
Integrated Circuit & System on Chip.
What
什么是GPU?跟CPU有什么区别?终于有人讲明白了
原创 华章科技 2020-01-31 14:03:55
导读:一文看懂GPU的前世今生。
作者:钱纲 来源:华章科技
2016年,发生了一件震动IT界的大事。谷歌的人工智能软件阿尔法狗(AlphaGo)击败了韩国的世界围棋冠军九段选手李世石。2017年,阿尔法狗又击败了当年世界围棋排名第一的中国围棋九段选手柯洁。至此,人类在所有的棋类比赛中全部输给了计算机。
阿尔法狗是一个中央处理器(Central Process Unit,CPU)和图形处理器(Graphic Process Unit,GPU)一起工作的围棋智能机器人。阿尔法狗以神经网络、深度学习、蒙特卡洛树搜索法为核心算法。其系统由四部分组成:
策略网络(Policy Network),以当前局面为输入,预测下一步的走法;
快速走子(Fast Rollout),目标和策略网络相似,在适当牺牲质量的条件下的加速走法;
价值网络(Value Network),以当前局面为输入,估算胜率;
蒙特卡洛树搜索(Monte Carlo Tree Search),把上述三个部分整合起来,形成完整的系统。
最初的阿尔法狗有176个GPU和1202个CPU。GPU能够通过内部极多进程的并行运算,取得比CPU高一个数量级的运算速度。但是GPU为了管理多进程,它需要在微架构上进行精心设计以满足深度学习计算对于带宽和缓存的需求。那么GPU和CPU有什么不同呢?
01 图形处理器
CPU由运算器(ALU)和控制器(CU)两大部件组成。此外,还有若干个寄存器和高速缓冲存储器及实现它们之间联系的数据、控制及状态总线。ALU用来执行算术运算、移位操作、地址运算和转换;寄存器件用于保存中间数据以及指令;CU负责对指令译码,并发出为完成每条指令所要执行的各个操作的控制信号(见图24-1)。
▲图24-1 CPU的结构图(冯·诺依曼构架)
CPU的运行遵循冯·诺依曼构架:存储程序顺序执行。程序执行过程如下:CPU根据程序计数器(Program Counter,PC)从内存中得到指令,然后通过指令总线将指令送至译码器,将转译后的指令交给时序发生器与操作控制器,再从内存中取得数据并由运算器对数据进行处理,最后通过数据总线将数据存至数据缓存寄存器以及内存中。
CPU是一步步来处理数据的(见图24-2)。在处理大规模与高速数据时,CPU很难满足需要。
▲图24-2 CPU的工作原理
当芯片的集成度增加后,漏电流也随之增大,但时钟频率的提高有限,而且晶体管的线宽很快就会到达物理极限,因此芯片的性能很难靠减小晶体管线宽来提高。于是,人们开始在设计上做文章,首先想到的是让多个处理器并行工作,这样效率自然提高了很多,于是多核CPU和GPU由此诞生。
另一个想法是芯片不变,而在应用系统上加人工智能,以此取得计算上的收益。随着大数据时代的到来,以人工智能为导向的应用系统也越来越多了。
在现代的计算机中,图形处理越来越重要,于是一个专门处理图形的核心处理器GPU应运而生。对于处理图形数据来说,图形上的每个像素都要被处理,这就是一个大数据,因此对运算速度的要求很高。但GPU所需的功能比较单一,于是就诞生了基于优化图形处理的GPU构架(见图24-3)。
▲图24-3 CPU与GPU构架对比示意图
CPU的功能模块多,适合复杂的运算环境,大部分晶体管用在控制电路和Cache上,少部分晶体管用来完成运算工作。GPU的控制相对简单,且不需要很大的Cache,大部分晶体管可被用于各类专用电路和流水线,GPU的计算速度因此大增,拥有强大的浮点运算能力。
当前的多核CPU一般由4或6个核组成,以此模拟出8个或12个处理进程来运算。但普通的GPU就包含了几百个核,高端的有上万个核,这对于多媒体处理中大量的重复处理过程有着天生的优势,同时更重要的是,它可以用来做大规模并行数据处理。
尽管,GPU是为了图像处理设计的,但它的构架并没有专门的图像处理算法,仅仅是对CPU的构架进行了优化,因此GPU不仅在图像处理中应用广泛,还在科学计算、密码破解、数值分析、大数据处理、金融分析等需要并行运算的领域中广为应用。GPU是一种较为通用的专业芯片。
02 图形处理器的构成
GPU的线路板一般是6层或4层PCB线路板。GPU的所有元器件都集成在它的线路板上,线路板影响着GPU的质量。
GPU线路板上最大的芯片就是GPU,它上面有散热片和风扇。作为处理数据的核心,GPU大多采用单芯片设计,而专业的GPU也有采用多个GPU芯片的。
GPU线路板上的另一个重要芯片是数/模转换器(RAMDAC)。它的作用是将显存中的数字信号转换成显示器能够识别的模拟信号,速度以MHz为单位,速度越快,图像越稳定,它决定了GPU能支持的最高刷新频率。为了降低成本,多数厂商都将数/模转换器整合到了GPU芯片中,但仍有一些高档GPU采用独立的数/模转换器芯片。
GPU的数据是存放在显存内的,显存是用来存储等待处理的图形数据信息的。显存容量决定了GPU支持的分辨率、色深。分辨率越高,显示的像素点越多,所需显存容量越大。对目前的三维GPU来说,需要很大的显存来存储Z-Buffer数据或材质数据。
显存有两大类:单端和双端显存。前者从GPU中读取数据并向数/模转换器传输数据且经过同一端口,数据的读写和传输无法同时进行;后者则可以同时进行数据的读写与传输。目前流行的显存有SDRAM、SGRAM、DDR RAM、VRAM、WRAM等。
GPU线路板上采用的常见电容类型有电解电容、钽电容等,前者发热量较大,许多名牌GPU采用钽电容来获得性能上的提升。电阻也是如此,常见的金属膜电阻、碳膜电阻越来越多地让位于贴片电阻。
GPU线路板上有对GPU进行供电的供电电路。它的作用是调整来自主板的电流以供GPU稳定地工作。由于GPU越来越精密,因此对GPU供电电路的要求也越来越高。
GPU线路板上还有一款用于VGA BIOS的闪存。它包含了GPU和驱动程序的控制程序、产品标识等信息。该闪存可以通过专用程序进行升级,改善GPU性能,有时能给GPU带来改头换面的效果。
GPU线路板上有向GPU内部提供数/模转换时钟频率的晶体振荡器等元器件。此外,由于GPU的频率越来越高,工作时热量很大,GPU线路板上还会有一个散热风扇。
03 计算机图形的生成原理
计算机的输出图像是模拟信号,而计算机处理的是二进制数字信号。数据离开CPU后,经过以下四个步骤,才到达显示屏成为图像。
- 经总线进入GPU,将CPU送来的数据送到GPU里进行处理。(数字信号)
- 从GPU进入显存,将GPU处理完的资料送到显存。(数字信号)
- 从显存进入数/模转换器,从显存读取出数据然后送到数/模转换器进行数据转换。
- 从数/模转换器进入显示器,将转换完的模拟信号送到显示屏(模拟信号)
显示屏上显示的是最后处理的结果,显示效能的高低由以上四个步骤共同决定,它与GPU的效能不同,GPU的效能决定了中间两步。第一步是由CPU进入到GPU,最后一步是由GPU将资料送到显示屏上。
近几年,人工智能中的深度学习算法大热,让GPU制造商大火。其实,深度学习的理论早在20世纪七八十年代就有了,但它的崛起主要是因为GPU的出现。英伟达公司的联合创始人与CEO黄仁勋说:“因为人工智能世界的大爆炸发生了,人工智能计算机科学家们找到了新算法,让我们能利用深度学习的技术,取得无人敢想的成果。”
04 显卡的诞生
提到显卡和GPU,人们会想到游戏和电影中精美的三维图形。其实,早期显卡不但不能处理三维图形,甚至连二维图形都无法处理,它仅具备显示能力。今天,GPU不但能够处理复杂的三维图形,还能作为协处理器,在通用计算中使用。
电脑图形处理器的发展是从图形显示适配器开始的,到图形加速器,再到图形处理器即GPU,其功能在不断增强。
从显示适配器到图形加速卡的转变是显卡历史上的重要转折点。从此,显卡开始承担计算机中的部分计算任务,这奠定了其日后与CPU分庭抗礼的基础。
电脑图形学是在1962年,由麻省理工学院的伊凡·苏泽兰(Ivan Edward Sutherland)在他的博士论文中提出来的。这位香农的学生是电脑图形之父。在之后的20年里,电脑图形学一直在不断发展,但没有产生专门的图形处理芯片。
在显卡出现之前,电脑中通常的图形输出工作由CPU承担。显卡的出现不是为了加速电脑的图形输出,最初的显卡是为了让游戏机上的二维图形显示加速。这款游戏是雅达利公司于1977年推出的雅达利2600。同期流行的电脑是苹果-II,而苹果-II的图形输出由CPU承担。
进行图形处理时需要电脑具备较强的并行计算能力,对精度和运算强度的要求也很高,对早期的电脑来说,这很难。当时的显卡仅仅是将CPU计算生成的图形翻译成显示设备能识别的信号来进行显示,不具备计算能力,被称作图形适配器(VGA Card)。
▲图24-4 Antic芯片
雅达利2600拥有专门负责在电视上输出图形的8位Antic芯片和音频的CTIA芯片(见图24-2)。雅达利2600的设计者杰伊·迈纳(Jay Miner),也是20世纪80年代图形性能最强大的电脑阿米加(Amiga)的设计者。雅达利2600内部的Antic芯片是显卡的老祖宗。
1981年,IBM推出了最早的装在5150个人电脑上的MDA(Monochrome Display Adapter)和CGA(Color Graghic Adapter)两款二维加速卡。
MDA仅支持黑色和绿色的文字,图形内存为4KB,无法产生图形。CGA是IBM个人电脑中最早的彩色显卡,640×200的分辨率,4种颜色。由于CGA的分辨率太低,因此有了EGA增强图形适配器(Enhanced Graphics Adapter)。
MDA、CGA、EGA三种标准都是以TTL数字信号输出的。IBM很快研发出了基于ISA(Industry Standard Architechture)的显卡,是最古老也是最普遍使用的VGA显卡。
直到VGA标准出现,显卡才和主板分开,VGA(Video Graphic Array)即显示绘图阵列,它的数字模式可以达到720×400种颜色,绘图模式可达640×480×16种颜色,以及320×200×256种颜色。直到此时,显卡才能同时显示256种色彩。
VGA标准采用了模拟信号输出,其彩色显示能力大大加强,原则上能显示无穷多种颜色,因此VGA迅速成为显示设备的标准。
这个时代,出现了第一款真正的显卡——Trident 8900/9000显卡,它是ISA/16色显卡的代名词,也是三维显卡的真正鼻祖,它第一次使显卡独立于电脑,显卡从此不再是集成的一块芯片,这为以后独立显卡的发展提供了可能性。
VGA之后又出现了SVGA标准。它是VGA标准的衍生产物,改良过的SVGA图形适配器已经能够支持16比特的彩色了。最早的SVGA显卡是Cirrus Logic的GD5428/5429,它集成了1~2MB显存,支持16比特的彩色。不过GD5428/5429仍使用VESA总线,因此卡身很长,成本不低。
真正将SVGA发扬光大的是S3735(Tr64V)以及Trident 9680,它们能够达到1024×768的分辨率,并且在低分辨率的情况下支持32比特真彩色。
1984年,硅图公司(Silicon Graghics Inc.,SGI)推出了专业的高端图形工作站,并配置了专门的图形硬件,称为图形加速器。它引入了许多经典概念,如顶点变换和纹理映射。在随后的10多年里,硅图公司又研发了很多面向专业领域的图形工作站,但它们的价格昂贵,无法进入个人电脑市场。
1984年,IBM又推出了两款显卡,它们是PGC(Professional Graghics Controller)和EGA。这两款显卡能够支持二维和三维的图形加速,并被用于计算机辅助设计。
1986年,德州仪器推出了第一款具有在芯片上进行图形处理功能的微处理器TMS34010。这款处理器需使用特殊的图形编程语言。1990~1992年,它是视窗加速卡中,德州仪器图形框架(Texas Instruments Graghics Architecture,TIGA)的基础。
1987年,康莫多国际(Commodore International)公司推出了阿米加500电脑。该电脑拥有功能强大的图像处理专用芯片。这款芯片也是在杰伊·迈纳的倡导下加上的,这款显卡给阿米加500带来了704×576像素的图形显示功能。
除了显卡外,阿米加500的音频输出性能也极好。虽然阿米加500的显卡不是第一块应用在电脑上的显卡,但该显卡是第一款真正意义上的二维加速卡。阿米加500电脑的诞生让人们意识到图形加速卡对于电脑的意义(见图24-5)。
▲图24-5 阿米加500电脑用的显卡
1988年,支持256种颜色显示的第一代显卡问世。它是ATI公司生产的ATI VGA Wonder显卡。这是一款真正意义上的第一代显卡,时至今日VGA一词还是显卡的代名词。
05 前GPU时代
1989年,多家芯片制造商联合创立了影像电子工程标准协会(Video Electronic Standards Association,VESA)。1994年年底,VESA发表了64位架构的VESA Local Bus标准,80486及以后的个人电脑大多采用该标准的显卡。
1991年,英特尔推出了一种局部总线PCI(Peripheral Component Interconnect)。在结构上,PCI是在CPU和原来的系统总线之间插入的一级总线,由一个桥接电路对该层进行管理,并实现接口间的协调数据传送。管理器提供信号缓冲,使其支持10种外接设备,同时在高时钟频率下保持高性能。PCI为显卡、声卡、网卡等设备提供了接口。
显卡接口制约着显卡技术的发展。为了加快显卡与总线间的传输速度,使用高带宽的接口总线势在必行。在民用市场,显卡接口的起点是最普通的ISA接口,ISA接口包含ISA总线、EISA总线和VESA总线,ISA接口是一种统称。
当VGA标准流行之后,ISA接口就显得力不从心了,由PCI取而代之,但PCI接口并未持续多久就被更为先进的AGP(Accelerated Graphics Port)所淘汰。与PCI相比,AGP在带宽上有了突飞猛进的发展,还能有效利用系统内存。
但AGP的半开放性格局使之不断面临兼容性的困扰。从最早的AGP 1×到AGP 8×,真正具有里程碑意义的只有AGP 4×。如今AGP 8X也开始被PCI Express×16取而代之了。
1991年,支持微软视窗操作系统图形加速的第二代显卡(Graphics Card)问世。
VGA的唯一功能就是输出图像,图形运算全靠CPU,当微软的视窗操作系统出现后,PC不堪重负。1991年5月,ATI发布Mach8,这是ATI第一款优化微软视窗操作系统图形界面的显卡。ATI用专用芯片进行图形运算处理,将CPU解放了出来,且让视窗操作系统的界面运行起来非常流畅,图形化操作系统的资源消耗大降、实用性大增。
Mach8就是ATI 38800-1芯片。Mach8显卡由两个芯片组成,主芯片为VGA Wonder XL 24(ATI 28800-6),负责显示输出,辅助芯片是Mach8专门用于加速视窗操作系统图形界面的,通过双芯片的设计增强了绘图能力。
为了与只具备显示功能的VGA相区别,具备图形处理能的显卡被称为Graphics Card,即图形加速卡,它加速了视窗的普及,加速了PC图形化界面的步伐。
1991年6月,S3公司推出了一款二维图形加速卡S3 86C911。它是最早的视窗加速卡之一,支持16位256种颜色。此后,二维显卡进入了群雄争霸时代。当时,Trident、S3、Matrox三大厂商占据主导地位。
这些二维显卡角逐的激烈程度丝毫不亚于今天的三维显卡的争斗。由此也产生了不少经典产品:Trident的9440、S3的Trio64V+、Matrox的Millennium等。其中性能最优的是Millennium及后继产品,但因其售价昂贵没有得到很多市场份额。当时,最成功的是S3的Trio 64V+。等到了voodoo时代,它仍是voodoo的好搭配。
第一款三维显卡是三维实验室(3Dlabs)制造的GLINT 300SX(见图24-6)。它的三维图形的高洛德着色(Gouraud Shading),深度缓冲,全屏抗锯齿,Aplha混合等特性被沿用至今。300SX正式开启了计算机三维显示的大门,但它也有很多不足,比如没有数模转换芯片(RAMDAC),要加上数模转换芯片才能将内容输出到显示器上。
▲图24-6 300SX GPU
06 多媒体时代的显卡
1994年,支持视频加速的第三代显卡出现了。
这时的PC已经进入了多媒体时代,二维图形处理在第二代显卡面前已不是问题了,但越来越多的视频图形解码让CPU不堪重负,因此集成了简单的视频解码器的第三代显卡出现了。
ATI在1994年推出的Mach64是第一款广为人知的多媒体显卡,它的硬件支持YUVtoRGB颜色转换和硬件缩放。有了它的PC能应付基本的AVI和MPEG-1播放,而不需要昂贵的专用硬件解码器,使得多媒体PC的成本大幅下降。
1994年,第四代显卡,三维加速显卡出现了。
三维显卡前期,令人难忘的是3Dfx Interactive公司(简称了Dfx)。1996年,3Dfx推出的voodoo显卡奠定了3Dfx在图形显示领域的地位,但它并不普及,因为太贵了。当时的RAM很贵,而voodoo需要很大的RAM。
另外voodoo要卖到500美元才能赚钱,voodoo没有二维输出能力,用户必须外加一块100美元左右的二维加速卡才能正常使用它。高昂的成本让个人电脑厂商对它避而远之。据说,3Dfx承诺免费提供半年的voodoo芯片都被拒绝了。图24-7是3Dfx推出的第一款三维显卡。
▲图24-7 3Dfx的第一款三维显卡
3Dfx的运气很好。1996年夏,芯片工艺的更新让RAM价格大跌,3Dfx借机得以推广,而各游戏和个人电脑生产厂家也改变了态度,开始使用voodoo。当voodoo以300美元的价格上市时,市场被引爆了。voodoo支持DVD和OpenGL,但二者还较粗糙,抑制了voodoo的性能。3Dfx只好开发图形API——Glide。
20世纪末,3Dfx的崛起宣布了三维显卡进入了白热化竞争时代。S3、Matrox、3Dlabs等厂商都加入了竞争,但它们均不敌voodoo。除voodoo以外的三维显卡的代表作是ATI的3DRage II+DVD。
这一款1996年秋天发布的显卡,其二维引擎来自Mach64。它具有MPEG-2硬件动态补偿功能,能在播放DVD时起到辅助作用,这是非常先进的。加上ImpacTV芯片,它还可以播放电视节目。3DRage II的驱动支持也非常好,无论是游戏用户还是专业用户都可以得到对应的驱动程序。只是ATI当时专注于OEM市场,而非零售。
3Dfx为了解决voodoo没有二维加速功能的问题,于1997年开发了具有二维加速功能的voodoo rush。但是其性能很差,它以主卡加副卡的方式实现二维加速,且二维芯片来自第三方。voodoo rush成了一款二维显示很差、三维性能又比voodoo差的显卡。它对Glide的支持也很差,经常无法加速。
不久,ATI研发出了3D Rage Pro。因其强大的DVD回放功能成了当时OEM多媒体电脑的首选。ATI尝试过进入零售市场,但因其很差的驱动失败了,等到ATI驱动没问题的时候,Rage Pro已过时了。3D Rage Pro是最早支持AGP接口的显卡之一。
ATI在被AMD收购之前一直是计算机图形领域的领头羊之一。这是一家由三位来自中国香港的华裔在1984年于加拿大创建的计算机图形公司。其主要创始人何国源,1950年出生于中国广东省。
12岁时,何国源来到香港。因家庭贫困,他20岁时只身来到学费和生活费较低的台湾就读大学。1984年,已在电脑领域有了丰富工作经验的何国源移居加拿大,创办了计算机图形公司——ATI。
1998年,3Dfx推出了voodoo2。voodoo2的性能比voodoo提高了2~3倍,它还增加了大量新的画质提升技术。voodoo2降低了对CPU的依赖,很多低端的CPU也可以流畅运行大型三维游戏。
voodoo2还引入了SLI技术,能让两张voodoo2显卡同时运算同一画面。有1/3以上的voodoo2用户是双卡用户。voodoo2让3Dfx成了三维显卡初期的绝对老大。
1998年,3Dfx犯了两个致命的错误:一是收购了一家名为STB的公司,自行生产GPU,舍弃了第三方合作伙伴;二是对Glide API的封锁,导致游戏厂商开始对其敬而远之,表面上看3Dfx因voodoo2风光无限,但这也是其衰落的开始。
3Dfx在1998年犯的错误并没有让它面临危机,这是因为没有竞争对手。到了1999年情况就不同了,几件事让3Dfx面临灭顶之灾。先是DX7带来了硬件T&L,硬件T&L的出现彻底解放了CPU,即便是低端CPU,搭配了支持硬件T&L的显卡也可以流畅地玩游戏。大量视觉技术的添加使得Glide的优势丧失殆尽。
3Dfx于1999年发布的voodoo3不支持新出现的AGP4x,仅支持2x,但只支持接口,不支持AGP的特性。voodoo3的16比特渲染在大势所趋的32比特潮流面前毫无竞争力。
同时,来自英伟达的TNT2以其强大的性能干脆利落地将voodoo3打败了。与同年发布的Gefroce 256相比,它只是一款TNT的改进产品,但这未能阻碍TNT2成为一代经典。
1998年2月,英特尔发布了和Real 3D合作设计的i740显卡(见图24-8)。这是迄今为止英特尔推出过的唯一一款独立显卡。i740支持2X AGP规格,核心频率为80MHz,像素填充率为55MT/s,支持DVD解压、平行信息处理、精准像素描插补等技术。
i740的2D效果并不令人满意,但它的三维性能还不错,它首次在民用显卡中采用散热风扇。后来,英特尔将i740改进后集成进了810芯片组。
▲图24-8 英特尔的i740显卡
关于作者:钱纲,现就职于美国德州仪器公司,从事半导体工艺及半导体器件的开发与研究工作。科学网人气作者,其作品在线获得超过千万人次的浏览量。钱纲的作品以涉及历史、科技的杂文、随笔为主。主要作品有美国历史及人物纪事《美国往事》,硅谷历史《硅谷简史》等。
本文摘编自《芯片改变世界》,经出版方授权发布。
延伸阅读《芯片改变世界》
推荐语:本书是芯片技术发展的科普图书,重点讲述了电子工业的产生,早期电子器件、半导体器件、及芯片的产生与发展的历史。把芯片技术与其发展史结合起来,描绘芯片产业与第三、第四次工业革命的兴起及发展过程。本书的主角是芯片技术的历史沿革、发明家、创业家、风险投资家及企业家。
Why
芯片国产化的三大障碍(中文)
中国想要摆脱芯片对外国技术的依赖,必须克服三大障碍:光刻机、芯片设计软件、高纯度硅材料。每一项的难度都极高。
任正非:为什么华为现在要搞基础研究?(中文)
2020年7月29-31日,任正非访问上海交通大学、复旦大学、东南大学、南京大学的讲话摘要。
凭借中国一国之力能搞出光刻机吗?(中文)

芯片生产的核心设备是光刻机,目前只有荷兰 ASML 能生产,中国自己能搞出来吗?
How
与程序员相关的CPU缓存知识
2020年03月01日 陈皓

好久没有写一些微观方面的文章了,今天写一篇关于CPU Cache相关的文章,这篇文章比较长,主要分成这么几个部分:基础知识、缓存的命中、缓存的一致性、相关的代码示例和延伸阅读。其中会讲述一些多核 CPU 的系统架构以及其原理,包括对程序性能上的影响,以及在进行并发编程的时候需要注意到的一些问题。这篇文章我会尽量地写简单和通俗易懂一些,主要是讲清楚相关的原理和问题,而对于一些细节和延伸阅读我会在文章最后会给出相关的资源。
因为无论你写什么样的代码都会交给CPU来执行,所以,如果你想写出性能比较高的代码,这篇文章中提到的技术还是值得认真学习的。另外,千万别觉得这些东西没用,这些东西非常有用,十多年前就是这些知识在性能调优上帮了我的很多大忙,从而跟很多人拉开了差距……
基础知识
首先,我们都知道现在的CPU多核技术,都会有几级缓存,老的CPU会有两级内存(L1和L2),新的CPU会有三级内存(L1,L2,L3 ),如下图所示:
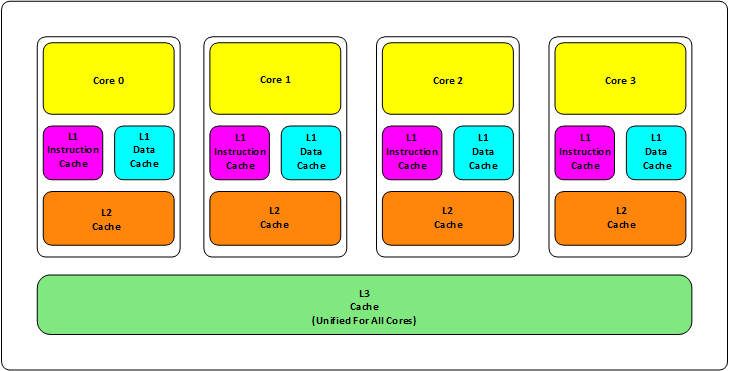
其中:
L1缓分成两种,一种是指令缓存,一种是数据缓存。L2缓存和L3缓存不分指令和数据。
L1和L2缓存在每一个CPU核中,L3则是所有CPU核心共享的内存。
L1、L2、L3的越离CPU近就越小,速度也越快,越离CPU远,速度也越慢。
再往后面就是内存,内存的后面就是硬盘。我们来看一些他们的速度:
L1 的存取速度:4 个CPU时钟周期
L2 的存取速度: 11 个CPU时钟周期
L3 的存取速度:39 个CPU时钟周期
RAM内存的存取速度:107 个CPU时钟周期
我们可以看到,L1的速度是RAM的27倍,但是L1/L2的大小基本上也就是KB级别的,L3会是MB级别的。例如:Intel Core i7-8700K ,是一个6核的CPU,每核上的L1是64KB(数据和指令各32KB),L2 是 256K,L3有12MB(我的苹果电脑是 Intel Core i9-8950HK,和Core i7-8700K的Cache大小一样)。
我们的数据就从内存向上,先到L3,再到L2,再到L1,最后到寄存器进行CPU计算。为什么会设计成三层?这里有下面几个方面的考虑:
一个方面是物理速度,如果要更大的容量就需要更多的晶体管,除了芯片的体积会变大,更重要的是大量的晶体管会导致速度下降,因为访问速度和要访问的晶体管所在的位置成反比,也就是当信号路径变长时,通信速度会变慢。这部分是物理问题。
另外一个问题是,多核技术中,数据的状态需要在多个CPU中进行同步,并且,我们可以看到,cache和RAM的速度差距太大,所以,多级不同尺寸的缓存有利于提高整体的性能。
这个世界永远是平衡的,一面变得有多光鲜,另一面也会变得有多黑暗。建立这么多级的缓存,一定就会引入其它的问题,这里有两个比较重要的问题,
一个是比较简单的缓存的命中率的问题。
另一个是比较复杂的缓存更新的一致性问题。
尤其是第二个问题,在多核技术下,这就很像分布式的系统了,要对多个地方进行更新。
缓存的命中
在说明这两个问题之前。我们需要要解一个术语 Cache Line。缓存基本上来说就是把后面的数据加载到离自己近的地方,对于CPU来说,它是不会一个字节一个字节的加载的,因为这非常没有效率,一般来说都是要一块一块的加载的,对于这样的一块一块的数据单位,术语叫“Cache Line”,一般来说,一个主流的CPU的Cache Line 是 64 Bytes(也有的CPU用32Bytes和128Bytes),64Bytes也就是16个32位的整型,这就是CPU从内存中捞数据上来的最小数据单位。
比如:Cache Line是最小单位(64Bytes),所以先把Cache分布多个Cache Line,比如:L1有32KB,那么,32KB/64B = 512 个 Cache Line。
一方面,缓存需要把内存里的数据放到放进来,英文叫 CPU Associativity。Cache的数据放置的策略决定了内存中的数据块会拷贝到CPU Cache中的哪个位置上,因为Cache的大小远远小于内存,所以,需要有一种地址关联的算法,能够让内存中的数据可以被映射到Cache中来。这个有点像内存地址从逻辑地址向物理地址映射的方法,但不完全一样。
基本上来说,我们会有如下的一些方法。
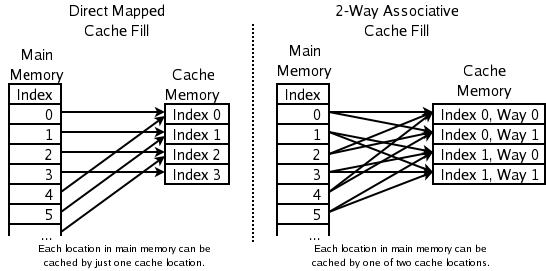
一种方法是,任何一个内存地址的数据可以被缓存在任何一个Cache Line里,这种方法是最灵活的,但是,如果我们要知道一个内存是否存在于Cache中,我们就需要进行O(n)复杂度的Cache遍历,这是很没有效率的。
另一种方法,为了降低缓存搜索算法,我们需要使用像Hash Table这样的数据结构,最简单的hash table就是做“求模运算”,比如:我们的L1 Cache有512个Cache Line,那么,公式:(内存地址 mod 512)* 64 就可以直接找到所在的Cache地址的偏移了。但是,这样的方式需要我们的程序对内存地址的访问要非常地平均,不然冲突就会非常严重。这成了一种非常理想的情况了。
为了避免上述的两种方案的问题,于是就要容忍一定的hash冲突,也就出现了 N-Way 关联。也就是把连续的N个Cache Line绑成一组,然后,先把找到相关的组,然后再在这个组内找到相关的Cache Line。这叫 Set Associativity。如下图所示。
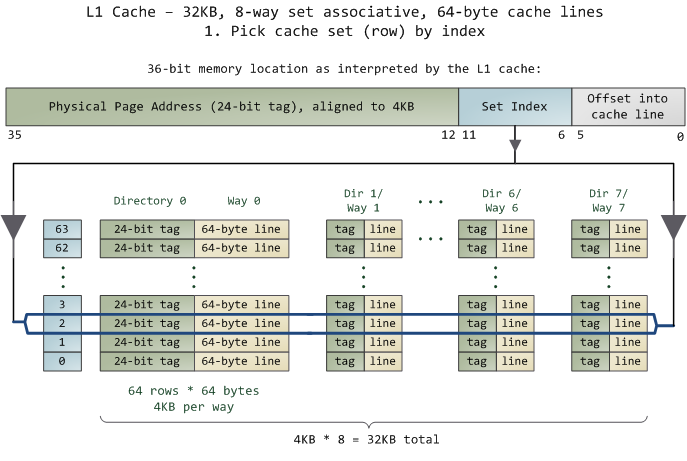
对于 N-Way 组关联,可能有点不好理解,这里个例子,并多说一些细节(不然后面的代码你会不能理解),Intel 大多数处理器的L1 Cache都是32KB,8-Way 组相联,Cache Line 是64 Bytes。这意味着,
32KB的可以分成,32KB / 64 = 512 条 Cache Line。
因为有8 Way,于是会每一Way 有 512 / 8 = 64 条 Cache Line。
于是每一路就有 64 x 64 = 4096 Byts 的内存。
为了方便索引内存地址,
Tag:每条 Cache Line 前都会有一个独立分配的 24 bits来存的 tag,其就是内存地址的前24bits
Index:内存地址后续的6个bits则是在这一Way的是Cache Line 索引,2^6 = 64 刚好可以索引64条Cache Line
Offset:再往后的6bits用于表示在Cache Line 里的偏移量
如下图所示:(图片来自《Cache: a place for concealment and safekeeping》)
当拿到一个内存地址的时候,先拿出中间的 6bits 来,找到是哪组。
然后,在这一个8组的cache line中,再进行O(n) n=8 的遍历,主是要匹配前24bits的tag。如果匹配中了,就算命中,如果没有匹配到,那就是cache miss,如果是读操作,就需要进向后面的缓存进行访问了。L2/L3同样是这样的算法。而淘汰算法有两种,一种是随机一种是LRU。现在一般都是以LRU的算法(通过增加一个访问计数器来实现)
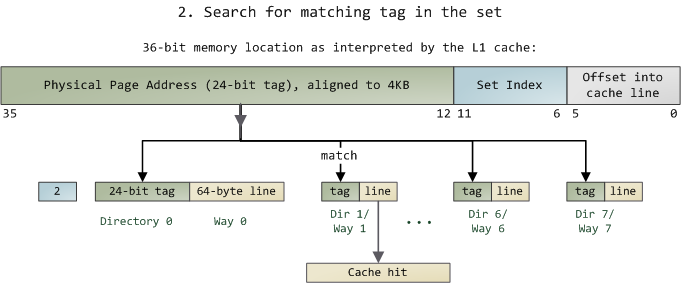
这也意味着:
L1 Cache 可映射 36bits 的内存地址,一共 2^36 = 64GB的内存
当CPU要访问一个内存的时候,通过这个内存中间的6bits 定位是哪个set,通过前 24bits 定位相应的Cache Line。
就像一个hash Table的数据结构一样,先是O(1)的索引,然后进入冲突搜索。
因为中间的 6bits 决定了一个同一个set,所以,对于一段连续的内存来说,每隔4096的内存会被放在同一个组内,导致缓存冲突。
此外,当有数据没有命中缓存的时候,CPU就会以最小为Cache Line的单元向内存更新数据。当然,CPU并不一定只是更新64Bytes,因为访问主存实在是太慢了,所以,一般都会多更新一些。好的CPU会有一些预测的技术,如果找到一种pattern的话,就会预先加载更多的内存,包括指令也可以预加载。这叫 Prefetching 技术 (参看,Wikipedia 的 Cache Prefetching 和 纽约州立大学的 Memory Prefetching)。比如,你在for-loop访问一个连续的数组,你的步长是一个固定的数,内存就可以做到prefetching。(注:指令也是以预加载的方式执行,参看本站的《代码执行的效率》中的第三个示例)
了解这些细节,会有利于我们知道在什么情况下有可以导致缓存的失效。
缓存的一致性
对于主流的CPU来说,缓存的写操作基本上是两种策略(参看本站《缓存更新的套路》),
一种是Write Back,写操作只要在cache上,然后再flush到内存上。
一种是Write Through,写操作同时写到cache和内存上。
为了提高写的性能,一般来说,主流的CPU(如:Intel Core i7/i9)采用的是Write Back的策略,因为直接写内存实在是太慢了。
好了,现在问题来了,如果有一个数据 x 在 CPU 第0核的缓存上被更新了,那么其它CPU核上对于这个数据 x 的值也要被更新,这就是缓存一致性的问题。(当然,对于我们上层的程序我们不用关心CPU多个核的缓存是怎么同步的,这对上层的代码来说都是透明的)
一般来说,在CPU硬件上,会有两种方法来解决这个问题。
Directory 协议。这种方法的典型实现是要设计一个集中式控制器,它是主存储器控制器的一部分。其中有一个目录存储在主存储器中,其中包含有关各种本地缓存内容的全局状态信息。当单个CPU Cache 发出读写请求时,这个集中式控制器会检查并发出必要的命令,以在主存和CPU Cache之间或在CPU Cache自身之间进行数据同步和传输。Snoopy 协议。这种协议更像是一种数据通知的总线型的技术。CPU Cache通过这个协议可以识别其它Cache上的数据状态。如果有数据共享的话,可以通过广播机制将共享数据的状态通知给其它CPU Cache。这个协议要求每个CPU Cache 都可以“窥探”数据事件的通知并做出相应的反应。如下图所示,有一个Snoopy Bus的总线。
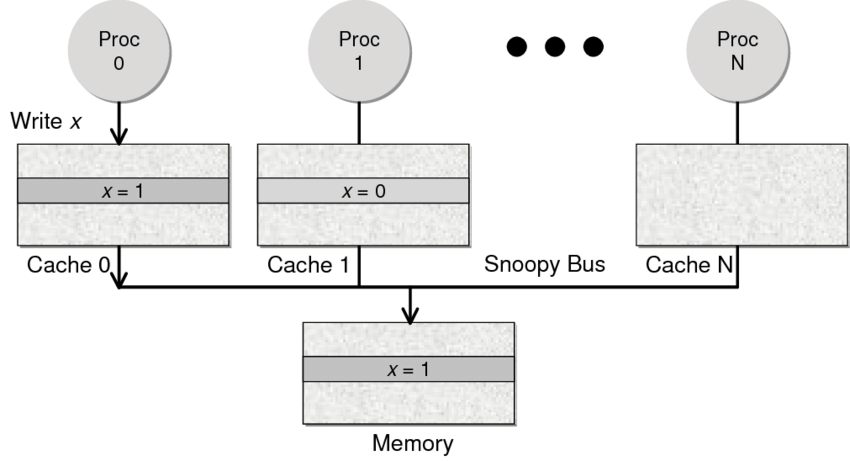
因为Directory协议是一个中心式的,会有性能瓶颈,而且会增加整体设计的复杂度。而Snoopy协议更像是微服务+消息通讯,所以,现在基本都是使用Snoopy的总线的设计。
这里,我想多写一些细节,因为这种微观的东西,不自然就就会更分布式系统相关联,在分布式系统中我们一般用Paxos/Raft这样的分布式一致性的算法。而在CPU的微观世界里,则不必使用这样的算法,原因是因为CPU的多个核的硬件不必考虑网络会断会延迟的问题。所以,CPU的多核心缓存间的同步的核心就是要管理好数据的状态就好了。
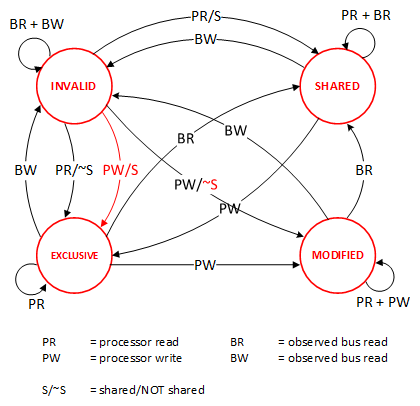
这里介绍几个状态协议,先从最简单的开始,MESI协议,这个协议跟那个著名的足球运动员梅西没什么关系,其主要表示缓存数据有四个状态:Modified(已修改), Exclusive(独占的),Shared(共享的),Invalid(无效的)。
这些状态的状态机如下所示(有点复杂,你可以先不看,这个图就是想告诉你状态控制有多复杂):
下面是个示例(如果你想看一下动画演示的话,这里有一个网页(MESI Interactive Animations),你可以进行交互操作,这个动画演示中使用的Write Through算法):
当前操作 CPU0 CPU1 Memory 说明
1) CPU0 read(x) x=1 (E) x=1 只有一个CPU有 x 变量,
所以,状态是 Exclusive
2) CPU1 read(x) x=1 (S) x=1(S) x=1 有两个CPU都读取 x 变量,
所以状态变成 Shared
3) CPU0 write(x,9) x=9 (M) x=1(I) x=1 变量改变,在CPU0中状态
变成 Modified,在CPU1中
状态变成 Invalid
4) 变量 x 写回内存 x=9 (M) X=1(I) x=9 目前的状态不变
5) CPU1 read(x) x=9 (S) x=9(S) x=9 变量同步到所有的Cache中,
状态回到Shared
MESI 这种协议在数据更新后,会标记其它共享的CPU缓存的数据拷贝为Invalid状态,然后当其它CPU再次read的时候,就会出现 cache miss 的问题,此时再从内存中更新数据。从内存中更新数据意味着20倍速度的降低。我们能不能直接从我隔壁的CPU缓存中更新?是的,这就可以增加很多速度了,但是状态控制也就变麻烦了。还需要多来一个状态:Owner(宿主),用于标记,我是更新数据的源。于是,现了 MOESI 协议
MOESI协议的状态机和演示示例我就不贴了,我们只需要理解MOESI协议允许 CPU Cache 间同步数据,于是也降低了对内存的操作,性能是非常大的提升,但是控制逻辑也非常复杂。
顺便说一下,与 MOESI 协议类似的一个协议是 MESIF,其中的 F 是 Forward,同样是把更新过的数据转发给别的 CPU Cache 但是,MOESI 中的 Owner 状态 和MESIF 中的 Forward 状态有一个非常大的不一样—— Owner状态下的数据是dirty的,还没有写回内存,Forward状态下的数据是clean的,可以丢弃而不用另行通知。
需要说明的是,AMD用MOESI,Intel用MESIF。所以,F 状态主要是针对 CPU L3 Cache 设计的(前面我们说过,L3是所有CPU核心共享的)。(相关的比较可以参看StackOverlow上这个问题的答案)
程序性能
了解了我们上面的这些东西后,我们来看一下对于程序的影响。
示例一
首先,假设我们有一个64M长的数组,设想一下下面的两个循环:
1 | const int LEN = 64*1024*1024; |
按我们的想法来看,第二个循环要比第一个循环少4倍的计算量,其应该也是要快4倍的。但实际跑下来并不是,在我的机器上,第一个循环需要127毫秒,第二个循环则需要121毫秒,相差无几。这里最主要的原因就是 Cache Line,因为CPU会以一个Cache Line 64Bytes最小时单位加载,也就是16个32bits的整型,所以,无论你步长是2还是8,都差不多。而后面的乘法其实是不耗CPU时间的。
示例二
我们再来看一个与缓存命中率有关的代码,我们以一定的步长increment 来访问一个连续的数组。
1 | for (int i = 0; i < 10000000; i++) { |
我们测试一下,在下表中, 表头是步长,也就是每次跳多少个整数,而纵向是这个数组可以跳几次(你可以理解为要几条Cache Line),于是表中的任何一项代表了这个数组有多少,而且步长是多少。比如:横轴是 512,纵轴是4,意思是,这个数组有 4*512 = 2048 个长度,访问时按512步长访问,也就是访问其中的这几项:[0, 512, 1024, 1536] 这四项。
表中同的项是,是循环1000万次的时间,单位是“微秒”(除以1000后是毫秒)
| count | 1 | 16 | 512 | 1024 |
| 1 | 17539 | 16726 | 15143 | 14477 |
| 2 | 15420 | 14648 | 13552 | 13343 |
| 3 | 14716 | 14463 | 15086 | 17509 |
| 4 | 18976 | 18829 | 18961 | 21645 |
| 5 | 23693 | 23436 | 74349 | 29796 |
| 6 | 23264 | 23707 | 27005 | 44103 |
| 7 | 28574 | 28979 | 33169 | 58759 |
| 8 | 33155 | 34405 | 39339 | 65182 |
| 9 | 37088 | 37788 | 49863 |156745 |
| 10 | 41543 | 42103 | 58533 |215278 |
| 11 | 47638 | 50329 | 66620 |335603 |
| 12 | 49759 | 51228 | 75087 |305075 |
| 13 | 53938 | 53924 | 77790 |366879 |
| 14 | 58422 | 59565 | 90501 |466368 |
| 15 | 62161 | 64129 | 90814 |525780 |
| 16 | 67061 | 66663 | 98734 |440558 |
| 17 | 71132 | 69753 |171203 |506631 |
| 18 | 74102 | 73130 |293947 |550920 |
我们可以看到,从 [9,1024] 以后,时间显著上升。包括 [17,512] 和 [18,512] 也显著上升。这是因为,我机器的 L1 Cache 是 32KB, 8 Way 的,前面说过,8 Way的有64组,每组8个Cache Line,当for-loop步长超过1024个整型,也就是正好 4096 Bytes时,也就是导致内存地址的变化是变化在高位的24bits上,而低位的12bits变化不大,尤其是中间6bits没有变化,导致全部命中同一组set,导致大量的cache 冲突,导致性能下降,时间上升。而 [16, 512]也是一样的,其中的几步开始导致L1 Cache开始冲突失效。
示例三
接下来,我们再来看个示例。下面是一个二维数组的两种遍历方式,一个逐行遍历,一个是逐列遍历,这两种方式在理论上来说,寻址和计算量都是一样的,执行时间应该也是一样的。
1 | const int row = 1024; |
然而,并不是,在我的机器上,得到下面的结果。
逐行遍历:0.081ms
逐列遍历:1.069ms
执行时间有十几倍的差距。其中的原因,就是逐列遍历对于CPU Cache 的运作方式并不友好,所以,付出巨大的代价。
示例四
接下来,我们来看一下多核下的性能问题,参看如下的代码。两个线程在操作一个数组的两个不同的元素(无需加锁),线程循环1000万次,做加法操作。在下面的代码中,我高亮了一行,就是p2指针,要么是p[1],或是 p[30],理论上来说,无论访问哪两个数组元素,都应该是一样的执行时间。
1 | void fn (int* data) { |
int p[32];
int p1 = &p[0];
int p2 = &p[1];
thread t1(fn, p1);
thread t2(fn, p2);
然而,并不是,在我的机器上执行下来的结果是:
对于 p[0] 和 p[1] :560ms
对于 p[0] 和 p[30]:104ms
这是因为 p[0] 和 p[1] 在同一条 Cache Line 上,而 p[0] 和 p[30] 则不可能在同一条Cache Line 上 ,CPU的缓存最小的更新单位是Cache Line,所以,这导致虽然两个线程在写不同的数据,但是因为这两个数据在同一条Cache Line上,就会导致缓存需要不断进在两个CPU的L1/L2中进行同步,从而导致了5倍的时间差异。
示例五
接下来,我们再来看一下另外一段代码:我们想统计一下一个数组中的奇数个数,但是这个数组太大了,我们希望可以用多线程来完成这个统计。下面的代码中,我们为每一个线程传入一个 id ,然后通过这个 id 来完成对应数组段的统计任务。这样可以加快整个处理速度。
1 | int total_size = 16 * 1024 * 1024; |
然而,在执行过程中,你会发现,6个线程居然跑不过1个线程。因为根据上面的例子你知道 result[] 这个数组中的数据在一个Cache Line中,所以,所有的线程都会对这个 Cache Line 进行写操作,导致所有的线程都在不断地重新同步 result[] 所在的 Cache Line,所以,导致 6 个线程还跑不过一个线程的结果。这叫 False Sharing。
优化也很简单,使用一个线程内的变量。
1 | void thread_func (int id) { |
我们把两个程序分别在 1 到 32 个线程上跑一下,得出的结果画一张图如下所示(横轴是线程数,纵轴是完成统的时间,单位是微秒):

上图中,我们可以看到,灰色的曲线就是第一种方法,橙色的就是第二种(用局部变量的)方法。当只有一个线程的时候,两个方法相当,基本没有什么差别,但是在线程数增加的时候的时候,你会发现,第二种方法的性能提高的非常快。直到到达6个线程的时候,开始变得稳定(前面说过,我的CPU是6核的)。而第一种方法无论加多少线程也没有办法超过第二种方法。因为第一种方法不是CPU Cache 友好的。也就是说,第二种方法,只要我的CPU核数足够多,就可以做到线性的性能扩展,让每一个CPU核都跑起来,而第一种则不能。
篇幅问题,示例就写到这里,相关的代码参看我的Github相关仓库。
延伸阅读
Wikipedia : CPU Cache
经典文章:Gallery of Processor Cache Effects (这篇文章中的测试已经有点过时了,但是这篇文章中所说的那些东西还是非常适用的)
Effective C++作者 Scott Meyers 的演讲 CPU Caches and Why You Care (Youtube,PPT)
美国私立大学Swarthmore的教材 Cache Architecture and Design
经典文章:What Every Programmer Should Know About Memory (这篇文章非常经典,但是开篇太晦涩了,居然告诉你晶体管内的构造,第三章和第六章是重点)
Nonblocking Algorithms and Scalable Multicore Programming (英文版,中文版)
Github上的一个代码库 hardware-effects 里面有受CPU影响的程序的演示
Optimizing for instruction caches (Part 1,Part 2, Part 3)
经典数据:Latency Numbers Every Programmer Should Know
关于Java的可以看一下这篇Optimizing Memory Access With CPU Cache 或是 Writing cache-friendly code
总之,这个CPU Cache的调优技术不是什么新鲜的东西,只要Google就能找到有很多很多文章……
(全文完)
关注CoolShell微信公众账号和微信小程序
兵进光刻机,中国芯片血勇突围战

中美贸易摩擦从2018年开始不断升级,影响全球,其中技术封锁和非法断供是美国一系列施压措施的武器之一,以打击国内一批高科技企业。首当其冲就是芯片半导体产业。
2018年美国制裁中兴的手段立竿见影,正是锁住了国内企业在芯片产业上无法自主的咽喉。
而华为能够抵挡到现在的关键,也是因为华为本身的海思芯片业务发展得风生水起。
但前不久,IT之家报道了台积电因美国施压可能无法向华为稳定供货14nm芯片的消息,虽然还不确定结果,但不得不令人担忧。
根据美国《出口管理条例》的限制,产品涵盖硬件、软件等的美国技术含量超过25%,就会被要求禁止销售给中国。
哪怕国外制造,但源自美国的内容超过25%,也在限制范围内。
报道中称,台积电内部评估,其7nm工艺源自美国技术比重不到10%,14nm比重大约15%。
这意味着若美国真的将“源自美国技术”的标准从25%下调至10%,那么14nm芯片的供货将受到限制。
作为台积电重要客户之一,华为将深受不利影响。更让人担忧的是,万一未来7nm、甚至5nm芯片供应也被限制,那华为无疑也将被扼住7寸。
芯片行业的玩家大概能分成三种:IDM、Foundry和Fabless。
IDM意思是芯片的设计、制造、封测都能做,有完整能力,像三星;Foundry的意思是只做代工,例如台积电;Fabless就是专注于芯片设计与销售,例如华为海思。
是的,华为海思只负责做芯片的产品设计和销售,不具备制造、封测的能力,所以要依赖代工厂。
而纵观国际市场,能满足华为代工要求的,只有三星和台积电两家。三星本身和华为有着竞争关系,所以一直以来华为和台积电合作紧密。
但如果这次台积电在美国的施压下停止对华为14nm芯片供货,后果很难想象。
并且最近市场还有传闻,台积电担心华为过度建立库存,因而减少华为7nm芯片的供货,重新分配产能。
最终结果还未可知,但这些消息都在给我们敲响警钟:一旦我们依赖的供应商断货,我们将束手无策。
而这一天很可能来得比想象中快,就像去年美国政府将华为列入实体清单,几天之后谷歌就暂停了安卓和其他服务对华为的支持。
风暴来临的速度永远会让人措手不及。
中芯国际,买一台EUV光刻机好难
还好华为意识到了这一点,IT之家之前也报道,华为正积极将14nm芯片订单转交给大陆芯片代工厂中芯国际。

中芯国际2019年已经成功实现第一代14纳米FinFET工艺量产。2020年1月14日,中芯南方厂投产国内首条14nm生产线,月产能可达到3.5万片。同时,他们的12nm技术已经进入客户导入阶段,这是一个令人振奋的消息。
对于目前十分关键的7nm工艺,中芯国际早在2017年就开始布局,并打算在今年年内进行风险试产。
但是,目前有一个问题横亘在面前:他们缺少一台7nm EUV光刻机。这是决定能否大规模量产7nm芯片的关键设备。
根据日媒披露,中芯国际在2018年就向荷兰光刻机巨头ASML订购了一台EUV光刻机。
ASML是目前全球唯一能生产这种设备的厂商。双方计划的是2019年初交付设备。
然而,这台光刻机的交付之路可谓崎岖多舛,但直到目前,仍然没有在中国落地。
2018年末,就在接近7nm EUV光刻机向中芯国际交付的时间点上,ASML的元器件供应商Prodrive突遇火灾,工厂部分库存、生产线被烧毁,2019年的交货计划也被迫延迟。

然后,英国路透社称援引不具名的知情人士消息,美国政府从2018年开始就与荷兰官员至少进行了4轮会谈,企图阻止ASML向中国出售EUV光刻机。为此美国国务卿蓬佩奥甚至亲自游说荷兰政府。
兵进光刻机,中国芯片血勇突围战
这中间,还有荷兰当地媒体报道称ASML美国子公司的中国员工窃取ASML的技术并泄露给中国企业的事件。
兵进光刻机,中国芯片血勇突围战
……
不过好在,ASML方面都及时作出了澄清,他们表示媒体有关“延迟交货”的说法是存在错误的,所谓“中国间谍”窃取技术的事件也存在误读,ASML只是在几年前被硅谷的一小部分员工侵犯了知识产权,其中恰好部分涉案员工是中国人而已。
兵进光刻机,中国芯片血勇突围战
他们表示:不会对中国断供光刻机。
同时ASML解释了EUV光刻机目前还没有交货的原因:
根据瓦圣纳协议,ASML出口EUV到中国,必须取得荷兰政府出口许可,但该出口许可在今年到期,所以ASML在到期前重新进行申请,目前正等待荷兰政府核准。
只是到目前,这台EUV光刻机究竟何时交付,还是未知数。
从沙子到芯片
说到这里,可能有IT之家小伙伴仍然不清楚光刻机对于芯片行业的重要意义,它到底是什么?汐元利用这一节给大家科普一下。
首先要从一枚芯片到底是什么制造出来的说起。
我们经常听说,芯片是沙子做成的。没错。芯片制造第一步就是将沙子液态化,然后去除杂质,提取高纯度的硅。
兵进光刻机,中国芯片血勇突围战
▲高温熔化的沙子
接着通过精密控制温度和旋转的速度,将硅拉成硅棒。然后将硅棒切成一片一片的,形成晶圆。
兵进光刻机,中国芯片血勇突围战
▲拉硅棒
兵进光刻机,中国芯片血勇突围战
▲切成晶圆
晶圆需要进一步处理,包括在表面形成矽化合物、植入离子、化学气相沉积等各种操作,最后在晶圆表面覆盖光阻(一种光敏材料)。
兵进光刻机,中国芯片血勇突围战
▲形成化合物
兵进光刻机,中国芯片血勇突围战
▲植入离子
这些通常被统称为“光刻胶”。
兵进光刻机,中国芯片血勇突围战
▲形成光阻材料
然后,关键的操作来了,我们需要将芯片设计师设计的电路图写到很多层的光罩(掩膜)上,然后用光源透过光罩,像幻灯机一样把光罩上的电路图显影在晶圆表面。
兵进光刻机,中国芯片血勇突围战
▲投影
由于光敏材料和光的反应,等于将电路图“画”在了晶圆上。
这个过程就是光刻,需要符合要求的光刻机才能完成。
接下来,还要对已经显影了电路图的晶圆进行蚀刻、物理气相沉积等操作,就是给晶圆表面的元件加入金属导线。
兵进光刻机,中国芯片血勇突围战
▲蚀刻
然后,就是对晶圆进行化学机械研磨,使晶圆表面的材质平坦化。
最后,就是对晶圆进行切割、封装、测试等,最终形成我们使用的芯片。
虽然汐元几句话说完了,但是实际生产的时候,前后可多达5000道工序,极度复杂。
回到刚才说到的光刻环节。光刻光刻,是把光当作刀子一样在晶圆表面刻画电路图。所以,这里的光源,非常重要。
光源的精密程度,决定了写入晶圆的电路的精密程度,也就决定了芯片上的晶体管能做多小,这,也就和我们挂在嘴边的XX纳米工艺直接相关。
怎样定义这个精密程度呢?答案就是光源的波长。
翻一下电磁波的波谱,可以发现在所有的光线中,紫外线的波长几乎是最短的了。

所以,整个半导体制程的进化过程就是考虑怎么使用波长更短的紫外光的过程。
给大家看一张表格:

在此之前,行业里主流的光刻机使用的是DUV深紫外光源。深紫外光源就是波长短于300nm的紫外光线,主要使用的是KrF和ArF两个波段,他们制造40nm制程以下半导体已经比较吃力了。
但是科技厂商们发挥聪明才智,一直让DUV的支持延续到了10nm甚至7nm(也就是所谓的第一代7nm工艺),但是再往下,DUV就真Hold不住了,只能使用波长为13nm左右的EUV极紫外光线。
我们知道,工艺制程越小,技术挑战的难度就越高,当工艺制程小于10nm的时候,逼进物理极限,摩尔定律也面临失效,这种极限挑战下,需要投入的技术资源以及研发资金是不可想象的,全球其实没有多少家半导体企业能支撑。
而当今世界,唯一能够造出EUV极紫外光刻机的,就是ASML。所以它被人们誉为“摩尔定律的拯救者”。
EUV光刻机,到底难在哪里?
可能有IT之家小伙伴会问:为什么只有ASML能造出EUV光刻机呢?这个EUV光刻机到底难在哪里?
我们首先需要明白EUV光刻机的工作原理。当然,细节极度复杂,汐元尽量用简单的话讲清楚。
上一节我们讲过,光刻这部分原理其实很简单,就是让光透过写有电路图的多层光罩,将电路图显影在晶圆上。
兵进光刻机,中国芯片血勇突围战
▲再看一遍这个图
所以有两个关键点,一个是光源,一个是光罩。
极紫外光源怎么产生?方法不止一种,ASML的办法是,用强烈的雷射光两次轰击“锡液滴”,就可以产生波长13.5nm的极紫外光。
兵进光刻机,中国芯片血勇突围战
▲轰击锡液滴
然后,利用复杂的光学结构将极紫外光变成极紫外光雷射。
具体的方法大家不用了解,涉及高端的化学知识和光学知识。
变成的雷射光还要经过一段复杂的照明光学系统,目的是将雷射光整形成需要的样子,然后通过光罩来成像。
兵进光刻机,中国芯片血勇突围战
▲图自ASML官方
这里有一点,前面我们说的,过去的光刻机是光线穿透光罩成像,像幻灯机一样。
但是极紫外光不一样,它很脆弱,会被光罩的材料吸收。这是个难点,对光学系统的要求极高。
为了避免极紫外光被吸收,EUV光刻机中,必须使用反射式光罩来成像。
兵进光刻机,中国芯片血勇突围战
EUV光刻机的原理基本就是这样。说起来简单,但实际有很多难点:
首先,如何让雷射准确击中锡液滴?而且是前脉冲和主脉冲能够击中锡液滴2次,同时每秒钟击50000次。怎么样,吓人吧。
兵进光刻机,中国芯片血勇突围战
再就是刚才说的,EUV光产生后,还需要经过复杂的光学系统,怎么样让光不被光学镜片吸收,保证转换效率?这需要极端强大的光学技术支持。
兵进光刻机,中国芯片血勇突围战
还有一个问题是电源,目前的电源无法产生足够的功率让EUV大幅度提高效率。
然后,还有光刻胶光阻的敏感度、光子散射噪音引起的随机现象等,都是EUV光刻机面临的问题。
有数据说,每台EUV光刻机有超过10万个零件、3千条电线、4万个螺栓、2公里长的软管等零组件,最大重量达180公吨。
制造难度可想而知。
这样一台光刻机多少钱呢?
根据媒体报道,此前中芯国际订购的EUV光刻机是1.2亿欧元,相当于人民币9亿多元,而先进的EUV光刻机可以达到1.5亿美元,约合人民币10亿元!这比美国第四代战斗机F35的价格还贵!
虽然这么贵,但想买EUV光刻机还不止是钱的问题,关键是它的产量极低,ASML一年也就能生产十几到二十台EUV光刻机,全球那么多半导体企业,争破头皮也不一定买得到。
ASML,舍我其谁的背后
那么ASML凭什么能造出这种设备呢?
这家公司的崛起之路其实也颇为曲折,日后有时间汐元可以详细为大家讲一讲。
兵进光刻机,中国芯片血勇突围战
简单来说,其实早期的光刻机制造并不复杂,最早是日本的尼康和佳能进入这个领域,但后来让美国的Perkin Elmer和GCA公司捷足先登。
不过尼康和佳能也不是吃素的,在上世纪80年代,逐步击败前面两家美国公司。
那个时候,还没有ASML什么事,他们在1984年成立,当时只是飞利浦的一个小部门。
兵进光刻机,中国芯片血勇突围战
不过他们很给力,第二年就和蔡司合作改进光学系统,1986年就推出了自家很棒的第二代产品PAS-2500。
兵进光刻机,中国芯片血勇突围战
到了八十年代末,GCA衰亡,Perkin Elmer卖身给美国另一家巨头光刻机SVG。但后来,SVG发展也不行了,在2000年被ASML收购,ASML在这次收购中获得了关键的反射技术。
90年代末21世纪初,行业需要超越193nm的解决方案,这实际上是ASML和尼康的决战。ASML在2002年接受台积电提出的浸入式193nm的技术方案,光源也就是DUV深紫外光。
而尼康作了一回死,它和英特尔合作一起研发了一个非常超前的技术,结果失败了。
于是ASML从此逐渐超越尼康,成为光刻机领域的霸主。后来英特尔离开了尼康,转身投向ASML阵营。
至于EUV光刻机,其实最早是英特尔牵头搞的,还联合很多公司以及实验室成立了一个专门研究EUV的组织,其中就包括ASML。
后来这个组织解散了,就剩ASML还笃定要做EUV。
2012年,英特尔、三星和台积电分别以41亿、5.03亿、8.38亿欧元入股ASML,因为要打造EUV光刻机,耗资巨大。

当然,英特尔、三星和台积电也没吃亏,后来事实证明,他们不仅享有EUV光刻机的优先供货权,并且由于ASML股价暴涨,在后来出售或减持ASML股份时,这三巨头都获利颇丰。
从这简短的发展历程能看出,之所以只有ASML能造出EUV光刻机,汐元总结,有三个原因:
一是几十年技术积淀,足够耐心。
这个积淀有两个途径,一个是自身研发投入,另一个是并购,例如前面说的,收购SVG获得了关键的反射技术,还有收购美国光学技术供应商Cymer得到了光源技术,收购蔡司半导体公司24.9%的股权,并与之共同研发最顶尖的光学技术。
二是赌对了技术方向,能制造7nm工艺的芯片技术不止一种,但EUV是比较可行的;
第三点,也是最重要的,不缺钱,不缺资源。
ASML有一项独特的规定,就是要想获得光刻机的优先供货权,必须入股自己,这样就等于将半导体巨头们绑定成利益共同体,无论是资金还是技术资源,都有保证。
其实,ASML光刻机设备90%的零部件都依赖外购,正是因为和众多技术供应商形成利益共同体的关系,ASML才能整合最顶尖的资源来办大事。
八,国产光刻机,走在曲折但奋进的路上
ASML虽然伟大,但毕竟是别人家的。
本文开头对当前局势的分析,相信IT之家小伙伴们也很清楚,对于中国来说,只有自己掌握了核心科技,才能不被外界掣肘。
所以最后一节,我们回到文章开头所说情势,聊一聊国产光刻机目前的发展现状。
中国对光刻机的研究起步并不晚,大概在上世纪70年代,早期的型号主要是接触式光刻机。所谓接触式光刻机,也就是光罩贴在晶圆上的。中科院1445所在1977年研制出了一台接触式光刻机,比美国晚了二十年左右。
1985年,机电部45所研制出了第一台分步投影式光刻机,而美国在1978年研制出这种光刻机,当时使用的是436nm G线光源
90年代的时候,国内光刻机在技术上和国外其实相差还不远,大概相当于国外80年代中期的水平。
不过要知道,光刻机这种东西,工艺(即采用光源的波长)每向前进一个台阶,制造的难度、需要的资金,都是指数级增长的,越往后越难搞。
2000年开始,我国开始启动研究193nm ArF光刻机的项目。正如前文所说,那个时候ASML已经正在研究EUV光刻机了。
2002年,光刻机被列入国家863重大科技攻关计划,由科技部和上海市共同推动成立上海微电子装备有限公司来承担。

上海微电子基本上也代表了目前国产光刻机的最高水平。经过十多年的发展,目前其自主研发的600系列光刻机可以实现90nm制程工艺芯片的量产,使用的还是193nm ArF光源。

很明显,从制程工艺的角度上看,国产光刻机目前和ASML差距非常大。不过,国际上其他国家也基本没有量产157nm及以下光刻机的,从这个角度看,国产光刻机和除ASML之外的国际水准也并未落后多少。
目前上海微电子还在研究为65nm制程芯片服务的光刻机,什么时候能够做出来,还不好说。
还有的,就是一些实验室取得的成果,以及一些媒体误读。
例如2019年4月,武汉光电国家研究中心的甘棕松团队成功研发出9nm工艺光刻机,这个就还是实验室里取得的成果,使用的也不是ASML的那一套方案。
再例如2018年11月,中国科学院光电技术研究所“超分辨光刻装备研制”项目通过验收,实现了22nm的分辨率,引起媒体一阵沸腾。
但其实,这个设备基本上可以说并不是用来制造芯片的,距离制造芯片也非常遥远。
所以这里也说明一下,光刻机不仅是用来制造芯片的,也可以用来制造一些光学领域的其他器件等。
总之,目前国产光刻机能实现的制程水平还卡在90nm,和ASML差距明显,高端光刻机还是要靠进口。
世界局势风云变幻,现实不断催促我们必须尽快在半导体技术领域有所突破。
但是,在这个产业里,其实也没有什么捷径或者弯道超车的路可走,只有一个制程节点一个制程节点地去攻破,积淀技术。想要追赶国际领先的水平,只有付出更多的精力,投入更多的资源。
光刻机,当然至关重要,但并不是说,花钱买来一台EUV光刻机,中国半导体产业就能一跃而上。
同时,这个行业进化节奏之快,对于科研人员来说,也没有太多成绩上的激励,必须十年甚至几十年如一日地沉下心来去做。
而这,是ASML能够崛起的原因,也是我们想要实现追赶的唯一途径。
Experience
MIPS
是一种开源的 CPU 架构,据报道目前形势很不妙。核心维护者只剩下一个人,拥有它的公司已经申请破产。预计这个架构应该不久就会正式死掉。
