
本书倡导在计算机迅速发展、技术不断革新的今天,回归到计算机的基础知识上。通过探究计算机的本质,提升工程师对计算机的兴趣,在面对复杂的最新技术时,能够迅速掌握其要点并灵活运用。
本书以图配文,以计算机的三大原则为开端、相继介绍了计算机的结构、手工汇编、程序流程、算法、数据结构、面向对象编程、数据库、TCP/IP 网络、数据加密、XML、计算机系统开发以及SE 的相关知识。
图文并茂,通俗易懂,非常适合计算机爱好者和相关从业人员阅读。
回车和换行
作者: 阮一峰
日期: 2006年4月30日
今天,我总算搞清楚”回车”(carriage return)和”换行”(line feed)这两个概念的来历和区别了。
在计算机还没有出现之前,有一种叫做电传打字机(Teletype Model 33)的玩意,每秒钟可以打10个字符。但是它有一个问题,就是打完一行换行的时候,要用去0.2秒,正好可以打两个字符。要是在这0.2秒里面,又有新的字符传过来,那么这个字符将丢失。
于是,研制人员想了个办法解决这个问题,就是在每行后面加两个表示结束的字符。一个叫做”回车”,告诉打字机把打印头定位在左边界;另一个叫做”换行”,告诉打字机把纸向下移一行。
这就是”换行”和”回车”的来历,从它们的英语名字上也可以看出一二。
后来,计算机发明了,这两个概念也就被般到了计算机上。那时,存储器很贵,一些科学家认为在每行结尾加两个字符太浪费了,加一个就可以。于是,就出现了分歧。
Unix系统里,每行结尾只有”<换行>”,即”\n”;Windows系统里面,每行结尾是”<回车><换行>”,即”\r\n”;Mac系统里,每行结尾是”<回车>”。一个直接后果是,Unix/Mac系统下的文件在Windows里打开的话,所有文字会变成一行;而Windows里的文件在Unix/Mac下打开的话,在每行的结尾可能会多出一个^M符号。
关于2的补码
作者: 阮一峰
日期: 2009年8月 5日
珠峰培训
问一个基本的问题。
负数在计算机中如何表示?
举例来说,+8在计算机中表示为二进制的1000,那么-8怎么表示呢?
很容易想到,可以将一个二进制位(bit)专门规定为符号位,它等于0时就表示正数,等于1时就表示负数。比如,在8位机中,规定每个字节的最高位为符号位。那么,+8就是00001000,而-8则是10001000。
但是,随便找一本《计算机原理》,都会告诉你,实际上,计算机内部采用2的补码(Two’s Complement)表示负数。
什么是2的补码?
它是一种数值的转换方法,要分二步完成:
第一步,每一个二进制位都取相反值,0变成1,1变成0。比如,00001000的相反值就是11110111。
第二步,将上一步得到的值加1。11110111就变成11111000。
所以,00001000的2的补码就是11111000。也就是说,-8在计算机(8位机)中就是用11111000表示。
不知道你怎么看,反正我觉得很奇怪,为什么要采用这么麻烦的方式表示负数,更直觉的方式难道不好吗?
昨天,我在一本书里又看到了这个问题,然后就花了一点时间到网上找资料,现在总算彻底搞明白了。
2的补码的好处
首先,要明确一点。计算机内部用什么方式表示负数,其实是无所谓的。只要能够保持一一对应的关系,就可以用任意方式表示负数。所以,既然可以任意选择,那么理应选择一种最方便的方式。
2的补码就是最方便的方式。它的便利体现在,所有的加法运算可以使用同一种电路完成。
还是以-8作为例子。
假定有两种表示方法。一种是直觉表示法,即10001000;另一种是2的补码表示法,即11111000。请问哪一种表示法在加法运算中更方便?
随便写一个计算式,16 + (-8) = ?
16的二进制表示是 00010000,所以用直觉表示法,加法就要写成:
00010000
+10001000
---------
10011000
可以看到,如果按照正常的加法规则,就会得到10011000的结果,转成十进制就是-24。显然,这是错误的答案。也就是说,在这种情况下,正常的加法规则不适用于正数与负数的加法,因此必须制定两套运算规则,一套用于正数加正数,还有一套用于正数加负数。从电路上说,就是必须为加法运算做两种电路。
现在,再来看2的补码表示法。
00010000
+11111000
---------
100001000
可以看到,按照正常的加法规则,得到的结果是100001000。注意,这是一个9位的二进制数。我们已经假定这是一台8位机,因此最高的第9位是一个溢出位,会被自动舍去。所以,结果就变成了00001000,转成十进制正好是8,也就是16 + (-8) 的正确答案。这说明了,2的补码表示法可以将加法运算规则,扩展到整个整数集,从而用一套电路就可以实现全部整数的加法。
2的补码的本质
在回答2的补码为什么能正确实现加法运算之前,我们先看看它的本质,也就是那两个步骤的转换方法是怎么来的。
要将正数转成对应的负数,其实只要用0减去这个数就可以了。比如,-8其实就是0-8。
已知8的二进制是00001000,-8就可以用下面的式子求出:
00000000
-00001000
---------
因为00000000(被减数)小于0000100(减数),所以不够减。请回忆一下小学算术,如果被减数的某一位小于减数,我们怎么办?很简单,问上一位借1就可以了。
所以,0000000也问上一位借了1,也就是说,被减数其实是100000000,算式也就改写成:
100000000
-00001000
---------
11111000
进一步观察,可以发现100000000 = 11111111 + 1,所以上面的式子可以拆成两个:
11111111
-00001000
---------
11110111
+00000001
---------
11111000
2的补码的两个转换步骤就是这么来的。
为什么正数加法适用于2的补码?
实际上,我们要证明的是,X-Y或X+(-Y)可以用X加上Y的2的补码完成。
Y的2的补码等于(11111111-Y)+1。所以,X加上Y的2的补码,就等于:
X + (11111111-Y) + 1
我们假定这个算式的结果等于Z,即 Z = X + (11111111-Y) + 1
接下来,分成两种情况讨论。
第一种情况,如果X小于Y,那么Z是一个负数。这时,我们就对Z采用2的补码的逆运算,求出它对应的正数绝对值,再在前面加上负号就行了。所以,
Z = -[11111111-(Z-1)] = -[11111111-(X + (11111111-Y) + 1-1)] = X - Y
第二种情况,如果X大于Y,这意味着Z肯定大于11111111,但是我们规定了这是8位机,最高的第9位是溢出位,必须被舍去,这相当于减去100000000。所以,
Z = Z - 100000000 = X + (11111111-Y) + 1 - 100000000 = X - Y
这就证明了,在正常的加法规则下,可以利用2的补码得到正数与负数相加的正确结果。换言之,计算机只要部署加法电路和补码电路,就可以完成所有整数的加法。
每行字符数(CPL)的起源
作者: 阮一峰
日期: 2011年10月23日
前几天,我收到网友小龙的Email。
他想与我讨论一个问题:
“各种计算机语言的编码风格,有的建议源码每行的字符数(characters per line)不超过72个,还有的建议不超过80个,这是为什么?区别在哪里?怎么来的?”
我一下子就被问住了。
命令行状态下,终端窗口的显示宽度,默认是80个字符,这个我早就知道,但是并不清楚原因;至于72个字符,更是从未注意过。
幸好,世界上还有Wikipedia,我在里面找到了答案。

每行72个字符的限制,来源于打字机。上图是20世纪60年代初,非常流行的IBM公司生产的Selectric电动打字机。

当时,美国最通用的信笺大小是8.5英寸x11英寸(215.9 mm × 279.4 mm),叫做US Letter。打字的时候,左右两边至少要留出1英寸的页边距,因此每行的长度实际为6英寸。打字机使用等宽字体(monospaced)的情况下,每英寸可以打12个字符,就相当于一行72个字符。

早期,源码必须用打字机打出来阅读,所以有些语言就规定,每行不得超过72个字符。直到今天,RFC文档依然采用这个规定,因为它从诞生起就采用打字稿的形式。

20世纪70年代,显示器出现了。它的主要用途之一,是将打孔卡(punched card)的输入显示出来。当时,最流行的打孔卡是IBM公司生产的80栏打孔卡,每栏为一个字符,80栏就是80个字符。
上图是一张Fortran语言的源码填写单,一共有80栏,程序员在每一栏选择想要输入的字符,最多为80个字符。

然后,用机器自动生成打孔卡,在每栏选定的位置打一个孔。
计算机读取打孔卡以后,把每个孔转换为相应的字符。如果显示器每行显示80个字符,就正好与打孔卡一一对应,终端窗口的每行字符数(CPL)就这样确定下来了。
(完)
EOF是什么?
作者: 阮一峰
日期: 2011年11月12日
我学习C语言的时候,遇到的一个问题就是EOF。
它是end of file的缩写,表示”文字流”(stream)的结尾。这里的”文字流”,可以是文件(file),也可以是标准输入(stdin)。
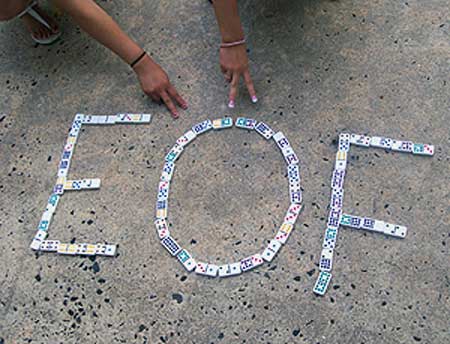
比如,下面这段代码就表示,如果不是文件结尾,就把文件的内容复制到屏幕上。
int c;
while ((c = fgetc(fp)) != EOF) {
putchar (c);
}
很自然地,我就以为,每个文件的结尾处,有一个叫做EOF的特殊字符,读取到这个字符,操作系统就认为文件结束了。
但是,后来我发现,EOF不是特殊字符,而是一个定义在头文件stdio.h的常量,一般等于-1。
#define EOF (-1)
于是,我就困惑了。
如果EOF是一个特殊字符,那么假定每个文本文件的结尾都有一个EOF(也就是-1),还是可以做到的,因为文本对应的ASCII码都是正值,不可能有负值。但是,二进制文件怎么办呢?怎么处理文件内部包含的-1呢?
这个问题让我想了很久,后来查了资料才知道,在Linux系统之中,EOF根本不是一个字符,而是当系统读取到文件结尾,所返回的一个信号值(也就是-1)。至于系统怎么知道文件的结尾,资料上说是通过比较文件的长度。
所以,处理文件可以写成下面这样:
int c;
while ((c = fgetc(fp)) != EOF) {
do something
}
这样写有一个问题。fgetc()不仅是遇到文件结尾时返回EOF,而且当发生错误时,也会返回EOF。因此,C语言又提供了feof()函数,用来保证确实是到了文件结尾。上面的代码feof()版本的写法就是:
int c;
while (!feof(fp)) {
c = fgetc(fp);
do something;
}
但是,这样写也有问题。fgetc()读取文件的最后一个字符以后,C语言的feof()函数依然返回0,表明没有到达文件结尾;只有当fgetc()向后再读取一个字符(即越过最后一个字符),feof()才会返回一个非零值,表示到达文件结尾。
所以,按照上面这样写法,如果一个文件含有n个字符,那么while循环的内部操作会运行n+1次。所以,最保险的写法是像下面这样:
int c = fgetc(fp);
while (c != EOF) {
do something;
c = fgetc(fp);
}
if (feof(fp)) {
printf(“\n End of file reached.”);
} else {
printf(“\n Something went wrong.”);
}
除了表示文件结尾,EOF还可以表示标准输入的结尾。
int c;
while ((c = getchar()) != EOF) {
putchar(c);
}
但是,标准输入与文件不一样,无法事先知道输入的长度,必须手动输入一个字符,表示到达EOF。
Linux中,在新的一行的开头,按下Ctrl-D,就代表EOF(如果在一行的中间按下Ctrl-D,则表示输出”标准输入”的缓存区,所以这时必须按两次Ctrl-D);Windows中,Ctrl-Z表示EOF。(顺便提一句,Linux中按下Ctrl-Z,表示将该进程中断,在后台挂起,用fg命令可以重新切回到前台;按下Ctrl-C表示终止该进程。)
那么,如果真的想输入Ctrl-D怎么办?这时必须先按下Ctrl-V,然后就可以输入Ctrl-D,系统就不会认为这是EOF信号。Ctrl-V表示按”字面含义”解读下一个输入,要是想按”字面含义”输入Ctrl-V,连续输入两次就行了。
(完)
为什么文件名要小写?
作者: 阮一峰
日期: 2017年2月10日
上周,《中文技术文档写作规范》加入了文件的命名规则。
“文件名建议只使用小写字母,不使用大写字母。”
“为了醒目,某些说明文件的文件名,可以使用大写字母,比如README、LICENSE。”
网友看见了,就提问为什么文件名要小写?
说实话,虽然这是 Linux 传统,我却从没认真想过原因。赶紧查资料,结果发现四个很有说服力的理由,支持这样做。
下面就是这四个理由。另外,文后我还会发布一条前端培训的消息。
一、可移植性
Linux 系统是大小写敏感的,而 Windows 系统和 Mac 系统正好相反,大小写不敏感。一般来说,这不是大问题。
但是,如果两个文件名只有大小写不同,其他都相同,跨平台就会出问题。
foobar
Foobar
FOOBAR
fOObAr
上面四个文件名,Windows 系统会把它们都当作foobar。如果它们同时存在,你可能没办法打开后面三个文件。
另一方面,在 Mac 系统上开发时,有时会疏忽,写错大小写。
// 正确文件名是 MyModule.js
const module = require(‘./myModule’);
上面的代码在 Mac 上面可以运行,因为 Mac 认为MyModule.js和myModule.js是同一个文件。但是,一旦代码到服务器运行就会报错,因为 Linux 系统找不到myModule.js。
如果所有的文件名都采用小写,就不会出现上面的问题,可以保证项目有良好的可移植性。
二、易读性
小写文件名通常比大写文件名更易读,比如accessibility.txt就比ACCESSIBILITY.TXT易读。
有人习惯使用驼峰命名法,单词的第一个字母大写,其他字母小写。这种方法的问题是,如果遇到全部是大写的缩略词,就会不适用。

比如,一个姓李的纽约特警,无论写成NYPoliceSWATLee还是NyPoliceSwatlee,都怪怪的,还是写成ny-police-swat-lee比较容易接受。
三、易用性
某些系统会生成一些预置的用户目录,采用首字母大写的目录名。比如,Ubuntu 在用户主目录会默认生成Downloads、 Pictures、Documents等目录。
Mac 系统更过分,一部分系统目录也是大写的,比如/Library/Audio/Apple Loops/。
另外,某些常见的配置文件或说明文件,也采用大写的文件名,比如Makefile、INSTALL、CHANGELOG、.Xclients和.Xauthority等等。
所以,用户的文件都采用小写文件名,就很方便与上面这些目录或文件相区分。
如果你打破砂锅问到底,为什么操作系统会采用这样的大写文件名?原因也很简单,因为早期 Unix 系统上,ls命令先列出大写字母,再列出小写字母,大写的路径会排在前面。因此,如果目录名或文件名是大写的,就比较容易被用户首先看到。
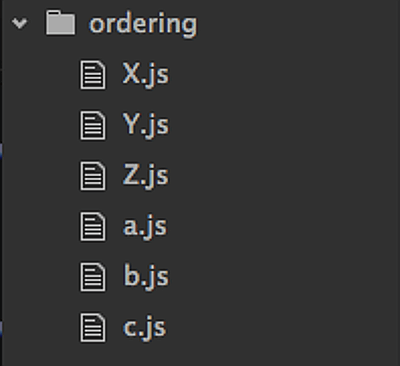
四、便捷性
文件名全部小写,还有利于命令行操作。比如,某些命令可以不使用-i参数了。
大小写敏感的搜索
$ find . -name abc
$ locate “*.htmL”
大小写不敏感的搜索
$ find . -iname abc
$ locate -i “*.HtmL”
另外,大写字母需要按下 Shift 键,多多少少有些麻烦。如果文件名小写,就不用碰这个键了,不仅省事,还可以提高打字速度。
程序员长时间使用键盘,每分钟少按几次 Shift,一天下来就可以省掉很多手指动作。长年累月,也是对自己身体的一种保护。
综上所述,文件名全部使用小写字母和连词线(all-lowercase-with-dashes),是一种值得推广的正确做法。
(正文完)
计算机是怎样跑起来的
目录 · · · · · ·
第1章 计算机的三大原则 1
1.1 计算机的三个根本性基础 3
1.2 输入、运算、输出是硬件的基础 4
1.3 软件是指令和数据的集合 6
1.4 对计算机来说什么都是数字 8
1.5 只要理解了三大原则,即使遇到难懂的最新技术,也能轻松应对 9
1.6 为了贴近人类,计算机在不断地进化 10
1.7 稍微预习一下第2章 13
第2章 试着制造一台计算机吧 15
2.1 制作微型计算机所必需的元件 17
2.2 电路图的读法 21
2.3 连接电源、数据和地址总线 23
2.4 连接I/O 26
2.5 连接时钟信号 27
2.6 连接用于区分读写对象是内存还是I/O的引脚 28
2.7 连接剩余的控制引脚 29
2.8 连接外部设备,通过DMA输入程序 34
2.9 连接用于输入输出的外部设备 35
2.10 输入测试程序并进行调试 36
第3章 体验一次手工汇编 39
3.1 从程序员的角度看硬件 41
3.2 机器语言和汇编语言 44
3.3 Z80 CPU的寄存器结构 49
3.4 追踪程序的运行过程 52
3.5 尝试手工汇编 54
3.6 尝试估算程序的执行时间 57
第4章 程序像河水一样流动着 59
4.1 程序的流程分为三种 61
4.2 用流程图表示程序的流程 65
4.3 表示循环程序块的“帽子”和“短裤” 68
4.4 结构化程序设计 72
4.5 画流程图来思考算法 75
4.6 特殊的程序流程——中断处理 77
4.7 特殊的程序流程——事件驱动 78
COLUMN 来自企业培训现场 电阻颜色代码的谐音助记口诀 82
第5章 与算法成为好朋友的七个要点 85
5.1 算法是程序设计的“熟语” 87
5.2 要点1:算法中解决问题的步骤是明确且有限的 88
5.3 要点2:计算机不靠直觉而是机械地解决问题 89
5.4 要点3:了解并应用典型算法 91
5.5 要点4:利用计算机的处理速度 92
5.6 要点5:使用编程技巧提升程序执行速度 95
5.7 要点6:找出数字间的规律 99
5.8 要点7:先在纸上考虑算法 101
第6章 与数据结构成为好朋友的七个要点 103
6.1 要点1:了解内存和变量的关系 105
6.2 要点2:了解作为数据结构基础的数组 108
6.3 要点3:了解数组的应用——作为典型算法的数据结构 109
6.4 要点4:了解并掌握典型数据结构的类型和概念 111
6.5 要点5:了解栈和队列的实现方法 114
6.6 要点6:了解结构体的组成 118
6.7 要点7:了解链表和二叉树的实现方法 120
第7章 成为会使用面向对象编程的程序员吧 125
7.1 面向对象编程 127
7.2 对OOP的多种理解方法 128
7.3 观点1:面向对象编程通过把组件拼装到一起构建程序 130
7.4 观点2:面向对象编程能够提升程序的开发效率和可维护性 132
7.5 观点3:面向对象编程是适用于大型程序的开发方法 134
7.6 观点4:面向对象编程就是在为现实世界建模 134
7.7 观点5:面向对象编程可以借助UML设计程序 135
7.8 观点6:面向对象编程通过在对象间传递消息驱动程序 137
7.9 观点7:在面向对象编程中使用继承、封装和多态 140
7.10 类和对象的区别 141
7.11 类有三种使用方法 143
7.12 在Java和.NET中有关OOP的知识不能少 145
第8章 一用就会的数据库 147
8.1 数据库是数据的基地 149
8.2 数据文件、DBMS和数据库应用程序 151
8.3 设计数据库 154
8.4 通过拆表和整理数据实现规范化 157
8.5 用主键和外键在表间建立关系 159
8.6 索引能够提升数据的检索速度 162
8.7 设计用户界面 164
8.8 向DBMS发送CRUD操作的SQL语句 165
8.9 使用数据对象向DBMS发送SQL语句 167
8.10 事务控制也可以交给DBMS处理 170
COLUMN 来自企业培训现场 培训新人编程时推荐使用什么编程语言? 172
第9章 通过七个简单的实验理解TCP/IP网络 175
9.1 实验环境 177
9.2 实验1:查看网卡的MAC地址 179
9.3 实验2:查看计算机的IP地址 182
9.4 实验3:了解DHCP服务器的作用 184
9.5 实验4:路由器是数据传输过程中的指路人 186
9.6 实验5:查看路由器的路由过程 188
9.7 实验6:DNS服务器可以把主机名解析成IP地址 190
9.8 实验7:查看IP地址和MAC地址的对应关系 192
9.9 TCP的作用及TCP/IP网络的层级模型 193
第10章 试着加密数据吧 197
10.1 先来明确一下什么是加密 199
10.2 错开字符编码的加密方式 201
10.3 密钥越长,解密越困难 205
10.4 适用于互联网的公开密钥加密技术 208
10.5 数字签名可以证明数据的发送者是谁 211
第11章 XML究竟是什么 215
11.1 XML是标记语言 217
11.2 XML是可扩展的语言 219
11.3 XML是元语言 220
11.4 XML可以为信息赋予意义 224
11.5 XML是通用的数据交换格式 227
11.6 可以为XML标签设定命名空间 230
11.7 可以严格地定义 XML的文档结构 232
11.8 用于解析XML的组件 233
11.9 XML可用于各种各样的领域 235
第12章 SE负责监管计算机系统的构建 239
12.1 SE是自始至终参与系统开发过程的工程师 241
12.2 SE未必担任过程序员 243
12.3 系统开发过程的规范 243
12.4 各个阶段的工作内容及文档 245
12.5 所谓设计,就是拆解 247
12.6 面向对象法简化了系统维护工作 249
12.7 技术能力和沟通能力 250
12.8 IT不等于引进计算机 252
12.9 计算机系统的成功与失败 253
12.10 大幅提升设备利用率的多机备份 255
穿越计算机的迷雾

《穿越计算机的迷雾》从最基本的电学知识开始,带领读者一步一步、从无到有地制造一台能全自动工作的计算机。在这个过程中,读者可以学习到大量有趣的电学、数学和逻辑学知识,了解到它们是如何为电子计算机的产生创造条件,并促使它不断向着更快、更小、更强的方向发展。通过阅读《穿越计算机的迷雾》,读者可以很容易地理解自动计算实际上是如何发生的,而现代的计算机又是怎么工作的。以此为基础,在《穿越计算机的迷雾》的后面集中介绍了现代计算机的组成和主要功能,以及计算机核心与外部设备的接口,并对以操作系统为核心的软件进行了介绍。未经许可,不得以任何方式复制或抄袭《穿越计算机的迷雾》之部分或全部内容。
目 录
第1章 了解计算机,要从电开始 1
1.1 有的东西能导电,而有的则不能 2
1.2 电的老家是原子 2
1.3 为什么有些东西可以导电 6
1.4 电流是怎样形成的 8
1.5 电路和电路图 12
第2章 用电来表示数 16
2.1 怎样用电来代表一个数字 17
2.2 古怪的二进制计数法 21
2.3 二进制数就是比特串 25
2.4 用开关来表示二进制数字 26
第3章 怎样才能让机器做加法 30
3.1 我们是怎样用十进制做加法的 30
3.2 用二进制做加法其实更简单 31
3.3 使用全加器来构造加法机 33
第4章 电子计算机发明的前夜 38
4.1 电能生磁 39
4.2 继电器和莫尔斯电码 41
4.3 磁也能生电 44
4.4 电话的发明 46
4.5 爱迪生大战交流电 48
4.6 无线电通信的开端 53
第5章 从逻辑学到逻辑电路 59
5.1 逻辑学 59
5.2 数理逻辑 70
5.3 数字逻辑和逻辑电路 75
第6章 加法机的诞生 88
6.1 全加器的构造 88
6.2 加法机的组成 92
第7章 会变魔术的触发器 95
7.1 不寻常的开关和灯 95
7.2 反馈和振荡器 96
7.3 电子管时代 100
7.4 记忆力非凡的触发器 105
7.5 触发器的符号 109
第8章 学生时代的走马灯 111
8.1 能保存一个比特的触发器 111
8.2 边沿触发 115
8.3 揭开走马灯之谜 117
8.4 这个触发器很古怪 119
第9章 计算机时代的开路先锋 121
9.1 纯电子化的计算时代 121
9.2 晶体管时代 123
9.3 新材料带动技术进步 128
第10章 用机器做一连串的加法 133
10.1 把一大堆数加起来 133
10.2 轮流使用总线 137
10.3 简化操作过程 139
10.4 这就是传说中的控制器 143
第11章 全自动加法计算机 149
11.1 咸鸭蛋坛子和存储器 149
11.2 磁芯存储器 155
11.3 先存储,后计算 157
11.4 半自动操作 162
11.5 全自动计算 166
第12章 现代的通用计算机 168
12.1 更多的计算机指令 169
12.2 当计算机面临选择时 173
12.3 现代计算机的大体特征 177
12.4 为什么计算机如此有用 180
第13章 集成电路时代 183
13.1 电子管和晶体管时代 183
13.2 集成电路时代 186
13.3 流水线和高速缓存技术 192
13.4 掌上游戏机和手机就是计算机 196
第14章 核心与外部设备间的接口 198
14.1 计算机同外部的接口 199
14.2 I/O接口 203
14.3 中断和直接存储器访问 206
14.4 键盘 209
14.5 显示器 213
第15章 计算机的启动过程和操作系统 224
15.1 打开电源并启动计算机 225
15.2 各种各样的辅助存储设备 228
15.3 启动操作系统 235
15.4 操作系统的功能 237
第16章 办公、娱乐和程序设计 241
16.1 用于写文章和排版的文字处理软件 241
16.2 压缩和解压缩 243
16.3 图像、音乐和视频 245
16.4 计算机语言和编译软件 248
16.5 计算机病毒也是软件 254
编码

本书讲述的是计算机工作原理。作者用丰富的想象和清晰的笔墨将看似繁杂的理论阐述得通俗易懂,你丝毫不会感到枯燥和生硬。更重要的是,你会因此而获得对计算机工作原理较深刻的理解。这种理解不是抽象层面上的,而是具有一定深度的。
第1章 至亲密友
第2章 编码与组合
第3章 布莱叶盲文与二进制码
第4章 手电筒的剖析
第5章 绕过拐角的通信
第6章 电报机与继电器
第7章 我们的十个数字
第8章 十的替代品
第9章 二进制数
第10章 逻辑与开关
第11章 门
第12章 二进制加法器
第13章 如何实现减法
第14章 反馈与触发器
第15章 字节与十六进制
第16章 存储器组织
第17章 自动操作
第18章 从算盘到芯片
第19章 两种典型的微处理器
第20章 ASCII码和字符转换
第21章 总线
第22章 操作系统
第23章 定点数和浮点数
第24章 高级语言与低级语言
第25章 图形化革命
程序是怎样跑起来的
本书从计算机的内部结构开始讲起,以图配文的形式详细讲解了二进制、内存、数据压缩、源文件和可执行文件、操作系统和应用程序的关系、汇编语言、硬件控制方法等内容,目的是让读者了解从用户双击程序图标到程序开始运行之间到底发生了什么。同时专设了“如果是你,你会怎样介绍?”专栏,以小学生、老奶奶为对象讲解程序的运行原理,颇为有趣。本书图文并茂,通俗易懂,非常适合计算机爱好者及相关从业人员阅读。
第1章 对程序员来说CPU是什么 1
1.1 CPU的内部结构解析 3
1.2 CPU是寄存器的集合体 6
1.3 决定程序流程的程序计数器 9
1.4 条件分支和循环机制 10
1.5 函数的调用机制 13
1.6 通过地址和索引实现数组 16
1.7 CPU的处理其实很简单 17
第2章 数据是用二进制数表示的 19
2.1 用二进制数表示计算机信息的原因 21
2.2 什么是二进制数 23
2.3 移位运算和乘除运算的关系 25
2.4 便于计算机处理的“补数” 27
2.5 逻辑右移和算术右移的区别 31
2.6 掌握逻辑运算的窍门 34
COLUMN 如果是你,你会怎样介绍?——向小学生讲解CPU和二进制 38
第3章 计算机进行小数运算时出错的原因 41
3.1 将0.1累加100次也得不到10 43
3.2 用二进制数表示小数 44
3.3 计算机运算出错的原因 46
3.4 什么是浮点数 47
3.5 正则表达式和 EXCESS系统 50
3.6 在实际的程序中进行确认 52
3.7 如何避免计算机计算出错 55
3.8 二进制数和十六进制数 56
第4章 熟练使用有棱有角的内存 59
4.1 内存的物理机制很简单 61
4.2 内存的逻辑模型是楼房 65
4.3 简单的指针 67
4.4 数组是高效使用内存的基础 69
4.5 栈、队列以及环形缓冲区 71
4.6 链表使元素的追加和删除更容易 75
4.7 二叉查找树使数据搜索更有效 79
第5章 内存和磁盘的亲密关系 81
5.1 不读入内存就无法运行 83
5.2 磁盘缓存加快了磁盘访问速度 84
5.3 虚拟内存把磁盘作为部分内存来使用 85
5.4 节约内存的编程方法 88
5.5 磁盘的物理结构 93
第6章 亲自尝试压缩数据 97
6.1 文件以字节为单位保存 99
6.2 RLE 算法的机制 100
6.3 RLE 算法的缺点 101
6.4 通过莫尔斯编码来看哈夫曼算法的基础 103
6.5 用二叉树实现哈夫曼编码 105
6.6 哈夫曼算法能够大幅提升压缩比率 109
6.7 可逆压缩和非可逆压缩 110
COLUMN 如果是你,你会怎样介绍?——向沉迷游戏的中学生讲解内存和磁盘 114
第7章 程序是在何种环境中运行的 117
7.1 运行环境=操作系统+硬件 119
7.2 Windows克服了CPU以外的硬件差异 122
7.3 不同操作系统的API不同 124
7.4 FreeBSD Port帮你轻松使用源代码 125
7.5 利用虚拟机获得其他操作系统环境 127
7.6 提供相同运行环境的 Java虚拟机 128
7.7 BIOS和引导 130
第8章 从源文件到可执行文件 133
8.1 计算机只能运行本地代码 135
8.2 本地代码的内容 137
8.3 编译器负责转换源代码 139
8.4 仅靠编译是无法得到可执行文件的 141
8.5 启动及库文件 143
8.6 DLL文件及导入库 145
8.7 可执行文件运行时的必要条件 146
8.8 程序加载时会生成栈和堆 148
8.9 有点难度的Q&A 150
第9章 操作系统和应用的关系 153
9.1 操作系统功能的历史 155
9.2 要意识到操作系统的存在 157
9.3 系统调用和高级编程语言的移植性 160
9.4 操作系统和高级编程语言使硬件抽象化 161
9.5 Windows操作系统的特征 163
COLUMN 如果是你,你会怎样介绍?——向超喜欢手机的女高中生讲解操作系统的作用 170
第10章 通过汇编语言了解程序的实际构成 173
10.1 汇编语言和本地代码是一一对应的 175
10.2 通过编译器输出汇编语言的源代码 177
10.3 不会转换成本地代码的伪指令 180
10.4 汇编语言语法是“操作码+操作数” 182
10.5 最常用的mov指令 185
10.6 对栈进行push和pop 185
10.7 函数调用机制 187
10.8 函数内部的处理 189
10.9 始终确保全局变量用的内存空间 191
10.10 临时确保局部变量用的内存空间 196
10.11 循环处理的实现方法 199
10.12 条件分支的实现方法 202
10.13 了解程序运行方式的必要性 204
第11章 硬件控制方法 209
11.1 应用和硬件无关? 211
11.2 支撑硬件输入输出的IN指令和OUT指令 212
11.3 编写测试用的输入输出程序 215
11.4 外围设备的中断请求 218
11.5 用中断来实现实时处理 221
11.6 DMA可以实现短时间内传送大量数据 222
11.7 文字及图片的显示机制 224
COLUMN 如果是你,你会怎样介绍?——向邻居老奶奶说明显示器和电视机的不同 226
第12章 让计算机“思考” 229
12.1 作为“工具”的程序和为了“思考”的程序 231
12.2 用程序来表示人类的思考方式 232
12.3 用程序来表示人类的思考习惯 235
12.4 程序生成随机数的方法 237
12.5 活用记忆功能以达到更接近人类的判断 239
12.6 用程序来表示人类的思考方式 242
COLUMN 如果是你,你会怎样介绍?——向常光临的酒馆老板讲解计算机的思考机制 245
附录 让我们开始C语言之旅 247
C语言的特点 247
变量和函数 248
数据类型 249
标准函数库 250
函数调用 251
局部变量和全局变量 254
数组和循环 255
其他语法结构 256
网络是怎样连接的

本书以探索之旅的形式,从在浏览器中输入网址开始,一路追踪了到显示出网页内容为止的整个过程,以图配文,讲解了网络的全貌,并重点介绍了实际的网络设备和软件是如何工作的。目的是帮助读者理解网络的本质意义,理解实际的设备和软件,进而熟练运用网络技术。同时,专设了“网络术语其实很简单”专栏,以对话的形式介绍了一些网络术语的词源,颇为生动有趣。
本书图文并茂,通俗易懂,非常适合计算机、网络爱好者及相关从业人员阅读。
第1章 浏览器生成消息 1
——探索浏览器内部
1.1 生成HTTP请求消息 5
1.1.1 探索之旅从输入网址开始 5
1.1.2 浏览器先要解析URL 7
1.1.3 省略文件名的情况 9
1.1.4 HTTP的基本思路 10
1.1.5 生成HTTP请求消息 14
1.1.6 发送请求后会收到响应 20
1.2 向DNS服务器查询Web服务器的IP地址 24
1.2.1 IP地址的基本知识 24
1.2.2 域名和IP地址并用的理由 28
1.2.3 Socket库提供查询IP地址的功能 30
1.2.4 通过解析器向DNS服务器发出查询 31
1.2.5 解析器的内部原理 32
1.3 全世界DNS服务器的大接力 35
1.3.1 DNS服务器的基本工作 35
1.3.2 域名的层次结构 38
1.3.3 寻找相应的DNS服务器并获取IP地址 40
1.3.4 通过缓存加快DNS服务器的响应 44
1.4 委托协议栈发送消息 45
1.4.1 数据收发操作概览 45
1.4.2 创建套接字阶段 48
1.4.3 连接阶段:把管道接上去 50
1.4.4 通信阶段:传递消息 52
1.4.5 断开阶段:收发数据结束 53
怪杰Resolver 55
第2章 用电信号传输TCP/IP数据 57
——探索协议栈和网卡
2.1 创建套接字 61
2.1.1 协议栈的内部结构 61
2.1.2 套接字的实体就是通信控制信息 63
2.1.3 调用socket时的操作 66
2.2 连接服务器 68
2.2.1 连接是什么意思 68
2.2.2 负责保存控制信息的头部 70
2.2.3 连接操作的实际过程 73
2.3 收发数据 75
2.3.1 将HTTP请求消息交给协议栈 75
2.3.2 对较大的数据进行拆分 78
2.3.3 使用ACK号确认网络包已收到 79
2.3.4 根据网络包平均往返时间调整ACK号等待时间 83
2.3.5 使用窗口有效管理ACK号 84
2.3.6 ACK与窗口的合并 87
2.3.7 接收HTTP响应消息 89
2.4 从服务器断开并删除套接字 90
2.4.1 数据发送完毕后断开连接 90
2.4.2 删除套接字 92
2.4.3 数据收发操作小结 93
2.5 IP与以太网的包收发操作 95
2.5.1 包的基本知识 95
2.5.2 包收发操作概览 99
2.5.3 生成包含接收方IP地址的IP头部 102
2.5.4 生成以太网用的MAC头部 106
2.5.5 通过ARP查询目标路由器的MAC地址 108
2.5.6 以太网的基本知识 111
2.5.7 将IP包转换成电或光信号发送出去 114
2.5.8 给网络包再加3个控制数据 116
2.5.9 向集线器发送网络包 120
2.5.10 接收返回包 123
2.5.11 将服务器的响应包从IP传递给TCP 125
2.6 UDP协议的收发操作 128
2.6.1 不需要重发的数据用UDP发送更高效 128
2.6.2 控制用的短数据 129
2.6.3 音频和视频数据 130
插进Socket里的是灯泡还是程序 132
第3章 从网线到网络设备 135
——探索集线器、交换机和路由器
3.1 信号在网线和集线器中传输 139
3.1.1 每个包都是独立传输的 139
3.1.2 防止网线中的信号衰减很重要 140
3.1.3 “双绞”是为了抑制噪声 141
3.1.4 集线器将信号发往所有线路 146
3.2 交换机的包转发操作 149
3.2.1 交换机根据地址表进行转发 149
3.2.2 MAC地址表的维护 153
3.2.3 特殊操作 154
3.2.4 全双工模式可以同时进行发送和接收 155
3.2.5 自动协商:确定最优的传输速率 156
3.2.6 交换机可同时执行多个转发操作 159
3.3 路由器的包转发操作 159
3.3.1 路由器的基本知识 159
3.3.2 路由表中的信息 162
3.3.3 路由器的包接收操作 166
3.3.4 查询路由表确定输出端口 166
3.3.5 找不到匹配路由时选择默认路由 168
3.3.6 包的有效期 169
3.3.7 通过分片功能拆分大网络包 170
3.3.8 路由器的发送操作和计算机相同 172
3.3.9 路由器与交换机的关系 173
3.4 路由器的附加功能 176
3.4.1 通过地址转换有效利用IP地址 176
3.4.2 地址转换的基本原理 178
3.4.3 改写端口号的原因 180
3.4.4 从互联网访问公司内网 181
3.4.5 路由器的包过滤功能 182
集线器和路由器,换个名字身价翻倍? 184
第4章 通过接入网进入互联网内部 187
——探索接入网和网络运营商
4.1 ADSL接入网的结构和工作方式 191
4.1.1 互联网的基本结构和家庭、公司网络是相同的 191
4.1.2 连接用户与互联网的接入网 192
4.1.3 ADSL Modem将包拆分成信元 193
4.1.4 ADSL将信元“调制”成信号 197
4.1.5 ADSL通过使用多个波来提高速率 200
4.1.6 分离器的作用 201
4.1.7 从用户到电话局 203
4.1.8 噪声的干扰 204
4.1.9 通过DSLAM到达BAS 205
4.2 光纤接入网(FTTH) 206
4.2.1 光纤的基本知识 206
4.2.2 单模与多模 208
4.2.3 通过光纤分路来降低成本 213
4.3 接入网中使用的PPP和隧道 217
4.3.1 用户认证和配置下发 217
4.3.2 在以太网上传输PPP消息 219
4.3.3 通过隧道将网络包发送给运营商 223
4.3.4 接入网的整体工作过程 225
4.3.5 不分配IP地址的无编号端口 228
4.3.6 互联网接入路由器将私有地址转换成公有地址 228
4.3.7 除PPPoE之外的其他方式 230
4.4 网络运营商的内部 233
4.4.1 POP和NOC 233
4.4.2 室外通信线路的连接 236
4.5 跨越运营商的网络包 238
4.5.1 运营商之间的连接 238
4.5.2 运营商之间的路由信息交换 239
4.5.3 与公司网络中自动更新路由表机制的区别 241
4.5.4 IX的必要性 242
4.5.5 运营商如何通过IX互相连接 243
名字叫服务器,其实是路由器 246
第5章 服务器端的局域网中有什么玄机 249
5.1 Web服务器的部署地点 253
5.1.1 在公司里部署Web服务器 253
5.1.2 将Web服务器部署在数据中心 255
5.2 防火墙的结构和原理 256
5.2.1 主流的包过滤方式 256
5.2.2 如何设置包过滤的规则 256
5.2.3 通过端口号限定应用程序 260
5.2.4 通过控制位判断连接方向 260
5.2.5 从公司内网访问公开区域的规则 262
5.2.6 从外部无法访问公司内网 262
5.2.7 通过防火墙 263
5.2.8 防火墙无法抵御的攻击 264
5.3 通过将请求平均分配给多台服务器来平衡负载 265
5.3.1 性能不足时需要负载均衡 265
5.3.2 使用负载均衡器分配访问 266
5.4 使用缓存服务器分担负载 270
5.4.1 如何使用缓存服务器 270
5.4.2 缓存服务器通过更新时间管理内容 271
5.4.3 最原始的代理——正向代理 276
5.4.4 正向代理的改良版——反向代理 278
5.4.5 透明代理 279
5.5 内容分发服务 280
5.5.1 利用内容分发服务分担负载 280
5.5.2 如何找到最近的缓存服务器 282
5.5.3 通过重定向服务器分配访问目标 285
5.5.4 缓存的更新方法会影响性能 287
当通信线路变成局域网 291
第6章 请求到达Web服务器,响应返回浏览器 293
——短短几秒的“漫长旅程”迎来终点
6.1 服务器概览 297
6.1.1 客户端与服务器的区别 297
6.1.2 服务器程序的结构 297
6.1.3 服务器端的套接字和端口号 299
6.2 服务器的接收操作 305
6.2.1 网卡将接收到的信号转换成数字信息 305
6.2.2 IP模块的接收操作 308
6.2.3 TCP模块如何处理连接包 309
6.2.4 TCP模块如何处理数据包 311
6.2.5 TCP模块的断开操作 312
6.3 Web服务器程序解释请求消息并作出响应 313
6.3.1 将请求的URI转换为实际的文件名 313
6.3.2 运行CGI程序 316
6.3.3 Web服务器的访问控制 319
6.3.4 返回响应消息 323
6.4 浏览器接收响应消息并显示内容 323
6.4.1 通过响应的数据类型判断其中的内容 323
6.4.2 浏览器显示网页内容!访问完成! 326
Gateway是通往异世界的入口 328
附录 330
后记 334
致谢 334
作者简介 335