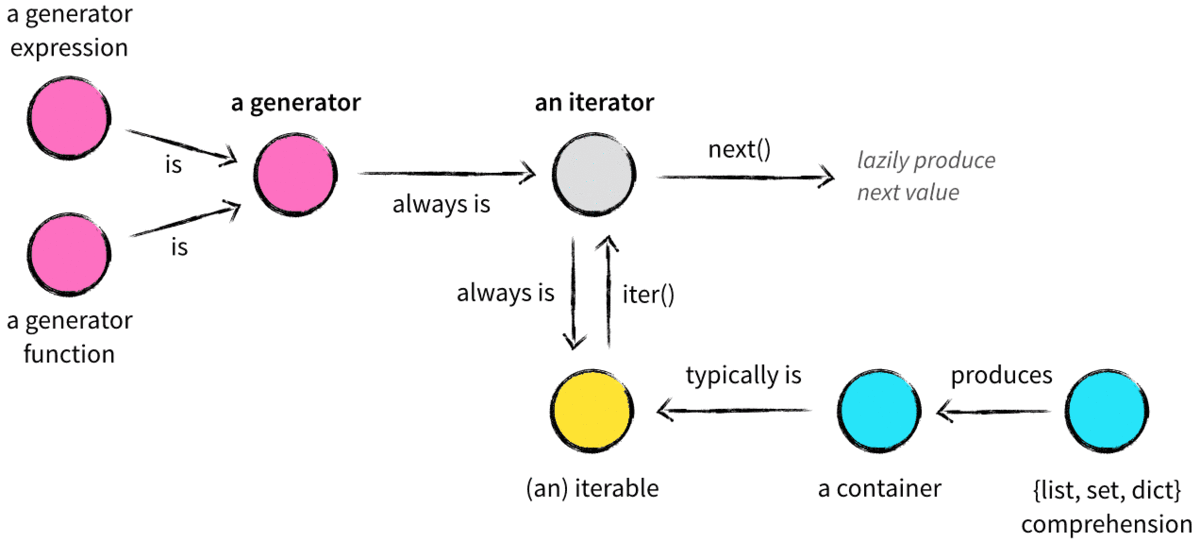
自学能力强的人有个特点,就是不怕麻烦。小时候经常听到母亲念叨,“怕麻烦!那还活着干嘛啊?活着多麻烦啊!” —— 深刻。
先关注使用再研究原理
作为人类,我们原本很擅长运用自己并不真正理解的物件、技能、原理、知识的……
三千多年以前,一艘欧洲腓尼基人的商船在贝鲁斯河上航行的时候搁浅了…… 于是,船员们纷纷登上沙滩。饿了怎么办?架火做饭呗。吃完饭,船员们惊讶地发现锅下面的沙地上有很多亮晶晶、闪闪发光的东西!今天的化学知识对当年的他们来说,是那一生不可触摸的 “过早引用”。他们并不懂这个东西的本质、原理,但稍加研究,他们发现的是,锅底沾有他们运输的天然苏打…… 于是,他们的总结是,天然苏打和沙子(我们现在知道沙子中含有石英砂)被火烧,可能会产生这个东西。几经实验,成功了。于是,腓尼基人学会了制做玻璃球,发了大财……
两千五六百年之前,释加牟尼用他的理解以及在那个时代有限的概念详细叙述了打坐的感受 —— 他曾连续打坐 6 年。今天,西方科学家们在深入研究脑科学的时候,发现 Meditation 对大脑有特别多的好处…… 这些好处就是好处,与宗教全然没有任何关系的好处。
- Harvard neuroscientist: Meditation not only reduces stress, here’s how it changes your brain
- This Is Your Brain on Meditation – The science explaining why you should meditate every day
- Researchers study how it seems to change the brain in depressed patients
- Meditation’s Calming Effects Pinpointed in the Brain
- Different meditation types train distinct parts of your brain
你看,我们原本就是可以直接使用自己并不真正理解的物件、技能、原理、知识的!可为什么后来就不行了呢?
或者说,从什么时候开始,我们开始害怕自己并不真正理解的东西,不敢去用,甚至连试都不敢去试了呢?
有一个相当恼人的解释:上学上坏了。
学校里教的全都是属于 “先声明再使用” 的知识。反过来,不属于这种体系架构的知识,学校总是回避的 —— 比如,关于投资与交易的课程,从来看不见地球上有哪个义务教育体系把它纳入教学范围。虽然,投资与交易,是每个人都应该掌握、都必须掌握的不可或缺的技能,某种意义上它甚至比数学语文都更重要,然而,学校就是不会真教这样的东西。
而且,现在的人上学的时间越来越长。小学、初中、高中、本科加起来 16 年…… 这么长时间的 “熏陶”,只能给大多数人造成幻觉,严重、深刻,甚至不可磨灭的幻觉,误以为所有的知识都是这种类型…… 可偏偏,这世界上真正有用的、真正必要的知识,几乎全都不是这种类型 —— 颇令人恼火。
现在的你,不一样了 —— 你要跳出来。养成一个习惯:
不管怎么样,先用起来,反正,研究透原理,不可能马上做到,需要时间漫漫。
用错了没关系,改正就好。用得不好没关系,用多了就会好。只要开始用起来,理解速度就会加快 —— 实践出真知,不是空话。
有的时候,就是因为没有犯过错,所以不可能有机会改正,于是,就从未做对过。
尊重前人的总结和建议
生活中,年轻人最常犯的错误就是把那句话当作屁:
不听老人言,吃亏在眼前。
对年轻人来讲,老人言确实很讨厌,尤其是与自己当下的感受相左的时候。
然而,这种 “讨厌” 的感觉,更多的时候是陷阱,因为那些老人言只不过是过早引用,所以,在年轻人的脑子里 “无法执行”,“报错为类型错误”……
于是,很多人一不小心就把 “不听老人言” 和 “独立思考” 混淆起来,然后最终自己吃了亏。可尴尬在于,等自己意识到自己吃亏了的时候吧,大量的时间早已飘逝,是为 “无力回天”。
你可以观察到一个现象,学霸(好学生)的特点之一就是 “老师让干啥就干啥”,没废话。
比如,上面告诉你了,“必须自己动手”,那你就从现在开始老老实实地在一切必要的情况下自己动手去 “总结、归纳、整理、组织 关键知识点”…… 那你就必然能够学好。但针对这么个建议,你反复在那里问,“为什么呀?”,“有没有更简单的办法啊?”…… 那你就完了,死定了。
学写代码的过程中,有很多重要的东西实际上并不属于 “编程语言范畴”。比如,如何为变量命名、如何组织代码,这些 “规范”,不是违背了就会马上死掉的[1];并且,初来乍到的时候,这些东西看起来就是很啰嗦、很麻烦的…… 然而,这些东西若是不遵守,甚至干脆不了解,那么最终的结果是,你永远不可能写出大项目,永远是小打小闹 —— 至于为什么,可以用那句你最讨厌的话回答你:
等你长大了就懂了……
自学编程的好处之一,就是有机会让一个人见识到 “规范”、“建议” 的好处。也有机会让一个人见识到不遵守这些东西会吃怎样的亏(往往是现世报)。
Python 中有一个概念叫 PEP,Python Enhancement Proposals,必须找时间阅读,反复阅读,牢记于心:
到最后,你会体会到,这不只是编程的事,这种东西背后的思考与体量,对整个人生都有巨大帮助。
脚注
[1]:也可能真的会死…… 请看一篇 2018 年 9 月份的一则新闻,发生在旧金山的事情:Developer goes rogue, shoots four colleagues at ERP code maker
官方教程:The Python Tutorial
虽然,第一部分总计七章关于编程内容的编排是非常特别且相当有效的:
- 它并没有像其它教程那样,从 “Hello world!” 入手;
- 它也没有使用与市面上所有编程教材一样的内容先后顺序;
- 它一上来就让你明白了程序的灵魂:布尔运算;
- 它很快就让你明白有意义的程序其实只有两个核心构成:运算和流程控制;
- 它让你很快理解函数从另外一个角度看只不过是 “程序员作为用户所使用的产品”;
- 它让你重点掌握了最初级却最重要的数据类型,字符串;
- 它让你从容器的角度了解了 Python 中绝大多数 “重要的数据类型”;
- 最重要的是,它不承诺你 “速成”,但承诺 “领你入门”…… 显然,它做到了。
但是,第一部分的内容核心目标是让你 “脱盲” —— 它的作用还做不到让你 “已然学会编程”,它更多是让你从此开始有能力去阅读更多的重要资源,比如,官方的教程和参考。第一部分的内容更像地图上的 “图例”,而不是地图本身。
第一部分反复读过之后,最重要的结果就是:
现在你有能力自己查询官方文档了……
起码,在此之后,再去阅读 The Python Tutorial,不那么费力了,最起码,可以靠自己理解绝大多数内容……
在继续阅读本书内容的同时,有空就要反复翻 The Python Tutorial。
官方文档中最重要的链接
Python 也许是目前所有编程语言中在文档建设(Documenting)方面做得最好的(好像真的不需要在这句话后面加上 “之一”)。Python 社区为了建设完善的文档,甚至有专门的文档制作工具 —— 得益于 Python 社区从一开始就非常重视文档规范 —— Sphinx。你在网络上最经常看到的计算机类文档,很可能都在这个网站上:Read the Docs……
Python 的官方文档网址是:
其中对初学者最重要的两个链接是:
理论上来讲,只要有了基础的概念,自己反复阅读官方的 The Python Tutorial 是最好的,没什么入门书籍比它更好 —— 因为它的作者是 Python 的作者,那个被称为 “善意独裁者” 的 Guido van Rossum。
此人很帅,但更帅的是他的车牌(摘自 Guido van Rossume 的个人主页):

为什么一定要阅读官方文档
买一两本 Python 教程是不可能完整掌握 Python 的 —— 其实,这句话里的 Python 替换成任何一种语言也是一样的。
教程和官方文档的各种属性是非常不一样的,比如,针对读者群,组织方式,语言表达…… 最不一样的地方在 “全面性”。任何一本单独的教程,都不可能像官方文档那样全面。各种单独教程的优势在于,它们更多地针对初学者、入门者设计,但与此同时,在全面性、深入性上做了妥协。
比如,在当前这本书里,不会涉及 Bytes Object —— 并非只有我一个人这么做,著名的 Python 教程《Think Python: How to Think Like a Computer Scientist》、《Dive into Python》等等都没有涉及 Bytes Object 这个话题。
由于官方文档实际上没办法对入门者、初学者过分友好 —— 毕竟,全面、权威、准确才是它更应该做到的事情 —— 所以,很多人在刚开始的时候求助于各类非官方的教材、教程。原本应该是入门以后就理应 “只读官方文档”,或者 “第一查询对象只能是官方文档”,但在很多人那里竟然变成了 “从一开始到最后都在回避官方文档(或者说 ‘最专业的说明文字’)”,这就不好了,真的很吃亏,且自己都无法知道自己究竟吃了多少亏 —— 总以为自己已经学完了,但实际上从一开始就一点都不全面。
请牢记且遵守这个原则:
第一查询对象只能是官方文档。
所以,当我用 Google 查询的时候,经常使用这样的格式:
<queries> site:python.org
有时甚至会指定在哪个目录里搜索:
bytes site:python.org/3/library,你试试这个连接:bytes site:python.org/3/library
这个原则对任何语言都适用。将来你在学习任何新软件包(库)、语言更新后的新特性、甚至另外一个新语言的时候,都要这么做。所谓的超强自学能力,基本上就是由一些类似这样的小习惯和另外一些特别基础的方法构成的强大能力。
将官方文档拉回本地
把 The Python Tutorial 拉回本地阅读,可能更为方便,尤其是可以用 Sphinx 重新制作之后,页面左侧可以总是显示完整的目录:

也可以把这个教程转换成 epub 格式,以便在移动设备上阅读;甚至可以把这些个页面的 .rst 源文件转换成 .ipynb 文件,以便用 Jupyter Lab 浏览时可以直接执行其中的代码……
注意
此页的 Code Cell 中都是可执行的 bash 命令……
在此页执行它们对你来说是没意义的 —— 因为它们的执行结果在服务器上;这其中的命令,应该在你本地计算机上的 Terminal 中执行,你才能在本地计算机上获取结果。
安装 git
1 | %%bash |
下载源文件
The Python Tutorial 的源文件位置在:
repo 地址是:
使用 git 将 repo 下载到 ~/Download/ 目录:
1 | %%bash |
安装 rst2ipynb
1 | %%bash |
批量转换 rst 至 ipynb
这个 rst2ipynb 的程序有点讨厌,一次只能处理一个文件…… 下面是一个 bash 程序,其实将来学起来也不难,看着跟 Python 差不多…… 下面的代码执行过后会出现很多 “警告” —— 没关系,文件会正常转换的。
1 | %%bash |
如此这般,你就把 rst 文件都转换成 ipynb 文件,保存在 ~/Downloads/cpython/Doc/tutorial/ipynbs/ 之中了。随便把它挪到你喜欢的什么地方。用本地的 Jupyterlab 浏览,或者用 Nteract App 浏览。
如果以后你经常需要批量转换某个目录内的 rst 文件,那就把 bash function 放在 ~/.bash_profile 文件里,在最后面追加以下代码:
1 | function rsti { |
而后在 Terminal 里执行一遍:
1 | source ~/.bash_profile |
而后,在有 .rst 文件的目录下输入 rsti 执行即可……
用 Sphinx 生成 html/epub 版本
1 | %%bash |
生成 html 版本和 epub 版本:
1 | %%bash |
用 Sphinx 这样生成的版本,支持本地目录内搜索,也确实比在网站上看更方便一点:
下载已经转换好的版本
万一有什么情况中间出错又搞不定的话,就直接下载已经转换好的版本:
1 | %%bash |
完整的 Python Doc 制作
其实,Python 的整个文档,已经是做好了制作文件的文档库:
cpython/Doc/Makefile
只不过,将所有文件编译到一个 epub 里,在 iPad 之类的移动设备上打开有点费劲 —— 在我的设备上显示有 7701 页,翻页都要顿一顿……
想要使用这个官方的 Makefile 的话,首先确认自己已经安装过 Sphinx,其次需要补充安装一个包:
1 | pip install blurb |
而后在 Terminal 中转到 Doc 所在目录,执行以下命令:
1 | make html |
笨拙与耐心
自学的过程,实际上需要拆解为以下四个阶段,虽然它们之间常常有部分重叠:
- 学
- 练
- 用
- 造
只要识字,就会忍不住阅读;只要感觉上有 “值得学” 的,就会忍不住去学 —— 事实上每个人时时刻刻都在学习,只不过,学习的目标选择与学习的方式以及效率均不相同而已。
绝大多数人从未区分过这几个阶段,也从未研究过这几个阶段分别应该如何对待。这就解释了为什么那么多人虽然总是忍不住阅读,总是忍不住学习,但终其一生都没有真正掌握过像样的技能…… 因为他们在第一个阶段就出错,到了第二个阶段就放弃,第三个阶段是直接跳过去的,总是 “对付着用”,至于第四个阶段么,想都没想过……
第一部分的内容,基本用来展示 “学” 的过程。学,就需要重复,甚至很多次重复,尤其是在面对充满了 “过早引用” 现象的知识结构的时候。
反复学,最锻炼的是 “归纳整理” 的能力。而且,最有意思的,这在大多数情况下还是自动发生的 —— 只要你不断重复,你的大脑会在不自主之间把那些已经掌握的知识点与当前尚未掌握的知识点区分开来,前者处理起来轻松容易,甚至可以跳过;后者需要投入更多的注意力去仔细处理…… 在这个过程中,绝大多数的归纳整理工作自动完成了。最后再加上一点 “刻意的、收尾性的归纳总结整理工作” —— 大功告成。
绝大多数人总是希望自己一遍就能学会 —— 于是,注定了失败;而面对注定的失败,却并不知道那与天分、智商全无关系,因为谁都是那样的;于是,默默认定自己没有天分,甚至怀疑自己的智商;于是,默默地离开,希望换个地方验证自己的天分与智商;于是,再次面临注定的失败;于是,一而再再而三地被 “证明” 为天分不够智商不够…… 于是,就变成了那条狗:
在一项心理学实验中,狗是被测试对象。把狗关进栅栏里;然而那栅栏并不算太高,原本狗一使劲就能跳过去。但狗带着电项圈,只要它被发现有要跳过栅栏的企图,它就会被电击…… 几次尝试之后,狗就放弃了跳出栅栏 —— 虽然它其实能跳过去。更为惊人的结果是,随后把这条狗关进很低的栅栏,甚至是它都不用跳直接就可以跨过去的栅栏,它也老老实实地呆在栅栏里。
自学是门手艺,编程很大程度上也是一门手艺,掌握它在绝大多数情况下与天分智商全无关系 —— 很多人是在十来岁的时候学会编程的基本技能的。所有的手艺,最基本特征就是:
主要靠时间
这就跟你看人们的车技一样,二十年安全驾龄和刚上路的肯定不一样,但这事跟天分、智商真的没什么关系……
到了第二部分,我们终于进入 “用” 的阶段 —— 嗯?“练” 怎么跳过去了?没有,我们的策略是,以用带练 —— 在不断应用的过程中带动刻意练习。
练和学,是多少有些重合部分的。比如,你可能反复 “学” 了第一部分两三遍,而后就进入了第二部分,开始接触 “用”,在 “用” 的过程中,只要有空,或者只要有需求,你就可能回去 “复习” 一遍第一部分的内容……
无论之前的 “学”,重复了多少遍,一旦开始练,就注定体会到各式各样的笨拙。一会儿漏写了一个引号或者一个括号,一会儿不小心使用了非英文字符的全角符号,要么就是发现自己犯的错误愚蠢且反复发生,比如,语句块起始语句末尾忘了写冒号……
这再正常不过了。
每次自学什么新东西的时候,你就把自己想象成 “再次出生的婴儿” —— 其实每次自学,的的确确都是重生。一旦掌握了一项新的技能,你就不再是从前的那个自己,你是另外一个人了。
看着婴儿蹒跚学步,的确笨拙,但谁会觉得它不可爱呢?
同样的道理,刚开始用一个技能的时候,笨拙其实就是可爱 —— 只不过这时候旁人不再这么觉得而已了,只不过因为你披着一张成年人的皮。然而,你的大脑中正在学习的那一部分,和新生婴儿的大脑没有任何区别。
在第一部分的时候,“练” 的必要其实并不大…… 甚至,因为这是 “过早引用” 太多的知识结构,所以,急于练习反倒会有副作用。由于对自己所面对的复杂知识结构(就是过早引用太多的知识结构)认识不够,没有提前的应对策略,所以,他们根据原本的习惯,边学边练,学不明白当然就练不明白,于是,走着走着就挫败感太强,于是,就自然而然地放弃了…… 而且,弄不好,越练越容易出现 “不必要的挫败感”。
一切 “主要靠时间” 的活动都一样,都需要在从事之前认真做 “心理建设”。通常情况下,读一本教程,上个学习班,就 “会” 了 —— 几乎肯定是错觉或者幻觉。
- 首先要明白,这肯定是个比 “天真的想象” 要长得多的过程。
- 其次要明白,并且要越来越自然地明白,哪儿哪儿都需要很多重复。读,要读很多遍;练,要练很多遍;做,要做很多遍……
有了这样的心理建设,就相对更容易保持耐心。
人们缺乏耐心的常见根源就是 “之前根本就没准备花那么多时间和精力”,所以当然很容易超出 “时间和精力的预算”,当然相对更容易焦虑 —— 就好像没多少本钱的人做生意常常更容易失败一样。
这也解释了为什么我在写这本书的过程中,心中锁定的目标群体是大一学生和高一学生(甚至也有初一学生):
他们最有自学的 “本钱”……
离开学校之后,绝大多数人很难再有 “一看一下午”、“一练一整天”、“一玩一整夜” 的本钱。又由于生活的压力越来越大,对 “能够使用” 新技能的 “需求” 越来越紧迫,于是,对任何一次自学的 “时间精力投资” 都缩手缩脚,小里小气……
预算观念非常重要 —— 这个观念的存在与否,成熟与否,基本上决定一个人未来的盈利能力。
大多数人对此不仅不成熟,甚至干脆没有预算观念!—— 这也是为什么绝大多数人不适合创业的最根本原因。
不夸张地讲,未来的你只需要恪守一个原则,就很可能会因此超越 99% 的人:
绝对不做预算不够的事情。
说来惭愧,我是四十多岁之后,在创业和投资中经历了大量的失败,付了不可想像的学费之后,才深刻理解这条看起来过分简单的原则 —— 亏得本科还是学会计毕业的呢!我的运气在于,在自学这件事上,从来给出的预算都很多……
大约 1984 年,我在远在边疆的延吉市的本地青少年宫参加了一个要交 10 元学费的暑期计算机兴趣班,老师姓金,教的是 BASIC 语言,用的机器是这样的:

它要外接上一个九寸的单色显示器,那时候还没有磁盘,所以,只要一断电,就什么都没有了……
后来上了大学,买书自学 C++,结果在一个地方被卡住了:
我写的代码死活编译不过去…… 当时的编译器错误提醒还不像今天这么完善,当时也没有什么 Google 可以随时看看网上是否早就有人遇到过跟我一样的问题…… 当时我身边根本就没有什么别人在玩这些东西,当时的学校里的电脑还很少,需要提前申请所谓的 “上机时间”,后来呢?后来就放弃了。
当时是什么东西卡住我了呢?说来都能笑死,或者都能被气死:
1 | if (c = 1) { |
习惯于写 BASIC 的我,“被习惯蒙蔽了双眼”,反复检查那么多遍,完全没看到应该写的是 c == 1!
一晃就好几年过去,有一天在书店看到一本 C++ 教程,想起来多年前放弃的东西,就把书买回来,在家里的电脑上重新玩了起来…… 然后就想起来问题在哪儿了,然后这事就被我重新捡起来了……
学完了也就学完了,真没地儿用。没地儿用,当然就很少练。
又过了好几年,我去新东方教书。2003 年,在写词汇书的过程中,需要统计词频,C++ 倒是用不上,用之前学过它的经验,学了一点 Python,写程序统计词频 ——《TOEFL 核心词汇 21 天突破》到今天还在销售。一个当年 10 块钱学费开始学的技能,就因为这本书,这些年给我 “变现” 了很多钱。
我有很多东西都是这样,隔了好多年,才重新捡起来,而后继续前行的。
最搞笑的是弹吉他。
十五六岁的时候,父亲给我买了一把吉他,理由是:
你连唱歌都跑调,将来咋学英语啊?
然后我就开始玩。花 5 块钱上了个培训班,第一天学了一个曲子,第二天就因为打架把吉他砸坏了,害得父亲又去给我买了一把更便宜的……
那个年代学吉他的人,第一首肯定是 “Romance d’Amour”(爱的罗曼史),我当然不例外。那曲子好听啊,好听到弹得不好也好听的地步。
然后吧,有一天,在一姑娘面前显摆,竟然没有弹错!弹完之后很得意…… 结果那姑娘一脸迷茫,隔了两三秒钟说,“不还有第二段吗?” —— 我一脸懵蛋,“…… 啊?”
可是吧,那第二段我终究没有学…… 其实也练过,但后来因为指骨摔断了,所以再后来的许多年,弹吉他只用拨片。直到…… 直到四十五岁那年。有一天,忽然想起这事,于是找来琴谱试了一下,花了一会的时间顺了下来。
所以,我猜我的 “自学能力强” 这件事本身,其实只不过是我投入的预算很多造成的 —— 活到老学到老,在我这里不是空话,所以,相对于别人,我这里只不过是预算太多、太充裕了而已。
于是,我学的时候重复得比别人多;练的时候重复得比别人多;到最后用得也相对比别人多很多 —— 这跟是否有天分或者聪明与否全然没有关系。
当然,学到的东西多了,就变得更聪明了似的。有高中学历的人通常情况下比只有小学学历的人更聪明 —— 其实就是这个原因而已。而这个现象与天生的智商并不总是正相关。
有个现象,不自学的人不知道。
真正开始自学且不断自学之后,刚开始总是觉得时间不够用 —— 因为当时的自己和其他人没什么太大区别。
随着时间的推移,不仅差异会出现,自我认知差异也开始越来越明显:
别人的时间都白过了,自己的时间都有产出……
到了下一个阶段,在其他人不断焦虑的情况下,自己却开始越来越淡定:
因为早已习惯了投入大量时间换取新技能……
等后来真的开始用这些技能做事,不断地做其他人因为时间白过了或者因为投入的 “预算” 不够而学不会做不到的事情 —— 并且还能充分明白,这并不是自己聪明、有天分的结果;只不过是做了该做的事情,投入了该投入的 “成本” 和 “预算” 而已……
于是,就真的能够理解下面这句话背后的深意:
人生很长,何必惊慌。
反正,这事跟天分与智商几乎没有任何关系。
刻意练习
在自学的过程中,总是有一些部分需要刻意练习。就好像小时候我们学习汉字,有些人总是把 “武” 这个字上加上一个撇 —— 对他们来说,不去写那个不该有的撇,就是需要刻意练习的。另外一些人倒是不在这个字上出错,但候和侯傻傻地分不清楚(类似的例子不计其数),那么,对他们来说就有了另外需要刻意练习的地方……
手艺这个东西,尤其需要刻意练习。我们说,手艺么,主要是靠时间…… 这里的 “时间”,准确地讲,就是 “刻意练习” 的时间,而不是任何时间。
我当过很长时间的英语老师。异常苦于一件事:最有用的道理最没人听。
学英语根本就不应该那么难,学了十六年也学不明白 —— 至于嘛!然而,最简单的道理,人们就是听不进去。他们之所以不行,就是因为从未刻意练习。学英语最简单的刻意练习就是朗读。每天朗读一小时,一百天下来就会超越绝大多数人,也会超越自己原本可能永远跨不过去的那个坎 —— 神奇的是,朗读什么无所谓,反正现在有声书那么多…… 更神奇的是,刚开始朗读得好不好听,甚至好不好都无所谓,反正没几天就能体会到大幅进步…… 最神奇的是,这么简单的事,99.99% 的人不做 —— 你身在中国,能理解这个比例真的没有夸张。
顺带推荐一下王渊源(John Gordan)的微信公众号:
清晨朗读会
到 2019 年 2 月 21 日,王渊源同学的清晨朗读会带着大伙朗读了第 1000 天……
许多年前,资质平庸的我,一直苦恼一件事:
- 为什么自己无论干什么都笨手笨脚、差这儿差那儿的……
- 为什么与此同时,总是能看到另外一些人,给人感觉 “一出手就是高手” 呢?!
这事折磨了我好多年…… 直到后来我当了老师,每年面前流过几万名学生之后,我才 “羞耻” 地反应过来:
- 我花在刻意练习上的时间太少了;
- 并且,也没有刻意思考哪些地方我应该去刻意练习。
而那些看起来 “一出手就是高手” 的人,则恰恰相反,他们不仅花很多时间刻意练习,还总是刻意思考在哪些地方尤其要刻意练习 —— 就是这一点差别造成了那么大的差距。
比如,小时候玩琴,因为手骨摔断了,于是就中断了很多刻意练习 —— 后来换成拨片之后,也习惯不好,不做很多基础练习,只是顺着感觉 “胡搞瞎搞”…… 于是,我的琴艺永远是自娱自乐也就刚刚够用的水准,永远上不了下一个台阶。我认识的人之中,许岑同学在这方面就是我这种情况的反向典范。
然而,我深刻地意识到,在另外一些地方,若是再 “混” 下去,那这辈子就别想有什么名堂了。所以,我就下决心在必要的地方一定要刻意地练习。印象中我第一个应用这种思考模式与决心的地方就是写书。我花了很长时间去准备第一本书,并且刻意地思考在哪些地方应该刻意地用力 —— 比如,在取书名这件在别人眼里可能并不是很重要的事上,我每天都琢磨,前后换了二十几个名字,最终选定…… 其后每一本出版的书籍,在书名选择上我都 “殚精竭虑” —— 最终的结果是,我的第一本书就是畅销书、长销书 —— 后面的每一本都是。
对,所谓的 “混”,解释很简单:
不做刻意练习的人就是在混时间。
需要刻意练习的地方,因人而异。有的人就是不可能让 “武” 字带把刀,不需要刻意练习,但另外一些人不是。有些人就是朗读十分钟的效果跟别人朗读一小时的效果一样地好,但更多的人并不是……
然而,这并不是所谓的 “天分” 差异,这大抵上只相当于正态分布坐标略不相同而已。每个人都一样,都有各自必须刻意练习的地方,都有对别人来说无比容易可偏偏对自己来说就是很难的地方,而且,在这件事上,大家的点虽然各不相同,但总体上需要刻意练习的部分比例都差不多 —— 虽然说不清楚那个比例到底是多少。
比如,在学一门新的编程语言时,我常常做这样的刻意练习:
在纸上用笔写程序……
而后,看着纸上的程序,把自己的大脑当作解析器,去判断每一句执行后的结果……
反复确认之后,再在编辑器里输入这个程序 —— 用很慢的速度,确保自己的输入无误……
然后再一运行,十有八九出错 —— 要再反复检查修改很多次才能顺利执行到最后……
为什么要这么做呢?因为我发现自己一旦学另外一个语言的时候,自己的大脑就会经常把这个新的语言与之前学过的其他语言相混淆,这很痛苦。我必须想出一个办法,让之前的也好,之后的也罢,干脆刻在自己的脑子里,不可能相互混淆。
我相信不是所有人都有我这样的烦恼和痛苦,虽然他们在我不烦恼不痛苦的地方也可能烦恼痛苦……
然而,于我来讲,这就是我需要刻意练习的地方 —— 这也是我刻意思考之后才找到的需要刻意练习的地方。
你也一样。你需要刻意练习的地方,需要你自己去刻意思考 —— 你和别人不一样,没有人和你一样,就这样。
这种事情,过去还真的是所谓 “书本上学不到” 的东西 —— 因为没有哪个作者能做到 “遍历世上所有人的所有特殊情况”…… 不过,互联网这本大书貌似正在突破这种限制,因为有无数的作者在写书,每个人所关注的点也不一样,再加上搜索引擎,所以,你总是可以在互联网这本大书中找到 “竟然与我一样的人”!
于是,你可能感受到了,其实吧,所谓 “刻意练习”,其实是 “刻意思考哪里需要刻意练习” 之后最自然不过的事情 —— 所以,“刻意思考” 才是关键。
应对策略很简单:
准备个专门的地方记录
我现在用的最多的就是 iPhone 上的 Notes,一旦遇到什么 “疑似需要刻意练习” 的点,就顺手记录在那里以防不小心忘记或者不小心遗漏。
而后有时间的时候就拿出来看看,排列一下优先级,琢磨一下刻意练习的方式,而后找时间刻意练习,如此这般,做到 “尽量不混日子”……
有时候,刻意练习是很容易的,比如,为了让自己记住当前正在学习的编程语言的语法规则,直至 “刻在脑子里一般”,需要做的无非是把编辑器中的 “Auto completion”(自动补全)先关掉三个月 —— 麻烦一点就麻烦一点,坚决不让 Tab 键帮自己哗啦哗啦写上一大片…… 那不叫麻烦,那叫刻意练习。
人们常说:
凡事,就怕琢磨……
那些高手,无一例外都是善于琢磨的人…… 可是,他们在琢磨什么呢?为什么他们会琢磨那些事呢?
你看,所谓的琢磨,其实真的不是很难,只不过,在此之前,你不知道该琢磨什么而已,一旦知道了,剩下的都再自然不过,都会自然而然地发生 —— 事实上,所谓的差别差距,只不过一线间而已。
为什么从函数开始?
读完第一部分之后,你多多少少已经 “写” 了一些程序,虽然我们总是说,“这就是让你脱盲”;也就是说,从此之后,你多多少少能够读懂程序,这就已经很好了。
可是你无论如何都避免不了已经写了一些,虽然,那所谓的 “写”,不过是 “改” 而已 —— 但毕竟也是一大步。
绝大多数编程书籍并不区分学习者的 “读” 与 “写” 这两个实际上应该分离的阶段 —— 虽然现实中这两个阶段总是多多少少重叠一部分。
在一个比较自然的过程中,我们总是先学会阅读,而后才开始练习写作;并且,最终,阅读的量一定远远大于写作的量 —— 即,输入远远大于输出。当然,貌似也有例外。据说,香港作家倪匡,他自己后来很少读书,每天咣当咣当地像是打扫陈年旧物倒垃圾一样写作 —— 他几乎是全球最具产量的畅销小说作家,貌似地球另外一端的史蒂芬・金都不如他多。又当然,他的主要输入来自于他早年丰富的人生经历,人家读书,他阅世,所以,实际上并不是输入很少,恰恰相反,是输入太多……
所以,正常情况下,输入多于输出,或者,输入远远多于输出,不仅是自然现象,也是无法改变的规则。
于是,我在安排内容的时候,也刻意如此安排。
第一部分,主要在于启动读者在编程领域中的 “阅读能力”,到第二部分,才开始逐步启动读者在编程领域中的 “写作能力”。
在第二部分启动之前,有时间有耐心的读者可以多做一件事情。
Python 的代码是开源的,它的代码仓库在 Github 上:
在这个代码仓库中,有一个目录下,保存着若干 Python Demo 程序:
这个目录下的 README 中有说明:
This directory contains a collection of demonstration scripts for
various aspects of Python programming.
beer.pyWell-known programming example: Bottles of beer.eiffel.pyPython advanced magic: A metaclass for Eiffel post/preconditions.hanoi.pyWell-known programming example: Towers of Hanoi.life.pyCurses programming: Simple game-of-life.markov.pyAlgorithms: Markov chain simulation.mcast.pyNetwork programming: Send and receive UDP multicast packets.queens.pyWell-known programming example: N-Queens problem.redemo.pyRegular Expressions: GUI script to test regexes.rpython.pyNetwork programming: Small client for remote code execution.rpythond.pyNetwork programming: Small server for remote code execution.sortvisu.pyGUI programming: Visualization of different sort algorithms.ss1.pyGUI/Application programming: A simple spreadsheet application.vector.pyPython basics: A vector class with demonstrating special methods.
最起码把这其中的以下几个程序都精读一下,看看自己的理解能力:
- beer.py Well-known programming example: Bottles of beer.
- eiffel.py Python advanced magic: A metaclass for Eiffel post/preconditions.
- hanoi.py Well-known programming example: Towers of Hanoi.
- life.py Curses programming: Simple game-of-life.
- markov.py Algorithms: Markov chain simulation.
- queens.py Well-known programming example: N-Queens problem.
就算读不懂也没关系,把读不懂的部分标记下来,接下来就可以 “带着问题学习”……
在未来的时间里,一个好的习惯就是,有空了去读读别人写的代码 —— 理解能力的提高,就靠这个了。你会发现这事跟其他领域的学习没什么区别。你学英语也一样,读多了,自然就读得快了,理解得快了,并且在那过程中自然而然地习得了很多 “句式”,甚至很多 “说理的方法”、“讲故事的策略”…… 然后就自然而然地会写了,从能写一点开始,慢慢到 “很能写”!
为了顺利启动第一部分的 “阅读”,特意找了个不一样的入口,“布尔运算”;第二部分,从 “阅读” 过渡到 “写作”,我也同样特意寻找了一个不一样的入口:从函数开始写起。
从小入手,从来都是自学的好方法。我们没有想着一上来就写程序,而是写 “子程序”、“小程序”、“短程序”。从结构化编程的角度来看,写函数的一个基本要求就是:
- 完成一个功能;
- 只完成一个功能;
- 没有任何错误地只完成一个功能……
然而,即便是从小入手,任务也没有变得过分简单。其中涉及的话题理解起来并不容易,尽管我们尽量用最简单的例子。涉及的话题有:
- 参数的传递
- 多参数的传递
- 匿名函数以及函数的别称
- 递归函数
- 函数文档
- 模块
- 测试驱动编程
- 可执行程序
这些都是你未来写自己的工程时所必须仰仗的基础,马虎不得,疏漏不得。
另外,这一部分与第一部分有一个刻意不同的编排,这一部分的每一章之后,没有写总结 —— 那个总结需要读者自己动手完成。你需要做的不仅仅是每一个章节的总结,整个第二部分读完之后,还要做针对整个 “深入了解函数”(甚至应该包括第一部分已经读过的关于函数的内容)的总结…… 并且,关于函数,这一章并未完全讲完呢,第三部分还有生成器、迭代器、以及装饰器要补充 —— 因为它们多多少少都涉及到下一部分才能深入的内容,所以,在这一部分就暂时没有涉及。
你要习惯,归纳、总结、整理的工作,从来都不是一次就能完成的,都需要反复多次之后才能彻底完成。必须习惯这种流程 —— 而不是像那些从未自学过的人一样,对这种东西想当然地全不了解。
另外,从现代编程方法论来看,“写作” 部分一上来就从函数入手也的确是 “更正确” 的,因为结构化编程的核心就是拆分任务,把任务拆分到不能再拆分为止 —— 什么时候不能再拆分了呢?就是当一个函数只完成一个功能的时候……
关于参数(上)
之前就提到过,从结构上来看,每个函数都是一个完整的程序,因为一个程序,核心构成部分就是输入、处理、输出:
- 它可以有输入 —— 即,它能接收外部通过参数传递的值;
- 它可以有处理 —— 即,内部有能够完成某一特定任务的代码;尤其是,它可以根据 “输入” 得到 “输出”;
- 它可以有输出 —— 即,它能向外部输送返回值……
所以,在我看来,有了一点基础知识之后,最早应该学习的是 “如何写函数” —— 这个起点会更好一些。
这一章的内容,看起来会感觉与 Part1.E.4 函数那一章部分重合。但这两章的出发点不一样:
- Part1.E.4 函数那一章,只是为了让读者有 “阅读” 函数说明文档的能力;
- 这一章,是为了让读者能够开始动手写函数给自己或别人用……
为函数取名
哪怕一个函数内部什么都不干,它也得有个名字,然后名字后面要加上圆括号 (),以明示它是个函数,而不是某个变量。
定义一个函数的关键字是 def,以下代码定义了一个什么都不干的函数:
1 | def do_nothing(): |
为函数取名(为变量取名也一样)有些基本的注意事项:
首先,名称不能以数字开头。能用在名称开头的有,大小写字母和下划线
_;其次,名称中不能有空格,要么使用下划线连接词汇,如,
do_nothing,要么使用 Camel Case,如doNothing—— 更推荐使用下划线;再次,名称不能与关键字重合 —— 以下是 Python 的 Keyword List:
| - | Python | Keyword | List | - |
|---|---|---|---|---|
and |
as |
assert |
async |
await |
break |
class |
continue |
def |
del |
elif |
else |
except |
False |
finally |
for |
from |
global |
if |
import |
in |
is |
lambda |
None |
nonlocal |
not |
or |
pass |
raise |
return |
True |
try |
while |
with |
yield |
你随时可以用以下代码查询关键字列表:
1 | from IPython.core.interactiveshell import InteractiveShell |
['False',
'None',
'True',
'and',
'as',
'assert',
'async',
'await',
'break',
'class',
'continue',
'def',
'del',
'elif',
'else',
'except',
'finally',
'for',
'from',
'global',
'if',
'import',
'in',
'is',
'lambda',
'nonlocal',
'not',
'or',
'pass',
'raise',
'return',
'try',
'while',
'with',
'yield']
True
关于更多为函数、变量取名所需要的注意事项,请参阅:
注:PEPs,是 Python Enhancement Proposals 的缩写:https://www.python.org/dev/peps/
不接收任何参数的函数
在定义函数的时候,可以定义成不接收任何参数;但调用函数的时候,依然需要写上函数名后面的圆括号 ():
1 | def do_something(): |
This is a hello message from do_something().
没有 return 语句的函数
函数内部,不一定非要有 return 语句 —— 上面 do_somthing() 函数就没有 return 语句。但如果函数内部并未定义返回值,那么,该函数的返回值是 None,当 None 被当作布尔值对待的时候,相当于是 False。
这样的设定,使得函数调用总是可以在条件语句中被当作判断依据:
1 | def do_something(): |
This is a hello message from do_something().
The return value of 'do_something()' is None.
if not do_something(): 翻译成自然语言,应该是,“如果 do_something() 的返回值是 ‘非真’,那么:……”
接收外部传递进来的值
让我们写个判断闰年年份的函数,取名为 is_leap(),它接收一个年份为参数,若是闰年,则返回 True,否则返回 False。
根据闰年的定义:
- 年份应该是 4 的倍数;
- 年份能被 100 整除但不能被 400 整除的,不是闰年。
所以,相当于要在能被 4 整除的年份中,排除那些能被 100 整除却不能被 400 整除的年份。
1 | def is_leap(year): |
False
True
False
True
1 | # 另外一个更为简洁的版本,理解它还挺练脑子的 |
False
函数可以同时接收多个参数。比如,我们可以写个函数,让它输出从大于某个数字到小于另外一个数字的斐波那契数列;那就需要定义两个参数,调用它的时候也需要传递两个参数:
1 | def fib_between(start, end): |
144 233 377 610 987 1597 2584 4181 6765
当然可以把这个函数写成返回值是一个列表:
1 | def fib_between(start, end): |
[144, 233, 377, 610, 987, 1597, 2584, 4181, 6765]
变量的作用域
下面的代码,经常会让初学者迷惑:
1 | def increase_one(n): |
2
当 increase_one(n) 被调用之后,n 的值究竟是多少呢?或者更准确点问,随后的 print(n) 的输出结果应该是什么呢?
输出结果是 1。
在程序执行过程中,变量有全局变量(Global Variables)和局域变量(Local Variables)之分。
首先,每次某个函数被调用的时候,这个函数会开辟一个新的区域,这个函数内部所有的变量,都是局域变量。也就是说,即便那个函数内部某个变量的名称与它外部的某个全局变量名称相同,它们也不是同一个变量 —— 只是名称相同而已。
其次,更为重要的是,当外部调用一个函数的时候,准确地讲,传递的不是变量,而是那个变量的值。也就是说,当
increase_one(n)被调用的时候,被传递给那个恰好名称也叫n的局域变量的,是全局变量n的值,1。而后,
increase_one()函数的代码开始执行,局域变量n经过n += 1之后,其中存储的值是2,而后这个值被return语句返回,所以,print(increase(n))所输出的值是函数被调用之后的返回值,即,2。然而,全局变量
n的值并没有被改变,因为局部变量n(它的值是2)和全局变量n(它的值还是1)只不过是名字相同而已,但它们并不是同一个变量。
以上的文字,可能需要反复阅读若干遍;几遍下来,消除了疑惑,以后就彻底没问题了;若是这个疑惑并未消除,或者关键点并未消化,以后则会反复被这个疑惑所坑害,浪费无数时间。
不过,有一种情况要格外注意 —— 在函数内部处理被传递进来的值是可变容器(比如,列表)的时候:
1 | def be_careful(a, b): |
(1, ['What?!', 2, 3])
所以,一个比较好的习惯是,如果传递进来的值是列表,那么在函数内部对其操作之前,先创建一个它的拷贝:
1 | def be_careful(a, b): |
(1, [1, 2, 3])
关于参数(下)
可以接收一系列值的位置参数
如果你在定义参数的时候,在一个位置参数(Positional Arguments)前面标注了星号,*,那么,这个位置参数可以接收一系列值,在函数内部可以对这一系列值用 for ... in ... 循环进行逐一的处理。
带一个星号的参数,英文名称是 “Arbitrary Positional Arguments”,姑且翻译为 “随意的位置参数”。
还有带两个星号的参数,一会儿会讲到,英文名称是 “Arbitrary Keyword Arguments”,姑且翻译为 “随意的关键字参数”。
有些中文书籍把 “Arbitrary Positional Arguments” 翻译成 “可变位置参数”。事实上,在这样的地方,无论怎样的中文翻译都是令人觉得非常吃力的。前面的这个翻译还好了,我还见过把 “Arbitrary Keyword Arguments” 翻译成 “武断的关键字参数” 的 —— 我觉得这样的翻译肯定会使读者产生说不明道不白的疑惑。
所以,入门之后就尽量只用英文是个好策略。虽然刚开始有点吃力,但后面会很省心,很长寿 —— 是呀,少浪费时间、少浪费生命,其实就相当于更长寿了呀!
1 | def say_hi(*names): |
Hi, ann!
Hi, mike!
Hi, john!
Hi, zeo!
say_hi() 这一行没有任何输出。因为你在调用函数的时候,没有给它传递任何值,于是,在函数内部代码执行的时候,name in names 的值是 False,所以,for 循环内部的代码没有被执行。
在函数内部,是把 names 这个参数当作容器处理的 —— 否则也没办法用 for ... in ... 来处理。而在调用函数的时候,我们是可以将一个容器传递给函数的 Arbitrary Positional Arguments 的 —— 做法是,在调用函数的时候,在参数前面加上星号 *:
1 | def say_hi(*names): |
Hi, mike!
Hi, john!
Hi, zeo!
实际上,因为以上的 say_hi(*names) 函数内部就是把接收到的参数当作容器处理的,于是,在调用这个函数的时候,向它传递任何容器都会被同样处理:
1 | def say_hi(*names): |
Hi, P!
Hi, y!
Hi, t!
Hi, h!
Hi, o!
Hi, n!
Hi, 0!
Hi, 1!
Hi, 2!
Hi, 3!
Hi, 4!
Hi, 5!
Hi, 6!
Hi, 7!
Hi, 8!
Hi, 9!
Hi, 10!
Hi, 9!
Hi, 8!
Hi, 7!
Hi, 6!
Hi, 5!
Hi, 4!
Hi, 3!
Hi, 2!
Hi, 1!
Hi, ann!
Hi, mike!
Hi, joe!
在定义可以接收一系列值的位置参数时,建议在函数内部为该变量命名时总是用复数,因为函数内部,总是需要 for 循环去迭代元组中的元素,这样的时候,名称的复数形式对代码的可读性很有帮助 —— 注意以上程序第二行。以中文为母语的人,在这个细节上常常感觉 “不堪重负” —— 因为中文的名词没有复数 —— 但必须习惯。(同样的道理,若是用拼音命名变量,就肯定是为将来挖坑……)
注意:一个函数中,可以接收一系列值的位置参数只能有一个;并且若是还有其它位置参数存在,那就必须把这个可以接收一系列值的位置参数排在所有其它位置参数之后。
1 | def say_hi(greeting, *names): |
Hello, Mike!
Hello, John!
Hello, Zeo!
为函数的某些参数设定默认值
可以在定义函数的时候,为某些参数设定默认值,这些有默认值的参数,又被称作关键字参数(Keyword Arguments)。从这个函数的 “用户” 角度来看,这些设定了默认值的参数,就成了 “可选参数”。
1 | def say_hi(greeting, *names, capitalized=False): |
Hello, mike!
Hello, john!
Hello, zeo!
Hello, Mike!
Hello, John!
Hello, Zeo!
可以接收一系列值的关键字参数
之前我们看到,可以设定一个位置参数(Positional Argument),接收一系列的值,被称作 “Arbitrary Positional Argument”;
同样地,我们也可以设定一个可以接收很多值的关键字参数(Arbitrary Keyword Argument)。
1 | def say_hi(**names_greetings): |
Hello, mike!
Oh, my darling, ann!
Hi, john!
既然在函数内部,我们在处理接收到的 Arbitrary Keyword Argument 时,用的是对字典的迭代方式,那么,在调用函数的时候,也可以直接使用字典的形式:
1 | def say_hi(**names_greetings): |
Hello, mike!
Oh, my darling, ann!
Hi, john!
Hello, mike!
Oh, my darling, ann!
Hi, john!
至于在函数内部,你用什么样的迭代方式去处理这个字典,是你自己的选择:
1 | def say_hi_2(**names_greetings): |
Hello, mike!
Oh, my darling, ann!
Hi, john!
函数定义时各种参数的排列顺序
在定义函数的时候,各种不同类型的参数应该按什么顺序摆放呢?对于之前写过的 say_hi() 这个函数,
1 | def say_hi(greeting, *names, capitalized=False): |
Hi, mike!
Hi, john!
Hi, zeo!
Welcome, Mike!
Welcome, John!
Welcome, Zeo!
如果,你想给其中的 greeting 参数也设定个默认值怎么办?写成这样好像可以:
1 | def say_hi(greeting='Hello', *names, capitalized=False): |
Hi, mike!
Hi, john!
Hi, zeo!
Welcome, Mike!
Welcome, John!
Welcome, Zeo!
但 greeting 这个参数虽然有默认值,可这个函数在被调用的时候,还是必须要给出这个参数,否则输出结果出乎你的想象:
1 | def say_hi(greeting='Hello', *names, capitalized=False): |
mike, john!
mike, zeo!
设定了默认值的 greeting,竟然不像你想象的那样是 “可选参数”!所以,你得这样写:
1 | def say_hi(*names, greeting='Hello', capitalized=False): |
Hello, mike!
Hello, john!
Hello, zeo!
Hi, mike!
Hi, john!
Hi, zeo!
这是因为函数被调用时,面对许多参数,Python 需要按照既定的规则(即,顺序)判定每个参数究竟是哪一类型的参数:
Order of Arguments
- Positional
- Arbitrary Positional
- Keyword
- Arbitrary Keyword
所以,即便你在定义里写成
1 | def say_hi(greeting='Hello', *names, capitalized=False): |
在调用该函数的时候,无论你写的是1
say_hi('Hi', 'mike', 'john', 'zeo')
还是1
say_hi('mike', 'john', 'zeo')
Python 都会认为接收到的第一个值是 Positional Argument —— 因为在定义中,greeting 被放到了 Arbitrary Positional Arguments 之前。
化名与匿名
化名
在 Python 中,我们可以给一个函数取个化名(alias)。
以下的代码,我们先是定义了一个名为 _is_leap 的函数,而后为它另取了一个化名:
1 | from IPython.core.interactiveshell import InteractiveShell |
<function __main__._is_leap(year)>
True
4547071648
4547071648
function
function
我们可以看到的是,id(year_leap_bool) 和 id(_is_leap) 的内存地址是一样的 —— 它们是同一个对象,它们都是函数。所以,当你写 year_leap_bool = _is_leap 的时候,相当于给 _is_leap() 这个函数取了个化名。
在什么样的情况下,要给一个函数取一个化名呢?
在任何一个工程里,为函数或者变量取名都是很简单却不容易的事情 —— 因为可能会重名(虽然已经尽量用变量的作用域隔离了),可能会因取名含混而令后来者费解……
所以,仅仅为了少敲几下键盘而给一个函数取个更短的化名,实际上并不是好主意,更不是好习惯。尤其现在的编辑器都支持自动补全和多光标编辑的功能,变量名再长都不构成负担。
更多的时候,为函数取一个化名,应该是为了提高代码可读性 —— 对自己或其他人都很重要。
lambda
写一个很短的函数可以用 lambda 关键字。
下面是用 def 关键字写函数:
1 | def add(x, y): |
8
下面是用 lambda 关键字写函数:
1 | add = lambda x, y: x + y |
8
lambda 的语法结构如下:
lambda_expr ::= "lambda" [parameter_list] ":" expression
以上使用的是 BNF 标注。当然,BNF 是你目前并不熟悉的,所以,有疑惑别当回事。
反正你已经见到示例了:
1 | lambda x, y: x + y |
先写上 lambda 这个关键字,其后分为两个部分,: 之前是参数,之后是表达式;这个表达式的值,就是这个函数的返回值。
注意:
lambda语句中,:之后有且只能有一个表达式。
而这个函数呢,没有名字,所以被称为 “匿名函数”。
add = lambda x, y: x + y
就相当于是给一个没有名字的函数取了个名字。
lambda 的使用场景
那 lambda 这种匿名函数的用处在哪里呢?
作为某函数的返回值
第一个常见的用处是作为另外一个函数的返回值。
让我们看看 The Python Tutorial 中的一个例子。
1 | def make_incrementor(n): |
42
43
这个例子乍看起来很令人迷惑。我们先看看 f = make_incrementor(42) 之后,f 究竟是什么东西:
1 | def make_incrementor(n): |
<function __main__.make_incrementor.<locals>.<lambda>(x)>
4428443296
4428726888
首先,要注意,f 并不是 make_incrementor() 这个函数的化名,如果是给这个函数取个化名,写法应该是:
1 | f = make_incrementor |
那 f 是什么呢?它是 <function __main__.make_incrementor.<locals>.<lambda>(x)>:
f = make_incrementor(42)是将make_incrementor(42)的返回值保存到f这个变量之中;- 而
make_incrementor()这个函数接收到42这个参数之后,返回了一个函数:lambda x: x + 42;- 于是,
f中保存的函数是lambda x: x + 42;- 所以,
f(0)是向这个匿名函数传递了0,而后,它返回的是0 + 42。
作为某函数的参数
可以拿一些可以接收函数为参数的内建函数做例子。比如,map()。
map(function, iterable, …)Return an iterator that applies function to every item of iterable, yielding the results. If additional iterable arguments are passed, function must take that many arguments and is applied to the items from all iterables in parallel. With multiple iterables, the iterator stops when the shortest iterable is exhausted. For cases where the function inputs are already arranged into argument tuples, see
itertools.starmap().
map() 这个函数的第一个参数,就是用来接收函数的。随后的参数,是 iterable —— 就是可被迭代的对象,比如,各种容器,例如:列表、元组、字典什么的。
1 | def double_it(n): |
[2, 4, 6, 8, 10, 12]
[2, 4, 6, 8, 10, 12]
显然用 lambda 更为简洁。另外,类似完成 double_it(n) 这种简单功能的函数,常常有 “用过即弃” 的必要。
1 | phonebook = [ |
[{'name': 'john', 'phone': 9876},
{'name': 'mike', 'phone': 5603},
{'name': 'stan', 'phone': 6898},
{'name': 'eric', 'phone': 7898}]
['john', 'mike', 'stan', 'eric']
[9876, 5603, 6898, 7898]
可以给 map() 传递若干个可被迭代对象:
1 | a_list = [1, 3, 5] |
[2, 12, 30]
以上的例子都弄明白了,再去看 The Python Tutorial 中的例子,就不会有任何疑惑了:
1 | pairs = [(1, 'one'), (2, 'two'), (3, 'three'), (4, 'four')] |
[(4, 'four'), (1, 'one'), (3, 'three'), (2, 'two')]
递归函数
递归(Recursion)
在函数中有个理解门槛比较高的概念:递归函数(Recursive Functions)—— 那些在自身内部调用自身的函数。说起来都比较拗口。
先看一个例子,我们想要有个能够计算 n 的阶乘(factorial)n! 的函数,f(),规则如下:
n! = n × (n-1) × (n-2)... × 1- 即,
n! = n × (n-1)!- 且,
n >= 1注意:以上是数学表达,不是程序,所以,
=在这一小段中是 “等于” 的意思,不是程序语言中的赋值符号。
于是,计算 f(n) 的 Python 程序如下:
1 | def f(n): |
120
递归函数的执行过程
以 factorial(5) 为例,让我们看看程序的流程:

当 f(5) 被调用之后,函数开始运行……
- 因为
5 > 1,所以,在计算n * f(n-1)的时候要再次调用自己f(4);所以必须等待f(4)的值返回; - 因为
4 > 1,所以,在计算n * f(n-1)的时候要再次调用自己f(3);所以必须等待f(3)的值返回; - 因为
3 > 1,所以,在计算n * f(n-1)的时候要再次调用自己f(2);所以必须等待f(2)的值返回; - 因为
2 > 1,所以,在计算n * f(n-1)的时候要再次调用自己f(1);所以必须等待f(1)的值返回; - 因为
1 == 1,所以,这时候不会再次调用f()了,于是递归结束,开始返回,这次返回的是1; - 下一步返回的是
2 * 1; - 下一步返回的是
3 * 2; - 下一步返回的是
4 * 6; - 下一步返回的是
5 * 24—— 至此,外部调用f(5)的最终返回值是120……
加上一些输出语句之后,能更清楚地看到大概的执行流程:
1 | def f(n): |
Call f(5)...
n = 5
n = 4
n = 3
n = 2
n = 1
Returning...
n = 1 return: 1
n = 2 return: 2
n = 3 return: 6
n = 4 return: 24
n = 5 return: 120
Get out of f(n), and f(5) = 120
有点烧脑…… 不过,分为几个层面去逐个突破,你会发现它真的很好玩。
递归的终点
递归函数在内部必须有一个能够让自己停止调用自己的方式,否则永远循环下去了……
其实,我们所有人很小就见过递归应用,只不过,那时候不知道那就是递归而已。听过那个无聊的故事罢?
山上有座庙,庙里有个和尚,和尚讲故事,说……
山上有座庙,庙里有个和尚,和尚讲故事,说……
山上有座庙,庙里有个和尚,和尚讲故事,说……
写成 Python 程序大概是这样:
1 | def a_monk_telling_story(): |
这是个无限循环的递归,因为这个函数里没有设置中止自我调用的条件。无限循环还有个不好听的名字,叫做 “死循环”。
在著名的电影盗梦空间(2010)里,从整体结构上来看,“入梦” 也是个 “递归函数”。只不过,这个函数和 a_monk_telling_story() 不一样,它并不是死循环 —— 因为它设定了中止自我调用的条件:
在电影里,醒过来的条件有两个
- 一个是在梦里死掉;
- 一个是在梦里被 kicked 到……
如果这两个条件一直不被满足,那就进入 limbo 状态 —— 其实就跟死循环一样,出不来了……
为了演示,我把故事情节改变成这样:
- 入梦,
in_dream(),是个递归函数;- 入梦之后醒过来的条件有两个:
- 一个是在梦里死掉,
dead is True;- 一个是在梦里被 kicked,
kicked is True……以上两个条件中任意一个被满足,就苏醒……
至于为什么会死掉,如何被 kick,我偷懒了一下:管它怎样,管它如何,反正,每个条件被满足的概率是 1/10……(也只有这样,我才能写出一个简短的,能够运行的 “盗梦空间程序”。)
把这个很抽象的故事写成 Python 程序,看看一次入梦之后能睡多少天,大概是这样:
1 | import random |
dead: False kicked: False
dead: False kicked: False
dead: False kicked: False
dead: False kicked: False
dead: False kicked: False
dead: False kicked: False
dead: False kicked: False
dead: True kicked: True
I slept 8 days, and was dead to wake up...
The in_dream() function returns: 8
如果疑惑为什么 random.randrange(0,10) 能表示 1/10 的概率,请返回去重新阅读第一部分中关于布尔值的内容。
另外,在 Python 中,若是需要将某个值与 True 或者 False 进行比较,尤其是在条件语句中,推荐写法是(参见 PEP8):
1 | if condition: |
就好像上面代码中的 if dead: 一样。
而不是(虽然这么写通常也并不妨碍程序正常运行[1]):
1 | if condition is True: |
抑或:
1 | if condition == True: |
让我们再返回来接着讲递归函数。正常的递归函数一定有个退出条件。否则的话,就无限循环下去了…… 下面的程序在执行一会儿之后就会告诉你:RecursionError: maximum recursion depth exceeded(上面那个 “山上庙里讲故事的和尚说” 的程序,真要跑起来,也是这样):
1 | def x(n): |
---------------------------------------------------------------------------
RecursionError Traceback (most recent call last)
<ipython-input-3-daa4d33fb39b> in <module>
1 def x(n):
2 return n * x(n-1)
----> 3 x(5)
<ipython-input-3-daa4d33fb39b> in x(n)
1 def x(n):
----> 2 return n * x(n-1)
3 x(5)
... last 1 frames repeated, from the frame below ...
<ipython-input-3-daa4d33fb39b> in x(n)
1 def x(n):
----> 2 return n * x(n-1)
3 x(5)
RecursionError: maximum recursion depth exceeded
不用深究上面盗梦空间这个程序的其它细节,不过,通过以上三个递归程序 —— 两个很扯淡的例子,一个正经例子 —— 你已经看到了递归函数的共同特征:
- 在
return语句中返回的是自身的调用(或者是含有自身的表达式)- 为了避免死循环,一定要有至少一个条件下返回的不再是自身调用……
变量的作用域
再回来看计算阶乘的程序 —— 这是正经程序。这次我们把程序名写完整,factorial():
1 | def factorial(n): |
120
最初的时候,这个函数的执行流程之所以令人迷惑,是因为初学者对变量的作用域把握得不够充分。
变量根据作用域,可以分为两种:全局变量(Global Variables)和局部变量(Local Variables)。
可以这样简化理解:
- 在函数内部被赋值而后使用的,都是局部变量,它们的作用域是局部,无法被函数外的代码调用;
- 在所有函数之外被赋值而后开始使用的,是全局变量,它们的作用域是全局,在函数内外都可以被调用。
定义如此,但通常程序员们会严格地遵守一条原则:
在函数内部绝对不调用全局变量。即便是必须改变全局变量,也只能通过函数的返回值在函数外改变全局变量。
你也必须遵守同样的原则。而这个原则同样可以在日常的工作生活中 “调用”:
做事的原则:自己的事自己做,别人的事,最多通过自己的产出让他们自己去搞……
再仔细观察一下以下代码。当一个变量被当做参数传递给一个函数的时候,这个变量本身并不会被函数所改变。比如,a = 5,而后,再把 a 当作参数传递给 f(a) 的时候,这个函数当然应该返回它内部任务完成之后应该传递回来的值,但 a 本身不会被改变。
1 | def factorial(n): |
5 120
120 120
理解了这一点之后,再看 factorial() 这个递归函数的递归执行过程,你就能明白这个事实:
在每一次 factorial(n) 被调用的时候,它都会形成一个作用域,
n这个变量作为参数把它的值传递给了函数,但是,n这个变量本身并不会被改变。
我们再修改一下上面的代码:
1 | def factorial(n): |
5 120
在 m = factorial(n) 这一句中,n 被 factorial() 当做参数调用了,但无论函数内部如何操作,并不会改变变量 n 的值。
关键的地方在这里:在函数内部出现的变量 n,和函数外部的变量 n 不是一回事 —— 它们只是名称恰好相同而已,函数参数定义的时候,用别的名称也没什么区别:
1 | def factorial(x): # 在这个语句块中出现的变量,都是局部变量 |
5 120
函数开始执行的时候,x 的值,是由外部代码(即,函数被调用的那一句)传递进来的。即便函数内部的变量名称与外部的变量名称相同,它们也不是同一个变量。
递归函数三原则
现在可以小小总结一下了。
一个递归函数,之所以是一个有用、有效的递归函数,是因为它要遵守递归三原则。正如,一个机器人之所以是个合格的机器人,是因为它遵循阿西莫夫三铁律(Three Laws of Robotics)一样[2]。
- 根据定义,递归函数必须在内部调用自己;
- 必须设定一个退出条件;
- 递归过程中必须能够逐步达到退出条件……
从这个三原则望过去,factorial() 是个合格有效的递归函数,满足第一条,满足第二条,尤其还满足第三条中的 “逐步达到”!
而那个扯淡的盗梦空间递归程序,说实话,不太合格,虽然它满足第一条,也满足第二条,第三条差点蒙混过关:它不是逐步达到,而是不管怎样肯定能达到 —— 这明显是两回事…… 原谅它罢,它的作用就是当例子,一次正面的,一次负面的,作为例子算是功成圆满了!
刚开始的时候,初学者好不容易搞明白递归函数究竟是怎么回事之后,就不由自主地想 “我如何才能学会递归式思考呢?” —— 其实吧,这种想法本身可能并不是太正确或者准确。
准确地讲,递归是一种解决问题的方式。当我们需要解决的问题,可以被逐步拆分成很多越来越小的模块,然后每个小模块还都能用同一种算法处理的时候,用递归函数最简洁有效。所以,只不过是在遇到可以用递归函数解决问题的时候,才需要去写递归函数。
从这个意义上来看,递归函数是程序员为了自己方便而使用的,并不是为了计算机方便而使用 —— 计算机么,你给它的任务多一点或者少一点,对它来讲无所谓,反正有电就能运转,它自己又不付电费……
理论上来讲,所有用递归函数能完成的任务,不用递归函数也能完成,只不过代码多一点,啰嗦一点,看起来没有那么优美而已。
还有,递归,不像 “序列类型” 那样,是某个编程语言的特有属性。它其实是一种特殊算法,也是一种编程技巧,任何编程语言,都可以使用递归算法,都可以通过编写递归函数巧妙地解决问题。
但是,学习递归函数本身就很烧脑啊!这才是最大的好事。从迷惑,到不太迷惑,到清楚,到很清楚,再到特别清楚 —— 这是个非常有趣,非常有成就感的过程。
这种过程锻炼的是脑力 —— 在此之后,再遇到大多数人难以理解的东西,你就可以使用这一次积累的经验,应用你已经磨炼过的脑力。有意思。
至此,封面上的那个 “伪代码” 应该很好理解了:
1 | def teach_yourself(anything): |
自学还真的就是递归函数呢……
思考与练习
普林斯顿大学的一个网页,有很多递归的例子
https://introcs.cs.princeton.edu/java/23recursion/
脚注
[1]:参见 Stackoverflow 上的讨论:Boolean identity == True vs is True
[2]:关于阿西莫夫三铁律(Three Laws of Robotics)的类比,来自著名的 Python 教程,Think Python: How to Think Like a Computer Scientist
函数的文档
你在调用函数的时候,你像是函数这个产品的用户。
而你写一个函数,像是做一个产品,这个产品将来可能会被很多用户使用 —— 包括你自己。
产品,就应该有产品说明书,别人用得着,你自己也用得着 —— 很久之后的你,很可能把当初的各种来龙去脉忘得一干二净,所以也同样需要产品说明书,别看那产品曾经是你自己设计的。
Python 在这方面很用功,把函数的 “产品说明书” 当作语言内部的功能,这也是为什么 Python 有 Sphinx 这种工具,而绝大多数其他语言没有的原因之一罢。
Docstring
在函数定义内部,我们可以加上 Docstring;将来函数的 “用户” 就可以通过 help() 这个内建函数,或者 .__doc__ 这个 Method 去查看这个 Docstring,即,该函数的 “产品说明书”。
先看一个 Docstring 以及如何查看某个函数的 Docstring 的例子:
1 | def is_prime(n): |
Help on function is_prime in module __main__:
is_prime(n)
Return a boolean value based upon
whether the argument n is a prime number.
Return a boolean value based upon
whether the argument n is a prime number.
'\n Return a boolean value based upon\n whether the argument n is a prime number.\n '
Docstring 可以是多行字符串,也可以是单行字符串:
1 | def is_prime(n): |
Help on function is_prime in module __main__:
is_prime(n)
Return a boolean value based upon whether the argument n is a prime number.
Return a boolean value based upon whether the argument n is a prime number.
'Return a boolean value based upon whether the argument n is a prime number.'
Docstring 如若存在,必须在函数定义的内部语句块的开头,也必须与其它语句一样保持相应的缩进(Indention)。Docstring 放在其它地方不起作用:
1 | def is_prime(n): |
Help on function is_prime in module __main__:
is_prime(n)
None
书写 Docstring 的规范
规范,虽然是人们最好遵守的,但其实通常是很多人并不遵守的东西。
既然学,就要像样 —— 这真的很重要。所以,非常有必要认真阅读 Python PEP 257 关于 Docstring 的规范。
简要总结一下 PEP 257 中必须掌握的规范:
- 无论是单行还是多行的 Docstring,一概使用三个双引号扩起;
- 在 Docstring 内部,文字开始之前,以及文字结束之后,都不要有空行;
- 多行 Docstring,第一行是概要,随后空一行,再写其它部分;
- 完善的 Docstring,应该概括清楚以下内容:参数、返回值、可能触发的错误类型、可能的副作用,以及函数的使用限制等等;
- 每个参数的说明都使用单独的一行……
由于我们还没有开始研究 Class,所以,关于 Class 的 Docstring 应该遵守什么样的规范就暂时略过了。然而,这种规范你总是要反复去阅读参照的。关于 Docstring,有两个规范文件:
需要格外注意的是:
Docstring 是写给人看的,所以,在复杂代码的 Docstring 中,写 Why 要远比写 What 更重要 —— 你先记住这点,以后的体会自然会不断加深。
Sphinx 版本的 Docstring 规范
Sphinx 可以从 .py 文件里提取所有 Docstring,而后生成完整的 Documentation。将来若是你写大型的项目,需要生成完善的文档的时候,你就会发现 Sphinx 是个 “救命” 的家伙,省时、省力、省心、省命……
在这里,没办法一下子讲清楚 Sphinx 的使用,尤其是它还用它自己的一种标记语言,reStructureText,文件尾缀使用 .rst……
但是,可以看一个例子:
1 | class Vehicle(object): |
Help on class Vehicle in module __main__:
class Vehicle(builtins.object)
| Vehicle(arg, *args, **kwargs)
|
| The Vehicle object contains lots of vehicles
| :param arg: The arg is used for ...
| :type arg: str
| :param `*args`: The variable arguments are used for ...
| :param `**kwargs`: The keyword arguments are used for ...
| :ivar arg: This is where we store arg
| :vartype arg: str
|
| Methods defined here:
|
| __init__(self, arg, *args, **kwargs)
| Initialize self. See help(type(self)) for accurate signature.
|
| cars(self, distance, destination)
| We can't travel a certain distance in vehicles without fuels, so here's the fuels
|
| :param distance: The amount of distance traveled
| :type amount: int
| :param bool destinationReached: Should the fuels be refilled to cover required distance?
| :raises: :class:`RuntimeError`: Out of fuel
|
| :returns: A Car mileage
| :rtype: Cars
|
| ----------------------------------------------------------------------
| Data descriptors defined here:
|
| __dict__
| dictionary for instance variables (if defined)
|
| __weakref__
| list of weak references to the object (if defined)
通过插件,Sphinx 也能支持 Google Style Docstring 和 Numpy Style Docstring。
以下两个链接,放在这里,以便你将来查询:
保存到文件的函数
写好的函数,当然最好保存起来,以便将来随时调用。
模块
我们可以将以下内容保存到一个名为 mycode.py 的文件中 —— 这样可以被外部调用的 .py 文件,有个专门的称呼,模块(Module)—— 于是,它(任何一个 .py 文件)也可以被称为模块:
1 | # %load mycode.py |
而后,我们就可以在其它地方这样使用(以上代码现在已经保存在当前工作目录中的 mycode.py):
1 | from IPython.core.interactiveshell import InteractiveShell |
Help on function is_prime in module mycode:
is_prime(n)
Return a boolean value based upon
whether the argument n is a prime number.
Help on function say_hi in module mycode:
say_hi(*names, greeting='Hello', capitalized=False)
Print a string, with a greeting to everyone.
:param *names: tuple of names to be greeted.
:param greeting: 'Hello' as default.
:param capitalized: Whether name should be converted to capitalzed before print. False as default.
:returns: None
'mycode'
True
Hello, mike!
Hello, zoe!
以上这个模块(Module)的名称,就是 mycode。
模块文件系统目录检索顺序
当你向 Python 说 import ... 的时候,它要去寻找你所指定的文件,那个文件应该是 import 语句后面引用的名称,再加上 .py 构成的名字的文件。Python 会按照以下顺序去寻找:
- 先去看看内建模块里有没有你所指定的名称;
- 如果没有,那么就按照
sys.path所返回的目录列表顺序去找。
你可以通过以下代码查看你自己当前机器的 sys.path:
1 | import sys |
在 sys.path 所返回的目录列表中,你当前的工作目录排在第一位。
有时,你需要指定检索目录,因为你知道你要用的模块文件在什么位置,那么可以用 sys.path.append() 添加一个搜索位置:
1 | import sys |
系统内建的模块
你可以用以下代码获取系统内建模块的列表:
1 | from IPython.core.interactiveshell import InteractiveShell |
('_abc',
'_ast',
'_codecs',
'_collections',
'_functools',
'_imp',
'_io',
'_locale',
'_operator',
'_signal',
'_sre',
'_stat',
'_string',
'_symtable',
'_thread',
'_tracemalloc',
'_warnings',
'_weakref',
'atexit',
'builtins',
'errno',
'faulthandler',
'gc',
'itertools',
'marshal',
'posix',
'pwd',
'sys',
'time',
'xxsubtype',
'zipimport')
True
False
跟变量名、函数名,不能与关键字重名一样,你的模块名称也最好别与系统内建模块名称重合。
引入指定模块中的特定函数
当你使用 import mycode 的时候,你向当前工作空间引入了 mycode 文件中定义的所有函数,相当于:
1 | from mycode import * |
你其实可以只引入当前需要的函数,比如,只引入 is_prime():
1 | from mycode import is_prime |
这种情况下,你就不必使用 mycode.is_prime() 了;而是就好像这个函数就写在当前工作空间一样,直接写 is_prime():
1 | from mycode import is_prime |
True
注意,如果当前目录中并没有 mycode.py 这个文件,那么,mycode 会被当作目录名再被尝试一次 —— 如果当前目录内,有个叫做 mycode 的目录(或称文件夹)且该目录下同时要存在一个 __init__.py 文件(通常为空文件,用于标识本目录形成一个包含多个模块的 包(packages),它们处在一个独立的 命名空间(namespace)),那么,from mycode import * 的作用就是把 mycode 这个文件夹中的所有 .py 文件全部导入……
如果我们想要导入 foo 这个目录中的 bar.py 这个模块文件,那么,可以这么写:
1 | import foo.bar |
或者1
from foo import bar
引入并使用化名
有的时候,或者为了避免混淆,或者为了避免输入太多字符,我们可以为引入的函数设定 化名(alias),而后使用化名调用函数。比如:
1 | from mycode import is_prime as isp |
True
甚至干脆给整个模块取个化名:
1 | from IPython.core.interactiveshell import InteractiveShell |
True
Hello, mike!
Hello, zoe!
模块中不一定只有函数
一个模块文件中,不一定只包含函数;它也可以包含函数之外的可执行代码。只不过,在 import 语句执行的时候,模块中的非函数部分的可执行代码,只执行一次。
有一个 Python 的彩蛋,恰好是可以用在此处的最佳例子 —— 这个模块是 this,它的文件名是 this.py:
1 | import this |
The Zen of Python, by Tim Peters
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense.
Readability counts.
Special cases aren't special enough to break the rules.
Although practicality beats purity.
Errors should never pass silently.
Unless explicitly silenced.
In the face of ambiguity, refuse the temptation to guess.
There should be one-- and preferably only one --obvious way to do it.
Although that way may not be obvious at first unless you're Dutch.
Now is better than never.
Although never is often better than *right* now.
If the implementation is hard to explain, it's a bad idea.
If the implementation is easy to explain, it may be a good idea.
Namespaces are one honking great idea -- let's do more of those!
这个 this 模块中的代码如下:
1 | s = """Gur Mra bs Clguba, ol Gvz Crgref |
这个 this.py 文件中也没有什么函数,但这个文件里所定义的变量,我们都可以在 import this 之后触达:
1 | from IPython.core.interactiveshell import InteractiveShell |
{'A': 'N',
'B': 'O',
'C': 'P',
'D': 'Q',
'E': 'R',
'F': 'S',
'G': 'T',
'H': 'U',
'I': 'V',
'J': 'W',
'K': 'X',
'L': 'Y',
'M': 'Z',
'N': 'A',
'O': 'B',
'P': 'C',
'Q': 'D',
'R': 'E',
'S': 'F',
'T': 'G',
'U': 'H',
'V': 'I',
'W': 'J',
'X': 'K',
'Y': 'L',
'Z': 'M',
'a': 'n',
'b': 'o',
'c': 'p',
'd': 'q',
'e': 'r',
'f': 's',
'g': 't',
'h': 'u',
'i': 'v',
'j': 'w',
'k': 'x',
'l': 'y',
'm': 'z',
'n': 'a',
'o': 'b',
'p': 'c',
'q': 'd',
'r': 'e',
's': 'f',
't': 'g',
'u': 'h',
'v': 'i',
'w': 'j',
'x': 'k',
'y': 'l',
'z': 'm'}
"Gur Mra bs Clguba, ol Gvz Crgref\n\nOrnhgvshy vf orggre guna htyl.\nRkcyvpvg vf orggre guna vzcyvpvg.\nFvzcyr vf orggre guna pbzcyrk.\nPbzcyrk vf orggre guna pbzcyvpngrq.\nSyng vf orggre guna arfgrq.\nFcnefr vf orggre guna qrafr.\nErnqnovyvgl pbhagf.\nFcrpvny pnfrf nera'g fcrpvny rabhtu gb oernx gur ehyrf.\nNygubhtu cenpgvpnyvgl orngf chevgl.\nReebef fubhyq arire cnff fvyragyl.\nHayrff rkcyvpvgyl fvyraprq.\nVa gur snpr bs nzovthvgl, ershfr gur grzcgngvba gb thrff.\nGurer fubhyq or bar-- naq cersrenoyl bayl bar --boivbhf jnl gb qb vg.\nNygubhtu gung jnl znl abg or boivbhf ng svefg hayrff lbh'er Qhgpu.\nAbj vf orggre guna arire.\nNygubhtu arire vf bsgra orggre guna *evtug* abj.\nVs gur vzcyrzragngvba vf uneq gb rkcynva, vg'f n onq vqrn.\nVs gur vzcyrzragngvba vf rnfl gb rkcynva, vg znl or n tbbq vqrn.\nAnzrfcnprf ner bar ubaxvat terng vqrn -- yrg'f qb zber bs gubfr!"
试试吧,试试能否独立读懂这个文件里的代码 —— 对初学者来说,还是挺练脑子的呢!
它先是通过一个规则生成了一个密码表,保存在 d 这个字典中;而后,将 s 这个变量中保存的 “密文” 翻译成了英文……
或许,你可以试试,看看怎样能写个函数出来,给你一段英文,你可以把它加密成跟它一样的 “密文”?
dir() 函数
你的函数,保存在模块里之后,这个函数的用户(当然也包括你),可以用 dir() 函数查看模块中可触达的变量名称和函数名称:
1 | import mycode |
['__builtins__',
'__cached__',
'__doc__',
'__file__',
'__loader__',
'__name__',
'__package__',
'__spec__',
'is_prime',
'say_hi']
测试驱动的开发
写一个函数,或者写一个程序,换一种说法,其实就是 “实现一个算法” —— 而所谓的 “算法”,Wikipedia 上的定义是这样的:
In mathematics and computer science, an algorithm is an unambiguous specification of how to solve a class of problems. Algorithms can perform calculation, data processing, and automated reasoning tasks.
“算法”,其实没多神秘,就是 “解决问题的步骤” 而已。
在第二部分的第一章里,我们看过一个判断是否为闰年的函数:
让我们写个判断闰年年份的函数,取名为 is_leap(),它接收一个年份为参数,若是闰年,则返回 True,否则返回 False。
根据闰年的定义:
- 年份应该是 4 的倍数;
- 年份能被 100 整除但不能被 400 整除的,不是闰年。
- 所以,相当于要在能被 4 整除的年份中,排除那些能被 100 整除却不能被 400 整除的年份。
不要往回翻!现在自己动手尝试着写出这个函数?你会发现其实并不容易的……
1 | def is_leap(year): |
第一步,跟很多人想象得不一样,第一步不是上来就开始写……
第一步是先假定这个函数写完了,我们需要验证它返回的结果对不对……
这种 “通过先想办法验证结果而后从结果倒推” 的开发方式,是一种很有效的方法论,叫做 “Test Driven Development”,以测试为驱动的开发。
如果我写的 is_leap(year) 是正确的,那么:
is_leap(4)的返回值应该是Trueis_leap(200)的返回值应该是Falseis_leap(220)的返回值应该是Trueis_leap(400)的返回值应该是True
能够罗列出以上四种情况,其实只不过是根据算法 “考虑全面” 之后的结果 —— 但你自己试试就知道了,无论多简单的事,想要 “考虑全面” 好像并不容易……
所以,在写 def is_leap(year) 中的内容之前,我只是用 pass 先把位置占上,而后在后面添加了四个用来测试结果的语句 —— 它们的值,现在当然都是 False…… 等我把整个函数写完了,写正确了,那么它们的值就都应该变成 True。
1 | from IPython.core.interactiveshell import InteractiveShell |
False
False
False
False
考虑到更多的年份不是闰年,所以,排除顺序大抵上应该是这样:
- 先假定都不是闰年;
- 再看看是否能被
4整除;- 再剔除那些能被
100整除但不能被400整除的年份……
于是,先实现第一句:“先假定都不是闰年”:
1 | from IPython.core.interactiveshell import InteractiveShell |
False
True
False
False
然后再实现这部分:“年份应该是 4 的倍数”:
1 | from IPython.core.interactiveshell import InteractiveShell |
True
False
True
True
现在剩下最后一条了:“剔除那些能被 100 整除但不能被 400 整除的年份”…… 拿一个参数值,比如,200 为例:
- 因为它能被
4整除,所以,使r = True,- 然后再看它是否能被
100整除 —— 能 —— 既然如此再看它能不能被400整除,
- 如果不能,那就让
r = False;- 如果能,就保留
r的值……
如此这般,200肯定使得r = False。
1 | from IPython.core.interactiveshell import InteractiveShell |
True
True
True
True
尽管整个过程读起来很直观,但真的要自己从头到尾操作,就可能四处出错,不信你就试试 —— 这一页最下面添加一个单元格,自己动手从头写到尾试试……
当然,Python 内建库中的 datetime.py 模块里的代码更简洁,之前给你看过:
1 | # cpython/Lib/datetime.py |
False
你自己动手,从写测试开始,逐步把它实现出来试试?—— 肯定不能允许你拷贝粘贴,哈哈。
在 Python 语言中,有专门用来 “试错” 的流程控制 —— 今天的绝大多数编程语言都有这种 “试错语句”。
当一个程序开始执行的时候,有两种错误可能会导致程序执行失败:
- 语法错误(Syntax Errors)
- 意外(Exceptions)
比如,在 Python3 中,你写 print i,而没有写 print(i),那么你犯的是语法错误,于是,解析器会直接提醒你,你在第几行犯了什么样的语法错误。语法错误存在的时候,程序无法启动执行。
但是,有时会出现这种情况:语法上完全正确,但出现了意外。这种错误,都是程序已经执行之后才发生的(Runtime Errors)—— 因为只要没有语法错误,程序就可以启动。比如,你写的是 print(11/0):
1 | print(11/0) |
---------------------------------------------------------------------------
ZeroDivisionError Traceback (most recent call last)
<ipython-input-2-5544d98276be> in <module>
----> 1 print(11/0)
ZeroDivisionError: division by zero
虽然这个语句本身没有语法错误,但这个表达式是不能被处理的。于是,它触发了 ZeroDivisionError,这个 “意外” 使得程序不可能继续执行下去。
在 Python 中,定义了大量的常见 “意外”,并且按层级分类:
在第三部分阅读完毕之后,可以回来重新查看以下官方文档:
https://docs.python.org/3/library/exceptions.html
1 | BaseException |
拿 FileNotFoundError 为例 —— 当我们想要打开一个文件之前,其实应该有个办法提前验证一下那个文件是否存在。如果那个文件并不存在,就会引发 “意外”。
1 | f = open('test_file.txt', 'r') |
---------------------------------------------------------------------------
FileNotFoundError Traceback (most recent call last)
<ipython-input-3-5fac19176fe6> in <module>
----> 1 f = open('test_file.txt', 'r')
FileNotFoundError: [Errno 2] No such file or directory: 'test_file.txt'
在 Python 中,我们可以用 try 语句块去执行那些可能出现 “意外” 的语句,try 也可以配合 except、else、finally 使用。从另外一个角度看,try 语句块也是一种特殊的流程控制,专注于 “当意外发生时应该怎么办?”
1 | try: |
[Errno 2] No such file or directory: 'test_file.txt'
如此这般的结果是:
当程序中的语句
f = open('test_file.txt', 'r')因为test_file.txt不存在而引发意外之时,except语句块会接管流程;而后,又因为在except语句块中我们指定了FileNotFoundError,所以,若是FileNotFoundError真的发生了,那么,except语句块中的代码,即,print(fnf_error)会被执行……
你可以用的试错流程还有以下变种:
1 | try: |
或者:
1 | try: |
甚至可以嵌套:
1 | try: |
更多关于错误处理的内容,请在阅读完第三部分中与 Class 相关的内容之后,再去详细阅读以下官方文档:
理论上,这一章不应该套上这么大的标题:《测试驱动开发》,因为在实际开发过程中,所谓测试驱动开发要使用更为强大更为复杂的模块、框架和工具,比如,起码使用 Python 内建库中的 unittest 模块。
在写程序的过程中,为别人(和将来的自己)写注释、写 Docstring;在写程序的过程中,为了保障程序的结果全面正确而写测试;或者干脆在最初写的时候就考虑到各种意外所以使用试错语句块 —— 这些明明是天经地义的事情,却是绝大多数人不做的…… 因为感觉有点麻烦。
这里是 “聪明反被聪明误” 的最好示例长期堆积的地方。很多人真的是因为自己很聪明,所以才觉得 “没必要麻烦” —— 这就好像当年苏格拉底仗着自己记忆力无比强大甚至干脆过目不忘于是鄙视一切记笔记的人一样。
但是,随着时间的推移,随着工程量的放大,到最后,那些 “聪明人” 都被自己坑死了 —— 聪明本身搞不定工程,能搞定工程的是智慧。苏格拉底自己并没完成任何工程,是他的学生柏拉图不顾他的嘲笑用纸笔记录了一切;而后柏拉图的学生亚里士多德才有机会受到苏格拉底的启发,写了《前分析篇》,提出对人类影响至今的 “三段论”……
千万不要因为这第二部分中所举的例子太容易而把自己迷惑了。刻意选择简单的例子放在这里,是为了让读者更容易集中精力去理解关于自己动手写函数的方方面面 —— 可将来你自己真的动手去做,哪怕真的去阅读真实的工程代码,你就会发现,难度还是很高的。现在的轻敌,会造成以后的溃败。
现在还不是时候,等你把整本书都完成之后,记得回来再看这个链接:
可执行的 Python 文件
理论上来讲,你最终可以把任何一个程序,无论大小,都封装(或者囊括)到仅仅一个函数之中。按照惯例(Convention),这个函数的名称叫做 main():
1 | def routine_1(): |
Routine 1 done.
Sub-routine 1 done.
Sub-routine 2 done.
Routine 2 done.
This is the end of the program.
当一个模块(其实就是存有 Python 代码的 .py 文件,例如:mycode.py)被 import 语句导入的时候,这个模块的 __name__ 就是模块名(例如:'mycode')。
而当一个模块被命令行运行的时候,这个模块的 __name__ 就被 Python 解释器设定为 '__main__'。
把一个程序整个封装到 main() 之中,而后在模块代码里加上:
1 | if __name__ == '__main__': |
这么做的结果是:
- 当 Python 文件被当作模块,被
import语句导入时,if判断失败,main()函数不被执行;- 当 Python 文件被
python -m运行的时候,if判断成功,main()函数才被执行。
还记得那个 Python 的彩蛋吧?this.py 的代码如下:
1 | s = """Gur Mra bs Clguba, ol Gvz Crgref |
所以,只要 import this,this.py 中的代码就被执行:
1 | import this |
我在当前目录下,保存了一个文件 that.py,它的内容如下 —— 其实就是把 this.py 之中的代码封装到 main() 函数中了:
1 | # %load that.py |
于是,当你在其它地方导入它的时候,import that,main() 函数的内容不会被执行:
1 | import that |
但是,你在命令行中,用 python that.py,或者 python -m that 将 that.py 当作可执行模块运行的时候,main() 就会被执行 —— 注意,不要写错,python -m that.py 会报错的 —— 有 -m 参数,就不要写文件尾缀 .py:
1 | %%bash |
1 | %%bash |
像 that.py 那样把整个程序放进 main() 函数之后,import that 不会自动执行 main 函数里的代码。不过,你可以调用 that.main():
1 | import that |
当然,that.py 之中没有任何 Docstring,所以 help(that) 的结果是这样的:
1 | import that |
所以,之前那个从 37 万多个词汇中挑出 3700 多个字母加起来等于 100 的词汇的程序,也可以写成以下形式:
1 | #!/usr/bin/env python |
至于以上代码中的第一行,#!/usr/bin/env python 是怎么回事,建议你自己动手解决一下,去 Google:
你会很快弄明白的……
另外,再搜索一下:
你就可以把以上程序改成在命令行下能够接收指定参数的 Python 可执行文件……
顺带说,import this 的彩蛋有更好玩的玩法:
1 | from IPython.core.interactiveshell import InteractiveShell |
True
False
False
True
True
True
在 Terminal 里输入 python ⏎ 而后在 Interactive Shell 里逐句输入试试。love = this 后面的每一句,都是布尔运算,想想看为什么是那样的结果?
1 | import this |
注意以下代码中,id() 函数的输出结果:
1 | from IPython.core.interactiveshell import InteractiveShell |
True
False
False
True
True
True
4345330968
4345330968
4308348176
4308349120
True
Python 的操作符优先级,完整表格在这里:
Python 的更多彩蛋:
刻意思考
随着时间的推移,你会体会到它的威力:
刻意思考哪儿需要刻意练习
只不过是一句话而已,却因知道或不知道,竟然会逐渐形成天壤之别的差异,也是神奇。
刻意思考,就是所谓的琢磨。琢磨这事,一旦开始就简单得要死,可无从下手的时候就神秘无比。让我们再看一个 “刻意思考” —— 即,琢磨 —— 的应用领域:
这东西能用在哪儿呢?
很多人学了却没怎么练,有一个很现实的原因 —— 没什么地方用得上。
这也怪我们的应试教育,大学前上 12 年学,“学”(更多是被逼的)的绝大多数东西,只有一个能够切实体会到的用处,考试 —— 中考、高考,以及以它们为目标的无数 “模考”…… 于是,反过来,不管学什么东西,除了考试之外,几乎无法想象其他的用处。
一旦我们启动了对某项技能的自学之后,在那过程中,最具价值的刻意思考就是,时时刻刻琢磨 “这东西能用在哪儿呢?”
比如,当你看到字符串的 Methods 中有一个 str.zfill() 的时候,马上就能想到,“嗯!这可以用来批量更名文件……”

虽然现在的 Mac OS 操作系统里已经有相当不错的批量更名工具内建在 Finder 之中(选中多个文件之后,在右键菜单中能看到 rename 命令),但这是近期才加进去的功能,几年前却没有 —— 也就是说,几年前的时候,有人可以用 str.zfill() 写个简单的程序完成自己的工作,而另外一些人仅因为操作系统没有提供类似的功能就要么手工做,要么干脆忍着忘了算了……
但更多的时候,需要你花时间去琢磨,才能找到用处。
找到用处,有时候还真挺难的 —— 因为人都一样,容易被自己的眼界所限,放眼望过去,没有用处,自然也就不用了,甚至不用学了,更不用提那就肯定是感觉不用练了……
所以,仔细想想罢 —— 那些在学校里帮老师干活的小朋友们,更多情况下还真不是很多人以为的 “拍马屁”(不排除肯定有哈),只不过是在 “主动找活干”……
找活干,是应用所学的最有效方式,有活干,所以就有问题需要解决,所以就有机会反复攻关,在这个过程中,以用带练……
所以,很多人在很多事上都想反了。
人们常常取笑那些呼哧呼哧干活的人,笑着说,“能者多劳”,觉得他们有点傻。
这话真的没错。但这么说更准:劳者多能 —— 你看,都想反了吧?
到最后,一切自学能力差的人,外部的表现都差不多,都起码包括这么一条:眼里没活。他们也不喜欢干活,甚至也没想过,玩乐也是干活(每次逢年过节玩得累死那种)—— 从消耗或者成本的角度来看根本没啥区别 —— 只不过那些通常都是没有产出的活而已。
在最初想不出有什么用处的时候,还可以退而求其次,看看 “别人想出什么用处没有?” —— 比如,我去 Google best applications of python skill,在第一个页面我就发现了这么篇文章:“What exactly can you do with Python? ”,翻了一会儿觉得颇有意思……
再高阶一点的刻意思考(琢磨),无非是在 “这东西能用在哪儿呢?” 这句话里加上一个字而已:
这东西还能用在哪儿呢?
我觉得这个问题对思维训练的帮助非常深刻 —— 别看只是多了一个字而已。
当我读到在编程的过程中有很多的 “约定” 的时候,就琢磨着:
- 哦,原来约定如此重要……
- 哦,原来竟然有那么多人不重视约定……
- 哦,原来就应该直接过滤掉那些不遵守约定的人……
—— 那这个原理(东西)还能用在哪儿呢?
—— 哦,在生活中也一样,遇到不遵守约定的人或事,直接过滤,不要浪费自己的生命……
学编程真的很有意思,因为这个领域是世界上最聪明的人群之一开辟出来并不断共同努力着发展的,所以,在这个世界里有很多思考方式,琢磨方式,甚至可以干脆称为 “做事哲学” 的东西,可以普遍应用在其它领域,甚至其它任何领域。
比如,在开发方法论中,有一个叫做 MoSCoW Method 的东西,1994 年由 Clegg Dai 在《Case Method Fast-Track: A RAD Approach》一书中提出的 —— 两个 o 字母放在那里,是为了能够把这个缩写读出来,发音跟莫斯科一样。
简单说,就是,凡事都可以分为:
- Must have
- Should have
- Could have
- Won’t have
于是,在开发的时候,把所谓的需求打上这 4 个标签中的某一个,以此分类,就很容易剔除掉那些实际上做了还不如不做的功能……
琢磨一下罢,这个东西还可以用在什么地方?
显然,除了编程之外,其他应用领域挺多的,这个原则相当地有启发性……
我写书就是这样的。在准备的过程中 —— 这个过程比绝大多数人想象得长很多 —— 我会罗列所有我能想到的相关话题…… 等我觉得已经再也没有什么可补充的时候,再为这些话题写上几句话构成大纲…… 这时候就会发现很多话题其实应该是同一个话题。如此这般,一次扩张,一次收缩之后,就会进行下一步,应用 MoSCoW 原则,给这些话题打上标签 —— 在这过程中,总是发现很多之前感觉必要的话题,其实可以打上 Won't have 的标签,于是,把它们剔除,然后从 Must have 开始写起,直到 Should have,至于 Could have 看时间是否允许,看情况,比如,看有没有最后期限限制……
在写书这事上,我总是给人感觉很快,事实上也是,因为有方法论 —— 但显然,那方法论不是从某一本 “如何写书” 的书里获得的,而是从另外一个看起来完全不相关的领域里习得后琢磨到的……
所谓的 “活学活用”,所谓的 “触类旁通”,也不过如此。
战胜难点
无论学什么,都有难点。所谓的 “学习曲线陡峭”,无非就是难点靠前、难点很多、难点貌似很难而已。
然而,相信我,所有的难点,事实上都可以被拆解成更小的单元,而后在逐一突破的时候,就没那么难了。逐一突破全部完成之后,再拼起来重新审视的时候就会发现那所谓的难常常只不过是错觉、幻觉而已 —— 我把它称为困难幻觉。
把一切都当作手艺看的好处之一就是心态平和,因为你知道那不靠天分和智商,它靠的是另外几件事:不混时间,刻意思考,以及刻意练习 —— 其实吧,老祖宗早就有总结:
天下无难事,只怕有心人……
大家都是人,咋可能没 “心” 呢?
想成为有心人,其实无非就是学会拆解之后逐一突破,就这么简单。
第三部分所用的例子依然非常简单 —— 这当然是作者的刻意;但是,所涉及的话题都是被认为 “很难很难”、“很不容易理解”、“初学者就没必要学那些了” 之类的话题:
- 类,以及面向对象编程(Class,OOP)
- 迭代器、生成器、装饰器(Iterators、Generators、Decorators)
- 正则表达式(Regular Expressions)
- 巴科斯-诺尔范式(Backus Normal Form)
尤其是最后一个,巴科斯-诺尔范式,几乎所有的编程入门书籍都不会提到……
然而,这些内容,在我设计《自学是门手艺》内容的过程中,是被当作 Must have,而不是 Should have,当然更不是 Could have 或者 Won't have 的。
它们属于 Must have 的原因也很简单:
无论学什么都一样,难的部分不学会,就等于整个没学。
—— 仅因为不够全面。
有什么必要干前功尽弃的事情呢?要么干脆别学算了,何必把自己搞成一个半吊子?—— 可惜,这偏偏是绝大多数人的习惯,学什么都一样,容易的部分糊弄糊弄,困难的部分直接回避…… 其实,所有焦虑,都是这样在许多年前被埋下,在许多年后生根发芽、茂盛发达的 —— 你想想看是不是如此?
虽然别人认为难,你刚开始也会有这样的错觉,但只要你开始施展 “读不懂也要读完,读完之后再读很多遍” 的手段,并且还 “不断自己动手归纳总结整理”,你就会 “发现”,其实没什么大不了的,甚至你会有错觉:
“突然” 之间一切都明了了!
那个 “突然”,其实就是阿基米德的 Eureka,那个他从澡堂里冲出来大喊大叫的词汇。
其实吧,泡澡和冥想,还真是最容易产生 Eureka 状态的两种活动。原理在于,泡澡和打坐的时候,大脑都极其放松,乃至于原本相互之间并无联系的脑神经突触之间突然产生相互关联;而那结果就是日常生活中所描述的 “融会贯通”,于是,突然之间,Eureka!
自学者总是感觉幸福度很高,就是这个原因。日常中因为自学,所以总是遇到更多的困难。又因为这些东西不过是手艺,没什么可能终其一生也解决不了,恰恰相反,都是假以时日必然解决的 “困难”…… 于是,自学者恰恰因为遇到的 “困难” 多,所以才有更多遇到 “Eureka” 的可能性,那种幸福,还真的难以表述,即便表述清楚了,身边的人也难以理解,因为自学者就是很少很少。
对很多人来说,阅读的难点在于起初的时候它总是显得异常枯燥。
刚识字、刚上学的时候,由于理解能力有限,又由于年龄的关系于是耐心有限,所以,那时需要老师耐心陪伴、悉心引导。这就好像小朋友刚出生的时候,没有牙齿,所以只能喝奶差不多…… 然而,到了一定程度之后一定要断奶,是不是?可绝大多数人的实际情况却是,小学的时候爱上了 “奶嘴”(有人带着阅读),而后一生没有奶嘴就吃不下任何东西。
他们必须去 “上课”,需要有人给他们讲书。不仅如此,讲得 “不生动”、“不幽默” 还不行;就算那职业提供奶嘴的人(这是非常令人遗憾的真相:很多的时候,所谓的 “老师” 本质上只不过就是奶妈而已)帅气漂亮、生动幽默、尽职尽力…… 最终还是一样的结果 —— 绝大多数人依然没有完整掌握所有应该掌握的细节。
开始 “自学” 的活动,本质上来看,和断奶其实是一回事。
- 知识就是知识,它没有任何义务去具备幽默生动的属性;
- 手艺就是手艺,它没有任何义务去具备有趣欢乐的属性。
幽默与生动,是要自己去扮演的角色;有趣与欢乐,是要自己去挖掘的幸福 —— 它们从来都并不自动包含在知识和手艺之中。只有当它们被 “有心人” 掌握、被 “有心人” 应用、甚至被 “有心人” 拿去创造的时候,也只有 “有心人” 才能体会到那幽默与生动、那有趣与欢乐。
所以,有自学能力的人,不怕枯燥 —— 因为那本来就理应是枯燥的。这就好像人生本无意义,有意义的人生都是自己活出来的一样,有意义的知识都是自己用出来的 —— 对不用它的人,用不上它的人来说,只能也只剩下无法容忍的枯燥。
能够耐心读完那么多在别人看来 “极度枯燥” 的资料,是自学者的擅长。可那在别人看来 “无以伦比” 的耐心,究竟是哪儿来的呢?如何造就的呢?没断奶的人想象不出来。其实也很简单,首先,平静地接受了它枯燥的本质;其次,就是经过多次实践已然明白,无论多枯燥,总能读完;无论多难,多读几遍总能读懂…… 于是,到最后,只不过是习惯了而已。
第三部分关于编程的内容过后,还有若干关于自学的内容。
在反复阅读编程部分突破难点的过程之中、过程之后,你会对那些关于自学的内容有更深更生动的认识。很多道理过去你都知道是对的,只不过因为没有遇到过生动的例子 —— 主要是没遇到过能让自己感到生动的例子 —— 于是你就一直没有重视起来,于是,就还是那句话,那一点点的差异,造成了后来那么大的差距。
然而,既然知道了真相的你,以后就再也没办法蒙蔽自己了 —— 这就是收获,这就是进步。
类 —— 面向对象编程
面向对象编程
注意:当前这一小节所论述的内容,不是专属于哪个编程语言(比如 Python、JavaScript 或者 Golang)。
面向对象编程(Object Oriented Programming, OOP)是一种编程的范式(Paradigm),或者说,是一种方法论(Methodology)—— 可以说这是个很伟大的方法论,在我看来,现代软件工程能做那么复杂的宏伟项目,基本上都得益于这个方法论的普及。
争议
现在,OOP 的支持者与反对者在数量上肯定不是一个等级,绝大多数人支持 OOP 这种编程范式。
但是,从另外一个角度,反对 OOP 的人群中,牛人比例更高 —— 这也是个看起来颇为吊诡的事实。
比如,Erlang 的发明者,Joe Armstrong) 就很讨厌 OOP,觉得它效率低下。他用的类比也确实令人忍俊不禁,说得也挺准的:
支持 OOP 的语言的问题在于,它们总是随身携带着一堆并不明确的环境 —— 你明明只不过想要个香蕉,可你所获得的是一个大猩猩手里拿着香蕉…… 以及那大猩猩身后的整个丛林!
—— Coders at Work
创作 UTF-8 和 Golang 的程序员 Rob Pike,更看不上 OOP,在 2004 年的一个讨论帖里直接把 OOP 比作 “Roman numerals of computing” —— 讽刺它就是很土很低效的东西。八年后又挖坟把一个 Java 教授写的 OOP 文章嘲弄了一番:“也不知道是什么脑子,认为写 6 个新的 Class 比直接用 1 行表格搜索更好?”
Paul Graham —— 就是那个著名的 Y-Combinator 的创始人 —— 也一样对 OOP 不以为然,在 Why Arc isn’t Especially Object-Oriented 中,说他认为 OOP 之所以流行,就是因为平庸程序员(Mediocre programers)太多,大公司用这种编程范式去阻止那帮家伙,让他们捅不出太大的娄子……
然而,争议归争议,应用归应用 —— 就好像英语的弊端不见得比其他语言少,可就是最流行,那怎么办呢?用呗 —— 虽然该抱怨的时候也得抱怨抱怨。
从另外一个角度望过去,大牛们如此评价 OOP 也是很容易理解的 —— 因为他们太聪明,又因为他们太懒得花时间去理解或容忍笨蛋…… 我们不一样,最不一样的地方在于,我们不仅更多容忍他人,而且更能够容忍自己的愚笨,所以,视角就不同了,仅此而已。
并且,上面两位大牛写的编程语言,现在也挺流行,Joe Armstrong 的 Erlang 和 Rob Pike 的 Golang,弄不好早晚你也得去学学,去用用……
基本术语
面向对象编程(OOP),是使用对象(Objects)作为核心的编程方式。进而就可以把对象(Objects)的数据和运算过程封装(Encapsulate)在内部,而外部仅能根据事先设计好的界面(Interface)与之沟通。
比如,你可以把灯泡想象成一个对象,使用灯泡的人,只需要与开关这个界面(Interface)打交道,而不必关心灯泡内部的设计和原理 —— 说实话,这是个很伟大的设计思想。
生活中,我们会遇到无数有意无意应用了这种设计思想的产品 —— 并不仅限于编程领域。你去买个车回来,它也一样是各种封装之后的对象。当你转动方向盘(操作界面)的时候,你并不需要关心汽车设计者是如何做到把那个方向盘和车轮车轴联系在一起并如你所愿去转向的;你只需要知道的是,逆时针转动方向盘是左转,而顺时针转动方向盘是右转 —— 这就可以了!
在程序设计过程中,我们常常需要对标现实世界创造对象。这时候我们用的最直接手段就是抽象(Abstract)。抽象这个手段,在现实中漫画家们最常用。为什么你看到下面的图片觉得它们俩看起来像是人?尤其是在你明明知道那肯定不是人的情况下,却已然接受那是两个漫画小人的形象?

这种描绘方式,就是抽象,很多 “没必要” 的细节都被去掉了(或者反过来说,没有被采用),留下的两个特征,一个是头,一个是双眼 —— 连那双 “眼睛” 都抽象到只剩下一个黑点了……
这种被保留下来的 “必要的特征”,叫做对象的属性(Attributes),进而,这些抽象的对象,既然是 “人” 的映射,它们实际上也能做一些抽象过后被保留下来的 “必要的行为”,比如,说话,哭笑,这些叫做对象的方法(Methods)。
从用编程语言创造对象的角度去看,所谓的界面,就由这两样东西构成:
- 属性 —— 用自然语言描述,通常是名词(Nouns)
- 方法 —— 用自然语言描述,通常是动词(Verbs)
从另外一个方面来看,在设计复杂对象的时候,抽象到极致是一种必要。
我们为生物分类,就是一层又一层地抽象的过程。当我们使用 “生物” 这个词的时候,它并不是某一个特定的我们能够指称的东西…… 然后我们开始给它分类……

所以,当我们在程序里创建对象的时候,做法常常是
- 先创建最抽象的类(Class)
- 然后再创建子类(Subclass)……
它们之间是从属关系是:
Class ⊃ Subclass
在 OOP 中,这叫继承(Inheritance)关系。比如,狗这个对象,就可以是从哺乳动物这个对象继承过来的。如果哺乳动物有 “头” 这个属性(Attributes),那么在狗这个对象中就没必要再重新定义这个属性了,因为既然狗是从哺乳动物继承过来的,那么它就拥有哺乳动物的所有属性……
每当我们创建好一个类之后,我们就可以根据它创建它的许多个实例(Instances)。比如,创建好了 “狗” 这个类之后,我们就可以根据这个类创建很多条狗…… 这好多条狗,就是狗这个类的实例。
现在能把这些术语全部关联起来了吗?
- 对象,封装,抽象
- 界面,属性,方法
- 继承,类,子类,实例
这些就是关于 “面向对象编程” 方法论的最基本的术语 —— 无论在哪种编程语言里,你都会频繁地遇到它们。
对象、类,这两个词,给人的感觉是经常被通用 —— 习惯了还好,但对有些初学者来说,就感觉那是生命不能承受之重。—— 这次不是英文翻译中文时出现的问题,在英文世界里,这些词的互通使用和滥用也使相当一部分人(我怀疑是大部分人)最终掌握不了 OOP 这个方法论。
细微的差异在于 “视角” 的不同。
之前提到函数的时候,我用的说辞是,
- 你写了一个函数,而后你要为这个产品的使用者写说明书……
- —— 当然,产品使用者之中也包括未来的你……
类(Class)这个东西也一样,它也有创作者和使用者。
你可以这样分步理解:
- 你创造了一个类(Class),这时候你是创作者,从你眼里望过去,那就是个类(Class);
- 而后你根据这个类的定义,创建了很多实例(Instances);
- 接下来一旦你开始使用这些实例的时候,你就成了使用者,从使用者角度望过去,手里正在操作的,就是各种对象(Objects)……
最后,补充一下,不要误以为所有的 Classes 都是对事物(即,名词)的映射 —— 虽然大多数情况下确实如此。

对基本概念有了一定的了解之后,再去看 Python 语言是如何实现的,就感觉没那么难了。
类 —— Python 的实现
既然已经在不碰代码的情况下,把 OOP 中的主要概念梳理清楚了,以下的行文中,那些概念就直接用英文罢,省得理解上还得再绕个弯……
Defining Class
Class 使用 class 关键字进行定义。
与函数定义不同的地方在于,Class 接收参数不是在 class Classname(): 的括号里完成 —— 那个圆括号有另外的用处。
让我们先看看代码,而后再逐一解释:
1 | from IPython.core.interactiveshell import InteractiveShell |
'Clay'
2019
<bound method Golem.say_hi of <__main__.Golem object at 0x10430e7b8>>
Hi!
__main__.Golem
str
int
method
method
以上,我们创建了一个 Class:
1 | class Golem: |
其中定义了当我们根据这个 Class 创建一个实例的时候,那个 Object 的初始化过程,即 __init__() 函数 —— 又由于这个函数是在 Class 中定义的,我们称它为 Class 的一个 Method。
这里的 self 就是个变量,跟程序中其它变量的区别在于,它是一个系统默认可以识别的变量,用来指代将来用这个 Class 创建的 Instance。
比如,我们创建了 Golem 这个 Class 的一个 Instance,g = Golem('Clay') 之后,我们写 g.name,那么解析器就去找 g 这个实例所在的 Scope 里有没有 self.name……
注意:self 这个变量的定义,是在 def __init__(self, ...) 这一句里完成的。对于这个变量的名称取名没有强制要求,你实际上可以随便用什么名字,很多 C 程序员会习惯于将这个变量命名为 this —— 但根据惯例,你最好还是只用 self 这个变量名,省得给别人造成误会。
在 Class 的代码中,如果定义了 __init__() 函数,那么系统就会将它当作 Instance 在创建后被初始化的函数。这个函数名称是强制指定的,初始化函数必须使用这个名称;注意 init 两端各有两个下划线 _。
当我们用 g = Golem('Clay') 这一句创建了一个 Golem 的 Instance 的时候,以下一连串的事情发生了:
g从此之后就是一个根据 Golem 这个 Class 创建的 Instance,对使用者来说,它就是个 Object;- 因为 Golem 这个 Class 的代码中有
__init__(),所以,当g被创建的时候,g就需要被初始化……- 在
g所在的变量目录中,出现了一个叫做self的用来指代g本身的变量;- self.name 接收了一个参数,
'Clay',并将其保存了下来;- 生成了一个叫做
self.built_year的变量,其中保存的是g这个 Object 被创建时的年份……
对了,Golem 和 Robot 一样,都是机器人的意思;Golem 的本义来自于犹太神话,一个被赋予了生命的泥人……
Inheritance
我们刚刚创建了一个 Golem Class,如果我们想用它 Inherite 一个新的 Class,比如,Running_Golem,一个能跑的机器人,那就像以下的代码那样做 —— 注意 class Running_Golem 之后的圆括号:
1 | from IPython.core.interactiveshell import InteractiveShell |
<bound method Running_Golem.run of <__main__.Running_Golem object at 0x1068b37b8>>
Can't you see? I'm running...
'Clay'
2019
Hi!
如此这般,我们根据 Golem 这个 Class 创造了一个 Subclass —— Running_Golem,既然它是 Golem 的 Inheritance,那么 Golem 有的 Attributes 和 Methods 它都有,并且还多了一个 Method —— self.run。
Overrides
当我们创建一个 Inherited Class 的时候,可以重写(Overriding)Parent Class 中的 Methods。比如这样:
1 | from IPython.core.interactiveshell import InteractiveShell |
<bound method runningGolem.run of <__main__.runningGolem object at 0x1068c8128>>
Can't you see? I'm running...
'Clay'
2019
Hey! Nice day, Huh?
Inspecting A Class
当我们作为用户想了解一个 Class 的 Interface,即,它的 Attributes 和 Methods 的时候,常用的有三种方式:
1 | 1. help(object) |
1 | from IPython.core.interactiveshell import InteractiveShell |
Help on runningGolem in module __main__ object:
class runningGolem(Golem)
| runningGolem(name=None)
|
| Method resolution order:
| runningGolem
| Golem
| builtins.object
|
| Methods defined here:
|
| run(self)
|
| say_hi(self)
|
| ----------------------------------------------------------------------
| Methods inherited from Golem:
|
| __init__(self, name=None)
| Initialize self. See help(type(self)) for accurate signature.
|
| ----------------------------------------------------------------------
| Data descriptors inherited from Golem:
|
| __dict__
| dictionary for instance variables (if defined)
|
| __weakref__
| list of weak references to the object (if defined)
['__class__',
'__delattr__',
'__dict__',
'__dir__',
'__doc__',
'__eq__',
'__format__',
'__ge__',
'__getattribute__',
'__gt__',
'__hash__',
'__init__',
'__init_subclass__',
'__le__',
'__lt__',
'__module__',
'__ne__',
'__new__',
'__reduce__',
'__reduce_ex__',
'__repr__',
'__setattr__',
'__sizeof__',
'__str__',
'__subclasshook__',
'__weakref__',
'built_year',
'name',
'run',
'say_hi']
{'name': 'Clay', 'built_year': 2019}
True
Scope
每个变量都属于某一个 Scope(变量的作用域),在同一个 Scope 中,变量可以被引用被操作…… 这么说非常抽象,难以理解 —— 只能通过例子说明。
我们先给 Golem 这个 Class 增加一点功能 —— 我们需要随时知道究竟有多少个 Golem 处于活跃状态…… 也因此顺带给 Golem 加上一个 Method:cease() —— 哈!机器人么,想关掉它,说关掉它,就能关掉它;
另外,我们还要给机器人设置个使用年限,比如 10 年;
…… 而外部会每隔一段时间,用 Golem.is_active() 去检查所有的机器人,所以,不需要外部额外操作,到了年头,它应该能关掉自己。—— 当然,又由于以下代码是简化书写的,核心目的是为了讲解 Scope,所以并没有专门写模拟 10 年后某些机器人自动关闭的情形……
在运行以下代码之前,需要先介绍三个 Python 的内建函数:
hasattr(object, attr)查询这个object中有没有这个attr,返回布尔值getattr(object, attr)获取这个object中这个attr的值setattr(object, attr, value)将这个object中的attr值设置为value
现在的你,应该一眼望过去,就已经能掌握这三个内建函数的用法 —— 还记得之前的你吗?眼睁睁看着,那些字母放在那里对你来说没任何意义…… 这才多久啊!
1 | from IPython.core.interactiveshell import InteractiveShell |
True
True
False
False
False
1
10
11
10
10
True
如果你试过把第 13 行的 Golem.population += 1 改成 population += 1,你会被如下信息提醒:
1 | 12 self.__active = True |
—— 本地变量 population 尚未赋值,就已经提前被引用…… 为什么会这样呢?因为在你所创建 g 之后,马上执行的是 __init()__ 这个初始化函数,而 population 是在这个函数之外定义的……
如果你足够细心,你会发现这个版本中,有些变量前面有两个下划线 __,比如,__life_span 和 self.__active。这是 Python 的定义,变量名前面加上一个以上下划线(Underscore)_ 的话,那么该变量是 “私有变量”(Private Variables),不能被外部引用。而按照 Python 的惯例,我们会使用两个下划线起始,去命名私有变量,如:__life_span。你可以回去试试,把所有的 __life_span 改成 _life_span(即,变量名开头只有一个 _,那么,hasattr(Golem, '_life_span') 和 hasattr(g, '_life_span') 的返回值就都变成了 True。
看看下面的图示,理解起来更为直观一些,其中每个方框代表一个 Scope:
整个代码启动之后,总计有 4 个 Scopes 如图所示:
- ①
class Golem之外;- ②
class Golem之内;- ③
__init__(self, name=None)之内;- ④
cease(self)之内;
在 Scope ① 中,可以引用 Golem.population,在生成一个 Golem 的实例 g 之后,也可以引用 g.population;但 Golem.__life_span 和 g.__active 在 Scope ① 是不存在的;
在 Scope ② 中,存在两个变量,population 和 __life_span;而 __life_span 是 Private(私有变量,因为它的变量名中前两个字符是下划线 __;于是,在 Scope ① 中,不存在 Golem.__life_span —— hasattr(Golem, '__life_span') 的值为 False;
在 Scope ③ 中和 Scope ④ 中,由于都给它们传递了 self 这个参数,于是,在这两个 Scope 里,都可以引用 self.xxx,比如 self.population,比如 self.__life_span;
在 Scope ③ 中,population 是不存在的,如果需要引用这个值,可以用 Golem.population,也可以用 self.population。同样的道理,在 Scope ③ 中 __life_span 也不存在,如果想用这个值,可以用 Golem.__life_span 或者 self.__life_span;
Scope ④ 与 Scope ③ 平行存在。所以在这里,population 和 __life_span 也同样并不存在。
补充
在本例子中,在 __init__(self, name=None) 函数中 self.population 和 Golem.population 都可以使用,但使用效果是不一样的:
self.population总是去读取Golem类中population的初始值,即使后面通过setattr(Golem, 'population', 10)更改population的值后,self.population的值仍为0,但Golem.population值则为10,你可以自己动手尝试一下。
Encapsulation
到目前为止,Golem 这个 Class 看起来不错,但有个问题,它里面的数据,外面是可以随便改的 —— 虽然,我们已经通过给变量 life_span 前面加上两个下划线,变成 __life_span,使其成为私有变量,外部不能触达(你不能引用 Golem.__life_span),可 Golem.population 就不一样,外面随时可以引用,还可以随时修改它,只需要写上一句:
1 | Golem.population = 1000000 |
我们干脆把 population 这个变量也改成私有的罢:__population,而后需要从外界查看这个变量的话,就在 Class 里面写个函数,返回那个值好了:
1 | from IPython.core.interactiveshell import InteractiveShell |
<bound method Golem.population of <__main__.Golem object at 0x1068da160>>
1
如果,你希望外部能够像获得 Class 的属性那样,直接写 g.population,而不是必须加上一个括号 g.population() 传递参数(实际上传递了一个隐含的 self 参数),那么可以在 def population(self): 之前的一行加上一句 @property:
1 | class Golem: |
如此这般之后,你就可以用 g.population 了:
1 | from IPython.core.interactiveshell import InteractiveShell |
1
如此这般之后,不仅你可以直接引用 g.population,并且,在外部不能再直接给 g.population 赋值了,否则会报错:
1 | --------------------------------------------------------------------------- |
到此为止,Encapsulation 就做得不错了。
如果你非得希望从外部可以设置这个值,那么,你就得再写个函数,并且在函数之前加上一句:1
2
3
4
5
6
7
8
9...
def population(self):
return Golem.__population
def population(self, value):
Golem.__population = value
这样之后,.population 这个 Attribute 就可以从外部被设定其值了(虽然在当前的例子中显得没必要让外部设定 __population 这个值…… 以下仅仅是为了举例):
1 | from IPython.core.interactiveshell import InteractiveShell |
1
101
101
Help on class Golem in module __main__:
class Golem(builtins.object)
| Golem(name=None)
|
| Methods defined here:
|
| __init__(self, name=None)
| Initialize self. See help(type(self)) for accurate signature.
|
| cease(self)
|
| is_active(self)
|
| say_hi(self)
|
| ----------------------------------------------------------------------
| Data descriptors defined here:
|
| __dict__
| dictionary for instance variables (if defined)
|
| __weakref__
| list of weak references to the object (if defined)
|
| population
mappingproxy({'__module__': '__main__',
'_Golem__population': 101,
'_Golem__life_span': 10,
'__init__': <function __main__.Golem.__init__(self, name=None)>,
'say_hi': <function __main__.Golem.say_hi(self)>,
'cease': <function __main__.Golem.cease(self)>,
'is_active': <function __main__.Golem.is_active(self)>,
'population': <property at 0x1068f9d68>,
'__dict__': <attribute '__dict__' of 'Golem' objects>,
'__weakref__': <attribute '__weakref__' of 'Golem' objects>,
'__doc__': None})
{'name': 'Clay', 'built_year': 2019, '_Golem__active': True}
True
<property at 0x1068f9d68>
10000
函数工具
这一章要讲的是迭代器、生成器和装饰器,这些都是函数工具。有人把它们称为 DIG(Decorator,Iterator,Generator)—— 它们都是真正掌握 Python 的关键。
迭代器(Iterator)
我们已经见过 Python 中的所有容器,都是可迭代的 —— 准确地讲,是可以通过迭代遍历每一个元素:
1 | string = "this is a string." |
t, h, i, s, , i, s, , a, , s, t, r, i, n, g, .,
item 1, item 2, 3, 5,
1, 2, 3, 4, 5,
有个内建函数,就是用来把一个 “可迭代对象”(Iterable)转换成 “迭代器”(Iterator)的 —— iter()。
1 | from IPython.core.interactiveshell import InteractiveShell |
str_iterator
tuple_iterator
list_iterator
迭代器如何使用呢?有个 next() 函数:
1 | from IPython.core.interactiveshell import InteractiveShell |
'P'
'y'
't'
'h'
'o'
'n'
在 i 这个迭代器里一共有 6 个元素,所以,next(i) 在被调用 6 次之后,就不能再被调用了,一旦再被调用,就会触发 StopIteration 错误。
那我们怎么自己写一个迭代器呢?
迭代器是个 Object,所以,写迭代器的时候写的是 Class,比如,我们写一个数数的迭代器,Counter:
1 | class Counter(object): |
11
12
13
101
102
103
104
105
type
这里的重点在于两个函数的存在,__iter__(self) 和 __next__(self)。
1 | def __iter__(self): |
这两句是约定俗成的写法,写上它们,Counter 这个类就被会被识别为 Iterator 类型。而后再有 __next__(self) 的话,它就是个完整的迭代器了。除了可以用 for loop 之外,也可以用 while loop 去遍历迭代器中的所有元素:
1 | class Counter(object): |
101
102
103
201
202
203
生成器(Generator)
那用函数(而不是 Class)能不能写一个 Counter 呢?答案是能,用生成器(Generator)就行。
1 | def counter(start, stop): |
101
102
103
104
105
哎呀!怎么感觉这个简洁很多呢?
不过,是否简洁并不是问题,这次看起来用生成器更简单,无非是因为当前的例子更适合用生成器而已。在不同的情况下,用迭代器和用生成器各有各的优势。
这里的关键在于 yield 这个语句。它和 return 最明显的不同在于,在它之后的语句依然会被执行 —— 而 return 之后的语句就被忽略了。
但正因为这个不同,在写生成器的时候,只能用 yield,而没办法使用 return —— 你现在可以回去把上面代码中的 yield 改成 return 看看,然后体会一下它们之间的不同。
生成器函数被 next() 调用后,执行到 yield 生成一个值返回(然后继续执行 next() 外部剩余的语句);下次再被 next() 调用的时候,从上次生成返回值的 yield 语句处继续执行…… 如果感觉费解,就多读几遍 —— 而后再想想若是生成器中有多个 yield 语句会是什么情况?
还有一种东西,叫做生成器表达式。先看个例子:
1 | even = (e for e in range(10) if not e % 2) |
<generator object <genexpr> at 0x107cc0048>
0
2
4
6
8
其实,这种表达式我们早就在 List Comprehension 里见过 —— 那就是通过生成器表达式完成的。
注意
仔细看 even = (e for e in range(10) if not e % 2) 中最外面那层括号,用了圆括号,even 就是用生成器创造的迭代器(Iterator),若是用了方括号,那就是用生成器创造的列表(List)—— 当然用花括号 {} 生成的就是集合(Set)……
1 | # even = (e for e in range(10) if not e % 2) |
[1, 3, 5, 7, 9]
1
3
5
7
9
1 | # even = (e for e in range(10) if not e % 2) |
{1, 3, 5, 7, 9}
1
3
5
7
9
生成器表达式必须在括号内使用(参见官方 HOWTOS),包括函数的参数括号,比如:
1 | sum_of_even = sum(e for e in range(10) if not e % 2) |
20
函数内部当然可以包含其它的函数,以下就是一个函数中包含着其它函数的结构示例:
1 | def a_func(): |
想象一下,如果,我们让一个函数返回的是另外一个函数呢?我们一步一步来:
1 | def a_func(): |
Hi, I'm a_func!
1 | def a_func(): |
Hi, I'm a_func!
Hi, I'm b_func!
上一个代码,我们可以写成这样 —— 让 a_func() 将它内部的 b_func() 作为它的返回值:
1 | def a_func(): |
Hi, I'm a_func!
Hi, I'm b_func!
如果我们在 return 语句里只写函数名呢?好像这样:
1 | def a_func(): |
Hi, I'm a_func!
<function __main__.a_func.<locals>.b_func()>
这次返回的不是调用 b_func() 这个函数的执行结果,返回的是 b_func 这个函数本身。
装饰器(Decorator)
函数也是对象
这是关键:
函数本身也是对象(即,Python 定义的某个 Class 的一个 Instance)。
于是,函数本身其实可以与其它的数据类型一样,作为其它函数的参数或者返回值。
让我们分步走 —— 注意,在以下代码中,a_decorator 返回的一个函数的调用 wrapper() 而不是 wrapper 这个函数本身:
1 | def a_decorator(func): |
Hi, I'm a_func!
We can do sth. before a func is called...
Hi, I'm a_func!
... and we can do sth. after it is called...
如果返回的是函数本身,wrapper,输出结果跟你想的并不一样:
1 | def a_decorator(func): |
Hi, I'm a_func!
<function __main__.a_decorator.<locals>.wrapper()>
装饰器操作符
不过,Python 提供了一个针对函数的操作符 @,它的作用是…… 很难一下子说清楚,先看看以下代码:
1 | def a_decorator(func): |
We can do sth. before calling a_func...
Hi, I'm a_func!
... and we can do sth. after it was called...
注意:以上的代码中,a_decorator(func) 返回的是 wrapper 这个函数本身。
在我们定义 a_func() 的时候,在它之前,加上了一句 @a_decorator;这么做的结果是:
每次
a_func()在被调用的时候,因为它之前有一句@a_decorator,所以它会先被当作参数传递到a_decorator(func)这个函数中…… 而后,真正的执行,是在a_decorator()里被完成的。
—— 被 @ 调用的函数,叫做 “装饰器”(Decorator),比如,以上代码中的 a_decorator(func)。
现在可以很简单直接地说清楚装饰器的作用了:
1 |
|
等价于
1 | def a_func(): |
就是用 a_decorator 的调用结果替换掉原来的函数。a_decorator 返回值是什么,以后调用 a_func 时就是在调用这个返回值,而 a_decorator 本身此时已经执行完毕了。
装饰器的用途
Decorator 最常用的场景是什么呢?最常用的场景就是用来改变其它函数的行为。
1 | def an_output(): |
The quick brown fox jumps over the lazy dog.
1 | def uppercase(func): |
THE QUICK BROWN FOX JUMPS OVER THE LAZY DOG.
你还可以给一个函数加上一个以上的装饰器:
1 | def uppercase(func): |
<strong>THE QUICK BROWN FOX JUMPS OVER THE LAZY DOG.</strong>
你把两个装饰器的顺序调换一下写成下面这样试试:
1 |
|
装饰器的执行顺序是 “自下而上” —— 其实是 “由里到外” 更为准确。体会一下。
装饰带有参数的函数
到现在我们见到的使用装饰器的函数都是没有参数的:an_output 以及之前的 a_func。
如果被装饰的函数有参数怎么办?装饰器自身内部又应该怎么写?
这时候,Python 的 *args and **kwargs 的威力就显现出来了 —— 之前怕麻烦没有通过仔细反复阅读搞定这 “一个星号、两个星号、直接晕倒” 的知识点的人,现在恐怕要吃亏了……
装饰器函数本身这么写:
1 | def a_decorator(func): |
在这里,(*args, **kwargs) 非常强大,它可以匹配所有函数传进来的所有参数…… 准确地讲,*args 接收并处理所有传递进来的位置参数,**kwargs 接收并处理所有传递进来的关键字参数。
假设我们有这么个函数:
1 | def say_hi(greeting, name=None): |
Hello! Jack.
如果我们想在装饰器里对函数名、参数,都做些事情 —— 比如,我们写个 @trace 用来告诉用户调用一个函数的时候都发生了什么……
1 | def trace(func): |
Trace: You've called a function: say_hi(), with args: ('Hello',); kwargs: {'name': 'Jack'}
Trace: say_hi('Hello',) returned: Hello! Jack.
Hello! Jack.
有了以上的基础知识之后,再去阅读 Python Decorator Library 的 Wiki 页面就会轻松许多:
学会装饰器究竟有多重要?
装饰器一定要学会 —— 因为很多人就是不会。
Oreilly.com 上有篇文章,《5 reasons you need to learn to write Python decorators》中,其中的第五条竟然是:Boosting your career!
Writing decorators isn’t easy at first. It’s not rocket science, but takes enough effort to learn, and to grok the nuances involved, that many developers will never go to the trouble to master it. And that works to your advantage. When you become the person on your team who learns to write decorators well, and write decorators that solve real problems, other developers will use them. Because once the hard work of writing them is done, decorators are so easy to use. This can massively magnify the positive impact of the code you write. And it just might make you a hero, too.
As I’ve traveled far and wide, training hundreds of working software engineers to use Python more effectively, teams have consistently reported writing decorators to be one of the most valuable and important tools they’ve learned in my advanced Python programming workshops.
为什么有那么多人就是学不会呢?—— 只不过是因为在此之前,遇到 *args **kwargs 的时候,“一个星号、两个星号、直接晕倒”…… 而后并未再多挣扎一下。
正则表达式
正则表达式本质上是个独立的语言,短小却格外强悍 —— 乃至于,如果你竟然没学会它的话,你的之前学的编程技能干脆与残疾无异。
Wikipedia 上对正则表达式的说明如下:
正则表达式(英语:Regular Expression,在代码中常简写为 regex、regexp 或 RE),又称正规表示式、正规表示法、正规运算式、规则运算式、常规表示法,是计算机科学的一个概念。正则表达式使用单个字符串来描述、匹配一系列符合某个句法规则的字符串。在很多文本编辑器里,正则表达式通常被用来检索、替换那些符合某个模式的文本。许多程序设计语言都支持利用正则表达式进行字符串操作。例如,在 Perl 中就内建了一个功能强大的正则表达式引擎。正则表达式这个概念最初是由 Unix 中的工具软件(例如 sed 和 grep)普及开的。
以下是绝大多数翻译成中文的教程中对正则表达式进行讲解时所使用的描述:
一个正则表达式(Regular Expression)通常被称为一个模式(Pattern)。
我常常觉得当初要是它被翻译成 “规则表达式”,那么很可能初学者不会感到那么大的压力 —— 谁都一样,看着由 “每个都认识的字构成的词组” 却不能直观地想到它究竟是什么东西,都会感到莫名的压力。
Regular,其实在它的众多语义中,取以下释义最符合 Regular Expression 的原意[1]:
⑭ Linguistics 规则的 ▸ regular verbs 规则动词
而 Pattern 这个词,在词典里有好几个对应的中文词汇:
① 图案;② 式样;③ 图样;④ 榜样;⑤ 模式;⑥ 样品;⑦ 模子
在当前语境之下,把 Pattern 翻译成 “模式”,显然不如 “模子” 更好(甚至连 “样品” 感觉都比 “模式” 更恰当)—— “模子” 这个词很直观啊,拿着一个模子去找与它一致的字符串…… “与规则一致”,英文用的是 Match,一般被翻译作 “匹配”。
在自学编程的过程中,处处都是这种语言翻译带来的迷惑、障碍,或者耽误。既然应该把 Regular Expression 理解为 “规则表达式” 更好,那其实吧,把 Pattern 直接理解为中文的 “规则”,可能更直观更准确,理解上更是毫无障碍:
一个规则表达式(Regular Expression)通常被称为一个规则(Pattern)。
那么,规则表达式里写的是什么呢?只能是规则了…… 到最后好像也就 “捕获”(Capture)这个词没什么歧义。
现在,我们已经把术语全部 “解密” 了,然后再看看下面的表述:
我们可以用书写特定的规则,用来在文本中捕获与规则一致的字符串,而后对其进行操作……
理解起来相当顺畅。
以下的 Python 代码中,\wo\w 就是一个规则表达式(或称为规则);
而 re.findall(pttn, str) 的作用就是,在 str 里找到所有与这个规则(Pattern,模式)一致(Match,匹配)的字符串:
1 | import re |
['row', 'fox', 'dog']
总结一下:
规则表达式(Regular Expressions,通常缩写为 Regex)是最强大且不可或缺的文本处理工具 —— 它的用处就是在文本中扫描/搜索(Scan/Search)与某一规则(Pattern)匹配(Match,即,与规则一致)的所有实例,并且还可以按照规则捕获(Capture)其中的部分或者全部,对它们进行替换(Replace)。
接下来为了避免歧义,我们干脆用 Regex 这个缩写,以及与它相关的英文单词:pattern, match, capture, replace(ment)……
有时,使用 Regex 并不是为了 Replace,而是为了检查格式,比如,可以用 Regex 检查用户输入的密码是否过于简单(比如,全部都由数字构成),比如可以用来验证用户输入的电话号码、证件号码是否符合特定格式等等。
另外,在自学的过程中,想尽一切办法把一切术语用简单直白的 “人话” 重新表述,是特别有效的促进进步的行为模式。
视觉体验
所谓百闻不如一见。
眼见为实 —— 想办法让一个陌生的概念视觉上直观,是突破大多学习障碍的最简单粗暴直接有效的方式。
我们最好先直接看看 Regex 的工作过程。以下,是用微软发行的代码编辑工具 Visual Studio Code 针对一小段文本使用若干条 Regex 进行匹配的过程:
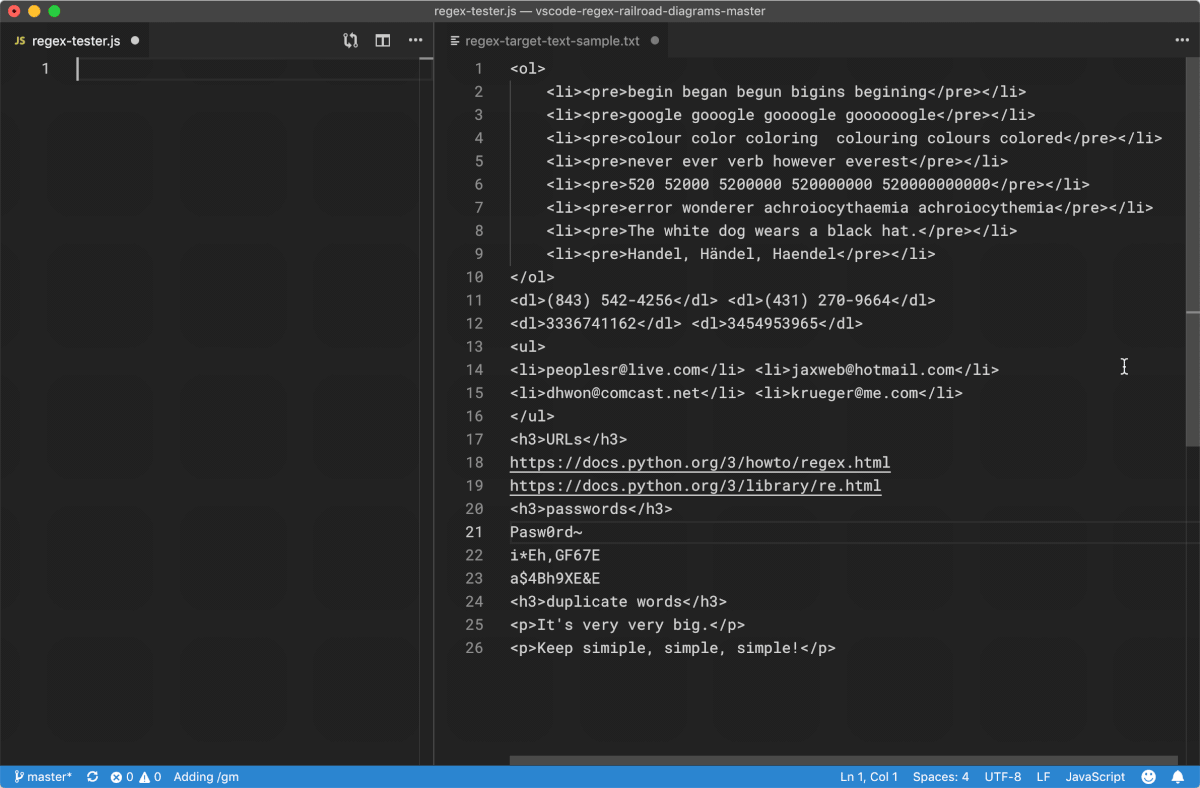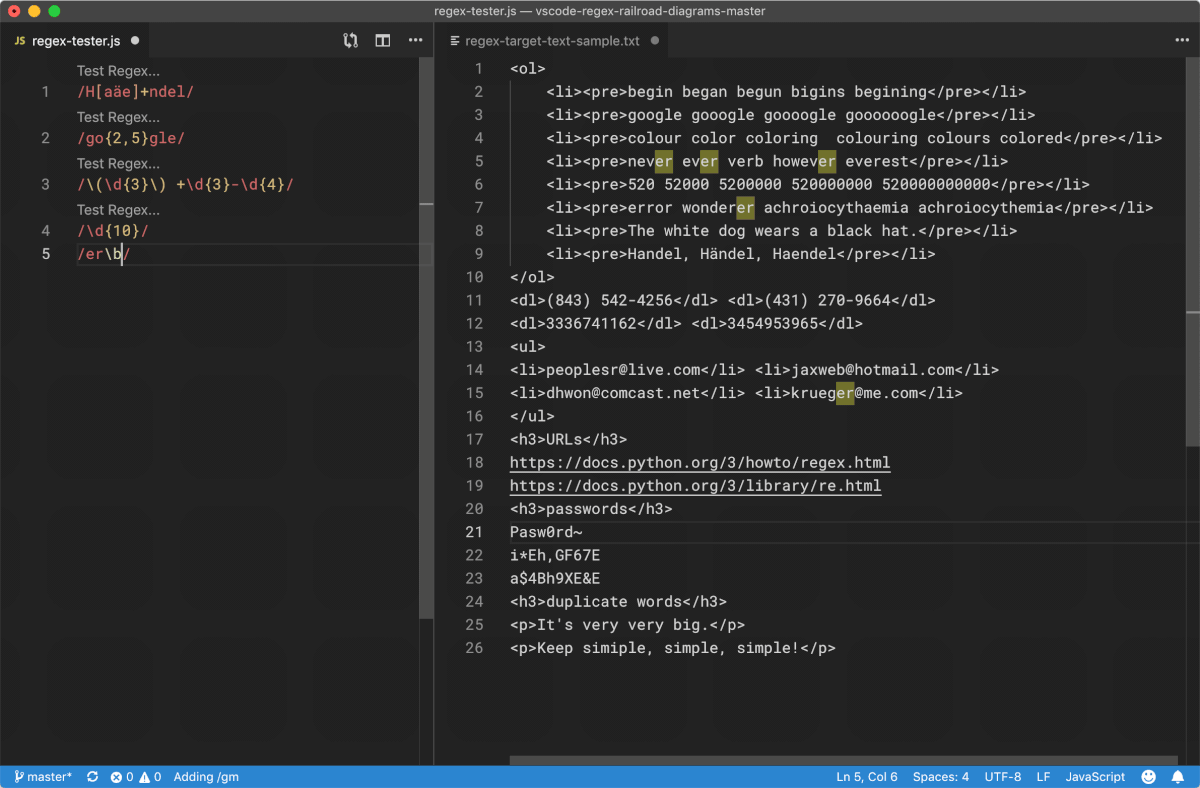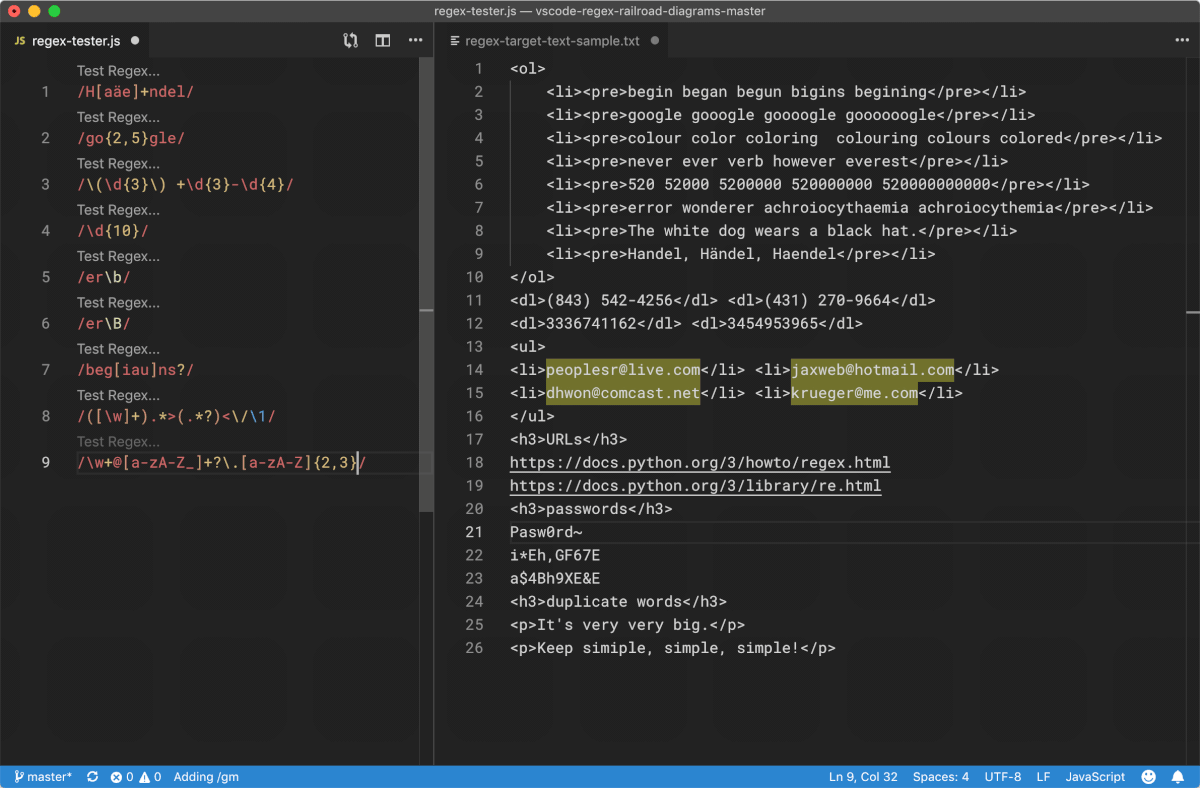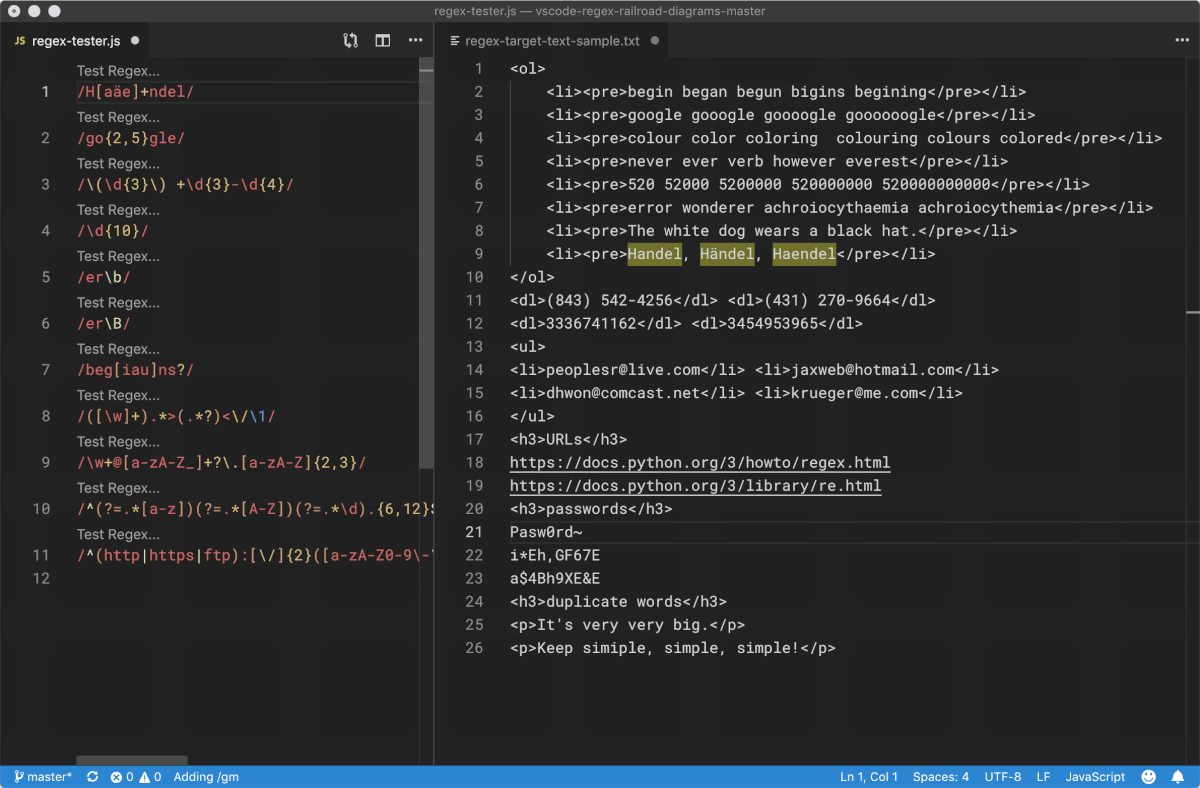
Python 的项目代码仓库里有一个很简短的 Demo 程序,叫 redemo.py,它使用 Tcl/Tk 作为图形界面,也可以用来测试正则表达式。
它的代码地址是:
https://raw.githubusercontent.com/python/cpython/master/Tools/demo/redemo.py
它运行起来长成这样:
目前(2019)网上最方便的 Regex 测试器,是 regex101.com:
以下,就是在一段文本中,找出所有首写字母大写的词汇的过程,并将其先全部替换成小写,再将其全部替换为大写的过程;使用的正则表达式是 ([A-Z]\w+),替换表达式分别是 \L$1 和 \U$1:
这个网站太好了,所以,平日里我是用 Nativefier 工具将这个网站打包为一个 Mac Desktop App 使用。不过,它也有局限,就是被搜索文件略微大点就报错,说 timeout……
准备工作
我们需要个文本文件,用来当作练习使用正则表达式去搜索替换的目标。这个文件保存在当前的根目录,文件名称是:regex-target-text-sample.txt。
以下代码中,pttn = r'beg[iau]ns?' 这一句中的 beg[iau]ns? 就是 Regex 的 Pattern。
注意:在 Python 代码中,写 Pattern 的时候,之所以要在字符串 '...' 之前加上 r,写成 r'...',是因为如果不用 raw string 的话,那么,每个转义符号都要写成 \\;如果用 raw string,转义符号就可以直接使用 \ 本身了…… 当然,如果你想搜索 \ 这个符号本身的话,那么还是得写 \\。
而 re.findall(pttn, str) 的意思是说,把 str 中所有与 pttn 这个规则一致的字符串都找出来:
1 | import re |
['begin', 'began', 'begun', 'begin']
文件 regex-target-text-sample.txt 中的内容如下:
1 | <ol> |
在以下的示例中,有时直接设定了 str 的值,而不是使用以上整个文本文件 —— 因为读者在阅读的时候,最好能直接看到被搜索的字符串。另外,如果使用整个文件,所得到的 Match 太多,也确实影响阅读。
优先级
毕竟,你已经不是 “啥都不懂” 的人了。你已经知道一个事实:编程语言无非是用来运算的。
所谓的运算,就有操作符(Operators)和操作元(Operands)—— 而操作符肯定是有优先级的,不然的话,那么多操作元和操作符放在一起,究竟先操作哪个呢?
Regex 也一样,它本身就是个迷你语言(Mini Language)。在 Regex 中,操作符肯定也有优先级。它的操作元有个专门的名称,原子(Atom)。
先大致看看它的操作符优先级,你就会对它有相当不错的了解:
| 排列 | 原子与操作符优先级 | (从高到低) | ||
|---|---|---|---|---|
| 1 | 转义符号 (Escaping Symbol) | \ |
||
| 2 | 分组、捕获 (Grouping or Capturing) | (...) (?:...) (?=...) (?!...) (?<=...) (?<!...) |
||
| 3 | 数量 (Quantifiers) | a* a+ a? a{n, m} |
||
| 4 | 序列与定位(Sequence and Anchor) | abc ^ $ \b \B |
||
| 5 | 或(Alternation) | `a\ | b\ | c` |
| 6 | 原子 (Atoms) | a [^abc] \t \r \n \d \D \s \S \w \W . |
当然,你若是在之前,没有自学过、理解过 Python(或者任何其它编程语言)表达式中的操作符优先级,那么一上来就看上面的表格不仅对你没有帮助,只能让你更迷惑。
—— 这就是理解能力逐步积累逐步加强的过程。
原子
在 Regex 的 Pattern 中,操作元,即,被运算的 “值”,被称为原子(Atom)。
本义字符
最基本的原子,就是本义字符,它们都是单个字符。
本义字符包括从 a 到 z,A 到 Z,0 到 9,还有 _ —— 它们所代表的就是它们的字面值。
即,相当于,string.ascii_letters 和 string.digits 以及 _。
1 | from IPython.core.interactiveshell import InteractiveShell |
'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ'
'0123456789'
以下字符在 Regex 中都有特殊含义:
\+*.?-^$|()[]{}<>
当你在写 Regex 的时候,如果你需要搜索的字符不是本义字符,而是以上这些特殊字符时,建议都直接加上转义符号 \ 来表示,比如,你想搜索 ',那你就写 \',或者你想搜索 # 那你就写 \#(事实上,# 并不是 Regex 的特殊符号,所以,它之前的转义符号可有可无)—— 这对初学者来说可能是最安全的策略。
跟过往一样,所有的细节都很重要,它们就是需要花时间逐步熟悉到牢记。
集合原子
集合原子还是原子。
标示集合原子,使用方括号 []。[abc] 的意思是说,“a or b or c”,即,abc 中的任意一个字符。
比如,beg[iau]n 能够代表 begin、began,以及 begun。
1 | import re |
['begin', 'began', 'begun', 'begin']
在方括号中,我们可以使用两个操作符:-(区间)和 ^(非)。
[a-z]表示从小写字母a到小写字母z中的任意一个字符。[^abc]表示abc以外的其它任意字符,即,非[abc]。
注意,一个集合原子中,^ 符号只能用一次,只能紧跟在 [ 之后。否则不起作用。
类别原子
类别原子,是指那些能够代表 “一类字符” 的原子,它们都得使用转义符号再加上另外一个符号表达,包括:
\d 任意数字;等价于 [0-9]
\D 任意非数字;等价于 [^0-9]
\w 任意本义字符;等价于 [a-zA-Z0-9_]
\W 任意非本义字符;等价于 [^a-zA-Z0-9_]
\s 任意空白;相当于 [ \f\n\r\t\v](注意,方括号内第一个字符是空格符号)
\S 任意非空白;相当于 [^ \f\n\r\t\v](注意,紧随 ^ 之后的是一个空格符号)
. 除 \r \n 之外的任意字符;相当于 [^\r\n]
类别原子挺好记忆的,如果你知道各个字母是哪个词的首字母的话:
d是 digitsw是 word characterss是 spaces
另外,在空白的集合 [ \f\n\r\t\v] 中:\f 是分页符;\n \r 是换行符;\t 是制表符;\v 是纵向制表符(很少用到)。各种关于空白的转义符也同样挺好记忆的,如果你知道各个字母是那个词的首字母的话:
f是 flipn是 new liner是 returnt是 tabv是 vertical tab
1 | import re |
['542-', '270-']
边界原子
我们可以用边界原子指定边界。也可以称作 “定位操作符”。
^ 匹配被搜索字符串的开始位置;
$ 匹配被搜索字符串的结束位置;
\b 匹配单词的边界;er\b,能匹配 coder 中的 er,却不能匹配 error 中的 er;
\B 匹配非单词边界;er\B,能匹配 error 中的 er,却不能匹配 coder 中的 er。
1 | import re |
['er', 'er', 'er']
['er', 'er']
注意:^ 和 $ 在 Python 语言中被 \A 和 \Z 替代。
事实上,每种语言或多或少都对 Regex 有自己的定制。不过,本章讨论的绝大多数细节,都是通用的。
组合原子
我们可以用圆括号 () 将多个单字符原子组合成一个原子 —— 这么做的结果是,() 内的字符串将被当作一整个原子,可以被随后我们要讲解的数量操作符操作。
另外,() 这个操作符,有两个作用:组合(Grouping),就是我们刚刚讲到的作用;而另外一个作用是捕获(Capturing),后面会讲到。
er是两个原子,'e'和紧随其后的'r'[er]是一个原子,或者'e'或者'r';(er)是一个原子,'er'
下一节中讲到数量操作符的时候,会再次强调这点。
数量操作符
数量操作符有:+ ? * {n, m}。
它们是用来限定位于它们之前的原子允许出现的个数;不加数量限定则代表出现一次且仅出现一次:
+ 代表前面的原子必须至少出现一次,即:出现次数 ≧ 1
例如,
go+gle可以匹配goooglegoooogle等;
? 代表前面的原子最多只可以出现一次,即:0 ≦ 出现次数 ≦ 1
例如,
colou?red可以匹配colored或者coloured;
* 代表前面的原子可以不出现,也可以出现一次或者多次,即:出现次数 ≧ 0
例如,
520*可以匹配52520520005200000520000000000等。
{n} 之前的原子出现确定的 n 次;
{n,} 之前的原子出现至少 n 次;
{n, m} 之前的原子出现至少 n 次,至多 m 次
例如,
go{2,5}gle,能匹配goooglegoooogle或gooooogle,但不能匹配gogle和gooooooogle
1 | from IPython.core.interactiveshell import InteractiveShell |
['google', 'gooogle', 'goooogle', 'goooooogle']
['google', 'gooogle', 'goooogle']
['coloured', 'colored']
['520', '52000', '5200000', '520000000', '520000000000']
数量操作符是对它之前的原子进行操作的,换言之,数量操作符的操作元是操作符之前的原子。
上一节提到,要注意区别:er、[er] 和 (er) 各不相同。
er是两个原子,'e'之后'r'[er]是一个原子,或者'e'或者'r';(er)是一个原子,'er'
1 | from IPython.core.interactiveshell import InteractiveShell |
['er', 'er', 'er', 'er']
['e', 'r', 'r', 'r', 'e', 'r', 'e', 'r', 'e', 'e', 'r', 'e', 'e']
['er', 'er', 'er', 'er']
在以上的例子中,看不出 er 和 (er) 的区别,但是,加上数量操作符就不一样了 —— 因为数量操作符只对它之前的那一个原子进行操作:
1 | from IPython.core.interactiveshell import InteractiveShell |
['err', 'er', 'er', 'er']
['err', 'r', 'erer', 'e', 'ere', 'e']
['er', 'er', 'er']
或操作符 |
或操作符 | 是所有操作符中优先级最低的,数量操作符的优先级比它高,所以,在 | 前后的原子被数量操作符(如果有的话)操作之后才交给 | 操作。
于是,begin|began|begun 能够匹配 begin 或 began 或 begun。
1 | import re |
['begin', 'began', 'begun', 'begin', 'begin']
在集合原子中(即,[] 内的原子)各个原子之间的关系,只有 “或” —— 相当于方括号中的每个原子之间都有一个被省略的 |。
注意:方括号的 | 不被当作特殊符号,而是被当作 | 这个符号本身。在方括号中的圆括号,也被当作圆括号 () 本身,而无分组含义。
1 | from IPython.core.interactiveshell import InteractiveShell |
['a', 'a', 'e', 'a', 'a', 'e', 'a', 'a', '|', 'e']
匹配并捕获
捕获(Capture),使用的是圆括号 ()。使用圆括号得到的匹配的值被暂存成一个带有索引的列表,第一个是 $1,第二个是 $2…… 以此类推。随后,我们可以在替换的过程中使用 $1 $2 中所保存的值。
注意:在 Python 语言中调用 re 模块之后,在 re.sub() 中调用被匹配的值,用的索引方法是 \1、\2…… 以此类推。
1 | import re |
[('white', 'black')]
'The black dog wears a white hat.'
'The white dog wears a white hat.'
非捕获匹配
有时,你并不想捕获圆括号中的内容,在那个地方你使用括号的目的只是分组,而非捕获,那么,你就在圆括号内最开头加上 ?: —— (?:...):
1 | import re |
['black']
'The black dog wears a black hat.'
在 Python 代码中使用正则表达式,匹配和捕获以及随后的替换,有更灵活的方式,因为可以对那些值直接编程。re.sub() 中,repl 参数甚至可以接收另外一个函数作为参数 —— 以后你肯定会自行认真阅读以下页面中的所有内容:
非捕获匹配,还有若干个操作符:
(?=pattern)
正向肯定预查(look ahead positive assert),在任何匹配规则的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。例如,
Windows(?=95|98|NT|2000)%60)
能匹配Windows2000中的Windows,但不能匹配Windows3.1中的Windows。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。
(?!pattern)
正向否定预查(negative assert),在任何不匹配规则的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。例如
Windows(?!95|98|NT|2000))
能匹配Windows3.1中的Windows,但不能匹配Windows2000中的Windows。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。
(?<=pattern)
反向(look behind)肯定预查,与正向肯定预查类似,只是方向相反。例如,
(?<=95|98|NT|2000)WindowsWindows)
能匹配2000Windows中的Windows,但不能匹配3.1Windows中的Windows。
(?<!pattern)
反向否定预查,与正向否定预查类似,只是方向相反。例如
(?<!95|98|NT|2000)Windows
能匹配3.1Windows中的Windows,但不能匹配2000Windows中的Windows。
控制标记
有几个全局控制标记(Flag)需要了解,其中最常默认指定的有 G 和 M:
A/ASCII,默认为 False
\d,\D,\w,\W,\s,\S,\b, 和\B等只限于 ASCII 字符- 行内写法:
(?a)- Python re 模块中的常量:
re.Are.ASCII
I/IGNORECASE,默认为 False
- 忽略字母大小写
- 行内写法:
(?i)- Python re 模块中的常量:
re.Ire.IGNORECASE
G/GLOBAL,默认为 True
- 找到第一个 match 之后不返回
- 行内写法:
(?g)- Python re 模块中这个标记不能更改,默认为 TRUE
L/LOCALE,默认为 False
- 由本地语言设置决定
\d,\D,\w,\W,\s,\S,\b, 和\B等等的内容- 行内写法:
(?L)- Python re 模块中的常量:
re.Lre.LOCALE
M/MULTILINE,默认为 True
- 使用本标志后,
^和$匹配行首和行尾时,会增加换行符之前和之后的位置。- 行内写法:
(?m)- Python re 模块中的常量:
re.Mre.MULTILINE
S/DOTALL,默认为 False
- 使
.完全匹配任何字符,包括换行;没有这个标志,.匹配除了nr之外的任何字符。- 行内写法:
(?s)- Python re 模块中的常量:
re.Sre.DOTALL
X/VERBOSE,默认为 False
- 当该标志被指定时,Pattern 中的的空白符会被忽略,除非该空白符在圆括号或方括号中,或在反斜杠
\之后。这样做的结果是允许将注释写入 Pattern,这些注释会被 Regex 解析引擎忽略。注释用#号来标识,不过该符号不能在字符串或反斜杠之后。- 行内写法:
(?x)- Python re 模块中的常量:
re.Xre.VERBOSE
几个最常用的 Regex
以下是几个常用的 Regex[2],值得保存:
matching username
matching password[3]
matching a HEX value
matching a slug
matching email address
/^([a-z0-9_\.-]+)@([\da-z\.-]+)\.([a-z\.]{2,6})$/@([%5Cda-z%5C.-]+)%5C.([a-z%5C.]%7B2,6%7D)$/)matching a URL
/^(https?:\/\/)?([\da-z\.-]+)\.([a-z\.]{2,6})([\/\w \.-]*)*\/?$/?([%5Cda-z%5C.-]+)%5C.([a-z%5C.]%7B2,6%7D)([%5C/%5Cw%20%5C.-])%5C/?$/)matching an IP address
/^(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)$/matching a HTML tag
对了,告诉你一个小秘密:
以上的正则表达式,点击都能连接到 regexper.com,在那里你能查看这些正则表达式的图形化示意图。另外,本文中,处于 markdown cell 的绝大多数正则表达式都有这样的连接…… 你可以重读的时候试试。
写 Regex 最烧脑的地方在于 “使其全面” —— 要考虑到各种意外情况。
当然,除非必要,也不要在 “全面” 这事上面花太多时间 —— 给你看一个据说是 “最大程度上能够匹配所有 email 地址的 Regex” [4],我都懒得测试的一个正则表达式:
1 | (?:(?:\r\n)?[ \t])*(?:(?:(?:[^()<>@,;:\\".\[\] \000-\031]+(?:(?:(?:\r\n)?[ \t] |
趣事一则
ELIZA 是人类史上第一个 “聊天机器人” 程序,上个世纪六十年代,1966 年实现的。核心就是使用正则表达式匹配对方语句中的关键词汇,再经过替换,形成看似有意义的 “回应” —— 事实上,ELIZA 完全不知道自己在说什么……
几年后,就是七十年代初,1972 年,另外一个聊天机器人 Parry [5]被写了出来…… 随后第二年,这两个聊天机器人在 ARPANET “碰面” 好好地聊了一下[6]:
ELIZA: Good Evening. Tell me your problems. Please terminate input with a period or a question mark.
PARRY: People get on my nerves sometimes.
ELIZA: I am not sure I understand you fully.
PARRY: You should pay more attention.
ELIZA: Suppose you should pay more attention.
PARRY: You’re entitled to your own opinion.
ELIZA: What makes you think I am entitled to my own opinion?
PARRY: It bothers me just to be around people in general.
ELIZA: Please go on.
PARRY: I went to the track at Bay Meadows a while back.
ELIZA: What does that suggest to you?
PARRY: I went to the races.
……
以下是后人用 Python 重新实现的 ELIZA 的程序代码,你可以直接执行它,尝试一下与 ELIZA 聊聊天:
1 | # %load https://raw.githubusercontent.com/jezhiggins/eliza.py/master/eliza.py |
Therapist
---------
Talk to the program by typing in plain English, using normal upper-
and lower-case letters and punctuation. Enter "quit" when done.
========================================================================
Hello. How are you feeling today?
脚注
[1]:释义摘自苹果电脑上系统内建的《牛津英汉双解辞典》
[2]:8 Regular Expressions You Should Know by Vasili
[3]:关于校验密码强度的正则表达式,往往需要设置更为复杂的规则,Stackoverflow 上的一则答复中有很好的示例:https://stackoverflow.com/a/21456918
[4]:http://www.ex-parrot.com/pdw/Mail-RFC822-Address.html
[5]:Parry 的源代码(用 Lisp 写的)在这里:http://www.cs.cmu.edu/afs/cs/project/ai-repository/ai/areas/classics/parry/
[6]:ELIZA 和 Parry 的完整聊天记录在这里:https://tools.ietf.org/html/rfc439
BNF 以及 EBNF
通常情况下,你很少会在入门书籍里读到关于 Backus-Naur Form(BNF,巴科斯-诺尔范式)和 Extended Backus-Naur Form(EBNF)的话题 —— 它们都被普遍认为是 “非专业人士无需了解的话题”,隐含的另外一层含义是 “反正就算给他们讲他们也无论如何看不懂”……
然而,在我眼里,这事非讲不可 —— 这是这本 “书” 的设计目标决定的。
严格意义上来讲,在《自学是门手艺》中,以自学编程为例,我完全没必要自己动手耗时费力写那么多东西 —— 如果仅仅是为了让读者 “入门” 的话。编程入门书籍,或者 Python 编程入门书籍,都已经太多太多了,其中质量过硬的书籍也多得去了 —— 并且,如果你没有英文阅读障碍,那你就会发现网上有太多非常优质的免费教程…… 真的轮不到李笑来同学再写一次。
我写这本书的目标是:
让读者从认知自学能力开始,通过自学编程作为第一个实践,逐步完整掌握自学能力,进而在随后漫长的人生中,需要什么就去学什么,
…… 不用非得找人教、找人带 —— 只有这样,前途这两个字才会变得实在。
于是,我最希望能做到的是,从这里了解了自学方法论,也了解了编程以及 Python 编程的基础概念之后,《自学是门手艺》的读者能够自顾自地踏上征程,一路走下去 —— 至于走到哪里,能走到哪里,不是我一个作者一厢情愿能够决定的,是吧?
当然,会自学的人运气一定不会差。
于是,这本 “书” 的核心目标之一,换个说法就是:
我希望读者在读完《自学是门手艺》之后,有能力独立地去全面研读官方文档 —— 甚至是各种编程语言、各种软件的相关的文档(包括它们的官方文档)。
自学编程,很像独自一人冲入了一个丛林,里面什么动物都有…… 而且那个丛林很大很大,虽然丛林里有的地方很美,可若是没有地图和指南针,你就会迷失方向。
其实吧,地图也不是没有 —— 别说 Python 了,无论什么编程语言(包括无论什么软件)都有很翔实的官方文档…… 可是吧,绝大多数人无论买多少书、上多少课,就是不去用官方 “地图”,就不!
—— 其实倒不是说 “第三方地图” 更好,实际的原因很不好意思说出来:
- 这首先吧,觉得官方文档阅读量太大了……(嗯?那地图不是越详细越好吗?)
- 那还有吧…… 也不是没去看过,看不懂……(嗯…… 这对初学者倒是个问题!)
所以,我要认为这本 “书” 的最重要工作是:
为读者解读清楚地图上的 “图例”,从此之后读者在任何需要的时候能够彻底读懂地图。
在阅读官方文档的时候,很多人在 The Python Tutorial 上就已经觉得吃力了…… 如果到了 Standard Libraries 和 Language References 的部分,就基本上完全放弃了,比如,以下这段摘自 string —— Common string operations:
Format Specification Mini-Language
…
The general form of a standard format specifier is:
2
3
4
5
6
7
8
9
fill ::= <any character>
align ::= "<" | ">" | "=" | "^"
sign ::= "+" | "-" | " "
width ::= digit+
grouping_option ::= "_" | ","
precision ::= digit+
type ::= "b" | "c" | "d" | "e" | "E" | "f" | "F" | "g" | "G" |
"n" | "o" | "s" | "x" | "X" | "%"
…
读到这,看着一大堆的 ::= [] | 当场傻眼了……
这是 BNF 描述,还是 Python 自己定制的 EBNF…… 为了理解它们,以后当然最好有空研究一下 “上下文无关文法”(Context-free Grammar),没准未来你一高兴就会去玩一般人不敢玩的各种 Parser,甚至干脆自己写门编程语言啥的…… 不过,完全可以跳过那些复杂的东西的 —— 因为你当前的目标只不过是 “能够读懂那些符号的含义”。
其实吧,真的不难的 —— 它就是语法描述的方法。
比如,什么是符合语法的整数(Integer)呢?符合以下语法描述的是整数(使用 Python 的 EBNF):
1 | integer ::= [sign] digit + |
以上的描述中,基本符号没几个,它们各自的含义是:
::=表示定义;< >尖括号里的内容表示必选内容;[ ]中是可选项;" "双引号里的内容表示字符;|竖线两边的是可选内容,相当于or;*表示零个或者多个……+表示一个或者多个……
于是:
interger定义是:由 “可选的sign” 和 “一个或者多个digit的集合” 构成 —— 第一行末尾那个+的作用和正则表达式里的+一样;sign的定义是什么呢?要么是+要么是-;digit的定义是什么呢?从"0"到"9"中的任何一个值……
于是,99、+99、-99,都是符合以上语法描述的 integer;但 99+ 和 99- 肯定不符合以上语法描述的 integer。
很简单吧?反正就是在 ::= 左边逐行列出一个语法构成的所有要素,而后在右边逐行逐一定义,直至全部要素定义完毕。
也许那些在此之前已经熟悉 BNF 范式的人会有点惊讶,“你怎么连 ‘终结符’ 和 ‘非终结符’ 这种最基本的概念都跳过了?” —— 是呀,即便不讲那俩概念也能把这事讲清楚到 “能马上开始用” 了的地步…… 这就是我经常说的,“人类有这个神奇的本领,擅长使用自己并不懂的东西……”
Python 对 BNF 的拓展,借鉴了正则表达式[1] —— 从最后两个符号的使用(* +)你可以看得出来。顺带说,这也是为什么这本 “书” 里非要讲其他入门书籍里不讲的正则表达式的原因之一。
又由于 Python 的社区文档是二十来年长期积累的,有时标注方法并不一致。比如,在描述 Python Full Grammar specification 的时候,他们用的语法标注符号体系就跟上面描述 String 的语法不一样了,是这样的:
:表示定义;[ ]中是可选项;' '引号里的内容表示字符;|竖线两边的是可选内容,相当于or;*表示零个或者多个……+表示一个或者多个……
—— 用冒号 : 替代了 ::=,用单引号 '' 替代了双引号 "",而尖括号 <> 干脆不用了:
1 | # Grammar for Python |
现在你已经能读懂 BNF 了,那么,可以再读读用 BNF 描述的 Regex 语法[2],就当复习了 —— 很短的:
1 | BNF grammar for Perl-style regular expressions |
真的没原来以为得那么神秘,是不?[3]
都学到这儿了…… 顺带再自学个东西吧。
这个东西叫 glob,是 Global 的缩写。你可以把它理解为 “超级简化版正则表达式” —— 它最初是 Unix/Posix 操作系统中用来匹配文件名的 “通配符”。
先看一张 1971 的 Unix 操作系统中关于 glob 的截图:
A screenshot of the original 1971 Unix reference page for glob – note the owner is dmr, short for Dennis Ritchie.
glob 的主要符号只有这么几个:
*?[abc][^abc]
现在的你,打开 Wikipedia 上的关于 glob 和 Wildcard character 的页面,肯定能做到 “无障碍” 理解:
顺带说,现在你再去读关于 Format String 的官方文档,就不会再觉得 “根本看不懂” 了,恰恰相反,你会觉得 “我怎么之前连这个都看不懂呢?”
https://docs.python.org/3/library/string.html#format-string-syntax
在自学这件事上,失败者的死法看起来千变万化,但其实都是一样的…… 只不过是因为怕麻烦或者基础知识不够而不去读最重要的文档。
比如,学英语的时候死活不读语法书。其实英文语法书也没多难啊?再厚,不也是用来 “查” 的吗?不就是多记几个标记就可以读懂的吗?比如,词性标记,v., n., adj., adv., prep.… 不就是相当于地图上的图例吗?那语法书,和现在这里提到的官方文档,不都是 “自学者地图” 吗?
但就是这么一点点简单的东西,挡住了几乎所有人,真是可怕。
脚注
[1]:The Python Language Reference » 1.2 Notation —— 这个链接必须去看一看……
[2]:Perl Style Regular Expressions in Prolog CMPT 384 Lecture Notes
Robert D. Cameron November 29 - December 1, 1999
[3]:很少有人注意到:在很多编程语言的文法文档中,"$" 被称为 <eos> —— 2017 年 5 月我投资了一个初创公司,听说他们的资产名称叫做 eos…… 我当场就被这个梗逗乐了。
拆解
在学习编程的过程中,你会不由自主地学会一个重要技能:
拆解
这么简单的两个字,在人生中的作用重大到不可想像…… 而且它也的确是自学能力中最重要的底层能力之一。
横向拆解
我很幸运,12 岁的时候有机会学习编程(习得了最基本的概念,那时候学的编程语言是 BASIC),所以,相对其他人在 “拆解任务” 方面有更强的初始意识。
后来,15 岁开始学着玩吉他的时候,发现道理其实是一样的。
有个曲子很难(当然也非常好听),曲名是 Recrerdes Da La Alhambra 阿罕布拉宫的回忆。你看看曲谱就知道它多难了:
那怎么办?怎么办?!—— 我的办法听起来看起来都很笨:
- 每次只弹一个小节;
- 而且还是放慢速度弹,刚开始很慢很慢;
- 等熟悉了之后逐渐快起来,直到正常速度;
- 再开始弹下一个小节;
- 同样是放慢速度弹,刚开始很慢很慢;
- 等熟悉了之后逐渐快起来,直到正常速度;
- 再把两个小节拼起来;
- 有些小节拼起来相对容易,另外一些需要挣扎很久才顺畅;
如此这般,最终就把这个很难的曲子弹出来了 —— 其实所有的初学者都是这么干的。
可以听听这个曲子放松一下(当然肯定不是我弹的哈哈):
1 | from IPython.display import IFrame |
<iframe
width="800"
height="450"
src="https://www.youtube.com/embed/OOsRMECWKAE?"
frameborder="0"
allowfullscreen
></iframe>
提起这事,总是会不由自主地叹口气 —— 因为在这事上我运气太差,刚把这个曲子练完没多久,还没来得及找人显摆,就摔断了掌骨和指骨,给我的手指灵活性造成了不可修复的损伤,于是,后来只能用拨片玩玩吉他了……
话说回来,自学的一个重要技巧就是,
把那些很难的任务无限拆分 —— 直至每个子任务都很小,小到都可操作为止。
比如,正则表达式,这个你必须学会的东西,学会学好真的不那么容易。一切的技能都一样,没学会之前都是很难很难的,可学会之后用熟了,你就会 “发现” 那东西其实也没多难……
那刚开始的时候怎么办?你其实需要运用拆分的本领:
- 先囫囵吞枣至少读一遍教程;
- 给自己搭好测试的环境(或许在 Regex101.com 上,或许用一个编辑器,比如 VS Code);
- 先不管什么意思,找一些 Regex 自己试试;
- 正式进入 “精度” 状态,每一小节每一小节地突破;
- 搞定一小节之后,就把它与之前的小节再反复翻两三遍;
- 把学习任务拆分成若干块,再重新逐个突破,比如,匹配,替换,在编辑器中使用,在 Python 代码中使用;
- 把各种操作符与特殊字符拆分成若干个组,而后,熟悉到牢记(而不用将来反复回来查询);
……
事实上,当你习惯这么做了之后,就会 “发现” 一切的自学任务,其实都不是 “难”,不过是 “繁杂程度不一” 而已。
很多人最终自学失败,要么是不懂拆分任务,要么就仅仅是怕麻烦而已 —— 还是那句话,人活着就挺麻烦的……
纵向拆解
拆解的第一种方法是把某个任务拆分成若干个小任务,正如上面的讲解那样,我称它为 “横向拆解”。

另外一种方法,我称它为 “纵向拆解”(有时,我也会用 “分层拆解” 这个说法)。
这种方式在自学复杂的概念体系时特别管用。
编程这种东西,之所以刚开始觉得难学,是因为其中涉及的概念除了之前我们强调的 “过早引用” 之外,还有个特征:
有的概念虽然并不同属一个层面,却常常纠缠在一起,没有明确的提示……
比如,常量、变量、字符串、函数、文件等等的概念,其实并不是某个特定的编程语言的专有概念,它们是所有编程语言都会涉及到的概念,因为计算机处理的就是这些东西,而无论哪个编程语言最终都要通过计算机去处理这些东西。
又比如说,分支与循环,每个编程语言都有对应的语句,所以,分支循环在逻辑判断、流程管理这个层面,而分支循环的 “实现” 应该划分到另外一个层面中去;而每个语言实现分支循环语句的语法多少有点差异 —— 这些细节属于那个编程语言本身:
1 | # Python 这么写: |
1 | // JavaScript 这么写: |
自学正则表达式的时候也如此。最基本的规则是属于 Regex 自己的;而后各种语言的实现各不相同,那是各个编程语言层面的;在各种编辑器中,除了基础的规则之外,也有它们自己的定制…… 看起来细节很多,但分层分类之后,就会变得很容易理解、很容易记住。
遇到 “面向对象编程” 也是如此。类、实例、对象、继承、多态…… 这些其实并不属于某一个编程语言,但它们也确实在几乎所有编程语言中被实现、被应用 —— 所谓的难,无非是因为属于两个层面甚至多个层面的概念被拧在一起教、学、练……
再比如说,在我把这个用编程当作习得自学能力的第一个 “实战项目” 之时,甚至要把 “读” 和 “写” 分成两个层面,先照顾 “读”,至于 “写”,要等到有了基本的 “读” 的能力之后再说;即便是到了 “写”,还要划分至少两个层面,首先是从 “简单的函数” 开始,而非上来就要写个 “大程序”…… 这种拆分层面的技能好像可以用在方方面面呢!
所以,要在自学的过程中,不停地想办法把它们从层面上区分开来 —— 不能总是把它们混在一块儿 “大锅烩”。
日常生活中,我们会遇到被评价为 “理解能力强” 的人,而另外那些不被如此评价的人就很不理解,很迷惑:
我到底差在哪儿了,你不说我理解能力强?难道我的理解能力很差吗?
当老师当久了,经常被这种现象震惊:
原来很简单的东西竟然可能成为很多人一生的障碍。
—— 并且,这话重复多少遍都不过分。
大多数人不太在意自己脑中的概念之间的关系,因为平日里这也不怎么耽误事。但一旦遇到复杂一点的知识体系,就完全搞不定了…… 而所谓知识体系的复杂,无非就是新的概念多一些,概念之间的关联更复杂一些…… 而概念之间的关联更复杂一些,无非是各个概念之间不仅只有一种联系,最后会形成网状连接……
—— 在《通往财富自由之路》那本书里,我几乎用了整本书的篇幅去讲解、厘清概念及其之间关系的重要性。
复杂吗?其实并不复杂 —— 在横向纵向分别逐步分清之后。
可问题在于,脑子里概念关联一团糟的人,自己并不觉得,甚至无法知道 —— 他们是那种跟你一块去看一场电影却能看到另外一部电影的人。说他们理解能力差过分吗?他们不能理解被评价为理解能力差,难道不是很自然吗?
分清概念的方法是什么?其实也不难,就是不断拆解,不断主动整理。每次用图表整理那些概念的时候,就会发现比原来更清晰一些,多次整理,最终就谙熟于心了。
想要再举更恰当更惊人的例子很难,勉为其难再举个例子。
当我在 2011 年遇到比特币的时候,现在回头看,在当时的情况下,我平日里习惯对概念及其关联进行各种纵向横向的拆解这件事给我 “创造” 了巨大的好运。后来我在《INBlockchain 的开源区块链投资原则》里提过这事:
“比特币” 这个概念,可以有多重的理解 —— 这也是为什么人们感到迷惑,或者相互之间很难达成一致理解的根本原因。
首先,比特币是世界上第一个,也是迄今为止最成功的区块链应用。
其次,比特币是一家世界银行,只不过它不属于任何权威管辖,它是由一个去中心化网络构成的。
另外,这家叫做比特币的,去中心化的世界银行,发行了一个货币,恰好也叫 “比特币”。有些人更喜欢使用相对小心的说法,把这个货币指称为 BTC,而不是 “比特币”(Bitcoin)。
最后,即便在比特币横空出世的七年后(2017),也很少有人意识到比特币(或者 BTC)其实也可以被理解为这家叫做比特币的去中心化的世界银行的股票。
—— 这无非就是把一个概念拆分成若干个层面再对每个层面准确理解而已。
但毫无疑问,这点靠很简单很简单的方法练就的理解能力,帮了我大忙。
触类旁通
无论听起来多么简单的任务,落实成代码肯定没那么简单,没那么容易。
以后你会越来越清楚的:写程序的主要工作量,往往并非来自于在编辑器里敲代码那个阶段。
更多的工作量,其实在于如何才能在脑子里把整个流程拆解清楚,考虑到各个方面……
所以,编程,更多是拿着纸笔梳理细节的工作。一旦所有的细节都想明白了,落实成代码其实是飞快的 —— 越是工程量大的项目越是如此。
这个道理在哪里都是相同、相通的。不说编程,说写书,也是一样的。
随着时间的推移,你花在 “拆解” 上的时间会越来越多,因为所有大的工程,都可以被拆解成小工程 —— 于是,也为了做出大工程,拆解的工作首先是必须,其次是最耗时费力但最值得的。
我身边很多人,包括出版社的专业编辑,都慨叹过我的 “写书速度”。我猜,实际上把他们惊到甚至惊倒的,并不是他们以为的 “李笑来写书的速度”,而是 “李笑来打字的速度” 而已。
当我告诉他们我要写一本什么书了的时候,实际上,有个工作早就完成了:“系统梳理要写的那本书的所有细节”,剩下的只是落笔把那些东西写出来而已 —— 当然,我是敲出来,用我那几乎无以伦比的输入速度敲出来 —— 那当然 “显得” 很快了!
创业也好,投资也罢,还是一样的。因为我这个人脸皮厚,不怕人们笑话,所以我可以平静地说这事:
我参与(或投资)过很多失败的创业项目……
对所有复盘的结果,无一例外,根源都是当初立项的时候,很多重要细节还没搞清楚,甚至没想到要去搞清楚,就已经开始行动…… 于是,在成本不断积累的情况下,没完没了地处理各种 “意外”,没完没了地重新制定目标,没完没了地拖延,没完没了地 “重新启动”…… 直至开始苟延残喘,最后不了了之。
拆解得不够,就容易导致想不清楚,想错,想歪……
也许,有人可能会理直气壮地反问,“怎么可能从一开始就把所有情况都想清楚么!” 唉,是呀,以前我也是这么想的…… 直到吃了很多亏,很多很多亏,很多很多很大很大的亏,才 “发现” 且不得不痛下决心去接受:事先想不清楚的,就不要去做。
这是一种特殊、且重要、又极有价值的能力。现实生活中,后来我也见过若干有这种能力的高人,比如,你可以到网上搜一个人名,庄辰超,他就是我见过的能做到干什么事之前都能全都想清楚的真人活人之一。
自学的时候,拆解任务的重要性更是如此。
这本 “书” 的一个特点,就是把 “自学”(或者平日里称为 “学习”)这个流程,拆解为 “学”、“练”、“用”、后面还会讲到 “造” 总计四个环节来处理 —— 从内容编排本身就这么干,甚至,在开头相当一部分,就明确说明,“根本不指望你读过一遍就会了”,还反复提醒,“要重复读很多遍,虽然第一遍必须囫囵吞枣”……
对于初学者常面临的尴尬,我们也从一开始就提醒,编程语言,和你之前在学校里学的语文,本质上没什么区别,先学会读,而后在多读多读再多读的同时,开始练习写 —— 这才真的很自然。
即便是开始讲如何写,我们的做法也是从 “写函数” 开始,而不是 “来,让我们写个程序……” —— 这一点点看起来不起眼的差异,作用是很大的,因为从 “小而完整” 的东西开始做(任何事)非常重要。
刚需幻觉
在前言之中,就举过一个例子,人们一不小心就把自己搭了进去…… 只不过因为没搞明白,道理就是道理,跟讲道理的老生其实全然没什么关系。
在自学中,耽误人的幻觉很多。比如,时间幻觉。人们总觉得自己时间不够了,所以学东西的时候总是很急…… 可实际上,练成一门手艺,到够用的地步,一两年足够;到很好的地步,三五年足够 —— 至于极好么,那是一辈子的事。结果呢,很多人瞎着急,乱 “省时间”,学啥都不全面,练啥都不足数足量,一晃三五年就过去,然后又开始焦虑,换个手艺再学学再试试…… 然后循环焦虑。
最坑人的幻觉,在我看来,就是刚需幻觉 —— 这又是我杜撰的一个词…… 听我慢慢讲。
感觉总是最大的坑
我的结论是:
绝大多数人的自学能力,基本上都是被 “自己的感觉” 耽误掉的。
即,原本每个人都有一定的自学能力,但最终,都被自己的感觉给干掉了,直至全然失去自学能力 —— 虽然其后也经常学习,但其后一生从事的全都是学习这个行为里最初级的模式:“模仿”。
为什么 “模仿” 是学习行为最初级的模式呢?
首先,模仿必须依赖模仿对象,受自己的视野所限。
其次,模仿只能处理表里如一的简单知识和技能;一旦遇到那些深层次的、表面上看不大出来的,模仿就无效了,即便是非要模仿、愣模仿,结果就只能是 “东施效颦”。
在《把时间当作朋友》中,我就反复强调一件事:
不要问学它有什么用,学就是了……
这原本是自学的最佳策略之一,也是自学的最根本策略。然而,听进去这句话的人不多,即便是我举了无数的例子,即便是他可能当时也有一点认同…… 然而,转瞬间又变成了原来的状态,无论遇到什么自学机会都不由自主地问:
我学它有什么用啊?
如果,得到的答案中,那 “用处” 对自己不是 “刚需”,瞬间就失去了动力,瞬间就放弃了追求…… 直至某一天,突然 “发现” 那竟然是个刚需…… 于是,临时抱佛脚。人么,总是对追求的事情形影相随;又有谁会对曾经放弃的事情念念不忘呢?于是,下一次还是会再做 “预算不足” 的决定。
最终失去自学能力的人,都是因为对 “刚需” 的判断失误 —— 这就是我说的 “刚需幻觉”。
刚需幻觉
“刚需幻觉” 的根源在于:
你不会的东西,对你来说感觉上就不是刚需。
要不是这本 “书” 里有个自学编程那么大且立体的一个例子存在,供我反复地、多角度地阐述道理,上面这句话还真的不好解释 —— 即便解释清楚了,也因为缺乏生动的例证而失去效力。
正则表达式(Regex)就是很好的例子。
当你没有学会它的时候,甚至不知道它的时候,感觉上,你不可能觉得那是个刚需 —— 因为你一直都活得好好的,甚至在你全然不知道那个东西竟然存在的情况下。
你略微学了一下,没学会、没学好、或者干脆放弃了之后,在感觉上,你也同样不会觉得那是刚需。因为你不会用它,所以你当然 “用不上它”…… 你根本没办法知道你不懂正则表达式这个事实让你 “未得到” 什么(不是 “失去”,因为你不曾拥有)。
然而,只要你花了一点力气,真的掌握了它,你会有两个 “发现”:
- 你根本离不开它[1];
- 它其实真没多难……
第二个 “发现” 总是让你无比庆幸 —— 幸亏学了,幸亏 “发现” 了,否则,自己耽误自己一辈子且完全不自知。庆幸!庆幸!!但第一个 “发现” 更为重要,因为但凡哪怕只有过一次这样的经历,你就可以永久摆脱 “刚需幻觉” 的诅咒。
编程也是一样的,当你开始学编程的时候,被身边的人发现,他们中的大多数一定会问你:
你学它要干嘛啊?
无论你怎么回答,他们的反应应该都是差不多的:反正就是不理解你的投入是否合理。
然后,等你学会了编程,掌握了这个技能,你的 “发现” 肯定包括那两点:
- 你根本离不开它;
- 它其实真没多难……
哪怕很简单的技能都是如此。许多年前,我专门花一两周的时间练习键盘盲打,以及把输入法方案选择改为微软双拼方案…… 也有人揶揄过我:“我靠,你练这玩意干嘛?难道将来要当一辈子打字员?”
当然,我很早就练就了一定的自学能力,所以很早就有一些自学经验,所以我用不着事后 “发现”,而是 “直接就知道”,将来:
- 我根本离不开它;
- 它其实真没多难……
事实上呢?事实上就是如此。打字速度极快,直接导致了后来我成为多产作家。无法想象如果我是个打字速度极慢的人,我如何写书,如何写那么多书和那么多文章;以及,后来我又是如何于 2018 年 9 月的某一天开始在 72 小时之内完成《韭菜的自我修养》初稿…… 可问题在于,这个技能难吗?在我长大的年代里,它算个技能;在今天,全都是从小就用键盘的人的世界里,谁不会呢?
所以,当面对一项新技能的时候,“觉得并非刚需” 肯定是幻觉。因为一个技能到底是不是刚需,在掌握它之前是不知道的……
只有真正掌握了那个技能之后,那个技能才会 “变” 成刚需。
并且,
一旦掌握了某项技能,它只能是刚需。
这种幻觉非常坑人。
我们的大脑,有一种神奇的功能 —— “无论如何都会用已有信息拼成一个完整图像的功能”。
“无论如何” 的意思是说,不管那已有信息有多么凌乱、有多么残缺、有多么无意义、人脑竟然还是可以拼出一个完整的 “有意义” 的图像。
这一点也经常被人利用。在新闻学里,就有著名的 “Framing Effect”:
这个原理也经常被各路营销使用:

很容易想象,经常被这些东西误导的人,“脑力” 欠缺到什么程度 —— 这当然也是他们全无自学能力的结果之一。
而当我们被刚需幻觉所左右的时候,我们明显是使用 “片面的信息” 拼出了 “完整的意义”,而后被其误导,严重误导,且全然不自知 —— 最气人的是,误导我们的竟然不是别人,竟然是我们自己的大脑!刚需幻觉如此,时间幻觉、困难幻觉亦如是。后面会讲到的注意力漂移,也依然是这种情况,自己才是真正的元凶……
所以,在决定学任何东西的时候,最好不要去咨询身边的人 —— 除非你确定对方是高手,最好是自学高手。否则,你遇到的永远是怀疑、打击、甚至嘲笑。最令人遗憾、最令人无奈的是,那些人其实也不是坏人,他们其实也不是故意,他们只是被自己的 “刚需幻觉” 误导了而已,他们(竟然)以为所有人都和他们一样…… 然后,若是你(居然)听信了他们的话,那就实在是太惨了!
要学,想学,那就自顾自去学吧,用不着征求别人的意见!
优势策略
如何不被 “刚需幻觉” 所迷惑、所限制呢?
首先,基础策略是,要深刻理解这个现象及其解释:
对任何一项技能来说,刚需是自学的结果,而不是自学的原因。
用 “是否为刚需” 作为自己是否开始学习的理由,注定会吃亏的,因为如此做的下场就是肯定被 “刚需幻觉” 所迷惑、所限制。
而后,也是更为重要的一个策略:
做个自驱动的人,而非被外部驱动的被动的人。
这基本上是个越早建立越好的习惯。绝大多数人一生都是被动者,终生只是被外界驱动而已。所以,他们会在某一时刻,“发现” 某个技能是刚需,然后再去学,但可惜却肯定的是,到那时候预算总是并不充裕,总是捉襟见肘。
最后一个很简单却很有效的策略是三个字,之前提到过的:
找活干
有活干,真的很幸福。
影响下一代
想象一下有些父母是这样跟孩子对话的:
- 爸爸(妈妈),你在干什么呀?
- 我在学 _________________(请自行填空)
- 那你学它干什么用啊?
- 等我学会就知道了……
而后又过了段时间……
- 孩子,过来看看!这是爸爸(妈妈)做的东西!
我猜,这样的孩子,会从小就自然而然地破解掉 “刚需幻觉”。
所谓的 “潜移默化”,所谓的 “耳闻目染”,其实是很简单的东西。
然而,效果呢?效果不会因为策略的简单或者容易而消减。通常的情况是,越是简单容易的策略,效用越是惊人。
所以,正确结论是这样的:
一切的技能都是刚需。
虽然,这并不意味着你不需要选择。
然而,至于学还是不学,其实从来都不是从 “有没有用” 来判断的,真正有意义的判断依据只有一条:
有没有时间?
有时间就学呗!没时间就挤时间呗!学得不足够好怎么办?花更多时间呗……
脚注
[1]:写这本书的时候,前后弄出来那么多 .ipynb 文件 —— 于是,到最后哪怕 “生成个目录” 这样看起来简单的活,若是会用正则表达式,就能几分钟完成;但若是不会,那就得逐一手工提取、排序、编辑…… 对我来说怎么可能不是刚需!
1 | import re |
> - [01.preface(**前言**)](01.preface.md)
> - [02.proof-of-work(**如何证明你真的读过这本书?**)](02.proof-of-work.md)
> - [Part.1.A.better.teachyourself(**为什么一定要掌握自学能力?**)](Part.1.A.better.teachyourself.md)
> - [Part.1.B.why.start.from.learning.coding(**为什么把编程当作自学的入口?**)](Part.1.B.why.start.from.learning.coding.md)
> - [Part.1.C.must.learn.sth.only.by.reading(**只靠阅读习得新技能**)](Part.1.C.must.learn.sth.only.by.reading.md)
> - [Part.1.D.preparation.for.reading(**开始阅读前的一些准备**)](Part.1.D.preparation.for.reading.md)
> - [Part.1.E.1.entrance(**入口**)](Part.1.E.1.entrance.md)
> - [Part.1.E.2.values-and-their-operators(**值及其相应的运算**)](Part.1.E.2.values-and-their-operators.md)
> - [Part.1.E.3.controlflow(**流程控制**)](Part.1.E.3.controlflow.md)
> - [Part.1.E.4.functions(**函数**)](Part.1.E.4.functions.md)
> - [Part.1.E.5.strings(**字符串**)](Part.1.E.5.strings.md)
> - [Part.1.E.6.containers(**数据容器**)](Part.1.E.6.containers.md)
> - [Part.1.E.7.files(**文件**)](Part.1.E.7.files.md)
> - [Part.1.F.deal-with-forward-references(**如何从容应对含有过多 “过早引用” 的知识?**)](Part.1.F.deal-with-forward-references.md)
> - [Part.1.G.The-Python-Tutorial-local(**官方教程:The Python Tutorial**)](Part.1.G.The-Python-Tutorial-local.md)
> - [Part.2.A.clumsy-and-patience(**笨拙与耐心**)](Part.2.A.clumsy-and-patience.md)
> - [Part.2.B.deliberate-practicing(**刻意练习**)](Part.2.B.deliberate-practicing.md)
> - [Part.2.C.why-start-from-writing-functions(**为什么从函数开始?**)](Part.2.C.why-start-from-writing-functions.md)
> - [Part.2.D.1-args(**关于参数(上)**)](Part.2.D.1-args.md)
> - [Part.2.D.2-aargs(**关于参数(下)**)](Part.2.D.2-aargs.md)
> - [Part.2.D.3-lambda(**化名与匿名**)](Part.2.D.3-lambda.md)
> - [Part.2.D.4-recursion(**递归函数**)](Part.2.D.4-recursion.md)
> - [Part.2.D.5-docstrings(**函数的文档**)](Part.2.D.5-docstrings.md)
> - [Part.2.D.6-modules(**保存到文件的函数**)](Part.2.D.6-modules.md)
> - [Part.2.D.7-tdd(**测试驱动的开发**)](Part.2.D.7-tdd.md)
> - [Part.2.D.8-main(**可执行的 Python 文件**)](Part.2.D.8-main.md)
> - [Part.2.E.deliberate-thinking(**刻意思考**)](Part.2.E.deliberate-thinking.md)
> - [Part.3.A.conquering-difficulties(**战胜难点**)](Part.3.A.conquering-difficulties.md)
> - [Part.3.B.1.classes-1(**类 —— 面向对象编程**)](Part.3.B.1.classes-1.md)
> - [Part.3.B.2.classes-2(**类 —— Python 的实现**)](Part.3.B.2.classes-2.md)
> - [Part.3.B.3.decorator-iterator-generator(**函数工具**)](Part.3.B.3.decorator-iterator-generator.md)
> - [Part.3.B.4.regex(**正则表达式**)](Part.3.B.4.regex.md)
> - [Part.3.B.5.bnf-ebnf-pebnf(**BNF 以及 EBNF**)](Part.3.B.5.bnf-ebnf-pebnf.md)
> - [Part.3.C.breaking-good-and-bad(**拆解**)](Part.3.C.breaking-good-and-bad.md)
> - [Part.3.D.indispensable-illusion(**刚需幻觉**)](Part.3.D.indispensable-illusion.md)
> - [Part.3.E.to-be-thorough(**全面 —— 自学的境界**)](Part.3.E.to-be-thorough.md)
> - [Part.3.F.social-selfteaching(**自学者的社交**)](Part.3.F.social-selfteaching.md)
> - [Part.3.G.the-golden-age-and-google(**这是自学者的黄金时代**)](Part.3.G.the-golden-age-and-google.md)
> - [Part.3.H.prevent-focus-drifting(**避免注意力漂移**)](Part.3.H.prevent-focus-drifting.md)
> - [Q.good-communiation(**如何成为优秀沟通者**)](Q.good-communiation.md)
> - [R.finale(**自学者的终点**)](R.finale.md)
> - [S.whats-next(**下一步干什么?**)](S.whats-next.md)
> - [T-appendix.editor.vscode(**Visual Studio Code 的安装与配置**)](T-appendix.editor.vscode.md)
> - [T-appendix.git-introduction(**Git 简介**)](T-appendix.git-introduction.md)
> - [T-appendix.jupyter-installation-and-setup(**Jupyterlab 的安装与配置**)](T-appendix.jupyter-installation-and-setup.md)
> - [T-appendix.symbols(**这些符号都代表什么?**)](T-appendix.symbols.md)
全面 —— 自学的境界
之前提到过那些 “貌似一出手就已然是高手” 的人,也为此做过一番解释:
他们的特点就是善于刻意练习……
为了真正做到刻意练习,更重要的是需要不断地进行刻意思考 —— 刻意思考自己究竟应该在哪些地方必须刻意练习?
之前也说过,人和人非常不同,于是,需要刻意练习的地方也各不相同。
不过,倒是有一个方面,所有的自学者都必须刻意练习 —— 这是谁都逃不过的地方:
全面
那些 “貌似一出手就已然是高手” 的人就是在这一方面超越了绝大多数人 —— 在每个层面上,他们都学习得更全面,练习得更全面,使用得更全面,在使用此技能去创造的时候,思考得也就自然更为全面。于是,就产生了 “全面碾压” 的效果。
然而,这是很难被人发现的 “秘密”,因为 “全面” 这个事实,只存在于这些高人的大脑之中,很难被展示出来…… 而他们不会想到这是个什么 “秘密” —— 因为他们一直就是这么做的,他们会误以为所有人都是这么做的。
小时候,我经常看到父亲备课到深夜。他手中的教科书,每一页的页边都密密麻麻地写着各种注释,实在没地方写了,就在那个地方插上一张纸,于是能写得更多…… 到最后,他的那本书,要比别人同样的书看起来厚很多。
许多年后,我竟然成了老师,于是,我就备课。我备课的方法自然是 “拷贝” 过来的,我父亲怎么做的,我见过,于是我也那么做。到最后,都到了这个地步:只有那书已经成了别人的两倍厚度心里才踏实。
又过了一段时间,在一个内部分享会中,我听到一位老师的说法,他问我:
…… 李老师啊,您已经讲了这么久了,都熟到干脆不用备课的地步了吧?
我愣了一下,讲课前不用备课这事根本就不在我的想象范围之内啊!我父亲讲了那么多年的课,不还是经常备课到深夜嘛?我也一样做了,总是觉得 “还是有很多可以补充的地方” 啊!
然而,这个小插曲提醒了我一个现象:
我会那么做,我就会误以为所有人都会那么做……
我猜,那些 “貌似一出手就已然是高手” 的人,也一样,他们从未觉得这是什么 “秘密”,他就是那么做的,他们很久以来就是那么做的,他们误以为所有人都是那么做的。
从另外一方面,外人更希望他们拥有的是个 “秘密”。于是,因为自己并不知道那个 “秘密”,所以,自己做不到他们那样 —— 这样看起来就合理了,自己的心里也够舒服了,毕竟看起来理所应当了么。
把自学当作一门手艺,把所有的技能也都当作一门手艺,那就相对容易理解了:
全面,是掌握一门手艺的基本。
为了全面,当然要靠时间。所以,关于 “混与不混”,我们有了更深刻却又更朴素的认识:
所谓的不混时间,无非就是刻意练习、追求全面。
也正是这个原因,几乎所有自学高手都懂这个道理:
绝对不能只靠一本书
有个特别有趣的现象,我觉得绝大多数人平日里都挺大手大脚的,都挺舍不得对自己过分苛刻的,但一到买书这件事上,绝大多数人真的很节俭,真的很苛刻 —— 对待越严肃的知识越是如此。倒是在买本小说啊或者买张电影票的时候,基本不用过脑子。
他们好像完全不知道自己正在疯狂地虐待自己…… 的大脑。
对自己的胃好一点,我绝对认同 —— 因为我自己就是个吃货。
可是,在很长一段时间里,我完全不能理解人们为什么不由自主地对自己的大脑不好,不仅是不好,还是格外地不好,甚至干脆是虐待。
观察学生多了,也就慢慢理解了。
绝大多数人事实上从来没有习得过自学能力,他们终生都在被指导、被引领。而在校教育少则九年,多则十几年二十年,他们体验过太多 “不过尔尔” 的学习过程。他们肯定不是没花过钱,九年义务教育的过程中,就花了父母很多钱,后面若是上了大学,花钱更多…… 花过那么多钱,却总是没什么收获,在他们的经验中,“这次我应该小心点” 是再自然不过的事。
“第一次突破” 很重要。
如果一个人有过一次只通过阅读书籍即获得一项新技能的体验,那么,他们内心深处(更准的说法是大脑的底层操作系统)的那个成本计算方法就会发生改变,心里想的更可能是:
- 这肯定是有用的,一旦学会,收益可不是几十块钱的书价或几百块课价那么一点点……
- 至于是否能学会,主要看我投入的时间精力预算有多少……
我身边有很多自学能力非常强的人。
这些人买书的方式都是一样的,一旦他们决定学习什么技能的时候,第一个想到的是去买书,而不是去找人。他们之前体验过,他们就是很清楚:
- 首先,书里什么都有;
- 其次,仅靠阅读在大多数情况下绝对够了……
更为不一样的是,他们一定会买回来一大堆书 —— 而不是四处去问,“关于 xx 的哪一本书最好啊?”
在他们眼里,书是成本最低的东西,比起最终的收益来讲更是不值一提。
更为重要的是,一本书绝对不够 —— 无论是谁写的,无论那个作者多么著名,影响力有多大…… 因为,书也好、教程也罢,这种东西就是有 “篇幅限制” 的。更为关键的是,每个作者都有不一样的视角、不一样的出发点和不一样的讲解方式、组织方法。
比如,我这本就跟别人写的很不一样。我的出发点是把编程当作一个自学的例子,重点在于学会如何自学,并且通过实践真的习得一个起初你觉得不是刚需,学会之后发现干脆离不开的、不可或缺的技能。这本书的内容组织方式也不一样 —— 反正你现在已经知道了。
另外,这本书的目标里有更重要的另外一个:“让你有能力靠自己能够理解所有的官方文档” —— 书里不用讲官方标准库里的每个模块、每个函数究竟如何使用,因为那些在官方文档里定义得非常清楚……
而其他人写的呢?比如 Think Python,比如 A Bite of Python,再比如 Dive into Python[1],以及网上很多很多免费的 Python 教程都写得很好呢!
没有经验的人不懂而已。当你搞明白了一本书,后面再多读哪怕很多本的时间精力成本都是很低的,但每多读一本,都能让你在这个话题中变得更为完整。
针对同一个话题读很多本书的最常见体验就是:
- 嗯?这个点很好玩!这个角度有意思!
- 看看比比前面几个作者怎么论述的呢?
- 嗯?!怎么我看过却竟然没注意到呢!
这最后一条真的是很令人恼火却又享受的体验。它令你恼火,是因为你竟然错过;它令你享受,是因为虽然错过却竟然还有弥补的机会!
总有一天你会明白的,一切的 “学会” 和 “学好” 之间的差异,无非是全面程度的差异。
于是,翻译过来,“学好” 竟然如此简单:
多读几本书。狠一点,就是多读很多本书。
到最后,这种习惯会慢慢延伸到生活中。比如,我在遇到好歌的时候,总是想尽一切办法找到那首歌的很多版本,首唱者可能有很多版本,录音版、现场版,不同年份的版本等等;还有很多翻唱…… 看电影也一样,若是有翻拍版本,一定会找过来看 —— 不同国家的翻拍版本对比起来特别好玩。
甚至,到最后,你做东西的时候都会想着顺手多做几个版本。我这本 “书”,就肯定会有印刷版、电子版…… 到最后还会有个产品版 —— 这基本上是目前尚无其它作者做到的事情。
提高对所学知识技能的 “全面程度”,有个最狠的方法 —— 再次说出来不惊人,但实际效果惊到爆:
教是最好的学习方法。
这真的不是我的总结,人类很早就意识到这个现象了罢?
孔老夫子在《礼记・学记》里就 “曰” 过:
“学然后知不足,教然后知困。知不足,然后能自反也;知困,然后能自强也。故曰:教学相长也。”
到了孔子三十二代孙,孔颖达,解读《兑命》中所提 “学学半” 时,说到:
“学学半者,上学为教,下学者谓习也……”
许嘉璐先生[2]有一本书,《未央续集》,提到这段解读的时候讲了个自己的例子:
“我当了五十年的教师,经常遇到这种情况:
备好课了,上讲台了,讲着讲着,突然发现有的地方疏漏了,某个字的读音没有查,文章前后的逻辑没有理清楚,下完课回去补救,下次就不会出现同样的情况了,这就是教学相长。”
所以,别说老师了,学生更是如此。
我经常讲我所观察到的班里的第一和第二的区别 —— 因为这是很好的例子。
第一总是很开放,乐于分享,别人问他问题,他会花时间耐心解答;第二总是很保守,不愿分享,不愿把时间 “浪费” 在帮助他人身上…… 注意,在 “浪费” 这个词上我加了引号 —— 这是有原因的。
我的观察是,这不是现象,这是原因:
第一之所以比第二强,更可能是因为他开放、乐于分享,才成了第一。
而不是因为他是第一,所以才开放,所以才乐于分享。
因为到最后,你会发现,第一并没有因为时间被占用而成绩退步,反而成绩更好。这是因为他总是在帮助其他同学的过程里,看到了自己也要避免的错误、发现了其它的解题思路、巩固了自己的知识点,所以他在社交的过程中学到了更多,同时还收获了同学们的友谊 —— 换言之,通过分享,通过反复讲解,他自己的 “全面程度” 得到了最快的提高。
而第二呢?第二其实有可能比第一更聪明呢 —— 他可是全靠自己走到那个地步的!可是,他没有用最狠的方式提高自己的全面程度,虽然排名第二,可他其实只不过是一个 “下学” 者,于是,他很吃力的 —— 虽然他实际上很聪明…… 于是,在这种感受下,他怎么肯愿意把那么吃力才获得的东西分享出去呢?
这真是个有趣且意味深长的现象。
另外一个有趣的现象是,“下学” 者永远等待 “上学” 者整理好的东西。之前在《如何从容应对含有过多 “前置引用” 的知识?》提到过一个对应策略:
尽快开始整理归纳总结
同时给出了建议:
一定要自己动手去做……
不仅如此,还描述了个我自己的例子,通过 “自己动手整理” 才发现自己之前竟然完全理解错了。
我这方面运气非常好,因为父母全都是大学教师,从小父母就鼓励我帮同学解答问题,这让我不知不觉在很早很早就开始了 “上学” 的阶段。
这一次写这本 “书” 的过程中,同样的 “奇迹” 再次发生在我身上。
说实话,正则表达式我一直没有完全掌握 —— 虽然偶尔用用,也都是边查边用。实在解决不了,就算了…… 现在回头想想,多少就是因为 “仅凭感觉,并没觉得那绝对是刚需” [3] —— 当然,真正会了之后,马上开始时时刻刻都有可能使用,离开它简直活不下去 —— 写这书的后半程,有大量的重新组织的需要,很多文字替换,若是没有正则表达式,就干脆没法干……
我是如何完全掌握正则表达式的呢?就是因为写这本书。既然是写书,当然害怕自己在不经意中出错,此为其一。更为重要的是,必须先完整掌握之后才能有诸如 “为读者提供更好一点的理解起点”,“理解起来相对更简单直接的组织结构”,以及 “挖掘必须习得它的真正原因以便鼓励读者” 之类的畅销书卖点 —— 对作者来说,有什么比销量更重要的呢?
写一本好书,对我来讲,这个需求太刚了,刚到好像是钛钢的地步。
于是,本来就习惯于同一个话题多读好多本书的我,读了更多的书,翻了更多的教程,官方文档翻了更多遍,做了更多的笔记,每一章反复废掉原稿再次重写了很多遍…… 在这样的刺激下,“全面程度” 若是没有极速提高,那才怪了呢!
还有啊,我的英语,也是这么搞出来的。
所以,很多的时候,我这个人并不是 “好为人师”,细想想,貌似 “好为己师” 更为恰当一点。写书也好讲课也罢,其实自己的进步是最大的。
若是我没有在新东方教书七年,我连当前这个半吊子英文水准都不会有…… 为了在讲台上不犯错,多多少少都得多费一些功夫吧?我的经验和许嘉璐先生是一样的,无论备课多努力,后面还是会有纰漏…… 可是,这若只是做个 “下学” 者,岂不更惨?
哦,对了,其实所有的读者,都可以用这个简单的方法影响下一代:
有同学问,你就一定要耐心讲讲 —— 对自己有好处。
当然,最直接的方法是把自己变成 “上学” 者,保持开放,乐于分享,而孩子只需通过 “耳闻目染” 就可以了。
脚注
[1]:一点八卦:Dive into Python 的作者是 Mark Pilgrim;他是互联网上最著名的自绝于信息世界(infosuicide)的三人之一。另外两位分别是比特币的作者 Satoshi Nakamoto,和 Why the lucky stiff 的作者 Jonathan Gillette。
[2]:许嘉璐,1998 年至 2000 年全国人大常委会副委员长,民进中央主席,国家语言文字工作委员会主任。
[3]:写完这一段,给霍炬看,他当场嘲笑我,“哈!当年我就说,你应该学学 Vim,是不是到现在你都没学?” 我无言以对,因为真的就没学…… 然后,我想了想,回复他说,“好吧,我决定写一个 Vim 教程出来,嗯。”
自学者的社交
很多人有莫名其妙的误解,以为 “自学”(self-teaching)就一定是 “自己独自学”(solo-learning),殊不知,自学也需要社交。也有另外一些人,因为 “专心” 到一定程度,觉得社交很累,所以开始抵触一切社交。这些都不是全面的看法。
事实上,在任何领域,社交都是必须的,只不过,很多人没有建立、打磨过自己的社交原则,所以才被各种无效社交所累。就算讨厌,讨厌的也不应该是社交,而是无效社交。
在自学的任何一个阶段,学、练、用、造,社交都可能存在。
哪怕是在最枯燥,看起来最不需要社交的 “练” 的阶段,社交也会起很大的作用 —— 在自己累了的时候,看到有人还在练,看到很多人都在练,看到很多人其实也挺累的但还在练…… 这些都是让自己感觉没那么费劲的好办法。
实际上,在最初 “学” 的阶段,社交也是极为重要的。
生活中,你遇到过这样的现象没有:“看见别人打针,自己先疼得受不了……” 这是因为我们的大脑中有一种神经元,叫做镜像神经元(Mirror Neuron),它会让我们 “感同身受”,当我们看到另外一个人正在做什么的时候,镜像神经元会尽力给我们足够的刺激,让我们 “体验” 那个人的感受。以前人们不知道为什么哈欠竟然会 “传染”,现在科学家们很清楚了 —— 那就是镜像神经元在起作用。
镜像神经元的存在,使得我们有模仿能力、有通感能力、有同情心、有同理心…… 这也是为什么人类天然有社交需求的重要原因,因为我们的大脑皮层上都有很多的镜像神经元。
一般来说,物品、书籍之类非人的东西,都不大可能激活镜像神经元。只有看到人的时候,镜像神经元才会被激发。所以,你送给小朋友一把吉他,他不会有什么兴趣的。可若是你在弹琴的时候被他看见,他的镜像神经元就会因为你的行为而被触发,进而对弹奏吉他感兴趣 —— 注意,不是对吉他本身感兴趣。若是你在弹琴的时候,带着某种能够打动他的情绪,那他更容易被影响,因为情绪更能激发镜像神经元。也就是说,一切的学习起初都基于模仿,一切的模仿,都源自于看到真人的行为 —— 哪怕是在电影里看到,虽然只不过是影像而已,并非真人,但毕竟是真人的影像。
所以,无论学什么技能,都要找到用那种技能的人,这样我们的镜像神经元才可能更容易被激发,学习效果才会好。若是能找到热爱那项技能,乃至于一使用那项技能就很开心(最好的情绪之一)的人,那就更好了。激情这东西,是少数幸运儿才长期持有的东西,大多数人小时候挺多,过了十五六岁之后就开始有意无意磨灭了激情,且并不自知。
之前提到,
当我们看到另外一个人正在做什么的时候,镜像神经元会尽力给我们足够的刺激,让我们 “体验” 那个人的感受。
这句话里有个词很重要,“尽力”。因为镜像神经元只能调用我们大脑里已有的信息去模拟对方的感受,所以,它最多也就是 “尽力”,无法做到 “确保正确”。今天的糖尿病患者使用的皮下注射针头,已经可以做到很细,细到让使用者 “无感” 的地步,所以,当一个糖尿病患者给自己注射胰岛素的时候,他自己并不觉得疼,可是看的人却能 “疼” 到紧皱眉头的地步,为什么?因为旁观者的大脑里没有实际用那么细的针头注射胰岛素的经验,所以镜像神经元在旁观者 “感同身受” 时所调用的,其实是过往旁观者自己打针的体验 —— 被很粗的针头做静脉注射的痛苦体验。
所以,很多人误以为他们眼里的成功者靠的是 “坚持”、靠的是 “毅力”,这完全是自己的镜像神经元 “尽力” 的结果,是 “调用自己过往经验去感同身受的结果”…… 事实上呢?那些 “成功者” 其实并不在意成功,因为到死之前成长不应该也不可能结束,因为那是他们的生活方式,学习、进步、探索、迂回,甚至折腾、挫败和迷茫,都是他们生活中必不可少的内容,这是最初不自觉的选择,谈不上什么 “坚持”,谈不上什么 “毅力”…… 说实话,对他们来说,不让折腾才真痛苦呢,不学习才需要坚持和毅力呢!
再进一步,这也是为什么要选择朋友的原因。人与人之间有很大的差异,最大的差异来自于性格养成,大多数人会沦为表现型人格,只有少数人才会在不断调整中保持、呵护、进一步培养 “进取型” 人格。他们自然而然地更为乐观,更有耐心,更有承受力,更有战斗力,更能生产更能体验学习与进步的乐趣。与这样的人在一起,学习会更容易 —— 只因为镜像神经元会更容易地被正确激发。说清楚了,道理其实挺简单的。
有一次朋友跟我聊起他苦于没办法培养自己孩子的正经兴趣爱好…… 我说,其实很简单,只不过是你方法错了。你不用告诉孩子 “应该学什么,应该对什么感兴趣”,而是,想尽一切办法让孩子见识到拥有那个技能的,令他产生羡慕情绪的人 —— 只要孩子羡慕那个人,他就自然而然地有 “我也想这样” 的想法,到最后,谁都拦不住。这就是镜像神经元的力量。进而,所谓的社交,还真不一定是非要跟人说话、聊天…… 见识到,也是社交的最主要组成部分。
你看,谁说社交不重要?
进而,想要把一门手艺搞到真正 “精湛” 的地步,最有效的方法就是尽早进入 “造” 的阶段 —— 所谓的 “造”,就是不断创造的 “造”。
自学这门手艺,很简单,就是不断地学:
1 | def teach_yourself(anything): |
学上几个,自然就很精湛。而其它的用自学这门手艺习得的手艺,基本上都可以用 “是否做出了像样的作品” 作为检验自己的那门手艺是否达到了精湛的衡量指标。
硅谷有一家著名的孵化器,叫 Y-Combinator,现在的掌门人是个很年轻的人,Samuel H. Altman。他在那篇著名的文章《Advice for ambitious 19 year olds》中有一个精彩的建议:
No matter what you choose, build stuff and be around smart people.
无论你选择了什么,都要造出东西来,要与聪明人打交道。
当然,对于 “聪明人” 这个概念,我和 Sam 的看法并不一致。在我看来,有好作品的人都很聪明,但还是那句话,那不是天分和智商,那分明是有效积累。
我个人最看重的个人品质之一,就是有没有像样的作品。
很少有人有像样的作品。人群中只有少数人最终能拿出完整的作品 —— 人与人之间的差异是如此之大,乃至于少数人有作品,更少数人有好的作品,只极少数极少数人才可能做出传世的作品;而与此同时,绝大多数人(万分之九千九百九十九的人)一辈子都没有像样的作品,他们连一篇作文都写不明白。于是,与有像样作品的人打交道,总是非常值得。
并且,跟他们打交道也不费劲,都是思考非常通透的人,通常沟通能力极强。哪怕沟通起来貌似费劲的那一小部分,事实上也不是难以沟通,那只不过是人家简单朴实而已。
我甚至经常建议我的合伙人们,在招人的时候,把这一点当作最靠谱的判断方式。少废话,少吹牛逼,给我看看你的作品。这个原则可以一下子过滤掉所有的不合格者。另外一个很自然的现象是,如果一个人能做出像样的东西来,那么他身边的聪明人密度无论如何都会比其他人的高出很多。
地球上有效社交密度最高的地方,是 Github。有些程序员们常开玩笑,说 Github 是全球最大的同性社交网站,事实上,他们不知道,女性程序员的比例正在逐步提高,而且女性在科学上,从来就没有屈居二线过[1]。
在 Github 上,找到自己感兴趣的项目,而后为那项目贡献一己之力,用自己的工作赢得社区的认同…… 这就是 Github 上的社交方式。若是自己做了有意义的项目,就会有更多人关注;若是那项目对很多人有用,那就不仅有很多人关注,更有很多人会像当初的你一样为这个项目做贡献…… 这就是程序员们的有效社交。
Github 能成为地球上最大的有效社交网络,没毛病,因为用作品社交肯定是最高效的。
所以,无论学什么,都要想尽一切办法尽快做出自己的作品。做一个产品出来的过程中,会磨练另外一项自学者不可或缺的能力和素质:
完整
与之前提到的另外一项加起来,就构成了自学者的最基本素养:
- 学就学得全面;
- 做就做得完整。
无论多小的作品,都会让创作者感受到 “单一技能的必然无效性” —— 你试试就知道了。哪怕你想做个静态网站,你都会发现,仅仅学会 html/css 是不够的,因为部署到远端服务器上的时候,你无论如何都得学学 Linux 基本操作…… 而已然具备了自学者基本素养的你,自然会想办法 “全面掌握”,而不是糊弄一下而已。
更为重要的是,一旦你开始创作作品,你更大的 “发现” 就是,你肯定需要很多 “之前看起来并不相干的知识与技能”,而非 “只靠专业就够了”……
还是拿我出第一本书为例。那之前我没有写过书,若是出版了书放在书店,没有人知道李笑来是谁…… 于是,只有内容本身,并不保证那书能卖出去。除了把内容写出来之外,我必然要去学习很多之前完全没碰过的东西,比如 “如何才能做到系统持续地修订内容”;又比如,“如何与出版社编辑正常沟通”;再比如,“如何取一个好书名”…… 一个赛一个地 “与专业无关”。
所以,“做得完整”,从来都不是容易的事情。
从这个角度去理解,你就会明白那些高明的手艺人为什么总是做小东西 —— 那是因为在追求完整的过程中,你必然会发现,越小越容易完整。这也是为什么庸人总是好高骛远,因为他们不顾完整,所以就可以妄图建造海市蜃楼。
手艺人不怕做的事小。而且,“小” 无所谓,“完整” 才是关键。
有作品和没作品的人理解能力也不一样。做过作品的人,看到类似 MoSCoW Method 的做事原则,瞬间就能有所感悟,而没有作品的人,却不见得有一样的感受。
顺带给你看个 Wikipedia 上的链接列表,在编程领域里,有无数可以借鉴到生活中的哲学、方法论:
给自己足够长的时间去学;在充足 “预算” 之下耐心地练;不断找活干,以用代练;然后,最重要的是,一定要尽快尝试着做出属于自己的完整作品,无论大小。
只有这样,你才是个值得被交往的人。
脚注
[1]:NPR:Most Beautiful Woman’ By Day, Inventor By Night

上图是保存在美国专利局的一个存档文件(US Patent 2,292,387, Aug 11, 1942)截图。这项专利的发明者是 Hedy Lamarr,人家长得是这样的:

Hedy Lamarr 是好莱坞最知名的演员之一,并且,她也是自学高手:
Although Lamarr had no formal training and was primarily self-taught, she worked in her spare time on various hobbies and inventions, which included an improved traffic stoplight and a tablet that would dissolve in water to create a carbonated drink. The beverage was unsuccessful; Lamarr herself said it tasted like Alka-Seltzer.
这是自学者的黄金时代
历史上,自学者从未像今天这样幸福。
以前不是这样的。比如,几乎每个中国人从小就听说过无数次那种 “为了拜师学艺一跪就几天甚至几个月也不一定被收下” 的故事。
在古代,拜师学艺的确是很难的事情。首先,真正的好老师确实难寻;其次,高手也没空当老师;再次,就算是肯收徒授艺的老师也总是时间精力极其有限…… 更为重要的是,那时候想自学也真不行 —— 根本就没有什么称得上是文献的东西可供阅读或检索,很多重要信息甚至干脆只存在于某些人的脑中,就算它们被落实成了文献,也相当有限,且散落深藏在各处 —— 就算凑齐了,也没有 Google!
对,最关键的是那时候没有 Google……
今天的互联网,已经不再是二十几年前刚出现的那样 “激进而简陋” 的东西了。经过多年的发展,互联网上的内容已经构成了真正意义上的 “全球唯一通用图书馆” —— 而针对它可用的检索工具中最好的,当然是 Google。
于是,今天,自学者在真正的意义上身处于一个黄金时代 —— 没有什么是不能自学的。注意措辞,在这句话前面甚至根本不用加上 “几乎” 这样的限定以示准确 —— 你想学什么,就能学什么,而不是 “只有先拜师才能开始学艺”。
今天的你,想学什么就去问 Google;在学习中遇到什么问题,就直接问 Google —— 直接问它,通常总是比向某个人提问有效率得多。Google 就是这样,越用越离不开它……
其实很多人并不真的懂如何用好 Google 的,可是连这个它也能解决,因为你可以直接问它:
经过多年的发展,Google 的使用体验越来越好,2019 年的今天,你搜索以上语句返回的页面里,Google 甚至在众多搜索结果中选了一条它 “认为” 是 “最佳” 的搜索结果:
lifehack.com 上的这篇文章也的的确确值得细读 —— 读过且真正理解之后,不夸张地讲,你的 “搜索技能” 已经足够灭掉整个人类当前活跃群体中的 99% 了…… 这个说法真的完全没有夸张,绝大多数人就是不会在搜索的过程中使用那些符号的,比如 - * ~ @ # : " .. —— 还有很多其它技巧…… 话说,你在 Google 上用过 Time *place* 吗?
已经掌握了正则表达式以及 glob 的你,学习一下如何使用这种符号,实在是太小菜一碟了 —— 然而,这么简单的东西所能带来的未来收益是非常惊人的,不信走着瞧。
可实际上,还是得应用我们之前说过的原则:
首选查询,肯定是官方文档。
这么做的重要理由之一,是为了让你少受 “二手知识” 的蒙蔽和误导。这里有一个绝佳的例子让你理解二手知识的局限性:我写过的一本 “书”,发布在网上 —— 这本 “书” 的另外一个 “神” 之处,在于它能让你 “顿悟” 阅读的力量,不管你是男生还是女生…… 若是这个链接错过了,你竟然会错过整个生活!
Google Search 的官方文档在这里:
Google 还有更为强大的工具给你使用,叫做 Google Custom Search,官方文档在这里:
对编程工作来说,Google 当然格外地更为重要 —— 互联网上积累的最多最专业的信息,当然是计算机相关信息。所以,当你遇到什么错误提示的时候,不仅要问 Google,还要优先问问 Stackoverflow —— 连 Google 自己都这么干。在 colab.research.google.com(Google 为它的 TensorFlow 服务搭建的 Jupyterlab 环境)上,如果你运行什么代码出错了的话,那么,出错信息下面会出现一个按钮,上面写着:SEARCH STACK OVERFLOW,点击它就直接给你 Stackoverflow 上的搜索结果…… 真够意思!

Google、Stackoverflow、Wikipedia、Youtube,这些都是你经常要去搜索的好地方。
二十年前,Google 刚出现的时候,谁能想象它今天这个样子呢?以下是 1998 年 11 月 11 日 http://google.com 这个网址的截图:
当时,网站还没有正式上线,第一个链接是一个原型设计,用一个二级域名发布在斯坦福的网站上:http://google.stanford.edu/:
那个时候,Google 还要向外人强调一下,他们已经有 2500 万页面可供检索!
事实上,到了 2008 年,Google 公告称,可供检索页面已经超过一万亿(One Trillion),到了 2016 年年底,这个数字已经超过 130 万亿……
换个角度看,这个数字同时也是互联网上信息的积累 —— 世界上再没有比互联网更大更全的 “书” 了。并且,由于 Google 的存在,互联网这本大书,是可检索的!
于是,有事先问 Google 就成了自学者的必备修养。
能 Google 出答案的问题,就不需要去麻烦别人。
这也是一个自学者的基本素养。
偶尔,也确实会遇到 Google 了很久,就是没有找到答案的情况…… 这样的时候,你可能需要想办法 “问人” 了。然而,最靠谱的通常并不见得是 “身边的人”,而是互联网上各种垂直社区里的其他用户……
向人问,也是有学问的 —— 很多人张口就问,结果呢?结果没人理。为什么呢?
作为一个有素养的自学者,有一篇文章必须精读:
这是大神 Eric S. Raymond 和 Rick Moen 于 2001 年在网上发布的文章,被人们奉为经典;迄今为止经历了很多次的修订,最后一次是在 2014 年,Revision 3.10 —— 前后被翻译成了许多种语言。
不认真使用 Google,你就错过了整个人类历史上自学者最黄金的时代。
避免注意力漂移
注意力漂移,是我杜撰的一个词,用来作为 “注意力集中” 的反义词 —— 因为更多的时候,我们并不是 “注意力不集中”,而是…… 而是更令人恼火的一个现象:
“注意力所集中的焦点总是不断被自己偷偷换掉……”
比如,你本来只不过就想着去 Google 一个编程错误信息的解读,结果不知道怎么就 “注意到” 了另外一个东西,比如,“某编辑器的皮肤”,然后你就 “顺手” 把它下载下来,然后 “很自然地顺手把它装上”,而后又看了看,觉得有点必要于是 “顺手做了点定制”…… 然后欣赏了一会儿,并自我得意一番之后 “突然发现” 自己还没有解决两小时之前要解决的问题!
说这种现象 “令人恼火”,是因为那注意力所集中的焦点,是被自己偷偷换掉的!
好奇心越重的人,越是容易被注意力漂移所拖累。
好奇心是好东西,而且是必须认真呵护的东西 —— 几乎最重要、最强劲的自学动力,都混合着好奇心出现并持续。
在我成长的那个年代里,很多孩子本来是可以成为自学专家的,结果,99.99% 都被父母给毁了 —— 而且还是不经意地毁的。那些父母毁掉自己孩子的方法简单直接又粗暴、且毫不犹豫。
刚开始图好玩,小孩子问啥都回答…… 当然,最初的时候,小孩子问的问题也很容易回答;就算不容易,也很容易糊弄过去。没多久,父母就开始应付不过来了,一方面自己也没那么多耐心了,另外一方面是更为严重的问题 —— 自己的脑力不够。再加上那时候也没有 Google,所以,父母的反应惊人地一致:“去去去,赶紧睡觉!怎么就你事这么多?!”
一个个小朋友就这样被毁掉了,他们的好奇心就这样成了他们自己要主动避免的东西 —— 否则就会挨骂,谁愿意动不动就被一通数落呢?
好奇心是驱动一个人不断进步的最重要动力之一。所以必须不断呵护,呵护到老才对。
然而,就是这个如此金贵的东西,也会成为拖累;而且,若是真的被它拖累,那么最终真的会感觉非常遗憾,被好东西拖累 —— 太可惜了。
刚才所描述的,还只不过是两个小时而已的 “损失”。事实上,被注意力漂移所拖累的人,损失肯定远不止如此。在做 “工程” 或者 “项目” 的时候 —— 尤其是那种非实物类的工程或项目,比如,写个书,写个软件之类的 —— 注意力漂移导致的结果就是:
时间不断流逝,可是工程却永远没有结果。
这种损失,完全是任何正常人都没办法承受的…… 这话其实并不准,因为事实上据我观察,绝大多数人受到这种拖累的结果,自己其实无法想象 —— 因为永远没有完成过什么项目,永远没有完成过什么工程,又如何知道自己损失的究竟是什么呢?
到今天为止,我自己依然还是个需要不断与 “注意力漂移” 争斗的人 —— 许多年前,我注意到这个现象的时候,经过思考,就接受了一个事实:
注意力漂移不是能杜绝的现象,但必须在关键时刻有所应对……
如果当年的我没认真想过这事,没思索出对策,那么后来的我也不可能写那么多书,转行那么多次,自学那么多大大小小的技能…… 当然,各位读者也完全看不到现在正在阅读的文字 —— 因为它们不可能被完整地写出来,甚至干脆就不应该存在。
在罗列并比较众多策略之后,我选了一个看起来最不相干,却最本质的策略:
把 “全面完整” 放到最高优先级。
而后,这些年全靠这个策略挺了过来……
当我想做什么事的时候,或者想学什么东西的时候,我会投入一定的时间去琢磨,这个事或者这个东西,要做得全面完整,或者要学得全面完整,那都应该做什么呢?在思考如此严肃的问题的时候,我还是习惯用纸和笔,写写画画 —— 迄今为止没有找到合适的电子设备和软件替代。
我买笔记本,不是为了记笔记的,因为记笔记这个东西,实在是在电脑上做更方便,许多年前开始就是如此了。我的笔记本主要用来做一件事:
罗列整理那些为了做到 “全面完整” 而必须优先做的事。
用列表也好、或者用图表也罢,反正都是要不断整理修订的,而它的存在,给了我一个优先级:
除了这上面罗列的这些东西之外,在当前时间段,别的都不如它们重要。
一旦发现自己的注意力没有集中在这上面的关键之时,一旦发现自己的注意力已经漂移到其它当前并不重要的事项上,就马上纠正。
谁都知道应该先做重要且紧急的事情,可问题在于,如何判断 “是否重要” 呢?全面完整这四个字就会给我指引。
一方面,是用全面完整来保持自己对重要事情的关注,另外一方面,还需要提高对抗不相关完美诱惑的能力。十年前,我写《把时间当作朋友》的时候,还把这东西叫做 “脆弱的完美主义倾向”,现在我已经把这个概念升级了 —— 因为更准确地讲,那不是 “完美主义者的脆弱”,那是 “能力不及格者” 的 “轻重不分”。
早些年,我跟很多人一样痴迷于电脑这个东西,也跟很多人那样,用 Windows 惯出来了坏毛病 —— 动不动就重装系统…… 重装系统很浪费时间的,但那时也不知道为什么总是忍不住去干那事,哪怕有些小毛病,马上就受不了,弄的好像重装一个干净的操作系统会让自己的世界焕然一新一样。
再后来就明白了,这绝对就是自己的毛病 —— 做事不分轻重。
说实话,这也不是自己想明白的 —— 我没那么聪明。是因为遇到了一个高人。他的电脑桌面上,乱七八糟摆满了各种图标,从不整理。我问他这不影响效率吗?他说,明明有搜索你不用,到底是谁效率低下?我被问愣了,无言以对。
我又发现他根本没有装杀毒软件…… 我问为什么?他说,“养几个虫子玩玩也没什么不好……” 不过,他转念又告诉了我他的思考。他说,只要平时习惯好,病毒进来了也没啥可偷的,但更为关键的是,他用电脑是干活的,而不是干杀毒的活的…… 脑子如此清楚,让我自愧不如。
但学到了。
虽然我还是做不到桌面上图标很乱,虽然我是因为改用了 Mac OS,所以不装杀毒软件,但注意力要放到应该放的地方,这事我记住了,牢牢记住,从此之后许多年,从未忘过。每次发现自己轻重不分的时候,就会想起他,然后就改过自新。
如何成为优秀沟通者
一般认为,“手艺人” 的普遍特征之一就是缺乏沟通能力,或者沟通能力差 —— 也许是因为平时把所有的时间精力都投入到磨练手艺上去了罢。
但这肯定不是最主要的原因。你看手艺不怎么样的人沟通能力更差;手艺顶级的人却常常反过来沟通能力很强很强…… 为什么呢?
所以,最核心的理由,应该是一个人最基本的选择而已:
看一个人是否重视沟通能力。
因为若是一个人重视沟通能力,那么,他就自然而然地会想办法去进行刻意练习。如果他本人并不重视沟通能力,那么,自然就没有任何时间精力投入在这方面,结果就非常自然而然了。
非常遗憾,绝大多数人对沟通能力的重视远远不够 —— 他们也不是不重视,就是重视的程度实际上太差了。别说双向沟通了,即便是单向沟通,向别人问个问题这么 “简单” 的事,其实也需要 “学” 与 “练” —— 之前提到过的文章,事实上一定有读者并没有去认真阅读:
…… 作为一个有素养的自学者,有一篇文章必须精读:
这里还有 John Gordon(王渊源)同学录制的英文朗读版:
https://github.com/selfteaching/How-To-Ask-Questions-The-Smart-Way
经过多次尝试就知道了,连 “描述清楚自己的问题” 都不是一件很容易做得足够清楚、足够好的事呢。
对沟通能力进行 “刻意练习” 的最佳方式是什么呢?其实还是你已经知道的:
教是最好的学习方法
讲课、写教程,甚至写书 —— 这是最高效的提升沟通能力的刻意练习手段。
人们常说,“杀鸡焉用宰牛刀”…… 在我看来,既然如此,备上一把宰牛刀挺好的,平时宰牛就用宰牛刀,备不住哪天需要杀鸡的时候,并不需要非得换把刀才行,依然可以用那把宰牛刀……
讲演能力、写作能力,其实同样也是手艺而已,但它们也确实是很必要的手艺。尤其是,具备这两项手艺的人,在现在这样的社会里收入一定不差,不信你就观察一下身边的世界、你的眼界可以触达的人群。
这两个手艺若比作宰牛刀的话,则日常生活里与单人沟通,只不过是杀鸡而已 —— 哈,这个类比真是不能说给沟通对象听,实在有太大的误会可能性。然而,说正经的,其实这也是为什么 “教师” 这个行业的人有不少能够跑出来成为优秀创业者、优秀投资人的原因之一。
当然,绝大多数连一门手艺都没有弄明白的初学者,阅读以下内容时,会觉得 “与当前的自己没关系”…… 不过,请注意,这绝对是 “刚需幻觉”,千万不要被它误导。
已经说了无数遍了:绝大多数手艺都是这样的:
原理很简单,精湛与否取决于重复的次数。
哼,这句话不就是卖油翁说的吗?“无他,唯手熟尔” —— 是哦,卖油翁如是说。
以下,让我从入门开始讲起,而后步入进阶,最后到达高级……
入门
内容第一
无论是平日里讲话、还是台上讲课,抑或是写篇文章、写本书,永远都是内容第一,至于形式,并非不重要,但绝对不能喧宾夺主。
通常,我们用 “干货” 来描述内容的重要性。第一步就是准备干货,至于修辞啊、笑点啊、酷炫幻灯片啊等等等等,都必须是次要的,否则就是喧宾夺主。干货不够好,其它的做得越多、越好,最终越是容易露怯 —— 这很可怕。
所以,在你还没有确定自己值得讲、别人值得听的内容的情况下,就去学习如何制作幻灯片,在我看来完全是浪费时间。
使用工具的技巧之一,就是用最朴素的方法使用最好的工具,这样成本最低效果最好。所以,我在讲课、讲演的时候,通常就只用最简单的模版,空白、单色背景那种,而后一页里只写一句话 —— 就是接下来三五分钟里我要讲的重点(甚至干脆只是标题)…… 这样的幻灯片,我只需要几分钟就能做完。而后,我的所有时间精力都放在精心准备内容上去了。高效、低成本。
做事不分轻重,这不对。
内容质量
内容第一,就决定了另外一个事实:
不要讲或写你并不擅长的事。
换句话说,不要分享你做得不够好、做得不够精的手艺。讲课也好、写书也罢,都是分享。分享的意思是说,你有别人想要的东西 —— 别人想要的,就是他们学不好、做不好的东西…… 若是你自己手艺不强,手艺不精,其实就没什么可分享的,就算你想 “分享”,别人也不要。
你值得讲,别人值得听的,一定是你做得比别人更好的东西,就这么简单。
所以,在自己磨练手艺的时候,可以同时磨练沟通能力;然而,一旦需要讲,需要写,那么就说明,你自己确信自己做得比别人更好、比别人更精,所以,你值得讲,所以,人家值得听。
一旦你确定自己有值得讲、人家值得听的东西,那么,内容质量的第一要素已经完成了,接下来要注意哪些呢?只需要关注最重要的三个方面就可以了:
- 重点突出
- 例证生动
- 消除歧义
首先,“重点突出”,是最简单朴素、成本最低的 “优秀结构”。
既然是沟通,就要了解对方。在绝大多数情况下,对方想要的才是重点。
可问题在于,我们平日里面对单个人的时候都觉得 “了解对方很困难”,我们又如何判断 “一个群体” 呢?与很多人想象得相反,判断群体远比判断个体容易得多…… 因为你可以用粗暴分类,比如,你把听众或读者划分为 “小白” 和 “专家”,那你就知道了,你面对的群体中,更可能 “大部分是小白,小部分是专家”。于是,你就可以思考,“小白们最想知道的是什么?”,“专家们最重视的是什么?”,于是,你就可以在脑子里对所谓的 “重点” 有应对策略。
再比如说,你可以 “粗暴” 地把群体分为友善者和刺儿头两种。有经验的老师,都会专门准备 “针对刺儿头” 的内容,因为,人群中永远存在刺儿头 —— 至少一个,所以,在现场,必须要有应对他们的策略。比如,当一个刺儿头说了一句蛮不讲理却引发哄堂大笑的话,你怎么办?每个人的策略不同,但你必须找到属于你的最佳策略。
进而,在找到重点之后,紧接着必须要做到的一步就是 “例证生动”。寻找好例子,是需要很多时间精力的事情 —— 从来就没有任何 “信手拈来” 的生动例子。信手拈来,是读者或者听众的感觉而已,对你来说,肯定是举重若轻的 —— 你明明是在举重,却被认为 “如若举轻”。在第一部分,讲文件的那一章里,我举了个 “我自己费尽心机找好例子” 的例子,相信你读过之后,一定有所感触。
最后一步,就是在前两步都完成之后,反复确认一件事情,消除一切歧义。这是真功夫,因为这东西很难把自己关在屋子里自顾自练成。并且,每个人有自己的 “容易引发误解” 的特殊属性,大家各不相同 —— 于是,只能靠自己探索。
无论如何都不能骂听众读者傻逼,他们的所有看起来傻逼的反应,都是你所说、你所写引发的 —— 这是百分之百清楚无误的事实。当年我写博客的时候,决不删除任何留言。其中最大的一个理由就是,无论那留言显得多么荒谬,甚至干脆是谩骂,都值得我认真思考:
我到底说什么了?居然引来这种反应?!
看多了,思考多了,你就有你自己的策略了。
内容组织
只有一个重点的时候,其实并不需要组织;但若是有一个以上的重点,那么这些重点之间会产生逻辑关系:
- 并列
- 递进
- 转折
这是上中学的时候,所有人在语文课上都学习并掌握了的知识 —— 现在终于需要 “活学活用” 了。
在讲演、讲课、写教程、写非小说类书籍的时候,最有效的组织方式竟然是最简单的,并且只有一个:
层层递进
你有两个重点需要分享,那么把更重要的那个重点放在后面;你有三个重点要分享,那么就把最重要的放在最后面…… 无论你有多少个重点,都按这种方式排列,准没错!
并且,另外一个建议是:
3是重点数量的极限
如果你必须有 11 个重点,那怎么办?那就把它们分到最多 3 个分组中,比如,像当前文章这样,“入门”、“进阶”、“高级”……
另外一个策略,是与 “递进” 的逻辑关系组合使用的 —— 你要区分针对你所谓的重点,对方的已知状态。大家都知道的,何必当作重点?于是,未知程度最高的,放在未知程度不那么高的重点后面。
这都是听起来无比简单,甚至好像 “无需讲述” 的 “重点”,但若是你多观察一下周遭的世界,你就明白了,很多人可能并不是不知道这些方法,但不知道为什么,他们就是不去应用这么简单有效的方法,也是怪得很!
进阶
当入门的手段都已经熟练了,就可以做很多所谓 “锦上添花” 的事情。锦上添花据说有很多种手段,比如,制造笑点啊,使用炫酷的幻灯片啊等等…… 但我只想给你讲一个学会了就够用,却也是最简单、最直接,然而又最有效的手段:
输送价值观
事实上,你可以把当前这本 “书” 当作一个巨大且又生动的例子:
你把李笑来想象成一位在某个学校里为学生讲编程课的老师。那么,你就可以把当前这本书当作 “李笑来的讲义”…… 也许我和学生手里都拿着另外一本更著名的计算机专家所著的编程入门书籍,然而,我的讲义,就是按照我的顺序、我的内容编排来讲述的。
事实上我在写这本书的时候,从某个层面上来看,真的写的就是 “Python 官方文档” 以及 “Python 官方教程” 的辅助讲义,写作目标如此,写作方式亦如是。
那我做了什么最重要的事情呢?
我向我的群体输送了我觉得更有意义的价值观:
自学是门手艺……
当年我在学校里讲英语课的时候,除了讲英语本身之外,我输送的价值观是:
能管理好自己的时间的人,学英语学起来更容易……
后来,这一部分单独被提取出来,在我离开那所学校之后,写成了长销书,《把时间当作朋友》—— 你看,是一样的道理。
而所谓的价值观,定义很简单:
你的价值观,就是你认为什么比什么更重要。
价值观可大可小。大到集体利益与个人利益之间的比较,小到自学中 “全面” 压倒一切…… 然而,这世界总有独立于任何人存在的 “客观的价值比较”,只不过,每个人的 “价值观” 是自己的 “观点”。而我们每个人都希望自己的观点尽量摆脱自己的主观,尽量靠近那个 “客观的价值比较”…… 而一旦我们确定自己比原来的自己,甚至相对于其他人更进一步的时候,就很可能值得认真分享。
这个方法着实简单,然而却非常有效。这有点像什么呢?这有点像人家弹个吉他是 “蹦单音”,可你弹的却是 “曲调与和弦” 相辅相成的音乐…… 给你看一个 Youtube 上的《一生所爱》—— 这首曲子是我最喜欢的指弹版本 —— 这种弹法,不仅有旋律,还有和弦,并且还有打击乐器效果 “伴奏”:
1 | from IPython.display import IFrame |
<iframe
width="800"
height="450"
src="https://www.youtube.com/embed/AjWTop5O5jo?"
frameborder="0"
allowfullscreen
></iframe>
最初的时候,有个看起来很难以跨越的障碍:
感觉总是需要为自己塑造权威感 —— 否则就害怕没人听、没人看、没人信……
这是很多人掉进去的坑。刚开始的时候,自己就不是权威啊!无论怎么装神弄鬼,事实上就不是么!
很多人没想明白,因为害怕没人听、害怕没人看、害怕没人信,所以就开始各种作弊,包括各种装神弄鬼,各种欺世盗名…… 这么做,暂时管用,长期来看,肯定是吃亏的。
因为作弊其实并不难,装神弄鬼其实并不难,欺世盗名其实并不难 —— 真正难的是长期作弊…… 长期欺骗有多难呢?难到根本不可能的地步。尤其是在寿命越来越久的今天。《庄子》里说,“寿则多辱”,今天有了新解释 —— 大家都寿命很长,所以别骗人,因为早晚会露馅……
花那么长时间作弊什么的,还不如花那么长时间磨练手艺,你想想看是不是这个道理?
给你看一段视频,加州伯克利大学的 Brian Harvey 在课堂上告诉学生,“为什么不要作弊” 的真正原因:
1 | from IPython.display import IFrame |
<iframe
width="800"
height="450"
src="https://www.youtube.com/embed/hMloyp6NI4E?"
frameborder="0"
allowfullscreen
></iframe>
于是,千万别扭曲了自己,是什么样就是什么样,该怎么做就怎么做。而另外一件事是确定的:
分享多了,就自然进步了……
在求知的领域里,分享得越多,进步越快,且社交有效性提高得更多。
高级
无论什么手艺,大多数人都可以入门、少数人可以进阶…… 再往后,就通常被认为是个人 “造化” 了。
可这所谓的 “造化” 究竟指的是什么呢?
我觉得通过这本书,我可以向绝大多数普通人解释这个 “玄学词汇” 了……
这里所谓的 “造化”,指的应该是一个人的 “融会贯通的能力” —— 有 “造化” 的人,不过是把大量其他领域里的技能、技巧、甚至手艺学来而后应用到自己的手艺之中……
就这么简单。
有个特别好玩的例子。
现在大家已经熟悉了的吉他演奏中的 “指弹”(Percussive Guitar),可这种玩法在没有 Youtube 的时代里并不多见 —— 在我长大的年代里,甚至 “前所未闻”。不知道是谁,把打击乐器的手法融合到吉他演奏手法中去了,于是,在 Youtube 这样的视频工具出现之后,人们的 “见识” 成本降低了(过去也许要 “去西天取经才行”),很快就有人模仿,很快就有人更为擅长……
1 | from IPython.display import IFrame |
<iframe
width="800"
height="450"
src="https://www.youtube.com/embed/nY7GnAq6Znw?"
frameborder="0"
allowfullscreen
></iframe>
有这种能力的人,普遍有两个特征:
- 他们自学很多看起来不相干的手艺
- 他们对自己的手艺充满尊重与热爱
我也只能猜个大概。这其中的第二个特征,很可能是第一个特征的根源,因为他们对自己的手艺充满了尊重与热爱,所以,他们追求全面,他们刻意练习,他们还刻意思考…… 由此引发了对一切可能与自己的手艺相关的东西都感兴趣 —— 虽然在外界看来那两样东西可能全无联系。于是,他们利用已经在自己的手艺中练就的自学能力,不断自学新的东西,不断 “发现” 所谓的 “新大陆”,不断用他们的所见所闻回过来锤炼或更新自己的手艺……
所以,弹钢琴或者弹吉他的也去学了打击乐器;讲课的人会去听相声专场,学习相声演员是如何抖包袱的;写书的人可能会像我琢磨 “取名” 的艺术 —— 甚至不惜去研究一下自己并不屑于相信的易经八卦;学会计的去研究了物理或者经济学;学编程的也去学了设计,学设计的也去学了编程;做前端的去学了后端,做后端的也学会了前端;做统计的学会了数据可视化…… 搞来搞去,计算机行业里有个著名的词汇诞生:全栈工程师。
其实,所有精湛的手艺人,都是全栈,不信你就仔细观察一下。
于是,所有在入门、进阶之后走得更远的手艺人,都明白且认同这个道理:
学无止境
于是,最后一个重要技巧,不仅仅是 “不断磨练当前的手艺”,还有就是不断向所有的手艺人学习。
再进一步,技巧没用了…… 想再进一步,靠的是另外一个层次的东西 —— 那就是尊重与热爱。
这么多年来,在互联网上我最喜爱的老师,是麻省理工大学的 Walter Lewin 教授。
1 | from IPython.display import IFrame |
<iframe
width="800"
height="450"
src="https://www.youtube.com/embed/sJG-rXBbmCc?"
frameborder="0"
allowfullscreen
></iframe>
十多年前,MIT 出了一套 Open Course,在线的免费课程。授课老师绝大多数都是本校的著名教授 —— 在那么多课程里,我一下子就爱上了这位教授。建议你有时间把他的所有课程看完,虽然你可能觉得物理这东西你并不感兴趣 —— 可事实上,看完你就知道了,你只不过是运气不好,你从来没遇到过这么可爱牛逼的教授而已…… 在他身上,你可以学到无数,甚至是 “不可言说” 的技巧、秘密和手艺。
关键在于,你一定会非常生动地、深刻地体会到他对物理、他对授课的尊重和热爱。看过之后,你一定会跟我有一样的慨叹:“是哦,Love is the power.”
没有什么比 “热爱” 和 “尊重” 更为高级的了。就这样。
自学者的终点
…… 磨练自学手艺的你,早晚会遇到这种情况:
必须学会一个没人教、没人带,甚至没有书可参考的技能。
这也许是我自己能够想象到的自学者所能经历的最高境界吧,因为那么多年过去之后的我也只不过走到这个地方而已…… 许多年过去,我通过自学习得的没有人教、没有人带、甚至没有书可参考的技能,很拿得出手的只有两个而已:
- 制作长销书
- 区块链投资
先说说区块链投资。
2011 年,我开始投资比特币的时候,不像现在。现在你能在 Amazon 上找到一大堆书,给你讲区块链技术、区块链投资…… 2011 年的时候,互联网这本大书上,连篇像样的文章都几乎没有。
在这样的领域里成为专家,其实比外界想象得容易 —— 当然,无论什么,外界总是觉得很难。为什么比外界想象得更容易呢?因为大家都不懂,仅此而已。
所以,剩下的事情很简单:
谁能持续研究谁就可能更先成为专家。
到最后,还是一样的,决定因素在于有效时间投入,再次仅此而已。
了解我的人都知道,在知识技能的分享方面,我从来都没有 “藏着掖着” 的习惯。我说 “仅此而已” 的时候,那就是 “仅此而已”,没有任何其它保留。
说研读比特币白皮书,就真的研读,反复研读,每年都要重复若干遍 —— 有人问了,有那个必要吗?是哦,对我有没有那个必要,我自己说了算。并且,就算真有,告诉别人有什么用?对吧?
这里是《比特币白皮书》我翻译的版本。
说投资就真的投资,不是 “买两个试试”、“买几个玩玩” —— 我的做法是重仓。持仓之后继续研究,和两袖清风地读书研读肯定不一样。有一个与我极端相反的例子。此人大名鼎鼎,是《精通比特币》(Mastering Bitcoin)的作者,Andreas M. Antonopoulos,与我同岁,也是 1972 年生人。
他也是国外公认的比特币专家,但他不是投资人 —— 他几乎没有比特币。2017 年牛市的时候,人们听说大神 Andreas M. Antonopoulos 竟然几乎没有比特币,大为惊讶,向他捐款总计 102 个比特币左右 —— 千万不要误会我,我没有任何鄙视他的意思。这不是我说说而已,我是用行动支持他的人。他的书,《精通比特币》的中文版,还是我组织人翻译的。
我只是说,我和他不一样的地方在于,在某些方面我比他更实在,这也是事实。我相信我在实际投资后,对比特币也好区块链也罢,理解力会更深一些,因为驱动力不一样么,多简单的道理。
然而,仅仅 “谁能持续研究谁就更可能先成为专家” 这一条,其实并不够完成 “学会一个没人教、没人带,甚至没有书可参考的技能”。
这么多年来,我能够 “学会一些没人教、没人带,甚至没有书可参考的技能”(比如赚钱这事就是如此),更多的时候仰仗的是一个我已经告诉过你的 “秘密”…… 也许你想不起来了,但我一说你就能 “发现” 其实你真的已经听我说过:
刻意思考:这东西我还能用在哪儿呢?
并且,我还讲过在自学编程的过程中,见识到的 MoSCoW Method 给我在写书方式上的影响。
我写书就是这样的。在准备的过程中 —— 这个过程比绝大多数人想象得长很多 —— 我会罗列所有我能想到的相关话题…… 等我觉得已经再也没有什么可补充的时候,再为这些话题写上几句话构成的大纲…… 这时候就会发现很多话题其实应该是同一个话题。如此这般,一次扩张,一次收缩之后,就会进行下一步,应用 MoSCoW 原则,给这些话题打上标签 —— 在这过程中,总是发现很多之前感觉必要的话题,其实可以打上
Won't have的标签,于是,把它们剔除,然后从Must have开始写起,直到Should have,至于Could have看时间是否允许,看情况,比如,看有没有最后期限限制……在写书这事上,我总是给人感觉很快,事实上也是,因为有方法论 —— 但显然,那方法论不是从某一本 “如何写书” 的书里获得的,而是从另外一个看起来完全不相关的领域里习得后琢磨到的……
你看,把另外一个领域里的知识拿过来用,是在一个 “没人教、也没人带,甚至没有书籍可供参考” 的领域中,最基本的生存技巧。
再进一步,当我们在最开始的时候说,“尽量只靠阅读习得一项新技能” 的时候,有一个重点现在终于在之前的很多解释与讲解之后能说清楚了:
我们并不是不要老师这个角色了,准确地讲,我们只不过是不再需要 “传统意义上的老师” 了而已。
首先,我们把自己当作老师 —— 英文中,Self-teaching 这个词特别好,它描述得太准确了。很多的时候,想在身边找到好老师是很难的,甚至是不可能的。在这种情况下,我们没有别的选择,我们只能把自己当作老师去教自己。
其次,就算我们 100% 只依靠阅读,那内容不还是别人写的吗?写那内容的人,实际上就是老师。没错,书本,是历史上最早的远程教育形式,即便到今天也依然是最重要最有效的远程教学形式。阅读的好处在于,对老师的要求中没有地理位置的限制,若是能自由阅读英文,那就连国界限制都没有。“书中自有颜如玉” 这句话,显然是并不好色的人说的,因为他更爱书…… 这句话的意思其实是说:
各路牛人都在书里……
反正,写书的人群中,牛人比例相对较高,这是事实 —— 古今中外都一样。
进而,更为重要的是,一旦你把整个互联网当作一本大 “书”,把 Google 当作入口,实际发生的效果是:
你把 “老师” 这个角色去中心化了……
一方面 “老师” 这个角色的负担降低了,他们不用管你是谁,也不用管你怎么样了,他们该干嘛就干嘛;而另外一方面则对你更重要 —— 你学不同的东西,就可以找不同的老师;即便是相同的东西,你也可以找很多老师;对于任何一个老师,你都可以 “弱水三千只取一瓢”,也就是说,只挑他最厉害的部分去学…… 不就是多买几本书吗?不就是多搜索几次、多读一些文档吗?
最后,你竟然还有最厉害的一个小招数:
无论学会什么,都要进一步刻意思考:这东西我还能用在哪儿呢?
于是,你 “一下子” 就升级了 —— 用这样的方式,相对于别人,你最可能 “学会几乎任何一个没人教、没人带,甚至没有书可参考的技能”……
你看看自己的路径罢:从 “不得不把自己当作老师去教自己” 开始 —— 虽然起步是不得不,但这个 “不得不”,恰好是后来你变得更为强大的原因和起点…… 这就解释了为什么历史上有很多牛人的很多成就其实都是这样 “被迫” 获得的。
于是,我们终于可以好好总结一下了:
- 你一定要想办法启动自学,否则你没有未来;
- 你把自学当作一门手艺,长期反复磨练它;
- 你懂得学、练、用、造各个阶段之间的不同,以及针对每个阶段的对应策略;
- 面对 “过早引用” 过多的世界,你有你的应对方式;
- 你会 “囫囵吞枣”,你会 “重复重复再重复”,你深刻理解 “读书百遍其义自见”;
- 以后你最擅长的技能之一就是拆解拆解再拆解;
- 你用你的拆解手艺把所有遇到的难点都拆解成能搞定的小任务;
- 自学任何一门手艺之前你都不会去问 “有什么用”,而是清楚地知道,无论是什么只要学会了就只能也必然天天去用;
- 你没有刚需幻觉,你也没有时间幻觉,你更没有困难幻觉,反正你就是相对更清醒;
- 不管你新学什么手艺,你都知道只要假以时日你就肯定能做好,因为所有的手艺精湛,靠的只不过是充足的预算;
- 你知道如何不浪费生命,因为只要不是在刻意练习、不是在刻意思考,那就是在 “混时间”;
- 你总是在琢磨你能做个什么新作品;
- 你刻意地使用你的作品作为有效社交工具,也用作品去过滤无效社交;
- 你乐于分享,乐于阅读也更乐于写作 —— 因为这世界怎么帮助你的,你就想着要怎样回报;
- 你把全面和完整当作最高衡量标准,也用这个标准去克制、应对自己的注意力漂移;
- 你会不断自学新的手艺,因为你越来越理解单一技能的脆弱,越来越理解多项技能的综合威力;
- 你越来越依赖互联网,它是你最喜欢的 “书”,而 Google 是你最好的朋友 —— 他总是能帮你找到更好的老师;
- 偶尔,你会学会没人教、没人带、甚至没书可参考的手艺,别人都说你 “悟性” 高,可你自己清楚地知道那其实是怎么回事;
- 你越来越明白,其实没什么 “秘密”,越简单、越朴素的道理越值得重视;
- 你发现你用来思考的时间越来越多 —— 准确地讲,是 “琢磨”…… 只不过是因为你真会琢磨了 —— 你很清楚你应该花时间琢磨的是什么。
没有人教过我怎么写一本长销书(而不仅仅是畅销书),这显然是我通过自学习得的能力 —— 我也只能把自己当作老师教自己,这是不得已。然而,不得不的选择同样常常能给我带来好运…… 甚至,它也不是我通过阅读哪本书习得的能力 —— 因为这方面还真的没什么靠谱的书籍。然而,我竟然学会了 —— 靠什么?靠的就是上面说的那点事而已。
“秘密” 是什么?说出来后,你听起来肯定是感觉 “太简单了” 乃至于 “有点不像真的”…… 每次,我都很认真的问自己以下几个问题:
- 我要写的内容,的确是正确的吗?
- 我要写的内容,确实会对读者有用吗?
- 有什么内容是必须有的、应该有的?
- 我写的这个内容,十年后人们再看,还会觉得跟新的一样有用嘛?
- 我的书名,就那么放在那里,会直接让买家产生不由自主购买的吸引力吗?
一旦这几个问题我有了清楚的答案,我就知道,我有能力制作一本新的长销书了 —— 真的没有什么别的 “秘密”。
在《通往财富自由之路》中,我分享过以下内容:
我认为一个人的自学能力(当时还在用 “学习能力” 这个词)分为三个层次:
- 学会有人手把手教授的技能
- 学会书本上所教授的技能
- 学会没有人能教授的技能
这一次,我无非是把后两个层面用一个特大号的实例掰开了揉碎了讲清楚而已。
到最后,没什么不能自学的,反正都只不过是手艺 —— 只不过,我们每个人都受限于自己的时间精力而已。所以,若是你正在读高一,正在读大一,那就好好珍惜自己有机会可以随意设置充裕预算的时光罢。若是你已为人父母,那就想办法用自己的行动影响下一代罢。然而,其实更为重要的是,无论什么时候,都要这么想:
若是还有很长的未来,现在真不算晚……
自学不过是一门手艺,而且还是谁都能掌握的。不要 “试试” 而已,而是 “直接开干” —— 这样才好。
最后还有个需要补充的是:很多人崇尚 “刻苦”,并且刻意强调其中的 “苦” —— 古训中所谓的 “吃得苦中苦,方为人上人” —— 这一点我并不认同,而且还是深刻地不认同。
我的观察是,所谓的 “苦”,是那些完全不会自学的人对自学者的所作所为的错误理解。
自学一点都不苦,道理也很简单:
因为自学者是自发去学的,原动力在于自己。而不像其他人,是被动地学,原动力并非在于自己。
由于原动力在于自己,遇到困难时,当然同样苦恼;可不一样的是,有持续的原动力去克服那些困难,于是,总是在不断克服困难之后获得更大的愉悦、更大的满足感。
所以,“刻”,我们很认同,刻意地练习、刻意地思考,刻意地保持好奇心,刻意地去学习一些看起来与当前所掌握的手艺完全不相干的知识…… 至于 “苦” 么,那是别人的误解,我们自己开心着呢 —— 无所不在、无处诉说的幸福。
人生苦长,无需惊慌。
祝你好运!
李笑来
初稿完成于 2019 年 2 月 27 日
the-craft-of-selfteaching
One has no future if one couldn’t teach themself[1].
自学是门手艺
没有自学能力的人没有未来
作者:李笑来
特别感谢霍炬(@virushuo)、洪强宁(@hongqn) 两位良师诤友在此书写作过程中给予我的巨大帮助!
1 | # pseudo-code of selfteaching in Python |
有兴趣帮忙的朋友,请先行阅读 如何使用 Pull Request 为这本书校对。
目录
- 01.preface(前言)
- 02.proof-of-work(如何证明你真的读过这本书?)
- Part.1.A.better.teachyourself(为什么一定要掌握自学能力?)
- Part.1.B.why.start.from.learning.coding(为什么把编程当作自学的入口?)
- Part.1.C.must.learn.sth.only.by.reading(只靠阅读习得新技能)
- Part.1.D.preparation.for.reading(开始阅读前的一些准备)
- Part.1.E.1.entrance(入口)
- Part.1.E.2.values-and-their-operators(值及其相应的运算)
- Part.1.E.3.controlflow(流程控制)
- Part.1.E.4.functions(函数)
- Part.1.E.5.strings(字符串)
- Part.1.E.6.containers(数据容器)
- Part.1.E.7.files(文件)
- Part.1.F.deal-with-forward-references(如何从容应对含有过多 “过早引用” 的知识?)
- Part.1.G.The-Python-Tutorial-local(官方教程:The Python Tutorial)
- Part.2.A.clumsy-and-patience(笨拙与耐心)
- Part.2.B.deliberate-practicing(刻意练习)
- Part.2.C.why-start-from-writing-functions(为什么从函数开始?)
- Part.2.D.1-args(关于参数(上))
- Part.2.D.2-aargs(关于参数(下))
- Part.2.D.3-lambda(化名与匿名)
- Part.2.D.4-recursion(递归函数)
- Part.2.D.5-docstrings(函数的文档)
- Part.2.D.6-modules(保存到文件的函数)
- Part.2.D.7-tdd(测试驱动的开发)
- Part.2.D.8-main(可执行的 Python 文件)
- Part.2.E.deliberate-thinking(刻意思考)
- Part.3.A.conquering-difficulties(战胜难点)
- Part.3.B.1.classes-1(类 —— 面向对象编程)
- Part.3.B.2.classes-2(类 —— Python 的实现)
- Part.3.B.3.decorator-iterator-generator(函数工具)
- Part.3.B.4.regex(正则表达式)
- Part.3.B.5.bnf-ebnf-pebnf(BNF 以及 EBNF)
- Part.3.C.breaking-good-and-bad(拆解)
- Part.3.D.indispensable-illusion(刚需幻觉)
- Part.3.E.to-be-thorough(全面 —— 自学的境界)
- Part.3.F.social-selfteaching(自学者的社交)
- Part.3.G.the-golden-age-and-google(这是自学者的黄金时代)
- Part.3.H.prevent-focus-drifting(避免注意力漂移)
- Q.good-communiation(如何成为优秀沟通者)
- R.finale(自学者的终点)
- S.whats-next(下一步干什么?)
- T-appendix.editor.vscode(Visual Studio Code 的安装与配置)
- T-appendix.git-introduction(Git 简介)
- T-appendix.jupyter-installation-and-setup(Jupyterlab 的安装与配置)
- T-appendix.symbols(这些符号都代表什么?)
关于 文件转换为 ```.md``` 文件的备注: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
```bash
# 需提前安装 nbconvert 插件,Terminal 下执行:
$ jupyter nbconvert --to markdown *.ipynb
而后将所有 `.md` 文件移到 `markdown/` 目录之下 —— 除 `README.md` 文件之外
`README.md` 文件复制一份到 `markdown/` 目录之下,而后编辑为当前文件
# 需使用 VSCode 批量 Find and Replace:
将所有 (https://raw.githubusercontent.com/selfteaching/the-craft-of-selfteaching/master//images/ 替换为 (https://raw.githubusercontent.com/selfteaching/the-craft-of-selfteaching/master//images/
将所有 (Part.1.A.better.teachyourself_files/ 替换为 (https://raw.githubusercontent.com/selfteaching/the-craft-of-selfteaching/master//images/
将所有 (Part.1.E.6.containers_files/ 替换为 (https://raw.githubusercontent.com/selfteaching/the-craft-of-selfteaching/master//images/
将所有 ```\n\n 替换为 ```\n
将所有 \n\n``` 替换为 \n
1 |
|
将所有 .ipynb) 替换为 .md)
Part.1.E.3.controlflow.md 文件中有过长的 output 需要编辑Part.1.E.7.files.md 文件中有过长的 output 需要编辑1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
-----
推荐读者在自己的浏览器上安装 [Stylus](https://github.com/openstyles/stylus) 这类终端 CSS 定制插件,Chrome/Firefox/Opera 都支持 Stylus 插件。以便拥有更好的阅读体验。以下 gif 图片展示的是使用自定义 css 前后的效果:
> 
我用的 Stylus 定制 CSS(针对 github.com)是这样的:
```css
.markdown-body {font-family: "PingFang SC";}
strong {color:#6392BF;}
em {color: #A9312A; font-style: normal !important;}
table {font-size: 95% !important;}
.CodeMirror, pre {font-size: 90%;}
pre {
padding: 10px 25px;
background-color: #fafafa;
border-left: 4px solid #dadada;
border-radius: 10px;
}
pre code {
background-color: #fafafa;
}
h1 code,
h2 code,
h3 code,
h4 code,
p code,
li code,
blockquote p code,
blockquote li code,
td code {
background-color: #f6f6f6;
font-size: 90%;
color:#2e2e2e;
padding: 4px 4px;
margin: 0 8px;
box-shadow: 0px 1px 2px 0px rgba(0,0,0,0.2);
border-radius: 4px;
}
}
我写的内容里,为了重点突出,特别定制了 strong 和 em 两个元素的显示,让它们以不同的颜色展示;又因为中文并不适合斜体展示,所以,把 em 的 font-style 设定为 normal……
本书的版权协议为 CC-BY-NC-ND license。

脚注
[1]:‘Themselves’ or ‘themself’?– Oxford Dictionary
下一步干什么?
理论上,下一步你的选择很多。自学是门手艺,你可以用它去学任何你想要掌握的其它手艺。如果,你有意在编程这个领域继续深入,那么,以下就是一些不错的线索。
当然,最先应当做的是,去检查一下自己的 “突击” 的结果,去 Pythonbasics.org 做做练习:
除了我在这里介绍的之外,请移步 The Hitchhiker’s Guide to Python,它更为全面:
Python 必读书籍
无论学什么,一本书肯定不够,以下是学习 Python 的基本必读书籍:
- The Python Tutorial
- The Hitchhiker’s Guide to Python!
- Think Python: How to think like a computer scientist
- Automate the Boring Stuff with Python
- Effective Python
- Python Cookbook
- Fluent Python
- Problem Solving with Algorithms and Data Structures using Python
- Mastering Object-oriented Python - Transform Your Approach to Python Programming
更多 Python 书籍:
千万别觉得多,只要真的全面掌握,后面再学别的,速度上都会因此快出很多很多……
Python Cheatsheet
你已经知道了,这种东西,肯定是自己整理的才对自己真的很有用…… 不过,你也可以把别人整理的东西当作 “用来检查自己是否有所遗漏” 的工具。
网上有无数 Python Cheatsheets,以下是 3 个我个人认为相当不错的:
Awesome Python
Github 上的 “居民” 现在已经养成了一个惯例,无论什么好东西,他们都会为其制作一个 “Awesome …” 的页面,在里面齐心协力搜集相关资源。比如,你想学 Golang,那你去 Google 搜索 Awesome Go,一定会给你指向到一个 Github 上的 “Awesome Go” 的页面……
以下是 Awesome Python 的链接:
CS 专业的人都在学什么?
如果你真有兴趣把这门手艺学精,不妨看看 Computer Science 专业的人都在学什么……
下面这个链接值得认真阅读:
全栈工程师路径图
既然学了,就肯定不止 Python —— 在扎实的基础之上,学得越多学得越快。以下是一个 “全栈工程师路径图”,作者是位迪拜的帅哥 Kamran Ahmed:
https://github.com/kamranahmedse/developer-roadmap
Below you find a set of charts demonstrating the paths that you can take and the technologies that you would want to adopt in order to become a frontend, backend or a devops. I made these charts for an old professor of mine who wanted something to share with his college students to give them a perspective; sharing them here to help the community.
Check out my blog and say “hi” on Twitter.
Disclaimer
The purpose of these roadmaps is to give you an idea about the landscape and to guide you if you are confused about what to learn next and not to encourage you to pick what is hip and trendy. You should grow some understanding of why one tool would better suited for some cases than the other and remember hip and trendy never means best suited for the job
Introduction
Frontend Roadmap

Back-end Roadmap

DevOps Roadmap
路漫漫其修远兮……
但多有意思啊?这完全就是一场闯关游戏。
Visual Studio Code 的安装与配置
官方文档请查询:
允许命令行启动 VS Code
使用快捷键 ⇧⌘p 呼出 Command Palette,在其中输入 shell command,而后选中 Install 'code' command in PATH。此后,就可以在 Terminal 命令行中使用 code 命令了。(Windows 系统安装 VS Code 时会自动配置好,并不需要此步骤)
选择 Python 解析器版本
使用快捷键 ⇧⌘p 呼出 Command Palette,在其中输入 select interpreter,而后选中 Python: Select Interpreter。
而后,在系统中已安装的若干个版本中选择你需要的那一个。MacOS 系统自带一个 Python 2.7,而我们安装的 Anaconda 为系统另外安装了一个 Python 3.7。
安装扩展
使用快捷键 ⇧⌘x 呼出扩展面板。安装 anaconda 扩展,它会连带装上 python 扩展:
另外,为了输入方便,有两个扩展可选安装:
- Tabout 有它之后,可以使用 TAB 键跳出光标后的括号、引号等等;
- Sublime Text Keymap and Settings Importer 有它之后,可以在 VS Code 中使用 SublimeText 的快捷键,最重要的当属多光标编辑
⇧⌘l……
自动补全
专业编辑器最重要的功能之一,就是能够在你输入的时候它帮你做到 “自动补全”,通常使用的快捷键是 TAB 键 ⇥。
TAB 键 ⇥ 触发的自动补全有两种:
- 当前文件中已有的字符串。比如,之前你输入过
sum_of_word;那么,之后,你就可以输入su或者干脆sow而后按 TAB 键⇥,“自动补全” 功能会帮你完成输入sum_of_word- 已有的 Snippets。比如,当你需要输入
if ...: ...的时候,实际上当你输入if或者甚至i之后,你就可以用 TAB 键⇥,“自动补全” 功能会为你 “自动完成” 语句块的输入。
字符串自动补全,使用的是所谓的 Fuzzy Match。输入 sum_of_word 中所包含的任意字符的任意组合(按顺序),它都会尽量去匹配;所以,su 和 sow 都可以匹配 sum_of_word,再比如,rst 可以匹配 result。
在 Snippet 自动补全的过程中,常常有若干个 “TAB Stop”,即,有若干个位置可以使用 TAB 键 ⇥(或者,Shift + ⇥)来回切换;这时,第一种字符串自动补全的功能就失效了,如果需要使用字符串自动补全,那么需要按快捷键 ESC ⎋ 退出 Snippet 自动补全模式。
以下的 gif 文件演示的是以下代码的输入过程:
1 | def sum_of_word(word): |
因为有这样的功能,所以你在输入程序的时候其实是非常从容的,可以很慢输入,边思考边输入…… 可实际上,完成速度却很快。
另外,SublimeText 的多光标输入是很多程序员爱不释手的功能,于是,各种编辑器里都有第三方写的 SublimeText Keymap 插件,连 Jupyterlab 都有:
Git 简介
— You should’ve learned Git yesterday.

内容目标
再一次,这一篇内容的目标,依然不是 “教程”,而是 “教程” 的 “图例” —— 如果我们把真正的教程比喻成 “地图” 的话。最全面的 Git 教程在网上,Pro Git,是免费的 —— 把它反复阅读若干遍,理解完整:
并且还有各种语言的翻译版本 —— 也包括中文。
为什么你必须学会使用 Git?
Git 是一个分布式版本控制软件 —— 听起来也许跟你没关系,但无论是谁,都会因为能够使用 Git 而节约时间、提高效率。进而,如果你居然没有一个活跃的 Github 账户,那么你正在错过人类史上前所未有的共同协作时代 —— 半点都没有夸张。同样提供 Git 工具云服务的还有 Gitlab, Bitbucket 等等。
并且,Github 很可能是地球上第一个给人们提供 “用作品社交” 方式的平台,你若是不能参与其中,实在是太可惜了!
从逻辑上理顺 Git 基本命令
Git 的作用,基本上可以被划分为三部分:
- 备份文件
- 跟踪文件变化
- 与他人协作共同操作文件
在一个 git 仓库中,总计有四个 “抽象层”,它们分别是:
- upstream repository 保存在云端的仓库
- local repository 本地仓库
- staging area 缓存区
- working directory 工作区
其中,local repository 和 staging area 这两个抽象层的数据,保存在 working directory 根目录下的一个隐藏目录 .git/ 下;需要使用 ls -a 才能看到。
当你使用 git init 命令将一个本地文件夹 working directory 初始化为 local repository 的之后,该文件夹内部的结构如下:
1 | . |
以下示意图中仅包含最基本的 Git 命令 —— 并且基本上都是独自使用 Git 时的常用命令。
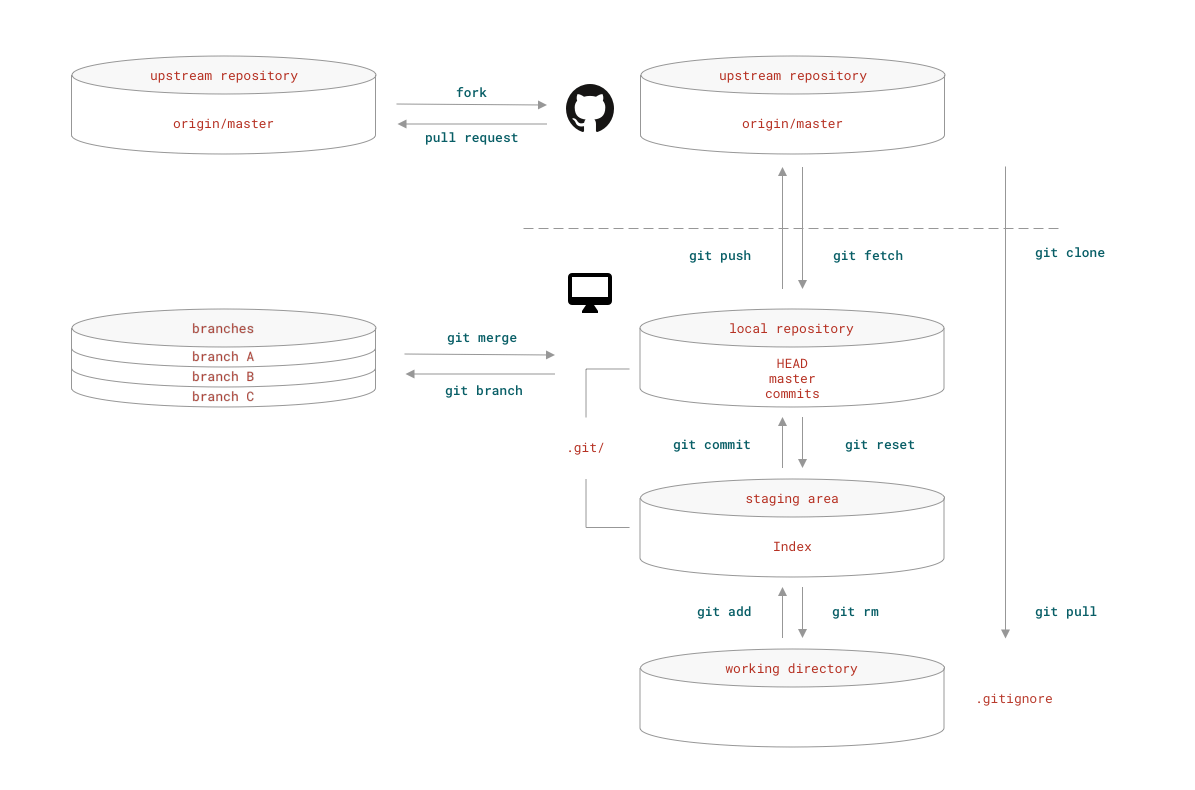
在工作区 working directory 这个抽象层中,你完成各种日常工作,创建、编辑、删除…… 你可能需要用某个编辑器去修改文件,你也可能频繁使用各种 Bash 命令,如,rm mkdir cp mv 等等。
时不时,你可能会把一些处理完的文件 “加入缓存区”;等一个阶段的工作完成之后,你可能会把那些已经放入缓存区的文件提交到(commit)本地仓库;而后继续工作…… 根据情况,你也会将本地仓库的文件推到(push)云端,即,远端仓库。如果,你正在与他人协作,你也可能经常需要从云端下拉(pull)最新版本到本地。
Git 的安装
Mac
Mac 的操作系统 Mavericks (10.9) 以上版本中都内建有 Git,你可以在 Terminal 中通过以下命令查看是否有 Git:
1 | git --version |
也可以通过 Homebrew 安装最新版本的 Git:
1 | ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)" |
还可以通过 Conda 安装:
1 | conda install -c anaconda git |
Windows
前往 https://gitforwindows.org 下载并安装 Git for Windows。
此外,它还会提供 Git Bash —— 在 Windows 操作系统中使用与 *Nix 操作系统一样的 Bash 命令行工具。
另外,在 Windows 操作系统中推荐使用 Git Bash 或者 PowerShell,而非 CMD 作为命令行工具。
Linux
大多数 Linux 操作系统要么基于 Debain,要么基于 Red-Hat —— 请自行查看 List of Linux distributions,确定自己的 Linux 发行版究竟基于哪一个。
基于 Debian 的 Linux 发行版:
1 | sudo apt-get update |
基于 Red-Hat 的 Linux 发行版:
1 | sudo yum upgrade |
Git 本地配置
在命令行工具中执行以下命令:
1 | git config --global user.name "<your_name>" |
Git GUI
Git 的图形化版本客户端,有很多种选择,以下几个跨平台的客户端最受欢迎:
更多选择,请移步查看 git-scm.com 上的 Git GUI Clients 列表。
需要了解的 Bash 基本命令
虽然 Git 也有图形化版本,但无论如何你都会接触到命令行工具。并且,谁都一样,早晚会遇到非使用命令行不可的情况。
以下是常用 Bash 命令的简要说明:
| 命令 | 简要说明 |
|---|---|
cd |
Change Directory 的缩写;转到指定目录 |
ls |
List 的缩写;列出当前目录中的内容 |
mkdir |
Make Directory 的缩写;在当前目录中创建一个新的目录 |
pwd |
Present Working Directory 的缩写;显示当前工作目录 |
touch |
创建一个指定名称的空新文件 |
rm |
Remove 的缩写;删除指定文件 |
rmdir |
Remove Directory 的缩写;删除指定目录 |
cp |
Copy 的缩写;拷贝指定文件 |
mv |
Move 的缩写;移动指定文件 |
cat |
Concatenate 的缩写;在屏幕中显示文件内容 |
chmod |
Change Mode 的缩写;改变文件的权限 |
man |
Manual 的缩写;显示指定命令的使用说明 |
其中,chmod 最常用的 4 个权限分别是:
| 文件权限模式 | 简要说明 |
|---|---|
777 |
任何人都可以读、写、执行该文件 |
755 |
任何人都可以读、执行该文件,但只有所有者可以修改 |
700 |
只有所有者才能进行读、写、执行操作 |
+x |
将文件设置为可执行 |
在使用 man 命令时,系统会使用 vim 文本编辑工具以只读模式打开帮助文件,常用键盘命令如下:
| 键盘命令 | 简要说明 |
|---|---|
f |
向后翻屏 |
b |
向前翻屏 |
d |
向后翻半屏 |
u |
向前翻半屏 |
j |
向后翻一行 |
k |
向前翻一行 |
h |
查看 vim 帮助 |
q |
退出 |
一些不错的 Git 教程
除了 Pro Git 这本书之外,还有很多值得去看:
当然,你肯定早晚会去 Github 上找 “Awesome Git”:
Jupyterlab 的安装与配置
下载并安装 Anaconda
Anaconda 是目前最方便的 Python 发行版,搭载了很多我们终将必用的软件包,除了 Python 之外,还有 R 语言,还包括 Pandoc,NumPy,SciPy,Matplotlib…… 等等。
无论是图形化界面安装,还是命令行界面安装,建议都把 Anaconda 安装在本地用户目录内,~/。请下载并安装 Python 3.x 的版本。
图形化界面安装的教程,官方的很详细,各个操作平台的说明都有:
在 MacOS 的 Terminal 命令行下,可以直接下载并安装:
1 | cd ~/Downloads/ |
安装到最后一步,会问你是否要安装微软出品的 Visual Studio Code,选择 yes —— 反正以后你的电脑上会不止一个文本编辑器…… 以后你可能还会安装的文本编辑器包括 SublimeText, Atom 等等。
安装完毕之后,打开 Terminal(Windows 系统需要打开之前安装的 Anaconda Prompt 输入),继续安装几个组件:
1 | conda update conda |
安装完毕之后,可以看看各个你将要用到的可执行命令都在什么地方,用 which 命令(windows下用 where 命令):
1 | which python |
第一次启动 Jupyter lab
打开 Terminal,cd 到你想打开 Jupyter lab 的目录(就是你保存 ipynb 文件的地方,以便在 Jupyter lab 中打开、浏览、编辑 ipynb 文件),在这里以用户根目录为例 ~/:
1 | cd ~ |
此时的 Terminal 窗口不能关闭,否则 Jupyter lab 就停止运行了 —— 就将它放在那里。
随后会有个浏览器打开,指向 http://localhost:8888/lab? —— 你就看到 Jupyter lab 的操作界面了。
目前,Jupyter lab 和 Jupyter notebook 是并存的,虽然前者是后者的下一步替代者。如果你依然习惯于使用 Jupyter notebook,那么,在浏览器中指向 http://localhost:8888/tree? 看到的就是 Jupyter notebook.
配置 Jupyter lab
打开 Terminal,输入以下命令:
1 | jupyter lab --generate-config |
这会在 ~/.jupyter/ 目录下生成一个 jupyter_notebook_config.py 文件。
1 | cd ~/.jupyter |
上面的 code 命令,需要你已经安装 Visual Studio Code,并且在已经在其中设置了 Install 'code' command in PATH。参见附录 Visual Studio Code 的安装与配置
事实上,你可以用你喜欢的任何编辑器打开 ~/.jupyter/jupyter_notebook_config.py 文件。
文件内容很长,有空可以仔细看。可以直接将以下内容拷贝粘贴到文件底部,根据需求修改:
1 | #c.NotebookApp.token = '' |
逐条解释一下:
c.NotebookApp.token = ''
每次打开 jupyter,它都会给你生成一个新的 Token —— 这是安全策略。但是,如果你只是在自己的电脑上使用,那么,这就给你制造了麻烦,因为若是你想同时用另外一个浏览器打开它,那你就需要从 Terminal 里拷贝那个 Token 出来。所以,你可以在配置文件里直接把它设置为空。
c.NotebookApp.open_browser = False
每次你执行 jupyter lab 或者 jupyter notebook 命令的时候,它都会使用系统默认浏览器。
每个人的习惯不一样。比如我,会想到用一个平时不怎么用的浏览器专门用在 Jupyter 上,这样会防止自己在关闭其它网页的时候不小心把 Jupyter 关掉…… 那我就会把这项设定为 False。
c.NotebookApp.notebook_dir = '~/'
在 Terminal 中执行 jupyter 命令的时候,它默认是在你当前所在的工作目录打开 jupyter,这同样是出于安全考虑。但是,如果你只是在自己的电脑上使用,且只有自己在使用,那么莫不如直接把它设置成 ~/,即,你的用户根目录,这样会很方便地访问各种地方的文件……
c.NotebookApp.default_url = '/tree'
这一项留给那些依然习惯于使用 jupyter notebook 的人,这样设置之后,即便是输入 jupyter lab 命令,打开的还是 jupyter notebook。
在 Terminal 里常用的与 Jupyter 有关的命令有:
1 | jupyter lab |
将 Jupyter lab 配置成系统服务
如果,你厌烦每次都要跑到 Terminal 里启动 Jupyter lab,可以把它配置成系统服务,每次开机启动它就自动运行。而你需要做的只不过是直接从浏览器中访问 http://localhost:8888/。
1 | code ~/Library/LaunchAgents/com.jupyter.lab.plist |
这条命令会让 Visual Studio Code 创建 ~/Library/LaunchAgents/com.jupyter.lab.plist 文件并打开。
在其中拷贝粘贴以下内容,注意,要把其中的 your_username 修改为你的用户名:
1 |
|
如果之前在 jupyter_notebook_config.py 文件里已经设置过
1 | c.NotebookApp.open_browser = False |
那么这两行就可以不要了:
1 | <string>--no-browser</string> |
而后在 Terminal 里执行:
1 | launchctl load ~/Library/LaunchAgents/com.jupyter.lab.plist |
如果你想重新启动这个服务,那么执行:
1 | launchctl unload ~/Library/LaunchAgents/com.jupyter.lab.plist |
关于 Jupyter lab themes
对中文用户来说,Jupyter 的默认字号有点过小,阅读起来不是很舒适。但最佳的方案不是去寻找合适的 themes,而是直接使用支持 Stylus 这类终端 CSS 定制插件的浏览器,Chrome/Firefox/Opera 都支持 Stylus 插件。
我用的 Stylus 定制 CSS 是这样的:
1 | a {color: #2456A4 ;} |
这样就相当于我把 JupyterLab Light 这个 Theme 稍微 Tweak 了一下。
另,我写的内容里,为了重点突出,特别定制了 strong 和 em 两个元素的显示,让它们以不同的颜色展示;又因为中文并不适合斜体展示,所以,把 em 的 font-style 设定为 normal……
安装插件
Jupyter notebook 经过很多年的发展,现在有很多扩展插件,但也有其中一些并不兼容最新的 Jupyter lab。不过,刚开始的时候用不着那么多插件,你只用其中的两个就足够开始了:
首先在用快捷键 ⌘ , 打开 jupyter lab 的 Advanced Settings,在 Extension Manager 中,添加 User Overrides:
1 | { |
而后在 Terminal 执行以下命令安装插件:
1 | jupyter labextension install @jupyterlab/toc |
toc 插件,自动将 ipynb 文件中的标题转换成目录。

jupyterlab_sublime 则可以让你在 Jupyter lab 的 cell 中,使用跟 SublimeText 一样的快捷键,比如 ⌘ D 能够多选其它与当前选中内容一样的内容;比如 ⌘ 加鼠标点击,可以生成多个可编辑点……

常用快捷键
以下是 MacOS 下 Jupyter lab 最常用的快捷键。快捷键在两种模式下执行,进入编辑模式用 ⏎,回到命令模式用 ⎋(ESC)。
另外,代码编辑过程中需要安装 Jupyterlab 插件 @ryantam626/jupyterlab_sublime 之后才能使用 “多行同时编辑功能”。
| 快捷键 | 说明 | 模式 |
|---|---|---|
ESC |
从编辑模式回到命令模式 | 命令 |
A |
在当前 Cell 之前插入一个 Cell | |
B |
在当前 Cell 之后插入一个 Cell | |
D, D |
连续按两次 d 键,删除当前 Cell |
|
Y |
将当前 Cell 设置为 Code Cell | |
M |
将当前 Cell 设置为 Markdown Cell | |
^ ⇧ - |
将当前 Cell 拆分为两个 | 编辑 |
⇧ M |
合并选中的 Cells | |
⇧ J or ⇧ ↓ |
连续向下选中 Cells | |
⇧ K or ⇧ ↑ |
连续向上选中 Cells | |
⇧ ⏎ or ^ ⏎ |
运行当前 Cell 中的代码 | |
⇧ L |
显示/隐藏代码行号 | |
⏎ |
当前 Cell 进入编辑模式 | 编辑 |
⇥ |
自动补全代码 | |
⇧ ⇥ |
呼出当前光标下词汇的 Docstring | |
⌘ D |
Sublime Keymap: 选中下一个相同字符串 | |
⇧ ⌘ L |
Sublime Keymap: 在选中的行内启动多行同时编辑 | |
⌘ + Mouse Click |
生成下一个可同时编辑的光标点 |
增加一些必要的快捷键
在 Settings > Keyboard Shortcuts 中,可以设定一些常用但系统并未给出的快捷键:
1 | { |
这样就添加了 4 个快捷键:
⌥ J: Move selected cells down⌥ K: Move selected cells upS: Enable output scrolling⌥ S: Disable output scrolling
比如 Move Selected cells up:
输出所有变量内容
默认情况下,Code Cell 只输出最后一个可以被 evaluate 的值,用 _ 代表之前刚刚被 evaluate 的值。
1 | [1, 2, 3] |
[1, 2, 3]
1 | _ # 执行完上面的 Cell,试试这个 Cell; 而后执行完下面的 Cell 之后再重新执行一次当前这个 Cell |
[1, 2, 3]
1 | (1, 2, 3) |
{1, 2, 3}
于是,为了显示最近 evaluate 的多个值,我们总是不得不使用很多的 print()……
如果觉得这事比较烦的话,可以在 Cell 最上面写上:
1 | from IPython.core.interactiveshell import InteractiveShell |
如果还想更省事一点,就把这个设置写入配置文件:
1 | c.InteractiveShell.ast_node_interactivity = "all" |
1 | from IPython.core.interactiveshell import InteractiveShell |
(1, 2, 3)
{1, 2, 3}
魔法函数
在 Code Cell 里,可以运行一些 “魔法函数”(Magic Functions),这是秉承了 IPython 的特性。绝大多数在 IPython 里能够使用的魔法函数在 Jupyterlab 里都可以直接使用。完整的 IPython 魔法函数请参照:
https://ipython.readthedocs.io/en/stable/interactive/magics.html
Jupyterlab 里较为常用的魔法函数整理如下:
| 魔法函数 | 说明 |
|---|---|
%lsmagic |
列出所有可被使用的 Jupyter lab 魔法函数 |
%run |
在 Cell 中运行 .py 文件:%run file_name |
%who |
列出所有当前 Global Scope 中的变量;类似的还有:%who df,%whos |
%env |
列出当前的环境变量 |
%load |
将其他文件内容导入 Cell,%load source,source 可以是文件名,也可以是 URL。 |
%time |
返回 Cell 内代码执行的时间,相关的还有 %timeit |
%writefile |
把 Cell 的内容写入文件,%write file_name;%write -a file_name,-a 是追加 |
%matplotlib inline |
行内展示 matplotlib 的结果 |
%%bash |
运行随后的 shell 命令,比如 %%bash ls;与之类似的还有 %%HTML,%%python2,%%python3,%%ruby,%%perl…… |
桌面版 Jupyter App
Nteract
支持各个操作系统,很好看、很好用。有一个小缺点是,不支持 input() 函数的调用。

Pineapple
只支持 MacOS,也很好用 —— 缺点就是很难看……

这些符号都代表什么?
以下的表格你可以用很多次 —— 每次学一门新语言的时候,都可以拿它整理一遍思路……
最初的时候,人们能向计算机输入的只能是 ASCII 码表中的字符。于是从一开始,计算机科学家们就绞尽脑汁去琢磨怎么把这些符号用好、用足……
于是,ASCII 码表中的字符常常在不同的地方有不同的用处。比如,.,在操作系统中,常常当作文件名和扩展名之间的分隔符;在很多编程语言中,都被当作调用 Class Attributes 和 Class Methods 的符号;在正则表达式中,. 代表除 \r \n 之外的任意字符……
把下面的表格打印出来,整理一下,在表格里填写每个符号在 Python 中都是用来做什么的?[1]
当前文件夹之中,有
symbols.numbers文件,是用来打印以下表格的……
以后不管学什么语言,就拿这个表格过一遍,到时候只有一个感觉:越学越简单!
很多人最初的时候学不进去,就是因为 “一些符号的用法太多了,经常混淆,于是就觉得累了、烦了……” 然而,只要多重复几次多在脑子里过几遍就熟悉了 —— 若是真的熟悉了、若是真的掌握了,你就会觉得:真的没什么啊!哪儿有那么难啊?!
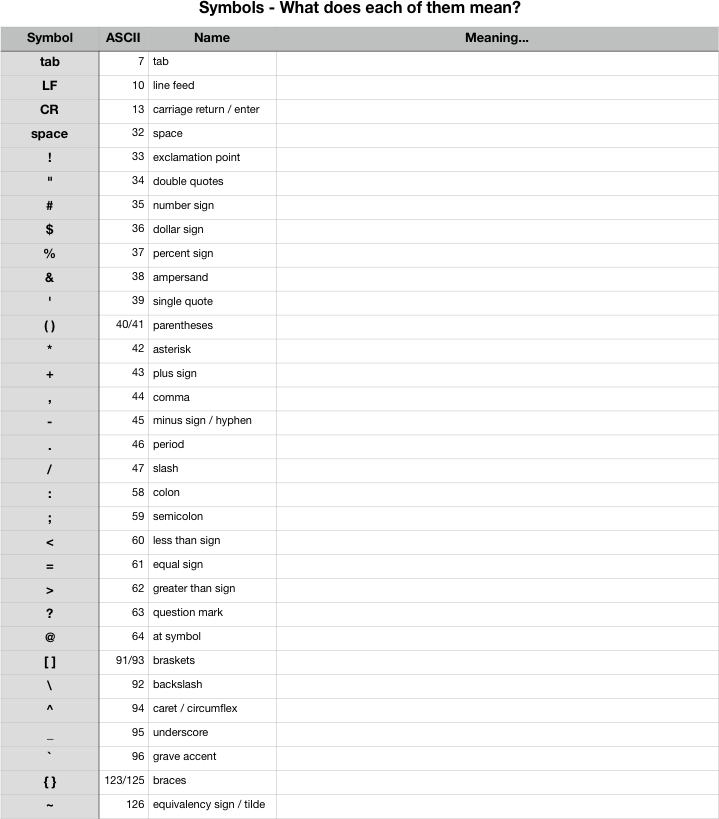
学编程的一个好玩之处就是:
但凡你学会了任何一门编程语言,你就会发现你的键盘上的每一个键你都用得上……
可是在此之前,你跟人家花了同样的价钱买来的硬件设备,你竟然有那么多根本就没用过的东西!
普通人花同样价钱买来的是台机器而已;可是你却不一样 —— 用同样的价钱买来的是一个特别听话的机器人,一个可以替你不分昼夜不辞辛苦干活的机器人 —— 这感觉非常神奇。
脚注
[1]:Python 语法,请参阅 The Python Language Reference 2. Lexical analysis
自学是门艺术
PART 1
- Part.1.A 为什么一定要掌握自学能力?
- Part.1.B 为什么把编程当作自学的入口?
- Part.1.C 只靠阅读习得新技能
- Part.1.D 开始阅读前的一些准备
- Part.1.E.1 入口
- Part.1.E.2 值及其相应的运算
- Part.1.E.3 流程控制
- Part.1.E.4 函数
- Part.1.E.5 字符串
- Part.1.E.6 数据容器
- Part.1.E.7 文件
- Part.1.F 如何从容应对含有过多 “过早引用” 的知识?
- Part.1.G 官方教程:The Python Tutorial
PART 2
- Part.2.A 笨拙与耐心
- Part.2.B 刻意练习
- Part.2.C 为什么从函数开始?
- Part.2.D.1 关于参数(上)
- Part.2.D.2 关于参数(下)
- Part.2.D.3 化名与匿名
- Part.2.D.4 递归函数
- Part.2.D.5 函数的文档
- Part.2.D.6 保存到文件的函数
- Part.2.D.7 测试驱动的开发
- Part.2.D.8 可执行的 Python 文件
- Part.2.E 刻意思考
PART 3
- Part.3.A 战胜难点
- Part.3.B.1 类 —— 面向对象编程
- Part.3.B.2 类 —— Python 的实现
- Part.3.B.3 函数工具
- Part.3.B.4 正则表达式
- Part.3.B.5 BNF 以及 EBNF
- Part.3.C 拆解
- Part.3.D 刚需幻觉
- Part.3.E 全面 —— 自学的境界
- Part.3.F 自学者的社交
- Part.3.G 这是自学者的黄金时代
- Part.3.H 避免注意力漂移
附章
附录
- Appendix A: Visual Studio Code 的安装与配置
- Appendix B: Git 简介
- Appendix C: Jupyterlab 的安装与配置
- Appendix D: 这些符号都代表什么?
IPCreator’s View of Coding
作者:IPCreator
Skill is acquired through correct and repetitive practice, and practice makes perfect.
阅读整合–>
代码片段–>
实践项目–>
博客总结–>
- 不放过任何一个err,每成功解决一个error就意味着自己的经验库又append一个案例;
- 理不顺想不通的时候,成长的时刻到了,坚持、坚持再坚持,成就感与困难度成正比;
- 官网+stackflow+github+google还解决不了的时候,暂时放一放,持续关注思考,直至惊喜发生;
- 换位常识思考,如果你是设计者,你会怎么设计,为什么这样设计?
- 尽量不要复制粘贴,要逐字阅读,逐个输入,对开发而言,thinking与coding相辅相成,缺一不可;
- 知其然还要知其所以然,不要浮于表面,浅尝则止,运行/部署成功不等于你掌握了每个环节的原理;
- 慢工出细活,慢就是快,防火胜于救火,先打好基础(概念、框架、原理等),高手都重视内功;
- 专而精,精而深,通过一个突破口(语言、框架、平台),抓住本质量(通俗易懂,能重建和迁移),再融会贯通,一通百通;
- coding只是解决问题的一种方式,不要重复发明轮子,要open和share,不要敝扫自珍,因为每个人都能掌握相应的技能,只是时间早晚而已;
- 创新整合也是一种行之有效的商业途径,不要为了技术而技术,为了创新而创新,商业思维很重要;
- 从战略上来说,我们大部分都只是用别人开发出来的工具(类似于厨具)开发产品(类似于菜品)而已;
- 阅读代码(类似于品尝他人菜品)、模仿创新(借鉴改造)、原创分享(晋级高级厨师);
- 道理都懂,为什么难以坚持?没有尝到甜头或者没有吃到苦头,又或者只是懒惰;
- 35岁以后能否再编程?取决于:以前的编程模式是否健康可持续?是否为自己实现创新产品和服务(而不只是为了挣钱);
- 程序员人生的梦想和快乐简单易实现,成为其中一员才能真正感同身受…
- 有劲、有趣和有用,正常可持续,Kick-off & Keep-going
Dreams cann’t measured by S/A/B/C/D degree、money and position.
Great mind thinks alike.
RTFC Read the fucking code.
RTFM Read the fucking manual.
STFW Search the fucking Web.
Read the article word by word.
Code can talk, let the code talk.
A good name tells the truth.
Keep code simple and reusable.
Keep hungry, Keep foolish.
Keep healthy and sustainable.
Less is more, slow is quick.
Don’t Reinvent the Wheel.
Use is the best way of learning English , so is programming.
Master the essence of things, including languages (English/C/C++/JAVA/PYTHON/JS…),
platforms(Arena/Android/Tensor…),tools(gcc/make/gradle/git…),etc
We make good habits first, then habits make us.
Success is a habit, so is happiness.
Hello World Program in Java
1 | class HelloWorld |
Hello World Program in C1
2
3
4
5
6#include<stdio.h>
main()
{
printf(“Hello World”);
}
Hello World Program in C++1
2
3
4
5
6#include <iostream>
int main()
{
std::cout << “Hello, world”;
}
Hello World Program in Javascript1
2
3
4
5
6
7<script>
window.onload = function()
{
document.getElementById(‘result’).innerHTML = “Hello World”;
}
</script>
<div id=”result></div>
Hello World Program in HTML<p>Hello World</p>
Hello World Program in Pythonprint “Hello World
Hello World Program in Perlprint “Hello World
Hello World Program in Rubyputs “Hello World
Source: http://blog.learntoprogram.tv/hello-world-eight-languages/
太用力的人跑不远
写在前面
有阶段的自己,会用蛮力去学习一些东西,就是这东西不管是否适合目前自己的知识体系, 觉得学了之后会更牛逼就去学,但是这样的东西往往学了记不住。 学习的过程越用力反而显得越吃力, 太吃力的事情,自然就无法有恒心, 这就是很多人会觉得自己做事总是无法持之以恒的原因。
努力不应该是某种需要被时常觉知的东西,意志力是短期内会用完的精神能量。
真正坚持到最后的人靠的不是激情,而是恰到好处的喜欢和投入。
太用力的人更容易产生期望落差,更不愿接受自己找错了方向的事实——没有什么比这样的“失落”更能让人心寒的了,太用力的人大多都因心累而倒在了半途中。
精神上的用力并不会让你跑得更快,但是精神上的疲惫却可以让你停下。
人越用力,就会越想要得到及时的良好刺激。越用力的人对于正刺激的需求就越高,越不能忍受暂时的负反馈。遗憾的是,人生常常是没有下文的考卷,这种刺激来得太慢、太不稳定。
真正的坚持归于平静,靠的是温和的发力,而不是时时刻刻的刺激。
太用力的人增加了执行的功耗。纠结,是太用力的一种表现,造成内部的运转处于空转的状态——意识与行动的主观脱节;从心所欲,就是把运转效率最大化后的结果——所想即所为。执行阶段最大的敌人,是纠结,是埋怨,是内心的冲突——太用力,就是心理额外动作太多。想好之后就只管去做。
我一直告诫自己不要用力过猛,以保持自己对困难的顿感和不顺的接受程度。
短期的过度用力极容易造成身体和心理上的挫伤。哪怕你在做的事情非常重要,也要保证基本的休息和放松。
不论是以后的工作还是将来的创业,都要保持一颗平常心。你需要更多的“寸劲”而不是“用力感”。在找到受力点“all in”之前,一切都要顺势而行,自然随和。
人在学习的过程会经历一系列的过程,先是笨拙期,再是熟练期——这两个过程他虽然能运用出技能,但是头脑中仍然能感受到使用时的提取感。这两个阶段都需要用力,但是用力的程度却大幅度减小。
技能掌握的最后阶段是运用自如期,就是张三丰把太极拳的形态全部都忘了的阶段。这个时候头脑中已经能下意识地去进行活动,达到了能耗最低的理想阶段。
从用力感,到毫无感觉,是一种技能掌握上的纯熟。年轻的时候太认真是件好事,或许只有用力过了,才能体会从心所欲、顺其自然的难得。
IT人员怎么用力
总有在校的学生问我现在 X,Y,Z… 技术很火热,应该学哪个? 我看他列出的那些准备学习的选项中,其实前景和热门程度都差不多。 这让他陷入了选择焦虑症,不管做什么决定都怕「一失足成千古恨」。
对技术发展趋势关心是好事,就像之前那篇「不要总是选择困难模式」里面说的那样。 但是其实在「不要总是选择困难模式」里面忽略了很重要的一点,就是你个人的兴趣。 比如有的人对苹果的东西有天生的热爱,所以选择「iOS开发」对他来说就更容易做好。 尽可能选择会让自己 Enjoy 的技术方向,路还很长,不享受过程的话容易半途而废。
太用力的人跑不远
记得之前本科的时候喜欢和舍友一起打Dota,打Dota开局之前一般要等人齐, 等人的这段时间我有时候会切出来写写代码,叫舍友开局了告诉我一声。 然后别人看到我在打Dota间隙都在写代码,就觉得我有多努力多努力,给人了一种非常「刻苦」的印象。 以至于上次和一个本科同学吃饭他还说起这个事情,觉得我能做到这样非常「牛逼」。
但是其实这样的事情,如果对于真的对写代码有经历过热爱的人,是不会觉得有多么刻苦的事情。 这是自然而然的事情,甚至其实有些代码,那种满足好奇心的快感,是比打游戏有意思的多, 是件很Enjoy的事情,而不是所谓的「刻苦」。
就像跑步,「太用力的人跑不远」。
不要用蛮力去学编程
记得当年初学 C++ 的同学,听别人说 C++ 很基础也很重要的一个知识点就是STL, 然后听说要学好 STL 就应该去看看侯捷的「STL源码剖析」。 然后就买了书硬啃,然后没啃几天就放弃了,觉得太讳莫如深了没法理解。
但是如果换个学习的方式, 先假设现在没有STL这个标准库, 让你用已有的C++语法知识去自己写一个仿造STL标准库的功能, 哪怕是最最简单的 vector 。 你在编写的时候就会自然而然得体会到内存动态扩展的一些缺点和潜在的坑。 会知道为什么适当使用 reserve 和 swap 能非常明显的提高性能。
然后在自己思考的过程中会提出很多相关的疑惑, 带着疑惑再去翻看「STL源码剖析」, 就会让你对一个个数据结构恍然大悟知根知底。 自然而然你的看书体验会非常的 Enjoy, 而不是觉得苦涩难咽。
编程和求知本身是一件愉悦身心的事情, 如果只是为了高薪,而用蛮力去写代码,只会让自己疲惫不堪。
最后
希望对在学习编程的路上很挣扎的朋友有所帮助。 毕竟工作是生活的很大一部分, 如果工作不开心,生活怎么办。
不是人人都懂的学习要点
学习是一种基础性的能力。然而,“吾生也有涯,而知也无涯。”,如果学习不注意方法,则会“以有涯随无涯,殆矣”。
一.学习也是一种能力
看到这个标题,有人会说:“学习,谁不会?”的确,学习就像吃饭睡觉一样,是人的一种本能,人人都有学习的能力。我们在刚出生的时候,什么也不知道,是一张真正的白纸,我们靠学习的本能,学会了走路、说话、穿衣服…后来,我们上学了,老师把书本上的知识一点一点灌输到我们的脑子里,我们掌握的知识越来越多,与此同时,我们学习能力却好像越来越差了,习惯了被别人喂饱,似乎忘记了怎么来喂自己了。
学习本来只是一种本能,算不上什么能力,然而,经过二十多年的不断学习,学习反而成为了一种真正的能力,因为我们慢慢失去了它,它就更显得珍贵。
在学校里我们基本上被动式学习,然而走出了象牙塔之后,不会再有人对你负责,不会有人主动教你,我们需要主动的学习。所谓的学习能力,其实就是自主学习的能力。
几年前,曾有一本风靡管理界的书,叫《第五项修炼》,这本书倡导建立学习型组织,因为从长远来看,一个组织唯一可持续的竞争优秀,就是比竞争对手更快更好的学习能力。
一个公司如此,一个人又何尝不是如此?众所周知现在是一个知识爆炸的时候代,知识更新非常快。据说,一个大学毕业生所学习到的知识,在毕业之后的2年内,有效的不过剩下5%,更何况我们的学校与社会需要严重脱轨。我们赖以立足的,不在于我们现在掌握了多少知识,而是我们有多强的学习能力!
学习不但是一种能力,而且是一种至关重要的能力,而这种能力的核心,就是学习的方法和心态。
二.买书是最划算的投资
古人云:“书中自有黄金屋,书中自有颜如玉。”这说明先贤们早就认识到,买书是最划算的投资了。
当我刚出道的时候,拿着非常微薄的工资,有一次我向主管抱怨道:“现在的书真贵啊,这点工资连饭都吃不起,更别说买书了!”主管对我说:“不要吝惜买书的钱,宁可忍着不吃饭,也不要忍着不买书,因为买书是回报率的最高的投资了。”
主管的话让我非常震动。后来,我看到喜欢的书时,再有没有手软过。我不断的学习,开发能力也不断的提高,工资水平也获得了大幅度的提高。一年后,我一个月工资的涨幅,就足够买两年的书了。你说,还有比这更划算的投资吗?
一本书,哪怕只有一页纸是有用的,它将所产生的潜在价值,也会远远超过书本身的价格。当然,书不在多,能踏踏实实消化掉一本好书,可能比泛泛而读10本普通书,要更有价值得多。
三.多读经典书
十年前,我刚进入IT行业的时候,真是求知渴,每星期都要往购书中心跑,可惜的是,那时给程序员看的书不像现在这么多,高质量的书就更少了。当时我印象中比较经典的书籍就是《Windows程序设计》、《COM本质论》、《Java编程思想》,还有就是谭浩强的《C语言程序设计》。其它充斥书架的,就是类似于《21天精通XXX》、《XXX从入门到精通》、《XX宝典》这样的书籍。
回首往昔,令我比较郁闷的一件事就是在我最有学习动力的时候,看的高质量的书籍太少,就好像是在长身体的时候,天天吃的是没营养的泡面。当然,这跟没有人指导也有很大的关系,独自一个人学习,让我走了很多的弯路。
软件开发方面的书籍,我大致将其分为三类:
(1)浅显的入门类书籍。
这类书的标题往往是《XX天精通XXX》、《XXX从入门到精通》、《XX开发实战》等,这类书往往从软件的安装讲起,喜欢翻译帮助文件。有人批评这类书为烂书、毫无价值,这并不公平。至少我本人,也曾从这些书中学到一些东西。即使是21天系列书,也有适合看的人群,只不过,它一般也就只能看21天而已,过后就可以扔到垃圾堆。这类书只适于还没有入门的初学者,从中学到一些入门的招式。这种书在刚起步的时候一般买上一本就可以了。如果你善于使用搜索引擎,这一本书也可以省了。
(2)国内外高手写的实战类书籍。
这类书实战性很强,把技术及原理讲得很透彻。比如《windows环境下32位汇编语言程序设计》、《深入解析MFC》、《Delphi深度探索》、《深入浅出WPF》、《深入剖析Asp.NET组件设计》等。以前这类书都是从国外翻译或从台湾引进,现在国内高手越来越多,出自国内作者的也越来越多。这类书如果在你学习的每个方向看个两三本,并且通过实践消化掉,那么毫无疑问,你会成为一个优秀的程序员。
(3)国外大牛写的、揭露本质、有丰富思想的书。
这类书就是所谓的经典书了,例如《代码大全》、《编程珠玑》、《设计模式》、《重构》、《代码整洁之道》等。经典书就像一个有深度、有思想的朋友,他会给你启发、每次阅读都会有新的收获,这类书具有真正的收藏价值。看经典书永远是正确的选择,它绝不会浪费你的时间,因为经典书是无数人沙里淘金、帮你挑选过的结果。
然而,阅读这类书并不是一件容易的事情,读者需要有丰富的开发经验,才能与作者产生共鸣。真正能消化经典书的人其实不多,这就好像饮酒,一个新手无论如何也品不出葡萄美酒的醇香。在酒桌上,人人都把杯中酒一饮而尽,当有人点评“这个酒不错”的时候,我只能无奈的苦笑一番,真的是甘苦自知。
如果一本经典书你看得很辛苦,很有可能就是因为你功力未够,这种情况下不要着急,慢点来,不妨先将其先束之高阁,多看看第二类实战型书籍,过一段时间再回头来看,也许你会有新的惊喜。
四.不要在上班时间看书
一个善于学习的人,首先要善于利用一切时间来学习。不知是伟大的雷锋叔叔还是鲁迅爷爷曾经说过:“时间就像海绵里的水,只要愿挤,总还是有的。”然而,当我们从上班时间中挤时间学习时,就千万要注意了,不要在上班时间看书!
上班时间看书不但是一件很敏感的事情,而且非常吸引眼球,很快就会引起周遭的不爽。首先老板心里不爽,他想:“我给你钱是让你来工作的,不是来学习的!”;其次同事们也不爽:“我们工作都做不完,瞧,这小子真闲哪!”用不了多久,你就会成为被众人排斥的异类。
当然,你可能会说,“我工作已经做完了,经理没有安排,当然可以学习了”,其实不然。你完成了一件事情,不等于所有的事情都完成了。一个优秀的员工,应该是主动要工作,而不是被动的等工作。工作完成以后,你至少还可以:
(1)主动汇报给你的经理,请他来检查你的成果,并安排新的任务;
(2)如果公司这一段时间确实比较闲,没有什么具体的任务,可以进行代码重构、优化;
(3)你还可以主动请缨,承担额外的工作或更艰巨的任务。
(4)如果一定要学习,也只能对着电脑屏幕来学习,纸质书最多只能拿来翻阅一下,而不能一直捧着,以免影响到其他人的情绪。
五、只学习与工作相关的东西
我曾发现不少程序员在学习方面找不到方向,一会学学C#,一会学学Java,看了最新的编程语言排行榜,又觉得该学C++。这样左抓抓,右挠挠,只会让你觉得更痒。
学习最忌三心二意。俗话说:“伤其十指不如断其一指”,每门都学一点,还不如专心学好一个方向。这个道理谁都懂,可是又该学哪个方向呢?难道只能跟着感觉走吗?
不!最实际的方向,应该跟着工作走,工作需要什么,我们就学什么,把工作需要的技能熟练掌握。我们为什么要学习和工作弱相关的东西呢?是为了转行或跳槽吗?可是,如果我们连现在本职工作都不能做好,又怎么能保证到新的岗位、用新学的技能就可以做得更好呢?
学习与工作需要的的东西,有很多好处:
首先,可以集中精力,在某一方面钻研得更加深入。所谓“百招会不如一招绝”,有了绝招,你还怕不能在“武林”立足吗?《天龙八部》中的慕容复武功博学无比,最后还不是被只会一招六脉神剑的段誉打得落花流水?
其次,可以学得更快、更深入,因为学习更具有针对性,而且可以立即在工作中运用,可以马上检验出学习的效果,对存在的问题可以进行深入的研究,因此掌握的知识也会更加的牢固。
第三,学习与工作结合在一起,工作时间也就成了学习时间,这样突破了三个8小时的限制。有人说,我们每天所有拥有的时间可以分为三个8小时,工作8小时,睡觉8小时,另外还有8小时自己可以自由支配的时间。工作和睡觉的两个8小时大家都一样,决定人生高度的是另外这个8小时。当我们把学习的焦点放到与工作相关的知识上时,工作时间中的很大一部分,同时也就成了宝贵的学习时间,这真是一举两得的美事啊。
六.织网式的学习
知识的广度和深度都很重要。作为一个程序员,深入把握技术细节,是写出优质代码的保证。但对于一个项目经理而言,知识的广度更显重要。项目中碰到的问题往往是综合性的,只有具有广博的知识,才能快速的对问题进行分析和定位。在程序员通往项目经理的道路上,我们必须有意识的扩大自己的知识面,形成更完善的知识体系。
每个人的知识体系就好比是一张网,我们学习其实就是要织这样一张网。 我曾看过渔网的编织过程,渔网虽大,也是一个结点起步,一个点一个点的编出来的,编织的过程中,始终只有一根主线。
学习又何尝不是这样,知识体系的大网也是由许多小的结点组成,要结这样一张网,只能由一个点起步。牵住一条主线,织出一个个的点,由点带出面,最后才能形成这张大网。
我曾经编写过一个网络信息采集软件,这个软件可以从具有列表页网站中按字段设置采集信息,支持自定义字段、页面多级关联、下载附件、支持多种数据库、可视化定义等特性。刚开始时,觉得这个软件也是一个比较大的功能点而已,后来发现这个不起眼的功能关联着大量的知识点,在开发过程中, 我顺藤摸瓜,各个击破,对很多知识点进行了细致的学习研究,软件开发完成后,个人的知识体系网也进一步得到了补充和完善。
图1 由知识点形成知识网
七.问题是最好的学习机会
日本经营之神松下幸之助曾经说过:“工作就是不断发现问题、分析问题、最终解决问题的一个过程,晋升之门将永远为那些随时解决问题的人敞开着。”可见,工作过程中有问题是正常,没有问题那才是真正的问题。在发生问题能时,能勇于面对问题、解决问题的人,才是公司真正的核心骨干。
现实中,很多人总是千方百计回避问题,当上司安排一项艰巨的任务时,也是想尽办法推托。殊不知,对于个人而言,其实问题是最好的学习机会。往往那些愿意接受困难工作的人,能力会变得越来越强,那就是因为他们在克服困难的过程中取得了巨大的进步。
有一次,一位项目经理对我说:“有一个问题,客户有一台HP服务器要装磁盘阵列,没人会做,怎么办啊?”
“可以学啊,没有人愿意去吗?”
“我都问了,没人想去。”
“哦,正好明天我有时间,我也没装过磁盘阵列,那我明天去学着弄一下。”我说的是真心话。
第二天早上,当我准备出发时,项目经理告诉我不用我去了,因为项目组好几个同事都想去“学着弄一下”。
结果服务器很快就装好了,远远没有之前大家想像的那么困难嘛。更重要的是,在解决这个问题的过程中,大家都学会了怎么装磁盘阵列。
碰到困难时,迎难而上吧,千万不要拒绝这个最好的学习机会!
八.经常思考总结
子曰:“学而不思则罔”。只学习不思考,就会迷惑,难以把握事情的本质。这就好比一个学武之人,只习得其形,而未得其神,难以成为真正的高手。
一个程序员从入门,到成为高手的过程中,往往要经过几次顿悟。顿悟会让你跳出知识的丛林,一切豁然开朗,仿佛打通了全身的奇经八脉一般奇妙。记得我有一次,顿悟到了一个很简单的结论:“原来高级编程语言中的类库是封装了Windows API来实现的。”后来碰到一些自带类库无法实现的功能时,我就会想到,其实可以通过调用Windows API来实现。利用这个思路,我解决了一些看起来很难的问题,得到老板的赏识,从而很快获得提升。
顿悟非常可贵,然而它不是随便发生的,而是经过一次次苦苦思索之后、灵光闪现的结果。思考的过程,其实就是将外在的知识内化为自己的知识的过程,而顿悟,则是批量的实现这种内化,将无数个知识点连接在一起,达到融会贯通的境界。
九、克服“高原现象”
爱学习的人都会有这样的经历,学习持续了一段时间之后,往往会有一个瓶颈期,长时间似乎很久没有什么进步,于是内心非常着急。
这种情况实际上这是由人的学习规律决定的一种“高原现象”。据研究,学习者在刚开始进步快,随后有一个明显的或长或短的进步停顿期,后期进步慢,中间的停顿期叫高原期。

图2 技能学习练习曲线
在我看来,高原期实质是一个消化期,由于前期的学习积累了太多的知识点,这些知识点在大脑中乱作一团,还没有形成一个知识体系。这时需要一定的时间来消化它,将它融会贯通,经常思考总结可以快速帮你跨过高原期。
在处于高原期的时候,还可以换一个相关的方向来学习,例如编程语言学不下去了,你可以学习一下设计模式,设计模式也学不下去了,再换成数据库。通过学习这些相关的知识,不但补齐了知识体系中的短板,而且各个知识点之间可以互相启发,帮助你实现顿悟,跨过高原期。
十、学习要有好心态
(1)学习要静心
急于求成是学习过程中普遍存在的一种心态。这可以理解,毕竟作为一个程序员,要学的东西实在太多了,而社会又是那样的浮躁,让人觉得一切都是那样的不安全、不确定,似乎只有学得快一点,才能跟上社会的脚步。
可是“欲速则不达”,想快快的学,往往会形成东一榔头、西一棒槌的学习方式,每一个点都没有吃透。心沉不下去,知识也会沉不下去。要想成为真正的高手,只能静下心来,一步一个脚印的攀登。
(2)学习是一个持续一生的过程
人生的过程,就是一个自我完善过程。
孔子曾经说:“吾十有五而志于学,三十而立,四十而不惑,五十而知天命,六十而耳顺,七十而从心所欲,不逾矩。”可见孔子也不是天生的圣人,也在不停的学习、进步,从“志于学”到最后“从心所欲,不逾矩”,孔子一共花了55年的时间。
作为一个程序员,更是需要不断更新自己的知识。我们所知道的东西,就像一个白色的圆圈,圈外则是黑暗的未知的世界。当圆圈越大,所接触到的黑暗部分就越多。我们只有不停的学习,打破更多的黑暗,找到更多光明。
(3)保持饥饿,保持愚蠢
看了《乔布斯传》之后,我最喜欢的一句话是“求知若饥,虚心若愚”(Stay Hungry,Stay Foolish),其实我更喜欢它更原生态的翻译“保持饥饿,保持愚蠢”。我们只有认识到自己还很饥饿和愚蠢,才会像没吃饱一样,由衷的需要学习、爱上学习。
当然,知易行难,知行合一才是学习的最高境界。我也始终是一个学习者,一直在路上。
关于App程序员泡沫
前言
做开发快七年了,对于程序员,外行人总有着数不完的讽刺和误解,但是我都懒得去解释,代码搬运工人也好,民工也罢,随他们去说吧。但是网上最近流传的程序员泡沫,尤其是APP程序员泡沫的文章导致很多我们的年轻的同行产生了疑惑,所以我这个隐藏了很久的能言善辩的老程序员出山来聊一聊这个APP程序员泡沫的话题。
笔者是2010年从事安卓开发,此前做J2ee,对于安卓我有很深的感情,此前也是有意学了iOS,但是还是决定在安卓这条路上一直走到黑,在2010年一个好的安卓开发苗子工资可以过万,工作经验也就1年那样子,基本上你会点安卓都可以接近1W。想想最近某些文章中提到现在安卓开发新手动不动就要过万的工资相比,我觉得现在的新手做法并不为过:第一,以现在的北京物价房价对比2010年来说,开发的工资其实并没有涨反倒是跌了。第二,现在的开发比2010年的新手安卓开发要厉害一些,那个时候网上资料很少,书也很少,大多数安卓开发自学起来很痛苦。现在网上资料多,也有很多高水品的技术书,也有很完善的培训机制。
当然现在很多APP开发存在漫天要价的现象,但是作为企业的HR,技术经理甚至老板你可以选择不要他啊。这篇文章只讨论一般的APP开发,脑残的APP开发不在此文范畴。
1.大环境
首先我们说说大环境,现在是互联网时代,你别跟我说什么资本寒冬,在2008年经济危机时,也没见哪个程序员饿死了。资本寒冬只是暂时的,从2010年到现在死的互联网公司多了去了,又会有无数的互联网公司站起来。人们已经离不开互联网和手机了,做为必需品你觉得会破灭吗?就如同北上广的房子一样,08年说泡沫,现在这么多年过去了,谁还会相信这是泡沫呢?
2.App开发
接下来我们说一说安卓开发和iOS开发,windowsphone我们暂且不谈,这家伙10年就说要干掉安卓,也就过过嘴瘾。
我现在引用一篇文章的看法:”泡沫,毕竟是泡沫,终有爆破的那一天。这个时间不会很长,3到5年。随着新技术慢慢变旧(当Android和iOS变成和C语言一样老),随着大批量的人才涌入和一些公司退出(十万开发者面对一千岗位),随着很多老板慢慢发现原理和真相(APP真的只是个终端)。” 一看就外行人写的,还说当Android和iOS变成和C语言一样老,现在写C,C++赚的不比App少,Java老不老呢?2010年做Javaweb的优秀开发月薪2W+,再说Android和iOS不是语言不能和C语言比较,我牙都笑掉了。在此我们只能看到这是外行人眼红App开发工资比他高,他又转不了开发罢了,和windowsphone一样也就过过嘴瘾。
3.安卓和ios灭亡
有不少眼红的人希望Android和iOS灭亡,就像塞班一样,看Android和iOS灭亡了你们怎么办?笔者的同学以前做塞班的,塞班灭亡了他转做iOS,现在一样很牛逼,因为人家C++强,转iOS有优势。同样如果安卓灭亡了,安卓开发可以转Java,iOS。其实年轻的App开发不用担心这些,当你的技术达到一定层次,语言已经不是阻碍我们的脚步了,笔者1周就学会obj-c,写iOS代码了。同时也给年轻的App开发建议就是要注重基础,安卓和iOS只是武学招式,真正使他们发挥威力是你的内功,也就是你的基础。
4.互联网职位稀缺性
一个优秀的程序员是十分难求,他不是去熬年头就能得到的,他需要付出很多,阅读很多书籍,看过很多技术文章,敲过很多高质量的代码,无数个Bug折磨过的,一步步才培养起来的,反观其他的互联网职业我就不便多说什么了,优秀的是有,但更多的是熬年头拼学历,他们所付出的努力远远没有优秀程序员付出的多,他们所创造的价值也未必有他们想象的大。现在有产品思维能言善辩的App开发越来越多,他们可以去抢产品经理的饭碗,但产品经理很难抢程序员的饭碗,这也说明了优秀App程序员的稀缺性。现在我在招聘网上找一个3年以上经验的安卓开发都很难,就算找到了也很容易被别的公司抢走。现在市场上最多的是1到2年的App开发,还有一些从别的行业转过来的App开发,靠谱的很少。
5.提升自己让别人去喷吧
我们中国人的一大劣根性就是见不得人好,这是正常现象,那么怎么提高自己使得自己更强,让别人更眼红呢?
看清自己并尽早规划职业生涯
早看清自己的人早确定方向,看到自己的优点避开缺点,如果你热爱开发你就继续干开发成为App架构师。如果你能言善辩,组织能力强又敲的一手好代码,那就去做技术经理。如果你只是为了钱而不喜欢代码,那你得想办法尽快脱离这个行业。
如果闷头去敲代码这显然是大部分程序员都能做到的,但是你有没有想过程序员这个职业可以做一辈子嘛,早做打算并且要对自己的职业生涯负责,找到自己的本性和擅长并发掘自己的潜力,从而决定自己是做个技术经理、架构师还是个什么其他相关的职业,工作多年如果还是和刚入行的干一样的活这显然不会提升自身的价值也迟早会被这个行当所淘汰。
做有产品思维的程序员
平常多看看其他的App是怎样的,和自己的对比下,每做一个需求要考虑它是否是必须的,能为用户带来什么,而不是产品经理让做什么就做什么想都不想。
业余多看书,多写代码,写技术博客,找到适合自己的学习方法
想要脱颖而出你不付出努力又怎么能行,平常可以写一些自己想写的代码,把他写到博客上或者建立自己的代码库,写博客可以提高自己的写作能力同时也检验你的技术的掌握程度,你会发现你为了写一篇技术文章会查很多资料看很多书,遇到很多的坑,这是你去看别人的技术文章所得不到的。技术首先要做到先精,再做到广,什么叫做精,至少我现在的也不敢说精通Android,不会的实在是太多了。而我现在看到的就是很多开发什么都想搞,结果什么都搞不明白,今天学了Android,明天看看iOS,后天H5和RN火了又都去学,结果什么都不专什么都不精,知道慕容复嘛,会的再多也打不过专精一门武学的乔峰吧。只有你先精一门的前提下再去深入的研究其他的技术这才是对的。不要跟我说什么全栈工程师才是未来的大势所趋,才是王道,跟我说这个首先要明确什么是全栈工程师?全栈工程师至少要精通一门,会一堆技术结果全是半吊子也好意思说自己是全栈?作为Android开发多看看底层的源码,Java的基础,设计模式和算法以及iOS的基本知识。更重要的是在学习的过程中找到适合自己的学习方法,比如我就是多看书,然后敲一敲自己喜欢的代码,写博客总结归纳。关于书,我建议大家还是多多宜善,不仅仅限于专业的。古时文人为了一本书可以受饿攒钱去买,但现在的大多数人,在吃穿玩上花了很多的钱,唯独在书上却斤斤计较,希望大家都能养成爱读书、读好书的好习惯。
提高自身形象,培养软实力
App程序员同时也需要跟别人打交道,至少要穿的得体干净,别自己舒服却让别人不舒服。多培养自己沟通的能力,多想想其他人是怎么想的,培养自己的同理心,管理好自己的情绪,学会什么时候该发火,什么时候该淡然一笑,学会对着那些令人无比生厌的小人报以自然的微笑。网上讨论什么牛逼的人应该脾气好,但我不这么认为,该霸气时就应该霸气。如果我们程序员能言善辩,精通业务,人际关系好,人脉广,并且还能敲的一手好代码,这绝对非常恐怖。
保持良好的技术敏锐度和前瞻性
作为一个开发,技术的敏锐度和前瞻性是极其重要的。做技术难免会遇到技术的更新和新技术的出现,如何去选择变得极为重要,因为人的精力有限,这一点选择远远要比努力重要。首先要选择自己擅长的那门技术相关的新技术来进行学习,接下来再考虑其他的新技术。说到其他”新”技术,不得不提到H5和RN,作为一个移动开发者和一个手机用户,并不看好这两门”新”技术。从用户的角度来看,我们更追求高品质和最好的体验,显然H5和RN都无法达到这一点,另外想想PC端也出现了很多web应用,但至今都不温不火的,因为体验太屎了,我宁可下个客户端也不会在web应用上做操作。总结一句,就是H5难成大器。作为一个开发者,H5只适合一些商城或者广告类的界面,它只是一种解决方案,想要拿它做App那太扯了。有人在2011年就说H5是趋势是潮流,过了5年还在说,是不是等我退休了你们还在说H8是趋势呢。至于RN,可能未来会有一些进展,国人太喜欢炒作也太浮躁,Android和iOS都有自己的成熟的开发框架,非要在此之上罩上一层去写js,感觉就像是不脱裤子拉屎一样(我实在找不到很好的形容)。用你们的脑子想想,未来人们追求的是什么,是极致和高品质,为了所谓的商业模式来应付用户群体必定走不远,当然想捞一票就跑的可以忽略极致和高品质这个问题,用户不会关心你用了什么技术,他们只关心好不好用。不好用的直接扔垃圾箱里,好用的就算时常让他们下载新版本也会有人用。总结一句,RN可能就是一个搅屎棍,它的出现可能会让很多人趟浑水并且浪费很多时间。对于RN现在我也是持观望态度,因为我发现真正重要,能让我走的更远的是基础和深度,而不是这些前途不明的潮流框架。总之,对于新技术要有自己的判断,不要听风就是雨。
选择好平台,不要计较一时得失
在好的平台才能得到最大的利益,才会发挥自己最大的能力,相反在差的平台以及不适合自己的岗位上就算再努力也白费,除了你手里那点钱什么都得不到,还会赔上最有价值的青春。有时要学会放弃,面对不好的平台、不适合自己的岗位当断则断,计较一时的金钱得失可能会葬送自己整个人生。就好比金子扔进茅坑它永远不会发光,一个铝片放在舞台上却能够闪光,不管我们是金子还是铝片一定要区分茅坑和舞台。既要活在当下同时眼光也要放远。
去做去行动
大道理很多人都懂,为何脱颖而出的就那么几个人,因为他们不只懂而且也去做了
笔记体系
自己生命、生活和人生的设计师
鲍勃·马丁大叔(Bob Martin)是软件开发理论的巨头之一。他提出的程序员誓言,是这个行业的基本职业道德。

誓言由关于软件开发人员的九个道德目标组成。
为了捍卫和维护计算机程序员的职业荣誉,我承诺,尽我所能和判断力:
1、我不会产生有害的代码。
2、我制作的代码永远是我最好的作品。我不会故意允许在行为或结构上有缺陷的代码。
3、每次发布时,我都会生成一个快速、可靠、可重复的证据,证明代码的每个元素都应该正常工作。
4、我将经常发布小版本,这样我就不会妨碍其他人的进展。
5、我会抓住每一个机会,无畏地,不懈地改进我的代码。我永远不会损害它们。
6、我将尽我所能保持自己和他人的生产力。我不会做任何降低生产力的事情。
7、我将继续确保支持其他人的工作,并且他们也可以支持我的工作。
8、我将对幅度和精度做出诚实的估计。我不会作出做不到的诺言。
9、我将永远不会停止学习和改进我的手艺。
一家数据公司称,2018年全世界的软件工程师有2230万人,中国有190万。

Standing on Shoulders of Giants
站在巨人的肩上,才有可能在有限的时间里取得最大的成绩…
发现趋势,追随趋势,顺势而安、乘势而起、造势而雄,不做旁观者,要成弄潮儿
如果进入了痛苦的高原期,请记住:付出与收获成正比,成功之路本身就不轻松,与戴皇冠必承其重,
此时,你需要坚信自己的判断和选择,坚持、坚持再坚持,基于量变到质变的法则,
一般都会“踏破铁鞋无觅处,得来全不费工夫”,届时,”待到山花烂漫时,君在丛中笑”。
学之者不如好之者,好之者不如乐之者,兴趣是最好的老师
化整为零,先易后难,循序渐进,各个击破,坚持是成功的密码,自胜者强
若贪多求快,则欲速不达
若聚焦极致,则迎刃而解
别急,慢慢来,一切都来得及
架构思考、动手实践、检索分析、复盘总结、循环递进
Why
C语言——了解计算机底层技术原理,数据结构+算法;
Python语言——AI的有力工具;
Kotlin JAVA——Android应用语言
德国工业设计大师 Dieter Rams 是功能主义的坚定信徒,他的设计理念就是他的名言:”少,但更好”(less but better)。
– 《伟大的产品做得少,但更好》
一个函数如果有多个同类型的参数,比如两个参数都是字符串f(string A, string B),作者认为必须警惕,因为容易误用,必须查文档才能分辨每个参数的含义。所以,函数定义时最好避免同类型的参数。
我为什么喜欢编程
作者: 阮一峰
日期: 2009年10月18日
这个周末,我在家核对More Joel on Software的最后定稿。
此书已经在申请书号了,一拿到书号,就可以印刷和销售了。所以,不出意外的话,年底之前就能上架。
在复核的过程中,我又读到了书中让我最有共鸣的一段话:Joel谈为什么公正对程序员很重要。
我不知道别人的情况,我自己喜欢编程,很大的原因就是觉得程序的世界更公平公正,谁对谁错,只要运行一下代码就知道了。这同现实世界截然不同,在现实的世界中,只要你有权有钱,善于搞人际关系和钻制度的空子,你就能把错的说成对的,把黑的说成白的。老老实实、埋头苦干的人,眼睁睁看着乾坤颠倒、小人得志,而只能束手无策、一筹莫展。
我们生活的这个国家,是一个禁止自由思考、党决定一切的国家。在这里,如果你想不撒谎、不干坏事、并且被公正地对待,那么可能你只能去编程了。
==================
不搞政治
作者:Joel Spolsky
译者:阮一峰
老实说,只要有两个以上的人待在一起,就会有政治。这很自然。我说”不搞政治”的真正的意思是”不搞恶性的政治”。程序员早就练出了对公正有非常良好的判断力。代码要么能运行,要么不能。坐在那里争论代码是否有问题,这是毫无意义的,因为你可以运行代码,答案自然就有了。代码的世界是非常公正的,也是非常严格有序的。许许多多的人选择编程,首要的原因就是,他们宁愿将自己的时间花在一个公平有序的地方,一个严格的能者上庸者下的地方,一个只要你是对的就能赢得任何争论的地方。
如果你要吸引程序员,你就必须去创造出这样一个环境。当一个程序员抱怨”人际关系复杂”时,他们的意思明白无误,就是指任何个人因素超过技术因素的环境。程序员在完成手头任务时,不被允许使用最合适的编程语言,而是被命令只能使用另一种特定的语言,原因仅仅是老板喜欢这种语言;没有什么比这更让人气愤了。晋升的原因不是成果,而是人际关系;没有什么比这更让人抓狂的了。程序员被迫去做技术上落后的东西,仅仅因为上级或者得到上级支持的人坚持这样;没有什么比这更让人发火了。
没有什么比因为技术原因赢得一场由于政治原因本来要输掉的争论更让人心满意足了。当我在微软公司刚开始工作的时候,有一个正在开发中的大型项目走入了歧途,项目的代号是MacroMan,目标是创造一种图形化的宏语言。真正的程序员遇到这种语言会很有挫折感,因为图形的特性让你真地没有办法完成循环和条件判断功能。此外,对于那些非程序员的用户,这种语言也不会有很大作用,因为我觉得那些用户不会习惯算法思维,没有办法很快地理解MacroMan。当我说出对MacroMan的负面评价时,我的老板告诉我:”如果火车要出轨,没有东西能够阻挡。算了吧。”但是,我还是不放弃,一再地不断地争论。那时我刚走出学校,在微软公司中差不多跟谁都没有利害关系,所以,渐渐地,人们开始倾听我的核心观点,MacroMan后来终止开发了。我是谁并不重要,重要的是我是对的。非政治性的组织就应该这样,这种组织才会让程序员感到高兴。
总的来说,关注你的组织的社交动态变化,对创造一个健康的、令人愉悦的工作环境是很关键的,这样可以留住程序员和吸引程序员。
为什么Joel不谈软件了?
作者: 阮一峰
日期: 2010年3月16日
3月初的时候,Joel发布了一个惊人消息(中文版见下文)。
他将不再写作网志了!就在3月17日,”Joel谈软件”开张十周年的纪念日,他就会停止自己的写作。
全世界排名第一的程序员网志要关门了?我简直不敢相信,不知道3月17日他会怎么告别,只能心神不宁地等着那一天。
结果昨天晚上,Joel出人意料地贴了一篇新文章,做了一些澄清。
首先,关于软件开发的文章,确实不会再写了,因为除了声明中提到的原因,Joel感到他已经有点在重复自己了。其次,讨论技术细节的文章,以后依然会写,比如Mercurial教程。最后,近期还会有一篇关于Twitter的文章,已经写了一半。
我对此感到很可惜,又一个自己喜欢的作者要从网上消失了。而且,Joel的风格太独特,将来恐怕不会再有这样的人了,滔滔不绝地把自己对软件开发的想法写成1000篇文章,免费给大家看,一写就是10年,而且写得那样生动活泼、富有启迪。这样的事情只可能在互联网诞生的初期发生,只有那种时候,才会让人产生异乎寻常的创造力和热情,因为无论你做什么,都是前无古人的,你都是在创造。等到网络模式成熟了,大家也就司空见惯了,没有太高的热情了,一切都是循规蹈矩。另一方面,我也很高兴,幸亏自己翻译了Joel的一本书,否则未来恐怕不会遇到这样的机会。
下面就是Joel告别Blog的声明,像他的其他文章一样,包含着令人深思的观点,非常值得一看。不知道这是不是最后一次我翻译他的文章了,但愿不是吧。
=======================
告别网志的时候到了
作者:Joel Spolsky
译者:阮一峰
发表日期:2010年3月1日
出处:inc.com
你创立了一家公司,做出了一种优秀的产品,现在你需要把消息传播出去。但是,你没有钱买广告,也没有钱雇佣公关公司,你的预算最多只够雇一个销售员。然而优秀的销售员都是聪明人,不会糊涂到愿意为你这样的小公司工作。
所以,你总是会想到网志。
当前,好像每一个初创公司,都有一个自己的网志。但是,其中99%都有问题。什么问题呢?那就是他们在网志中只谈自己,发一些招聘消息,展示一些新产品,秀一下员工一起野餐的照片。这样的文章,看上去当然很可爱。你的亲爱的妈妈,肯定很喜欢读。但是糟糕的是,除了你的妈妈,其他人都不感兴趣。大多数的企业网志,几乎没有任何读者,没有访问量,对销售也毫无影响。长此以往,网志的更新也越来越少,间隔的周期越来越长(如果撰写网志的责任由多个员工承担,情况就更是如此),最终网志就变得荒芜了。
我开始写”Joel谈软件”的时候,几乎没什么人写网志。那是10年前的事,那时我甚至还没有成立自己的公司。我的网志很快就在程序员中变得流行了,上面有各种各样的内容—-如何写出漂亮的代码,如何在短得不合理的时间中拿出产品,如何得到更多的薪水等等。访问人数一直在上升,到了后来,一个月的独立访问者超过100万人。它也使得人们对我的公司”Fog Creek”和我们的产品,产生了兴趣。
那么,企业网志的成功秘诀是什么?怎样才能把网志转化为影响力、销售额和利润?其实,我自己都不太清楚应该怎么做。直到去年,我参加了一个软件研讨会,在会上,一个著名的游戏开发者Kathy Sierra做了一个发言,我听了以后茅塞顿开。她讲了一个很简单的观点,完全解释了为什么我的网志能为我带来商业成功,而其他那么多公司的网志都做不到。
根据她的观察,要让企业网志真正有影响力,就必须谈一些比你的公司、你的产品更大的东西。这听起来不难,但是实际上不是,你需要严格的自律,不谈你自己和你的公司。表面上,网志似乎是一种个人化的媒体,很多时候确实如此。但是,Kathy Sierra说,一旦你使用网志来推广企业,你就不能用它谈论自己感兴趣的事情。你必须谈一些你的读者愿意看到、或者希望看到的东西,这样他们才会变成你的客户。你必须让你的读者感到满意。
举例来说,如果你销售的是照相机的闪光灯,你就不要去谈产品的技术细节,也不要去谈旺季的促销计划(优惠10%!)。你要介绍拍出优秀照片的10个窍门。
如果你开餐馆,网志就不要介绍你的菜单,而要介绍一些好吃的食品。你这样才能吸引,对你的餐馆不感兴趣的饕客。
如果你生产高档巧克力,就不要在网志上写你去多米尼加共和国收购可可豆的旅程,因为这只对你个人有意义。你应该写详细的教程,介绍如何自己做出草莓巧克力。以后的十年中,任何一个美食家或面包师,想在Google中找到制作草莓巧克力的方法,他就会发现你的文章。帮助你的读者做出美味食品,很可能会吸引来一些这种食品的购买者,这就是一个成功的企业网志的意义。介绍前往多米尼加的旅程,只能吸引那些想去多米尼加的人。除非你是搞旅游的,否则你不应该写这个内容。
回顾起来,”Joel谈软件”实际上是一本内容高度集中、专门写给程序员看的小型杂志,以介绍一些软件开发的实用主义观点为主。我也利用它,为自己的公司做免费广告,但是那些广告实际上更接近社论,而不像商业目的的广告。我写的最受欢迎的文章,都与我自己和我的公司无关,比如我写过如果软件公司想要重构代码,那么千万不要推倒重来。
一旦大量的程序员成为了我的读者,他们中的许多人就会变成我的公司的顾客。因为读者群实在是太集中了,导致我们公司开发的产品,只有供程序员使用的才会成功,其他的都不成功。那些都是很优秀的产品,但是就是不成功,因为它们不是供程序员使用的,而我们又没有能力将它们推广到非程序员的目标客户中。
当然,网志占用了我大量时间。它是一种劳动密集型的手工推销方式。合计起来,我用来做自己的网站、写作相关书籍、录制视频、参加网志会议等等的时间,大约占到过去十年我创业总的投入时间的三分之一。那也就是整整三到四年的工作量。
这样做是否值得?你也应该这样写网志吗?
这样说吧,我很受用这个方式,但是当我观察其他人越多,就越发现很多成功的初创公司,不把大量早期创业时间用来架设一个受欢迎的网志,结果也能得到客户,并且快速地发展起来。
而且,更麻烦的是,除了我自己之外,我真的找不到其他任何通过写网志而获得成功的企业家。
过去十年的大热门技术公司,往往都没有一个像样的网志。Twitter、Facebook、Google的网志,都充满了喋喋不休、乏味透顶的新闻稿,最多只是略加改写,好让文章看上去不是那么一本正经。Apple公司实际上根本没有网志,哪怕它开发出了好几样优秀的革命性产品。同时,微软公司倒是有相当一大批很不错的网志,但是毫无作用,这家公司还是给人一种笨重迟暮的印象。
所以,我觉得是时候了,应该从网络日志中退休了,能够在狭小美好的程序员世界成为一个互联网名人,已经足够了。3月17日就是”Joel谈软件”开张十周年的纪念日,我将最后发一篇正式的文章。同时,正常情况下,我也将停止录制视频节目和公开演讲。Twitter?”那玩意太可怕了,我不会去玩的。抱歉,我没法只用140个字母,就告诉你原因。”
真正原因是,虽然我一如既往喜欢写Blog,但是我的时间越来越少了,因为Fog Creek正在不断发展壮大。我们现在有32个雇员,以及至少6条正式的产品线。我们的顾客也已经多到令我无法自由写作的地步,我很怕自己漫不经心写出的一句话,会侮辱到某位顾客。我的日常工作占用了大量时间,以至于无法集中精力,写作一点有思想性的东西,哪怕每个月只写一篇到两篇。
大量证据也表明,推广Fog Creek的产品有很多有效的其他方法。过去,我们倚重网志作为营销渠道,忽略了其他方法。我现在意识到,网志使得我和Fog Creek,成为了一个很小的池塘中的大鱼。结果就是,对于那些经常阅读网志的5%~10%的程序员来说,我们是无可争议的头号产品。同时,对于除此之外的每个人,我们完全是默默无名的。
我希望,放弃网志就好像让一个双眼发展不均衡的孩子,戴一付眼镜。是时候让那只好的眼睛休息一会,而让那只比较弱的眼睛有一个成长的机会了。我的公司需要证明一点,就是我们不依赖于单一渠道推广自己的产品,这是任何一家其他公司都已经明白的道理。在目标市场的一个细分领域中,我们已经彻底做到饱和了,现在我们不得不去大得多的其他领域,寻找更多的潜在顾客。
对于我的读者,感谢你们过去10年中对我的关注。没有你们,我不可能做成这个网志。感谢你们高质量的Email、留言、twitter发言、评论文章,所有这一切使得我的过去10年成为一次美好的旅程。我很享受我们在网上形成的这种关系,期待未来在我的公司的某个发展阶段,我能够与你们有面对面的交流。
等几年,再用新框架
在技术领域,每个月都有一个新框架。例如,iOS 就有一个新的 UI 框架 SwiftUI。
我的建议是,等待几年再去学习它。不要担心会错过机会,这不是飞机航班,你仍然随时可以登机。任何时候,你都不应该因为害怕落后于潮流,而做出决定技术决定。如果你学习一个 UI 框架,它就应该对你的业务带来帮助,而不是为了学而学。

新技术总是被其制造商大肆宣传,他们不会说:”我们的新东西是平庸的”,他们有动机大肆炒作,以光彩照人的方式谈论自己的产品,这对他们有好处。一些在职业生涯早期的开发人员,也会加入炒作,他们是第一次见到这样的东西,因此非常兴奋。总之,新框架总是有自己的支持者,你问他们这个框架好不好,他们总是会说这很棒。
但是,新框架总是有这样或那样的问题,很少像承诺的那样好。它在某些方面可能会很好,而在其他方面则很糟。文档通常不完整,如何有效使用框架也没有形成规范。一旦你使用了它,团队的其他人也必须学习它,才能让整个团队适应你的代码,这给团队带来了额外的负担。因此,等待几年消除所有这些问题是有意义的。
如果你急于采用一个框架,可能会花费很多时间来研究它,之后很可能会发现,它根本不起作用。或者它确实有效,但不适用于你。再或者它以某种方式工作,但在性能或者向后兼容性上有严重问题。新框架就是一个未知数。
如果你采用了新框架,结果它无法正常工作,而你又必须切换回去,就要付出两次过渡成本。
新框架的出现并不会立即使旧框架过时。例如,Swift 1.0 是2014年发布,但真正可用是在2016年。这也不意味着你2016年就要使用它,因为2016年的版本是最早可投入生产的版本,真正成熟可能要等到2018年的版本。因此,新的语言、工具或框架不会淘汰旧的语言、工具或框架。过渡期会有很多年,在此期间,你可以随时采用新技术。没必要在出现的那年就赶上潮流。

为什么大多数程序员都是男的?

有个现象你肯定也留意过,那就是,程序员、科学家这些职业一般都是男人的天下,很少有女性,这是为什么呢?有本书叫《是高跟鞋还是高尔夫修改了我的大脑》,作者就提了个观点,说之所以女程序员、女科学家比较少,跟性别差异啊大脑结构啊能力啊统统没关系,完全是外界环境和心理因素造成的。比如,咱们一般都觉得,搞计算机、编程序的人,都有些极客风格,喜欢独来独往,黑白颠倒,沉闷孤僻。你想,女生们谁想被看作是这种人呀?华盛顿大学就曾做过一个实验,测试大学生对计算机科学的兴趣。他们专门布置了两个教室,一个是典型的极客风格,什么《星际迷航》海报、快餐、电子产品、技术类图书等等,满屋都是;而另一个教室就是很普通的房间。结果发现,在极客风格的教室里,男生比女生对计算机科学更感兴趣。但在另一个普通房间,男生和女生对计算机的感兴趣程度几乎一模一样。这就说明,你选择从事哪份职业,受外界环境影响很大。极客风格的房间就会给女生一种心理暗示:计算机科学是属于男孩子的,根本就不适合我。`
另外,自我评价也很重要。有科学家曾调查了几万名学生的学习成绩,以及他们对数学能力的自我评价。结果发现,在实际成绩差不多的情况下,男生对自己数学能力的打分却比女生高出一大截。这是因为,社会上普遍认为男生更擅长数学,所以他们就会美化自己的数学能力,将来就更有可能从事科学、数学相关的工作。其实,跟女生相比,他们并不是真正擅长数学,而是觉得自己擅长而已。
所以你看,女性很少选择计算机、科学职业,不是因为她们能力不行,而是外界环境和自我认知造成的。这就像是以前大家都有一种偏见,觉得女性只能当家庭主妇。可后来人家走向职场,不照样也很成功吗?
本文源自:《是高跟鞋还是高尔夫修改了我的大脑》
我希望程序可以更短,不是以行数或字符衡量,而是以解析树衡量。
– 保罗·格拉汉姆(Paul Graham)。他已经54岁了,发布了一门自创的计算机语言 Bel。有人问他目的何在,他做了上面的回答。
程序员真的需要高智商吗?
你一定很聪明吧!?你数学一定很好吧!?你的逻辑思维一定很强吧!?我觉得你们程序员都很牛逼!
绝大多数程序员都被问过这种被直接带有肯定的问题。自己即使嘴上回答 “不是啦”,可是心里还是很骄傲。
我以前也这样,现在变成熟后就不这么认为了。
程序员真的需要高智商吗?
我认为不需要。人类发明编程,就是想用编程来弥补人类的大脑缺陷。
在编程技术刚被发明时,程序是用来帮大学教授做科学计算的。随着硬件的发展,程序的应用越来越广泛,除了科学计算外,还可以在办公、医疗、航天等多个领域发挥其价值。
人类要开发大量具体的应用程序,编程语言从机器语言往高级语言发展就成了必然趋势。编程语言越接近高级语言,就越符合人类的思维方式。
从简易程度的角度来看,编程语言发展到高级语言后,编程这件事情就变得更容易了。
随着近些年开源软件的发展,大量优秀的开源软件把创造应用程序这件事情变得更简单,甚至可以说是 “傻瓜式”。如果你在今天想创建一个 Web App,一分钟就可以搞定。
编程过程变简单了,用编程方式来创造应用也变简单了,程序员的工作是不是也就变简单了呢?答案是肯定的。
我刚参加工作时,参与开发一个通讯录(BREW 操作系统上的应用),公司投入了 30 多个工程师。
如今,在 Android 操作系统上开发通讯录(甚至功能更完善),只需要投入 2-3 个高级工程师即可。这种变化并不是说以前的工程师比现在的工程师能力差,而是现在的开发过程变得更简单了。
在日新月异的技术发展过程中,我在招聘工程师的态度上也发生了变化。
我以前比较注重项目经验(很多公司在招聘时会应聘有过类似项目经验的候选人),现在我更看重面试者的谦虚和处理细节的能力。
2016 年我面试了 40 多个程序员,其中有两个同学让我印象深刻:
典型1:他很聪明,但不具备创造能力
在被淘汰的人中,有一个同学在学校期间就自学 Android。他给我展示了五个 Android 应用,并很自信地对我说:“这都是我一个人以外包身份给某公司开发的。”
刚开始我和他做了一些简单的交流:
Q: 你开发能力这么强,对薪水的预期是多少?
A: 20K。
Q: 你的基础怎么样?
A: 我是自学 Android,基础可能不是很好,但是我的动手能力很强。我可以一个人完成一个项目。
Q: 你平时写代码时遇到问题都是怎么解决的?
A: 网上找答案。
Q: 在运用一个 Activity 中,你了解里面存在多少种设计模式?
A: 我只听过设计模式,但没去看,以后打算看。
Q: 你最近一个项目中,用到的一个最熟悉的开源项目是什么?
A: Rxjava(作者注:Android 一个开源库)。
Q: 你能给我阐述一下 Rxjava 的思路吗?
A: (他把用法给我讲了一遍。)
Q: 这个用法的背后知道为什么吗?
A: 不知道。
后面我问了很多他在工作中实际用到的一些技术,基本上是知道怎么用,但不知道为什么。
从动手能力方面来看,他就是人们传统认为的那种 “聪明” 的人。从他脸上流露出的自信我相信这些应用都是他做的。但是,基于以下几点我淘汰了他:
1.基础很差。他虽然动手能力很强,但是对技术细节不理解。
2.写代码靠模仿。他对代码的认知还停留在 copy 和模仿阶段,如果不参考事例,就不会写代码。
3.创造力差。他适合一个萝卜一个坑的小公司或外包公司,但不适合创业公司,员工的创造力是创业公司渴望获得的。
4.有点骄傲。他可能认为自己是属于 “聪明” 那类的,而且不能发现自身的缺点、以及不太能接受别人对他的评价。在管理上会带来风险。
互联网行业中,很多工程师和这位同学一样。这类同学统一犯了一个错误:被”简单”的技术蒙蔽了双眼,使得找不到进步方向和空间。
典型2:他很踏实,而且很有想法
这位同学是一位 C++ 工程师。
我并没有从基础技能入手,而是直接了当地把想招他进来做什么事情告诉他。他刚开始显得很紧张,可能是觉得我面试的套路很奇怪吧。
我为了调节气氛,就在白板上画出我的想法。在不断地沟通后,他似乎明白我的意思,思考了一会儿就在黑板上画出了解决方案。
他提出的解决方案非常初步。虽然从大面上看似能走通,但是关键点和细节点都无法体现。我紧接着围绕方案提出了一些问题,他都能不紧不慢地一一解答。
为了了解他技术的深度,我开始围绕方案问技术的实现细节。比如,模块间的通信机制、事件队列的处理方法、数据共享的方式以及网络交互的实现细节等等。
这些技术细节非常考验局部架构能力,但他都能说出自己的见解。
我们最终讨论出了一套方案,并整理出了技术的难点。整个面试过程就像是一个方案讨论会,非常地自然。
在最后,我问他对这件事情有信心做吗?他的回答大致如下:
这件事情会很难,而且很多东西都没接触过。但是事情是可以的,也有价值。在具体实现上会遇到很多技术难点,需要花时间,但一定能做。
他虽然没有正面回答问题,但是我很满意。主要因为两点:第一,他能正确认识到事情的难度;第二,他不惧怕挑战。
至于信心这东西,和决策者的坚定目标有强烈的关系,团队的管理者有足够强的目标,同学们就会有足够的信心。他既然不惧怕挑战,在后续工作中我要不断为他输入信心。
面试结束后,我录取了这位同学。基于以下理由:
1.理解力强。他能非常快速地理解我的问题并作出回答。
2.想问题全面。他能由大面到小点,循序渐进改进解决方案。
3.勇于承认不足。虽然他面对没接触过的技术会主动承认不会,但还能提出个人观点。
4.善于发现细节。他非常善于捕捉设计方案的细节,提出的某些细节都直接关系到方案的成败。
在平时编程工作中,一个工程师是否厉害,并不能简简单单从代码能力一个点上来衡量,而是要结合场景。
这些场景包括:对所做事情的理解、对未来的把控、对异常的避免以及细节的处理。
聪明和优秀程序员之间并无太密切的联系
前面提到过人类发明编程是为了弥补人类的大脑缺陷。人脑的使用度是有限的,学习久了要休息,工作久了要休息,想多了要休息。休息大脑无关于你的智商是高还是低。
为了减轻程序员大脑的负担,编程从机器语言发展到高级语言做了大量的改善,而且很多改善都是为了弥补人的智力缺陷。不信你看:
1.将系统 “分解”,易于人脑理解。
2.将子程序写得短小,减轻大脑负担。
3.基于面向对象编程而不是过程编程,易于人脑理解。
4.微服务化,减轻维护压力,减轻大脑负担。
5.制定各种编程规范,将思路从繁琐的编程中解放出来,避免犯错。
6.进行审查、评审和测试的流程,避免犯错。
也许有人会说更高的智商在编程上会有更好的作用。衡量一个工程师的水平高度不应该站在人的角度,而应该站在处理事情的角度。
高智商的工程师可以写出更复杂无 bug 的系统,这确实是真的。但是写出的程序如果没有人能懂,没人能继续维护,这个复杂无 bug 的系统的价值就要大打折扣了。
千万别忘了,评价一个系统的好坏除了能正常运行之外,还要考虑可扩展性和易维护性。你考虑得越多,就需要你越注重细节处理。
如果你想学习编程,或者你正在学习编程,下面的建议可能对你有用:
优秀的程序员和高智商无太密切的联系。你越谦虚,进步就越快。
如何执着地用聪明的方式去处理事情,比你有多聪明更重要。
要想懂怎么写出优秀的代码,就得具备非常强的吸收细节的能力。
最后一点更重要。
不要轻易否定自己,你一定也能学会编程。
What
雇主最看重的是解决问题的技能,而不是编程语言的熟练程度、调试能力和系统设计。
新程序员犯下的最大错误就是专注于学习语法,而不是学习如何解决问题。
– 《解决问题的经验教训》
作者列出心目中最佳 CS 书籍,分成编程、算法、语言、系统和网络五个部分。
Flex & Bison
2018-09-09
flex & bison 不仅可以进行语言的词法和文法分析,还可以接续几乎所有的结构化文本。
简介
Flex
Flex是一个词法分析工具,词法分析可以称为lexical analysis,或称scanning;
词法分析把输入分割成一个个有意义的词块,称为记号(token);
Bison
Bison是一个语法分析工具,语法分析可以称为syntax analysis,或称parsing;
语法分析主要是确定词法分析记号(token)是如何彼此关联的;
基本所有的编译器项目中,都会使用lex或者flex做词法分析,并利用Yacc或者Bison对词法分析的结果进行语法分析。
flex和bison最早是用来生成编译器的,他们具备处理结构化的输入的能力,后来发现他们可以用在很多地方,例如解析css文件、json文件、XML文件等。
语法
上下文无关文法
当我们编写一个语法分析器,就需要我们用一定的方法来描述记号转化为语法分析树的规则。
这种描述的方法在计算机中最常用的就是上下文无关文法Context-Free Grammar。
上下文无关文法就是说这个文法中所有的产生式左边只有一个非终结符。
例如下面这个就是上下文无关文法
1 | S -> aSb | ab 这个文法产生了语言 {a^n * b^n : n ≥ 1} |
这个文法有两个产生式,每个产生式左边只有一个非终结符S,这就是上下文无关文法,因为你只要找到符合产生式右边的串,就可以把它归约为对应的非终结符。
要理解什么是上下文无关文法,可以先感受一下上下文有关文法,例如
1 | S -> ab |
这就是上下文相关文法,因为它的第一个产生式左边有不止一个符号,所以你在匹配这个产生式中的S的时候必需确保这个S有正确的“上下文”,也就是左边的a和右边的b,所以叫上下文相关文法。
因为上下文无关文法有足够强的表达力来表示大多数程序设计语言的语法,上下文无关文法又足够简单,使得我们可以构造有效的分析算法来检验一个给定字串是否是由某个上下文无关文法产生的。
BNF文法
为了编写一个语法分析器,需要一定的方法来描述语法分析器所使用的把一系列记号转化为语法分析树的规则。在计算机分析程序里最常用的语言就是上下文无关文法(Context-Free Grammar, CFG)。书写上下文无关文法的标准格式就是Backus-Naur范式(BackusNaur Form,BNF)。
BNF文法用起来是非常简单易懂的,例如我们可以用下面的表达式来表示 1 2 + 3 4 + 5:
1 | <exp> ::= <factor> | <exp> + <factor> |
每一行就是一条规则,用来说明如何创建语法分析树的分支。
有效的BNF总是带有递归性的,规则会直接或者间接地指向自身。
Flex语法结构
以最简单的word count的程序word_count.l来看
1 | %{ |
1 | %% |
1 | int main(int argc, char **argv) |
MacOS下编译代码命令
1 | flex word_count.l |
变量声明
声明部分可以进行声明和选项设置。
可以在%{和%}包围的部分里面定义c代码,里面的内容会被完整地复制到lex.yy.c 的开头,通常会用来放置include、define的信息。
规则定义
规则声明部分被两个%%包围,规则为
正则表达式 {匹配到之后执行的C代码}
例如:
1 | [a-zA-Z]+ { words++; chars += strlen(yytext); } |
在任意一个flex的动作中,变量yytext总是被设为指向本次匹配的输入文本。
前面的部分就是模式,处于一行的开始位置,后面的部分就是动作,也就是,输入中匹配到了这个模式的时候,对应的进行什么动作。
yytext,在输入匹配到该模式的时候,匹配的部分就存储到yytext里面。
C代码部分
这部分是C代码,它们会被复制到lex.yy.c的最末尾。
程序主要由一系列带有指令的正则表达式组成,这些指令确定了正则表达式匹配后相应的动作(action)。
Bison语法结构
bison的语法规则也分为三部分,以flex 和 bison协同的计算器程序为例
flex部分:创建calculator.l并声明
1 | %{ |
1 | %% |
bison代码:创建calculator.y并编写代码
1 | %{ |
1 | /* declare tokens */ |
1 | %% |
1 | int main(int argc, char **argv) |
声明部分和C代码部分
被%{和%}包围的部分,里面的内容会被完整地复制到lex.yy.c 的开头,通常会用来放置include、define的信息。
除此之外一般还要进行token设置。
token用于标记语法解析中用到的基本语素,教程里称之为“记号”。
用枚举来定义,而且为了避免冲突一般枚举的值从258开始。
语法是:
%token 记号,例如
1 | %token NUMBER |
这里一般是当flex成功匹配到一个模式的时候,会return一个token,然后在bison的规则中查找应该进行的动作。
规则部分
规则部分遵循DNF范式的定义,每一个bison语法分析器在分析其输入时都会构造一棵语法分析树。
在有些应用里,它把整棵树作为一个数据结构创建在内存中以便于后续使用。
在其他应用里,语法分析树只是隐式地包含在语法分析器进行的一系列操作中。
1 | %% |
第三部分是用户自定义代码
以上可以使用如下命令生成编译结果:
1 | bison -d calculator.y |
总结
利用flex & bison 除了可以进行语言的词法和文法分析,还可以接续几乎所有的结构化文本。
关于编程,你应该知道的几件事
网上有个著名的段子:
老婆给当程序员的老公打电话:“下班顺路买一斤包子带回来,如果看到卖西瓜的,买一个。”
当晚,程序员老公手捧一个包子进了家门。老婆怒道:“你怎么就买了一个包子?!”
老公答曰:“因为看到了卖西瓜的。”
搞笑之余,其实也可以看出程序员的思维方式跟普通的思维方式存在差异。
而这种差异,正是编程的奇妙之处。
什么是 “编程”?
所谓编程,从本质上来说,就是学习使用一种特定的语言,来描述现实世界的一个问题,再将这个问题通过计算机的运算,给出分析和解答。
从十七世纪开始,数学家和哲学家就都在探索如何将关于世界的知识归纳起来,并且用一套严谨的符号体系进行表征。
在这个过程中,数学家们奠定了现代编程语言的运算逻辑,而哲学家们则为现代编程语言的面向对象思想奠定了坚实的基础。
大名鼎鼎的艾伦·图灵(可参考电影《模仿游戏》)在此基础上描述了一种通用的计算机模型,图灵机由此诞生。
而后,冯·诺依曼等人用电子管实现了这种模型,这便是今天计算机的雏形。
虽然当时的技术无法达到真正 “人工智能” 的程度,但是时至今日,所有的编程语言依然沿着图灵机原理和冯·诺依曼体系发展。
现代编程语言应该能够完整地描述某一个现实领域的问题,并通过运算规则,操作计算设备获得分析过程和结果。
什么是 “编程思维”?
与人类的正常思维不同,程序的逻辑思维是严谨完善的。截止到目前,机器的宽容度在很大程度上还远不如一个低年龄的儿童。
也就是说,不管多么厉害的代码,一个逗号都不能出错。毕竟编程语言最终要作用于机械,因此编程思维很大程度上是一种线性思维,需要符合机械的流程。
所以,想学好编程,就要养成这种理性的逻辑思维方式,并且建立自己的知识体系。比如可以经常画流程图和时序图,或者编写伪代码来练习。
其实,随着技术的演进,编程已经没有想象中那么难了。越来越多的普通人,只需要经过简单的训练,就可以完成业务逻辑的编码工作。
什么是 “程序员”?
大多数程序小白在遇到电子设备的问题时都会想请教程序员,好像凡是会写代码的,都会修电脑,修手机,修一切的电子产品…… 没错,程序员大多对电子设备有相当的了解和控制力。
程序员,简单来说就是可以控制机器按照自己的意图做事的人。程序员必须具备模块化的思维能力,要能正确评估自己的模块对整个项目中的影响及潜在的威胁。
如今,随着可穿戴设备和智能家居设备的逐步普及,越来越多的传统设备配备了操作系统,成为了可编程设备。也就是说,程序员们可以编写程序改变世界的机会,也越来越多。
什么是 “优秀的程序员”?
另一方面,虽然现在能写代码的人不少,但是能成为优秀程序员的人却并不多。这导致了很多学编程的人找不到工作,同时很多高薪的工作却无人应征。
所以,单纯地解决业务问题,并不能成为一个优秀的程序员。
一个优秀的程序员还需要充分了解你写的代码。
你不仅需要知道写出的代码能够解决什么问题,你还需要知道系统是如何执行代码的,甚至执行代码能给系统带来什么改变。
一个优秀的程序员不仅仅是会编写程序,而且要具备刨根究底的精神,一步步追踪到硬件的执行。
Android开发正在改变日常生活
如果一个程序员懂得 Android 开发,就可以使用程序控制电视定时播放,可以控制智能手表表针的显示样式,可以控制空调的出风温度,可以将手机和门禁连接,可以在汽车的中控台上部署一个程序和手机共享音乐……当前这个 IOT 时代和 AI 时代的程序员,有更多机会可以通过机器改变现实世界。
作为程序员,如今可供控制的机器已经越来越多样化。只要掌握若干种关键技能,就可以很好地在这个机器拼接的世界中游刃有余。
如果您也想用编写的程序改变世界,那么就从现在开始学习编程吧!
我们建议您从 Android 开发入手,毕竟大多数可编程设备采用的都是 Android 系统。
雇主最欢迎的技术技能

美国一家招聘网站统计了,过去五年招聘岗位的技能要求。提到最多的前十位技能如下:SQL、Java、Python、Linux、JavaScript、AWS、C++、C、C# 和 .net。
不过需求增长速度最快的技能,排名完全不一样:docker、azure、机器学习、aws 和 Python。

关于战略问题的通信之六(译文)
作者: 阮一峰
日期: 2009年3月30日
《Joel谈软件》一书的翻译,我好久没提了。
合同规定今年1月交稿。假定我没有违约的话,此书现在应该上市了。可是,实际上……就算到下个月,我恐怕都翻译不完。……我也不想多解释了,反正这本书现在是我最大的烦恼,只能争取今年夏天上市了。
下面的文章是该书的第21篇。
=========================
关于战略问题的通信之六
作者:Joel Spolsky
译者:阮一峰
原文网址:http://www.joelonsoftware.com/items/2007/09/18.html
发表日期 2007年9月18日,星期二
IBM公司最近发布了一套开源Office软件,叫做IBM Lotus Symphony,看上去大概是根据StarOffice[1]修改的。但是,我怀疑起这个名字的真正目的,可能是想清除人们对最早那套Lotus Symphony[2]的记忆。那套软件在发布之前,被吹得天花乱坠,简直就像耶稣要复活一样,但是在发布之后一败涂地。它就是软件业中的Gigli[3]。
上个世纪80年代后期,Lotus公司努力地想找到下一步的方向,升级他们的旗舰产品—-电子表格和作图软件Lotus 1-2-3。他们很自然地就想到了两条路。第一条路是往软件中加入更多的功能,比如文字处理功能。这就是Symphony这个产品的由来。第二条看上去很显然的路,是做一个3D电子表格软件。这就是后来Lotus 1-2-3的3.0版本。
这两条路一开始就遇到了一个大麻烦:在古老的DOS环境中,内存占用不得超过640K。那个时候,IBM已经开始少量出售配备80286芯片的个人电脑,这种新的芯片能够提供更多的内存。但是,Lotus公司觉得,为这种售价高达10000美元的电脑开发专用软件,市场不会很大。所以,他们一个字节、一个字节地压缩,花了18个月,才将Lotus 1-2-3的新版本塞进了640K的内存中。但是,最终在白白浪费了许多时间之后,他们不得不放弃了3D功能,因为没有足够的内存可以塞进去。Symphony的遭遇也差不多,许多功能都被砍得干干净净。
这两条路都走错了。当Lotus 1-2-3的3.0版本上市的时候,每个人家中都已经有了一台80386芯片的电脑,配备了2MB或者4MB的内存。至于Symphony,它的电子表格功能很弱,文字处理功能也很弱,所有其他功能都很弱。
“够了,老同志,”你们会说。”谁如今还关心那些老掉牙的、只能在字符模式下运行的软件?”
请暂且忍耐我一分钟,因为历史正在以三种不同的方式重演。那么,最聪明的应对策略,就是压宝在同样的结局上面。
低速CPU和小容量内存的环境
从最早的时候一直到大概1999年,程序员都极其关注软件的效率问题。在这段时期中,内存空间总是不够大,CPU主频也不够高。
到了20世纪90年代后期,一些像微软和苹果这样的公司,开始注意到摩尔定律[4](其实它们只比别的公司早了一点点)。它们认识到,不必太在意软件的效率问题和内存占用……只要把很酷的功能做出来,然后等着硬件升级就可以了。微软公司首次发布Excel的Windows版本的时候,80386电脑还非常贵,实际上没什么人买得起,但是微软公司很有耐心。只过了几年,80386SX[5]出来了,兼容机的价格下降到1500美元,你只要买一台,就能运行Excel。
由于内存的价格直线下降,CPU的速度每年都在翻番,所以作为一个程序员,你就面临选择。你可以花6个月用汇编语言,重写程序的内循环(inner loop)。你也可以休假6个月,找一支摇滚乐队当鼓手。不管是哪一种选择,6个月后你的程序都会运行得更快。实际情况是没有程序员真的喜欢用汇编语言编程。
所以,我们都不怎么关心软件的效率或优化问题。
不过有一个例外,那就是在浏览器的Ajax应用程序中使用的JavaScript语言。因为这是当前几乎所有的软件开发工作的方向,所以这是一个重大的问题。
眼下的许多Ajax应用程序,有一百万行甚至更多的客户端代码。现在的瓶颈已经从内存和CPU,转移到了带宽和编译时间。你真的必须想尽办法进行优化,才能使复杂的Ajax程序有良好的表现。
但是,历史正在重演。带宽正在变得越来越便宜,即使这样,还是有人在考虑如何对Javascript进行预编译(precompile)。
有一些程序员将大量的精力投入优化工作,要将程序变得更紧凑和更快速。某一天,他们醒来后将发现,这种努力或多或少是白忙一场。如果你喜欢用经济学家的口吻夸夸其谈,那么你最低限度可以说,这种努力”不会带来长期的竞争优势”。
那些不关心效率、不关心程序是否臃肿、一个劲往软件中塞住高级功能的程序员,在长期中,将拥有更好的产品。
跨平台的编程语言
C语言的原始设计目标,就是为了让编写跨平台的应用程序变得更容易。它很好地实现了这个目标,但是并不是真的100%跨平台。所以,后来又出现了Java,它的通用性甚至要超过C语言。历史大概就是这样啦。
眼下,在跨平台这出连续剧中,正出现又一个高潮,那就是—-没错,你猜对了—-客户端Javascript的兼容性问题,尤其是浏览器DOM(文档对象模型)的兼容性问题。编写一个网络应用程序,让它在所有不同种类的浏览器上都能运行,这简直是一场可怕的噩梦。你根本找不到其他方法,只能精疲力竭地在Firefox、IE 6、IE 7、Safari和Opera上一一测试,猜猜发生了什么事?我没有时间在Opera上测试,所以只好不管Opera了。这意味着,新兴的互联网浏览器根本不会获得立足的机会。
未来会怎样?当然,你可以在心里企盼或祈求,微软公司和Firefox能够制作出更具备兼容性的产品。 祝你好运。不过,你还有另外一个选择,就是使用p-code虚拟机[6]或者Java虚拟机模型,你在底层系统之上建立一个小小的沙箱(sandbox),再将软件的运行建立在沙箱之上。这样做的不利之处,就是沙箱有很多缺陷,它们非常慢而且错误百出,这就是为什么Java applet[7]都死光光的原因。建立一个沙箱,你就等于走上了一条不归路,你能得到的运行速度只有底层系统的1/10,你也无法利用任何一个只有某个底层系统支持、而其他底层系统都不支持的特性。(直到今天,我都在翘首期待,有人能向我展示可以在智能手机上使用的Java applet。它能利用手机的所有功能,比如拍照、读取地址本、发送短消息、与全球卫星定位系统GPS互动等等。)
沙箱在过去行不通,在将来也不会行得通。
那么,未来会怎样?获胜的一方所采取的策略,正是贝尔实验室在1978年做出的决定,那里的科学家决定开发一种跨平台的、高效的编程语言,这就是后来的C语言。这种语言可以将程序编译成不同平台、不同系统可以理解的”本地”码(各种不同的Javascript和DOM就是本地码)。至于怎么编译,那是编译器作者需要解决的问题,与你无关。代码编译后的运行效果,与”本地的”Javascript直接运行完全一样,能够以一种统一的方式获取DOM模型的全部潜力,能够自动地和跨平台地,与IE和Firefox的核心代码融合在一起。对的,它还完美地支持CSS,能够以一种令人惊骇、但是事实证明是正确的方法,让你玩转CSS,所以你永远都不必为CSS的不兼容问题发愁。再也不会这样了,永远不会了。哦,等这一天到来的时候,该是多么美好啊。
完善的互动性和用户界面标准
IBM 360大型机(mainframe)使用一种叫做CICS[8]的用户界面,你今天在飞机场还能看到这个系统,你只要在办理登机手续的柜台上弯下身子就能看到。这种界面是80字符宽、24字符高的绿色屏幕,只有字符模式,没有图形界面,这是肯定的。主机发送一个表单给”客户端”(一台IBM 3270智能显示终端)。这个”客户端”是智能的,它知道如何将表单呈现给你,允许你将数据输入表单,在这个过程中,根本不与主机通信。这就是IBM大型机如此强大、远远超过Unix系统的原因之一,因为CPU根本不需要处理你的行编辑,这种任务由智能终端承担了。(如果你做不到为每个人都配置一台智能终端,那么你就去买一台System/1小型机,充当主机和哑终端[9]之间的中介,为你承担表单编辑的任务。)
不管怎样,只要你填完了表单,按下”发送”键,你输入的所有数据就被送回服务器端处理。然后,服务器端又给你发来一个新的表单。整个过程周而复始。
一切都很棒。但是,如果你想在这种环境下,使用文字处理软件,你该怎么办?(你真的无法如愿。在大型机上从来都没有过一个像样的文字处理软件。)
这就是历史上的第一阶段。它与互联网时代的HTML阶段正好对应。HTML语言就是带有字体变化的CICS。
等到历史进入第二阶段,所有人都在写字桌上配备了PC。于是,突然之间,也不管程序员本人愿不愿意,他就是具有了在任意时间、任意场合,随意操弄屏幕上任意角落的任意文字的能力。实际上,你可以获取用户打字时的每一次击键,因此你就能做出一个很好很快的应用程序,不必等到用户按下”发送”键,CPU就能提前介入,做出相应的处理。比如说,你可以开发一个文字处理软件,一旦当前行快要写满了,软件就会自动换行,将结尾的最后一个词移到下一行的行首。一切都在瞬间完成。哦,我的老天,你能做到这一点?
第二阶段也有自己的问题,那就是缺乏一个明确的用户界面标准……程序员具备了空前强大的决定权,几乎可以随意按照自己的偏好来制作软件,因此每个人都用不同的方式写软件,这就给用户带来了困扰,如果你会用X软件,这并不代表你就会使用Y软件。WordPerfect[10]和Lotus 1-2-3有截然不同的菜单设计、截然不同的键盘接口和截然不同的指令结构。在程序之间复制数据,根本没有可能。
这也正是我们今天在Ajax开发中面对的局面。当然,不可否认,Ajax应用程序的易用性比第一代DOS应用程序,有了很大的提高。因为从那时开始,我们已经学到了不少经验。但是Ajax应用程序没有规范的标准,如果想要协同工作,非常麻烦。你完全没有办法,将对象从一个Ajax应用程序中,剪切和粘贴到另一个中。举例来说,我就不太确定,你怎样才能将Gmail中的图片传到Flickr中。拜托,老兄,剪切和粘贴在25年前就发明出来了。
在历史上的第三个阶段中,出现了配备Macintosh操作系统和Windows操作系统的PC。一个统一的、标准的用户界面诞生了,包括多窗口和剪贴板这样的标准功能,这使得在多个程序间进行协同工作成为可能。这种崭新的GUI(图形用户界面),带给我们易用性和实用性的飞跃,导致了个人电脑爆炸式增长。
因此,如果历史会重演,我们就可以期待总有一天,Ajax程序的用户界面会出现某种程度的统一,它的诞生方式就如同Windows的诞生方式一样。总有人会写出一个具备压倒性优势的SDK(软件开发工具包),其他人就可以用它来开发功能强大的Ajax应用程序。不同的程序员使用同样的用户界面组件,使得开发出来的程序可以协同工作。那种赢得最多程序员认可的SDK,就具备了垄断性的竞争优势,堪称可于微软用Windows API获得的竞争优势媲美。
如果你是一个互联网开发者,你不想用别人都在用的主流SDK,那么越来越明显地,你将发现没有用户使用你的程序。原因其实你知道的很清楚,那就是你的程序不支持剪切和粘贴,无法进行地址本同步,也做不到其他所有在2010年流行的新奇的互动功能。
比如,请想像一下,假定你是Google公司的负责人,你为自家有Gmail这样的产品,感到沾沾自喜。但是没过多久,某家你从来没有听到过的公司,—-很可能是一家桀骜不驯的初创公司,背后有Y Combinator[11]的资助—-开发出了一种NewSDK,销售状况好得难以置信。这种NewSDK使用一种性能优异的跨平台编程语言,可以直接编译生成Javascript,而且更出色的是,它还配备了一个大型Ajax库,能够执行所有种类的智能性的互动功能。不仅仅是剪切和粘贴,还有一些很酷的聚合(mashup)功能,就像同步和单点身份管理(single-point identity management)。有了单点身份管理,用户就不必将自己正在干什么告诉Facebook和Twitter了,只需要在网上任意一个支持这个功能的地方,输入就可以了。你对这一套NewSDK嗤之以鼻,因为它的大小居然高达惊人的232MB!……232MB啊!……编译生成的Javascript,单单载入一个页面就需要76秒。所以你认定,自家的应用程序Gmail不会流失任何用户。
但是就是从那时起,就当你在Google总部里、坐在Google式座椅上、细细品味Google味咖啡、感到洋洋得意、沾沾自喜、高枕无忧、踌躇满志的同时,新版本的浏览器发布了,支持缓存编译后的Javascript。于是,突然之间,NewSDK的载入速度变得真的很快。Paul Graham又及时地向这家初创公司补充了6000包方便面,让他们饿的时候有东西吃。这样一来,这家公司又可以继续运营三年,将产品不断完善。
你手下的程序员,不管是张三还是李四,都有相同的看法,那就是Gmail太庞大了,无法移植到那个呆呆的NewSDK上面去。如果那样的话,我们就必须改变每一行的代码。这接近于完全重写整个程序,太可怕了。整个系统模型会一团混乱,充满了嵌套。NewSDK使用的跨平台编程语言用到的括号,多得连Google也无法承受。几乎每一个函数的最后一行,都是一个包含连续3296个右括号的字符串。你因此不得不去买一个特殊的编辑器,才能数清到底有多少个右括号。
后面的事情是,NewSDK的工程师又发布了一个相当不错的文本处理软件,以及一个相当不错的电子邮件应用程序,还有一个杀手级的Facebook/Twitter式的事件发表器,能够将网上与你有关的所有事情都进行同步。人们开始使用他们的产品。
就在你不知不觉之间,所有人都开始编写基于NewSDK的应用程序。这些程序的表现真的很好,一转眼,产业界点名只想用基于NEWSDK的应用程序。所有老式的纯Ajax应用程序看上去都变得很寒酸,它们做不到剪切和粘贴,不能够聚合和同步,互相之间无法很好地协同工作。Gmail就这样成了遗迹,好比Email程序中的WordPerfect。未来的某一天,你对孩子们说,曾几何时当你得到2GB的空间储存Email时,你是多么激动。孩子们全都嘲笑你,他们的指甲油都不止2GB。
你是不是觉得这个故事太荒诞不经了?那你就将”Google Gmail”替换成”Lotus 1-2-3”。NewSDK将是微软公司Windows传奇的重现。整个过程完全是Lotus公司如何丢失电子表格市场的重演。在互联网上,这种事情将再发生一次,因为现在所有影响市场的因素和背后的动力,同当年完全一样。我们唯一不知道的就是,它到底发生在何时、何地、何人身上,但是它一定会发生。
注释:
[1] StarOffice是Sun公司发布的一套Office软件,它的源代码在2000年7月开源,成为了后来的OpenOffice的基础。
[2] Lotus Symphony是Lotus公司在1984年发布的一套Office软件,在DOS环境下运行。1995年,IBM公司以35亿美元的价格,并购了Lotus公司。
[3] Gigli是一部2003年上映的美国电影,主演中包括Ben Affleck、Jennifer Lopez、Al Pacino等大明星。由于Ben Affleck和Jennifer Lopez在拍摄过程中爆出绯闻,这部电影在上映之前被大肆宣传,但是上映之后,口碑极差,被认为是有史以来最滥的电影之一。
[4] 摩尔定律(Moore’s Law)是指大约每隔18个月,芯片的晶体管容量比先前增加一倍,同时性能也提升一倍,而价格下降一半。这个定律描述了硬件的发展趋势,由Intel公司的共同创始人Gordon E. Moore在1965年提出。
[5] 80386SX是80386芯片的一个低价版,后者在1986年上市,前者在1988年上市。
[6] P-code是软件编译过程中产生的一种中间代码,不同于最终的机器码,可以使得编程语言不依赖于特定的平台或硬件。
[7] Java applet是用Java语言编写的、镶嵌在网页的小应用程序。它需要计算机安装了Java虚拟机以后才能运行。
[8] CICS是Client Information Control System(用户信息控制系统)的缩写。
[9] 哑终端(dumb terminal)就是连接主机而不做任何计算处理的终端机。
[10] WordPerfect是Coral公司拥有的文字处理软件,在20世纪80年代末和90年代初流行一时,是事实上的文字处理软件标准。后来,被微软公司的Word取代。
[11] Y Combinator是一家创业投资公司,专门为创业者提供种子资金。该公司由Paul Gramham等人在2005年创立。
罗胖60秒:什么是“设计”?
这个周五上新,给你推荐咱们「得到」里面的最新课程《跟贾伟学设计》。你可能会说,我又不是设计师,我干嘛要学设计?请注意,这里的设计,可不是讲怎么好看的那种美术设计,它其实是一种和陌生人对话的技术。
比如,
最新的手机,你拿到之后,是不需要看说明书的,马上就能知道哪个是开关键,哪个是音量键。再比如,进入宾馆的卫生间,这卫生纸折成了一个小三角,你马上就能get到:这个卫生间清扫完毕,还没人用过。这些现象的背后,都是设计师的智慧。所以贾伟老师说,
设计本质上是一套“读心术”和沟通术,能大大提高你和人沟通的效率。再说一下主讲人贾伟老师,他既是国内获奖最多的设计师之一,也是中国最大的设计公司的老板。在这门课里,他会把自己丰富的实战经验分享给你。《跟贾伟学设计》,请享用。
软件架构被高估,清晰和简单的设计被低估
(1)设计一个计算机系统的目标应该是简单性 。
系统越简单,理解起来就越简单,找到问题就越简单,实现它就越简单。描述的语言越清晰,设计就越容易理解。
干净的设计类似于干净的代码:它易于阅读且易于理解。
(2)如何编写干净的代码?
编写干净代码有很多好方法。但是,你很少会听到有人建议,在代码中应用”四人帮”的设计模式。
干净代码的特征是:单一责任,明确命名和易于理解的约定。这些原则同样适用于清晰的架构。
(3)设计模式的作用是什么?
设计模式可以为你提供如何改进代码或架构的想法。了解常见的设计模式是一件好事,它们有助于缩短与他人的讨论,让别人以与你相同的方式谈论一件事。
但是,设计模式不是目标,它们不能替代系统设计的简单性。在设计系统时,你可能会发现自己意外地应用了一个众所周知的设计模式,这是一件好事。但你不应该为了采用一种或多种设计模式,而将其用作锤子,到处寻找钉子来使用它。
我承认,虽然我花了很多时间阅读和理解”四人帮”的《设计模式》,但它们对我成为一名更好的程序员的影响,要小于我从其他工程师那里得到的反馈。
作为一名工程师,你的目标应该是更多地解决问题,并通过它们进行学习,而不是选择闪亮的设计模式。
Python
Guido van Rossum 老照片
1990年,34岁的荷兰程序员 Guido van Rossum,发布了一个个人的业余项目– Python 语言。
1994年,他参加波兰的 Python 研讨会。

2001年,Python 基金会成立。

2014年,他进入 Dropbox 公司工作。

中国传统颜色手册

一个方便使用的在线色表,列出中国古典的常见颜色。
程序员管人
程序员当久了以后,如果项目顺利,一般都有机会组建或者负责团队,开始管人。
管人其实比开发更难。技术是死的,人是活的,随时会变。把大家团结起来,一起奋斗,很不容易。

我认识的许多程序员,都不愿意管人。一个创业的朋友开一个工作室,他说这几年有好几次机会做大,但是都放弃了,因为不知道怎么管人。 他说,我可以管好自己,但我不知道怎么管好别人。
首先,招聘或者解雇,都是非常麻烦的事情。然后,绩效的评估,奖金的分配,很容易产生矛盾。只要有人心怀不满,就会有内耗,影响企业或团队的发展。万一出现"删库跑路"这种极端情况,更是要命的打击。

马云和任正非强在哪里?不是技术,而是管理和市场判断,他们都非常善于管人,尤其是管理大型组织。任正非就说过,我最大的本事就是一桶浆糊,把几万人粘成一股绳。
所以,程序员应该对自己有一个清醒的认识,管人和技术是两种不同的能力。如果你不善于管人,就不要去任职管理岗位;如果你在创业,就应该请专门的经理人,负责企业管理。
反过来说,对于那些不是程序员、不精通技术的人,只要你善于管理,那么你可以去找程序员,跟你一起技术创业。
程序员收入最高的美国技术公司
美国一家数据公司发布,2019年工程师年薪最高的技术公司排名,分成初级工程师、中级工程师、高级工程师、资深工程师、首席工程师五档。年薪包括工资、奖金和股票。





How
JetBrains我目前使用的 IDE 是 JetBrains 全家桶,目前我编写 Python 比较多,所以主要使用 PyCharm,另外写前端的时候也会使用 WebStorm,写 Java 就用 IntelliJ IDEA,C、C++ 用 CLion,PHP 的话就用 PhpStorm,Ruby 的话就用 RubyMine,其他的语言用的就少了,就没有装了。
如果我只能给其他程序员一个建议,那就是编写小的代码块,你要多写小方法、小功能、小程序。
我自己写C#时,当函数接近15或20行代码时,我会感到不舒服。我的限制是,一个函数最多最多就是24行代码,因为传统终端就是24行一屏。
– 《80/24规则》
我认为,电动汽车比传统汽车更简单是一个谬论。因为电动汽车将复杂性从硬件转移到了软件,因此看上去硬件更简单。
– HN 读者
美国空军邀请7个黑客破解 F-16 战斗机的数据系统,结果发现了不少漏洞。空军感到满意,明年计划邀请黑客攻击轨道上的真实卫星。
REST 和 GraphQL 的最大区别是处理缓存的方式。
当你用 REST 方式构建 API 时,基本上可以自动获得 HTTP 的缓存能力。如果选择 GraphQL,你就需要自己为客户端或应用程序添加缓存。
– 《如何构建优秀 API》
Git 原理解释(英文)
本文用通俗的示例和图片,解释 Git 进行版本管理的原理。
如何将任意命令装为图形界面?(英文)

本文介绍使用 Gooey 这个工具为任何命令行的命令,生成一个图形界面,用户只需写一个配置文件即可。上图是一个 MP3 转换命令的图形界面。
基于零宽字符的文本隐藏加密工具
该工具的原理是利用零宽度字符,将加密文本转码后嵌入到普通文本当中,从而表面看起来是一段普通文本,但是复制粘贴不会丢失密文。
free-for.dev
该仓库收集各种可以免费使用的(或有免费层的)互联网服务。
一个比直播睡觉更奇怪的网站:直播程序员写代码
今天小编发现了一个奇怪的网站,一点进去它的主页就有一个直播窗口,内容是程序员坐在自己的电脑前写代码,比如这样:
当时在首页迎接我的,是一个比这张截图右下角的人类活泼得多的生物。他一直播放着那种很嗨的、让人想要摇摆起来的背景音乐,顺便有点自说自话性质的念叨着自己正在写的代码。结果就是,我居然沉浸在这种类似于看人直播睡觉的诡异气氛中,心甘情愿地看着一个陌生人3分钟说了2个terrible,4个sucks,以及5个shit。(就是这个人↓)
把首页往下拉,会发现两句对网站的文字介绍:这是一个教育性质的直播平台,用这种直播程序员们用代码解决问题的真实场景的方法,来让大家相互学习、相互影响,更好地提升自己的技能。看到这段介绍的时候我的表情是这样的:
好奇地翻了一下网站的其他内容之后,我发现它确实是一个教育性质的直播平台,而且是既有趣又酷的那种。在网站的直播频道,页面会显示出直播的截图封面和标题,直播者的ID和国籍,以及直播内容所属的开发语言和难易程度。
小编看着学写代码还可以如此好玩,不得不佩服在线教育领域玩家们的脑洞。其实在小编眼里,学习写程序一直以来就是一件枯燥的事,说起IT男,你懂的。可有人说他们才是这个时代最具匠心的手艺人,因为科技带来的改变是程序员们一行一行代码写就的成果,仔细想想,确实如此。前段时间比较火的新兴职业——程序员鼓励师,就是为鼓励程序员快乐地写代码而设的,而他们值得拥有。
Experience
数据科学是软件业中唯一需要博士学位的地方,但也有很多数据科学家没有博士学位。如果您想从事任何其他的软件开发,则完全不需要博士学位。
– HN 读者讨论程序员是否需要博士学位
滚动条的演进

这个网页展示自从有计算机以来,系统滚动条的样式变化。
简明 Python 教程
Python 初学者教程《A Byte of Python》的中文翻译。
Modern C(第二版)

最新出版的 C 语言的英文教材,作者提供免费下载。
labstack
在线的代码运行试验环境(playground),支持15种语言,包括 C、C++、Python、Go、Ruby、Swift等。
我如何在40天里面写一个 C 语言编译器(英文)
作者的编译器开发日记,第一天写了20行代码,发展到后来的4000行,记录了每一天所解决的问题。
10种最佳的 Python IDE(英文)
本文介绍了10种 Python 编程 IDE(集成编程环境),每一种的简介和特点。
ShowMeBug

一个国产的在线实时编程环境,程序员面试助手,可以实时观看应聘者远程编程。
G-Shock 电子表
G-Shock 是卡西欧的高端电子表品牌,本文以几十张照片介绍 G-Shock 的设计师(下图右一),以及他是如何设计电子表的。


程序员太太太太难了
10月24日是程序员日,据说来源于2¹⁰ = 1024。虽然只是一个民间创意节日,但我们真心感谢程序员们,一直以来的默默付出。祝愿所有程序员们的世界,永远没有bug!

Regexper

将 JS 的正则表达式转成图形解释的在线工具。
folder-explorer

扫描一个目录,给出目录结构、文件大小等统计信息的桌面工具。
java-design-patterns
一个开源仓库,收集 Java 语言的各种编程模式。
codelani
该仓库对所有计算机语言进行统计,目前一共收集了3563种。
企业软件已死
几十年来,企业软件(即针对大公司的软件)与其它软件存在明显的区别,有着不同的品牌目标、不同的产品优先级和不同的销售周期。
今天,这些差异正在消失。企业软件的区别变得无关紧要,未来将全都是商务软件。

原因一:SaaS 的出现,改变了软件的销售模式。
云端软件的出现,使得软件的开发速度和成本降低了几个数量级。软件的购买决策,慢慢不再由上层决定,而开始变成自下而上的决策。起初,小团队和个人会自发使用一些帮助他们解决问题的工具,然后这种行为会在整个公司中蔓延。
比如,一个小组先采用了 Slack,然后整个团队都在用,接着邻近的团队也开始用,直至其他部门的团队也开始用。最终,高管们别无选择,只能在整个公司范围内采用它。如果普通员工一直在使用替代解决方案,并且知道它更有效时,他们就会站起来并要求采用它。
随着软件自下而上地采用,业务部门的行为开始像消费者。一个小团队会一时兴起尝试新事物,如果不起作用,他们会继续前进,尝试其他选择。如果确实可行,他们将继续使用它,甚至将其散布到整个组织中。
原因二:公司使用的软件品种激增。
根据一项统计,过去的15年中,公司使用的软件工具的品种激增。曾经的企业软件包含的专有功能(例如:性能管理,团队沟通,文件共享等),现在都不得不与专注于单一功能解决方案的 SaaS 公司竞争。这意味着,企业软件的固定合同锁定模式已经一去不复返了,企业软件对客户将不再有多年的锁定,而是必须与那些不断涌现的廉价云端替代产品竞争。
原因三:单个软件的使用周期变短。
公司也比以往任何时候,都更加频繁地更换工具。以前,IBM 出售企业软件时,会派遣一个团队在客户公司的办公室内安装价值25万美元的硬件。如果该客户想要更换软件,就需要将所有这些硬件都丢掉,向另一家公司支付6位数的费用,然后进行数月的迁移。现在只需要点几下鼠标,就能完成数据迁移。
总之,目前的现状就是,越来越多的企业将更多的业务转移到线上和云上,因此整个市场正在扩展。企业只要以每个用户每月几美元的价格,就能开始使用一个软件。通往企业软件的道路比以往任何时候都更短、更容易,并且软件公司非常容易融资,因此新产品不断涌现。最后,市场已经大规模分散化,企业以前会购买一个涵盖多种工具的单一产品套件,而现在则是分散购买不同功能、不同业务的在线服务组合。
这一切意味着:
(1)企业软件已死,以后只存在用于工作场所的软件。当然,发展一家财富500强公司作为客户,与发展一家75人的创业公司,仍然有所不同,但是销售的差异正在迅速缩小。
(2)现在,仅靠说服决策者,不再能赢得客户,需要为整个组织上下的所有最终用户提供令人愉悦的体验才可以。客户群正在从高管,转变为这些公司中数以百万计的工作人员。
(3)市场比以往任何时候都更具流动性。软件供应商曾经每年竞争一次年度合同,现在则是每天都在竞争。
(4)最后,品牌以新的方式发挥作用。企业软件的品牌曾经追求代表稳定性和可靠性。今天,如果软件不酷,就无法取胜。
Sourcetrail

可视化源码浏览器,可以对 C、C ++、Java、Python 源代码进行静态分析,并以图形可视化的形式呈现。
HomeBrew、CakeBrew
HomeBrew、CakeBrew对于开发者来说,这个软件几乎是 Mac 上必备的一个软件,它的官方简介就是 “The missing package manager for macOS”,算是 Mac 上的一个软件包平台,它里面包含着非常多的 Mac 开发软件包,比如 Python、PHP、Redis、MySQL、RabbitMQ、HBase 等等,几乎你能想到的开发软件都集成在里面了,堪称神器!它的安装也非常简单,参见这里:https://brew.sh/,另外 HomeBrew 也有对应的图形界面,叫做 CakeBrew,如果不喜欢命令行操作的话可以使用 CakeBrew 来代替。
Alfred
首推 Alfred,可以说是 Mac 必备软件,利用它我们可以快速地进行各种操作,大幅提高工作效率,如快速打开某个软件、快速打开某个链接、快速搜索某个文档,快速定位某个文件,快速查看本机 IP,快速定义某个色值,几乎你能想到的都能对接实现。
这些快速功能是怎么实现的呢?实际上是 Alfred 对接了很多 Workflow,我们可以使用 Workflow 方便地进行功能扩展,一些比较优秀的 Workflow 已经有人专门做过整理了,可以参见:https://github.com/zenorocha/alfred-workflows。
Sublime
Sublime有时候我们可能下载了或接收了一些单个的文本文件,我们只想看看文本文件内容是什么,或者对其再做一些简单的修改操作,这时候就没必要单独用 JetBrains 的 IDE 打开了,显得有点重了。或者有时候需要修改某个配置文件,这时候也需要一个比较好用的编辑器。我使用的就是 Sublime,对于一些日常的文本编辑是足够了,另外 Sublime 还可以扩展好多插件,配置好了功能上基本不输 JetBrains IDE,非常推荐。推荐指数:★★★★
Terrastruct

一个在线的架构图、流程图工具。
SnippetLab
在写代码的时候,我们经常会有一些常用代码或者精华代码,或者一些常用的配置,想要单独保存下来复用,这时我们可能会把它保存到某个文本文件里面,更高级点可以使用云笔记,如有道云笔记或者印象笔记,用过 GitHub Gists 的小伙伴可能会选择 GitHub Gists,但我觉得这些都不是最佳的。首先文本文件、云笔记里面其实并不是专门为了保存代码使用的,另外 GitHub Gists 保存操作并没有那么便捷,而且打开速度也很慢,影响体验。在这里推荐一款专门用来保存代码的软件叫做 SnippetLab,其设计初衷就是为了保存短代码片的,它支持几乎所有编程语言,另外支持分类、分级、加标签、加描述等,另外它还可以和 Alfred 对接实现快速搜索查找,另外还支持备份、导出、云同步等各种功能,非常适合做代码片的管理。推荐指数:★★★★
CVE 搜索
CVE 是严重的计算机 Bug 的一个编号系统。这是 CVE 的官方搜索系统,可以查找已经编号的 Bug,比如搜索 WordPress,可以返回2392条结果。
我的十年回顾(英文)
著名 JavaScript 程序员、Redux 作者 Dan Abramov 回顾自己的过去十年,从一个没有上大学的俄罗斯高中毕业生,到 Facebook 公司 React 团队的重要成员。
GOTO 语句被认为有害(中文)
Dijkstra 的《GOTO 有害论》在网上只有两个不太好的翻译版本。于是我花了15天翻译了此文。希望能对想用中文了解原文,历史,评价的人能有所帮助吧。
我编程20年的指导原则(英文)
一个编程20年的资深程序员,总结自己编写软件的原则,其中一条是:安全性 > 可用性 > 可维护性 > 代码简洁 > 性能 。另一条是,除非已经完全理解了所要解决的问题,否则不要动手写代码。
软件认证浪费时间和金钱(英文)
作者提出一系列理由,认为各种软件资格证书并无意义,不值得为了它们花费时间和金钱。
GameBoy 模拟器教程:使用 JavaScript 语言
这组系列文章讲解,如何用 JavaScript 语言模拟 GameBoy 的硬件,可以用来了解硬件知识。
黑客的贝叶斯方法:以 Python 为例

免费的英文电子书,讲解贝叶斯概率在 Python 语言中的应用。
过早优化的谬误
Tony Hoare 曾经说过:”过早的优化是万恶之源”。经过 Donald Knuth 大师的推荐,这句话已成为软件工程师的名言。

不幸的是,它被误解扭曲了。许多软件工程师将这一准则理解成”你永远不应该优化代码!”,认为没有必要进行优化。
Tony Hoare 和 Donald Knuth 的真正意思是,代码微优化(例如,一条特定语句消耗多少 CPU 周期)之前,开发者应该担心其他问题。而且,原话并不是说:”在开发的早期阶段,关注程序的性能是有害的。” 他只是反对过早的优化。
以下几点理由,可以解释为什么不能忽视软件性能。程序员正确的做法应该是,在软件开发的早期阶段,就关注性能问题。
(1)性能问题不容易在软件开发的最后阶段解决。20%的代码占用了80%执行时间,它们可能散布在整个源代码中,不容易一次性修改解决。
(2)许多工程师相信,到软件发布时,CPU 的性能将会提高,以弥补部分代码的性能低下。尽管在1990年代确实如此,但在最近十年 CPU 性能非常有限。
(3)软件工程师认为,他们的时间比 CPU 时间更有价值。因此,浪费 CPU 周期以减少开发时间是对的。但是,他们忘记了,用户的时间比他们的时间更有价值。
(4)优化可能会导致产品延迟进入市场,并降低利润,这是正确的。但这种想法忽略了性能不佳的产品可能很难销售,尤其是在市场竞争激烈的情况下。
(5)有些程序员认为,几乎没有必要确保在软件的设计阶段,就使用最佳算法,先实现功能再说,因为以后总是可以替换更好的算法。所以,无需担心软件在开发阶段的性能,以后可以通过更好的算法对其进行提高。不幸的是,更好的算法在后期不一定可以实现,而且代码往往因为牵扯太多,无法轻易替换其中某个部分。
中国地图坐标简介(英文)

中国的地图坐标不同于国际通用坐标,在标准地图会产生几百米的偏移,必须采用算法换算。
Swift Playgrounds

苹果公司官方的免费 Mac 桌面软件,通过游戏学习 Swift 语言。
Unity 官方教程

Unity 是一个游戏开发引擎,它的官方教程现在免费开放3个月,从零教你写一个 3D 游戏,教程质量相当高。
codefence
一个可以嵌入网页的交互式代码编辑器,用户能够直接在网页上输入代码并运行,得到结果。服务端是 Docker 容器,目前支持十几种主流的计算机语言。
Quickref
一个针对程序员的搜索引擎,只搜索编程相关的网站,比如 GitHub 和 StackOverflow。
winget-cli

微软官方的命令行 Windows 包管理工具,估计是为了从 Linux 和 MacOS 系统抢夺开发者。不知道能否最终取代 Chocolatey。
崩溃安卓手机的壁纸

有人发现,将上图用作某些安卓手机的壁纸,会导致系统立即崩溃重启,屏幕会不断地打开和关闭,无法再进入系统,不得不送修。目前确认受影响的手机,主要是三星和谷歌的 Pixel 手机,而且是最新的 Android 10 系统。
初步分析的原因是,加载壁纸后,手机会检查图像的”色彩空间”,这时有报错,但是没有任何捕获这个错误的代码,导致系统崩溃了。三星和谷歌都已经紧急发布了补丁。另一个相关的消息是,原定本周宣布的 Android 11 测试版,已经推迟。
字节跳动的三道算法面试题目(中文)
作者去面试 AI lab 视觉岗的暑期实习,第一面就是三道算法题。其中第一题是这样的:”10个小球随机分到12个盒子里,求恰好10个盒子都为空的概率,要求用 Python 程序模拟十万次,暴力求出该概率。” 详细解法可以参考这篇英语文章。
设计模式

该网站为中文教程,使用通俗的语言,介绍各种设计模式,图文并茂。此外,还有代码重构方面的英语内容。
推特工程部门宣布,开始替换带有歧视性的软件术语,比如”黑名单”(blacklist)改为”拒绝名单”(denylist),”白名单”改为”允许名单”(allowlist)。

codota

一个人工智能的代码提示和补全插件,支持各大主要的 IDE。
技术树
为了让后代了解我们如何开发和使用软件,GitHub 官方开出了一个书单,称为”技术树”(the Tech Tree),包括16个大类的200多本经典书籍。这些书籍的数字化版本,将存放在 GitHub 的北极仓库。
Code with me

IntelliJ IDEA 的官方插件,允许多人在 IDE 里面实时协同编程。
Play with Go

Go 语言教程网站,提供一系列互动式入门教程。
Docker 指南


一篇英文的 Docker 教程,解释最重要的一些概念,帮助读者学会使用 Docker 进行应用程序开发。
从头写一个 Deno 的 BitTorrent 下载器(中文)
介绍 BT 下载的实现细节,有 JavaScript 代码的下载客户端示例。
Reference
- Electron 7.0.0
- Electron 7.0.0稳定版正式发布:跨平台桌面应用开发工具
- 提交信息的规范
- C++ 生态环境介绍
- 北极代码地窖
- C++ 创始人 Bjarne Stroustrup 访谈
- MacOS、Windows、Ubuntu 性能比较
- 软件 bug 大事记
- 软件架构编年史
- 谷歌工程实践文档
- 50年前的登月程序和程序员有多硬核
- 学习编程的安卓 App
- MacOS下Java开发环境搭建之JDK
- Python - macOS下Python开发环境的搭建教程
- jetbrains全家桶phpstorm webstorm clion IntelliJ IDEA等注册码 定期更新
- C语言入门教程
- Python教程
- Kotlin 教程
- Kotlin 教程
- Java学习教程
- Java 教程
- Java 语言快速入门
- Homebrew
- Code Runner
- VS Code 从入门到进阶
- MAC 设置环境变量PATH 和 查看PATH
- Github
- Coding
- Stack Overflow
- 七牛
- English
- Git教程
- Python教程
- hexo-theme-yilia
- atom——A hackable text editor for the 21st Century
- 鸟哥的Linux私房菜(第三版)
- 深入理解计算机系统
- 大话数据结构
- 大话设计模式
- Python编程:从入门到实践
- C++ Primer 中文版(第 5 版)
- Java编程思想 (第4版)
- C程序设计语言
- 免费的编程中文书籍索引
- 编程人生
- 编码的奥秘
- 黑客与画家
- 软件随想录
- 技术大会演讲指南
- C 语言主函数 main() 怎么写?
- 从头构建一个 BitTorrent 客户端
- 7天用 Go 从零实现系列
- YAML 表示多行字符串的9种方法
- 谷歌突然公布并开源 Pigweed:可提升嵌入式开发效率
- 16 个好用的 Code Review 工具
- 寻找 COBOL 程序员
- apioak
- 分布式哈希表 (DHT) 和 P2P 技术
- CTO 干什么?
- Godot 101 -游戏引擎基础
- 任天堂总裁山內溥的轶事
- Android OpenGL ES 极简教程
- 如何在微信建立一个定时提醒机器人?
- leetcode 前 300 题
- .NET IDE Rider 公布 2020.2 路线图
- 大 O 表示法与算法复杂性
- 如何用 C 语言写一个简单的 CHIP-8 模拟器(中文)
- C 语言内部原理
- Android Studio 4.0 正式版发布
- 何时写注释?(英文)
- 伪随机数生成器(英文)
- EasyOCR
- hugo-leetcode-dashboard
- 计算机科学史上伟大的成就之一:Dijkstra最短路径算法
- 如何构建优秀的 API(英文)
- 什么是“进程、线程、协程”?
- 如何自己实现一个全文搜索引擎(英文)
- 编程界的十大天神
- labuladong 的算法小抄
- 我开发 SaaS 的工具和服务
- 如何写出容易维护的 Makefile
- 用 JS 写一个 JS 解释器(中文)
- Ruby 学习指南